
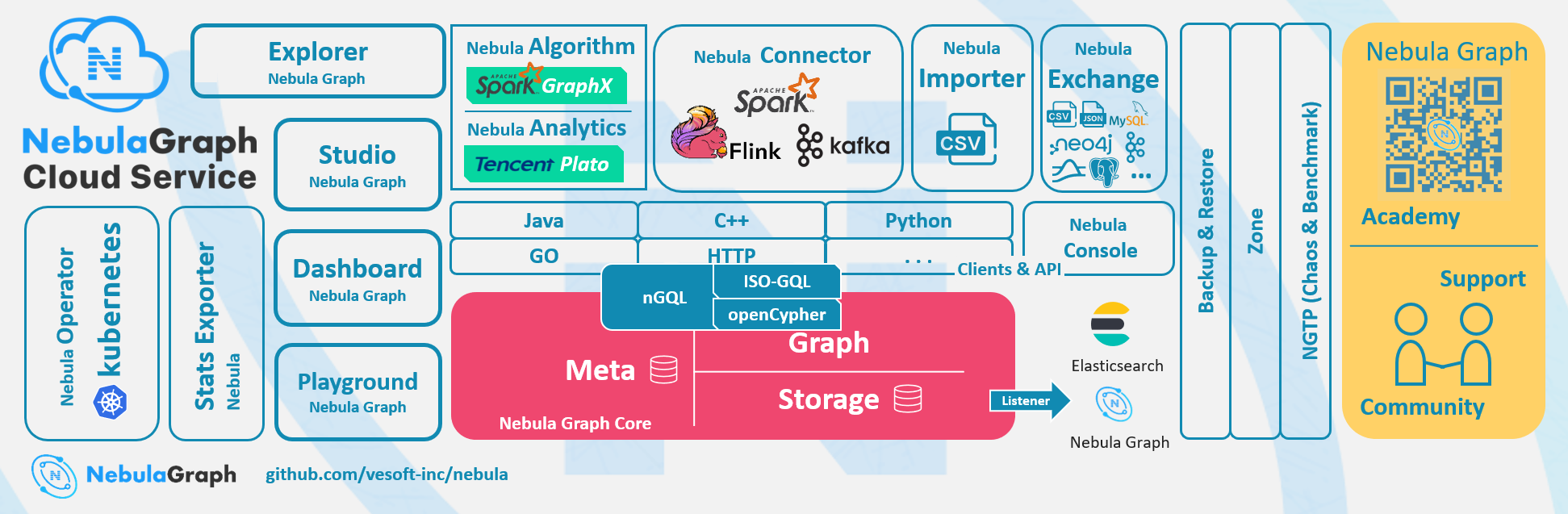
推薦一個分散式圖資料庫Nebula Graph,萬億級數據,毫秒級延時 什麼是Nebula Graph Nebula Graph 是一款開源的、分散式的、易擴展的原生圖資料庫,能夠承載包含數千億個點和數萬億條邊的超大規模數據集,並且提供毫秒級查詢 什麼是圖資料庫 圖資料庫是專門存儲龐大的圖形網路並從 ...
推薦一個分散式圖資料庫Nebula Graph,萬億級數據,毫秒級延時
什麼是Nebula Graph
Nebula Graph 是一款開源的、分散式的、易擴展的原生圖資料庫,能夠承載包含數千億個點和數萬億條邊的超大規模數據集,並且提供毫秒級查詢
什麼是圖資料庫
圖資料庫是專門存儲龐大的圖形網路並從中檢索信息的資料庫。它可以將圖中的數據高效存儲為點(Vertex)和邊(Edge),還可以將屬性(Property)附加到點和邊上
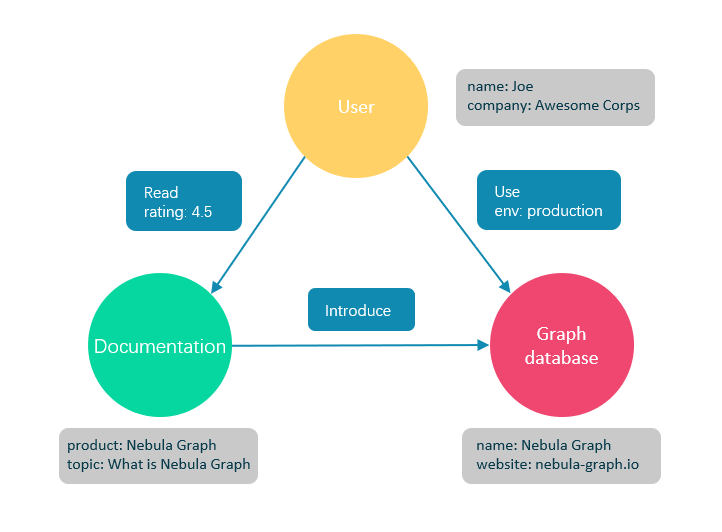
圖資料庫適合存儲大多數從現實抽象出的數據類型。世界上幾乎所有領域的事物都有內在聯繫,像關係型資料庫這樣的建模系統會提取實體之間的關係,並將關係單獨存儲到表和列中,而實體的類型和屬性存儲在其他列甚至其他表中,這使得數據管理費時費力。
Nebula Graph 作為一個典型的圖資料庫,可以將豐富的關係通過邊及其類型和屬性自然地呈現。
Nebula Graph 的優勢
開源
Nebula Graph 是在 Apache 2.0 條款下開發的。越來越多的人,如資料庫開發人員、數據科學家、安全專家、演算法工程師,都參與到 Nebula Graph 的設計和開發中來,歡迎訪問 Nebula Graph GitHub 主頁參與開源項目。
高性能
基於圖資料庫的特性使用 C++ 編寫的 Nebula Graph,可以提供毫秒級查詢。眾多資料庫中,Nebula Graph 在圖數據服務領域展現了卓越的性能,數據規模越大,Nebula Graph 優勢就越大。詳情請參見 Nebula Graph benchmarking 頁面。
易擴展
Nebula Graph 採用 shared-nothing 架構,支持在不停止資料庫服務的情況下擴縮容。
易開發
Nebula Graph 提供 Java、Python、C++ 和 Go 等流行編程語言的客戶端,更多客戶端仍在開發中。詳情請參見 Nebula Graph clients。
高可靠訪問控制
Nebula Graph 支持嚴格的角色訪問控制和 LDAP(Lightweight Directory Access Protocol)等外部認證服務,能夠有效提高數據安全性。詳情請參見驗證和授權。
生態多樣化
Nebula Graph 開放了越來越多的原生工具,例如 Nebula Graph Studio、Nebula Console、Nebula Exchange 等,更多工具可以查看生態工具概覽。
此外,Nebula Graph 還具備與 Spark、Flink、HBase 等產品整合的能力,在這個充滿挑戰與機遇的時代,大大增強了自身的競爭力。
相容 openCypher 查詢語言
Nebula Graph 查詢語言,簡稱為 nGQL,是一種聲明性的、部分相容 openCypher 的文本查詢語言,易於理解和使用。詳細語法請參見 nGQL 指南。
面向未來硬體,讀寫平衡
快閃記憶體型設備有著極高的性能,並且價格快速下降, Nebula Graph 是一個面向 SSD 設計的產品,相比於基於 HDD + 大記憶體的產品,更適合面向未來的硬體趨勢,也更容易做到讀寫平衡。
靈活數據建模
用戶可以輕鬆地在 Nebula Graph 中建立數據模型,不必將數據強制轉換為關係表。而且可以自由增加、更新和刪除屬性。詳情請參見數據模型。
廣受歡迎
騰訊、美團、京東、快手、360 等科技巨頭都在使用 Nebula Graph。詳情請參見 Nebula Graph 官網。
適用場景
Nebula Graph 可用於各種基於圖的業務場景。為節約轉換各類數據到關係型資料庫的時間,以及避免複雜查詢,建議使用 Nebula Graph。
欺詐檢測
金融機構必須仔細研究大量的交易信息,才能檢測出潛在的金融欺詐行為,並瞭解某個欺詐行為和設備的內在關聯。這種場景可以通過圖來建模,然後藉助 Nebula Graph,可以很容易地檢測出詐騙團夥或其他複雜詐騙行為。
實時推薦
Nebula Graph 能夠及時處理訪問者產生的實時信息,並且精準推送文章、視頻、產品和服務。
知識圖譜
自然語言可以轉化為知識圖譜,存儲在 Nebula Graph 中。用自然語言組織的問題可以通過智能問答系統中的語義解析器進行解析並重新組織,然後從知識圖譜中檢索出問題的可能答案,提供給提問人。
社交網路
人際關係信息是典型的圖數據,Nebula Graph 可以輕鬆處理數十億人和數萬億人際關係的社交網路信息,併在海量併發的情況下,提供快速的好友推薦和工作崗位查詢。
服務架構
架構總覽
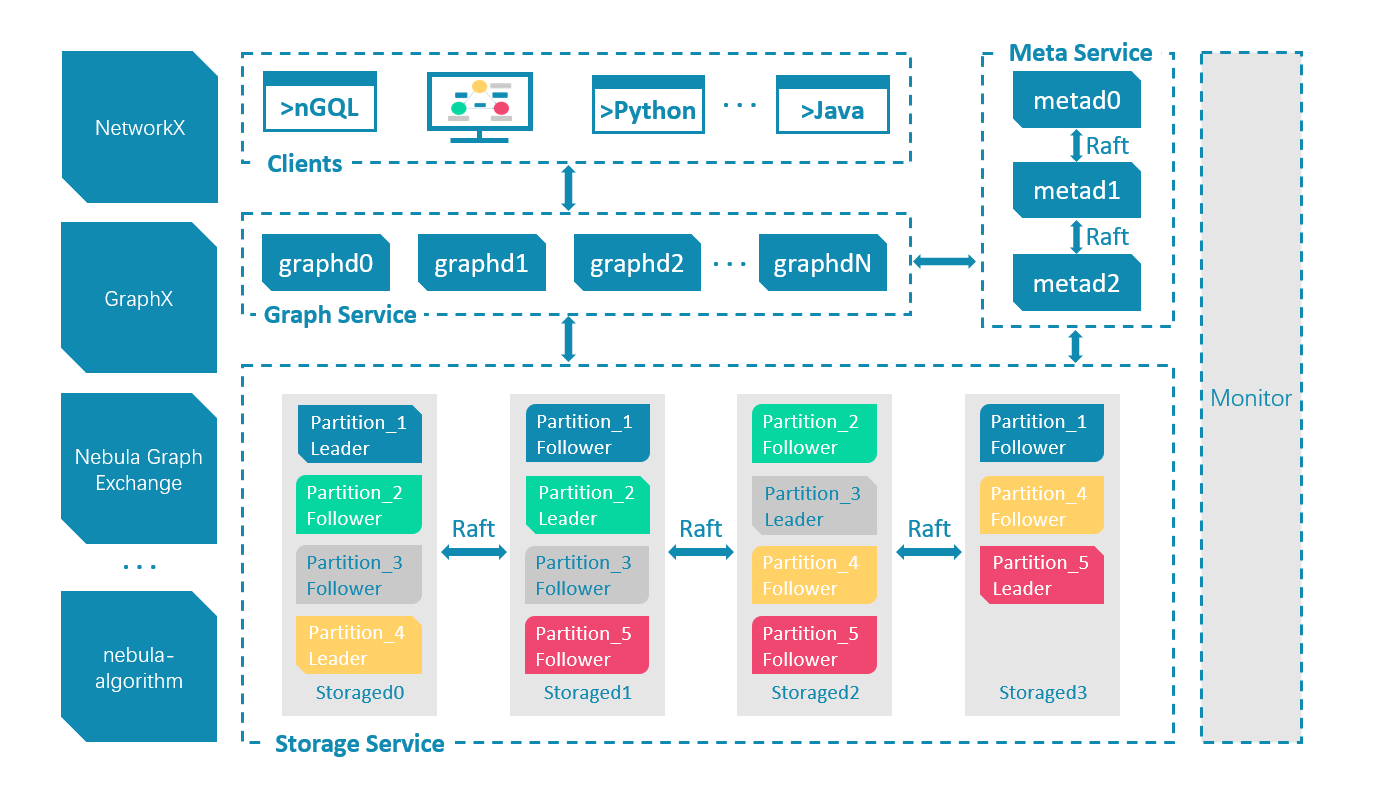
Nebula Graph 由三種服務構成:Graph 服務、Meta 服務和 Storage 服務,是一種存儲與計算分離的架構。
每個服務都有可執行的二進位文件和對應進程,用戶可以使用這些二進位文件在一個或多個電腦上部署 Nebula Graph 集群。
下圖展示了 Nebula Graph 集群的經典架構。
Meta 服務
在 Nebula Graph 架構中,Meta 服務是由 nebula-metad 進程提供的,負責數據管理,例如 Schema 操作、集群管理和用戶許可權管理等。
Graph 服務和 Storage 服務
Nebula Graph 採用計算存儲分離架構。Graph 服務負責處理計算請求,Storage 服務負責存儲數據。它們由不同的進程提供,Graph 服務是由 nebula-graphd 進程提供,Storage 服務是由 nebula-storaged 進程提供。計算存儲分離架構的優勢如下:
易擴展
分散式架構保證了 Graph 服務和 Storage 服務的靈活性,方便擴容和縮容。
高可用
如果提供 Graph 服務的伺服器有一部分出現故障,其餘伺服器可以繼續為客戶端提供服務,而且 Storage 服務存儲的數據不會丟失。服務恢復速度較快,甚至能做到用戶無感知。
節約成本
計算存儲分離架構能夠提高資源利用率,而且可根據業務需求靈活控製成本。
更多可能性
基於分離架構的特性,Graph 服務將可以在更多類型的存儲引擎上單獨運行,Storage 服務也可以為多種目的計算引擎提供服務。
Meta 服務
Meta 服務架構
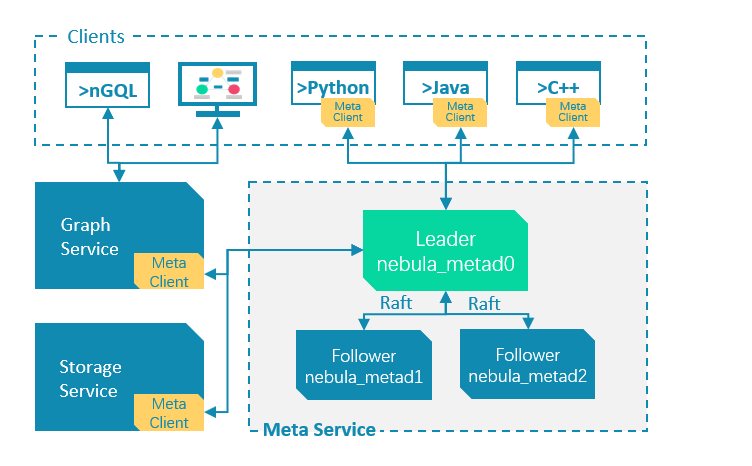
Meta 服務是由 nebula-metad 進程提供的,用戶可以根據場景配置 nebula-metad 進程數量:
- 測試環境中,用戶可以在 Nebula Graph 集群中部署 1 個或 3 個 nebula-metad 進程。如果要部署 3 個,用戶可以將它們部署在 1 台機器上,或者分別部署在不同的機器上。
- 生產環境中,建議在 Nebula Graph 集群中部署 3 個 nebula-metad 進程。請將這些進程部署在不同的機器上以保證高可用。
所有 nebula-metad 進程構成了基於 Raft 協議的集群,其中一個進程是 leader,其他進程都是 follower。
leader 是由多數派選舉出來,只有 leader 能夠對客戶端或其他組件提供服務,其他 follower 作為候補,如果 leader 出現故障,會在所有 follower 中選舉出新的 leader。
leader 和 follower 的數據通過 Raft 協議保持一致,因此 leader 故障和選舉新 leader 不會導致數據不一致。更多關於 Raft 的介紹見 Storage 服務
Meta 服務功能
管理用戶賬號
Meta 服務中存儲了用戶的賬號和許可權信息,當客戶端通過賬號發送請求給 Meta 服務,Meta 服務會檢查賬號信息,以及該賬號是否有對應的請求許可權。
更多 Nebula Graph 的訪問控制說明,請參見身份驗證。
管理分片
Meta 服務負責存儲和管理分片的位置信息,並且保證分片的負載均衡。
管理圖空間
Nebula Graph 支持多個圖空間,不同圖空間內的數據是安全隔離的。Meta 服務存儲所有圖空間的元數據(非完整數據),並跟蹤數據的變更,例如增加或刪除圖空間。
管理 Schema 信息
Nebula Graph 是強類型圖資料庫,它的 Schema 包括 Tag、Edge type、Tag 屬性和 Edge type 屬性。
Meta 服務中存儲了 Schema 信息,同時還負責 Schema 的添加、修改和刪除,並記錄它們的版本。
更多 Nebula Graph 的 Schema 信息,請參見數據模型。
管理 TTL 信息
Meta 服務存儲 TTL(Time To Live)定義信息,可以用於設置數據生命周期。數據過期後,會由 Storage 服務進行處理,具體過程參見 TTL。
管理作業
Meta 服務中的作業管理模塊負責作業的創建、排隊、查詢和刪除。
Graph服務
Graph 服務主要負責處理查詢請求,包括解析查詢語句、校驗語句、生成執行計劃以及按照執行計劃執行四個大步驟,本文將基於這些步驟介紹 Graph 服務。
Graph 服務架構
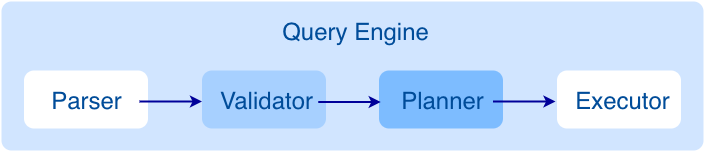
查詢請求發送到 Graph 服務後,會由如下模塊依次處理:
- Parser:詞法語法解析模塊。
- Validator:語義校驗模塊。
- Planner:執行計劃與優化器模塊。
- Executor:執行引擎模塊。
Parser
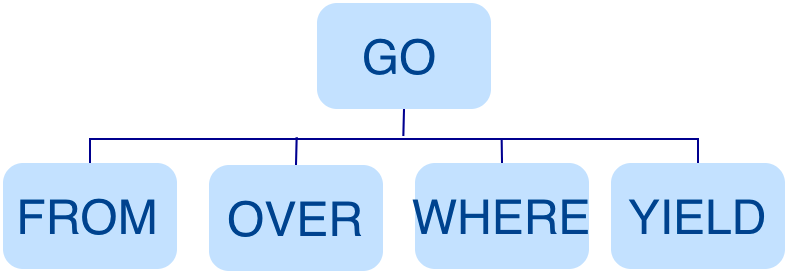
Parser 模塊收到請求後,通過 Flex(詞法分析工具)和 Bison(語法分析工具)生成的詞法語法解析器,將語句轉換為抽象語法樹(AST),在語法解析階段會攔截不符合語法規則的語句。
例如GO FROM "Tim" OVER like WHERE properties(edge).likeness > 8.0 YIELD dst(edge)語句轉換的 AST 如下。
Validator
Validator 模塊對生成的 AST 進行語義校驗,主要包括:
校驗元數據信息
校驗語句中的元數據信息是否正確。
例如解析 OVER、WHERE和YIELD 語句時,會查找 Schema 校驗 Edge type、Tag 的信息是否存在,或者插入數據時校驗插入的數據類型和 Schema 中的是否一致。
校驗上下文引用信息
校驗引用的變數是否存在或者引用的屬性是否屬於變數。
例如語句$var = GO FROM "Tim" OVER like YIELD dst(edge) AS ID; GO FROM $var.ID OVER serve YIELD dst(edge),Validator 模塊首先會檢查變數 var 是否定義,其次再檢查屬性 ID 是否屬於變數 var。
校驗類型推斷
推斷表達式的結果類型,並根據子句校驗類型是否正確。
例如 WHERE 子句要求結果是 bool、null 或者 empty。
校驗 * 代表的信息
查詢語句中包含 * 時,校驗子句時需要將 * 涉及的 Schema 都進行校驗。
例如語句GO FROM "Tim" OVER * YIELD dst(edge), properties(edge).likeness, dst(edge),校驗OVER子句時需要校驗所有的 Edge type,如果 Edge type 包含 like和serve,該語句會展開為GO FROM "Tim" OVER like,serve YIELD dst(edge), properties(edge).likeness, dst(edge)。
校驗輸入輸出
校驗管道符(|)前後的一致性。
例如語句GO FROM "Tim" OVER like YIELD dst(edge) AS ID | GO FROM $-.ID OVER serve YIELD dst(edge),Validator 模塊會校驗 $-.ID 在管道符左側是否已經定義。
校驗完成後,Validator 模塊還會生成一個預設可執行,但是未進行優化的執行計劃,存儲在目錄 src/planner 內。
Planner
如果配置文件 nebula-graphd.conf 中 enable_optimizer 設置為 false,Planner 模塊不會優化 Validator 模塊生成的執行計劃,而是直接交給 Executor 模塊執行。
如果配置文件 nebula-graphd.conf中enable_optimizer 設置為 true,Planner 模塊會對 Validator 模塊生成的執行計划進行優化。如下圖所示。
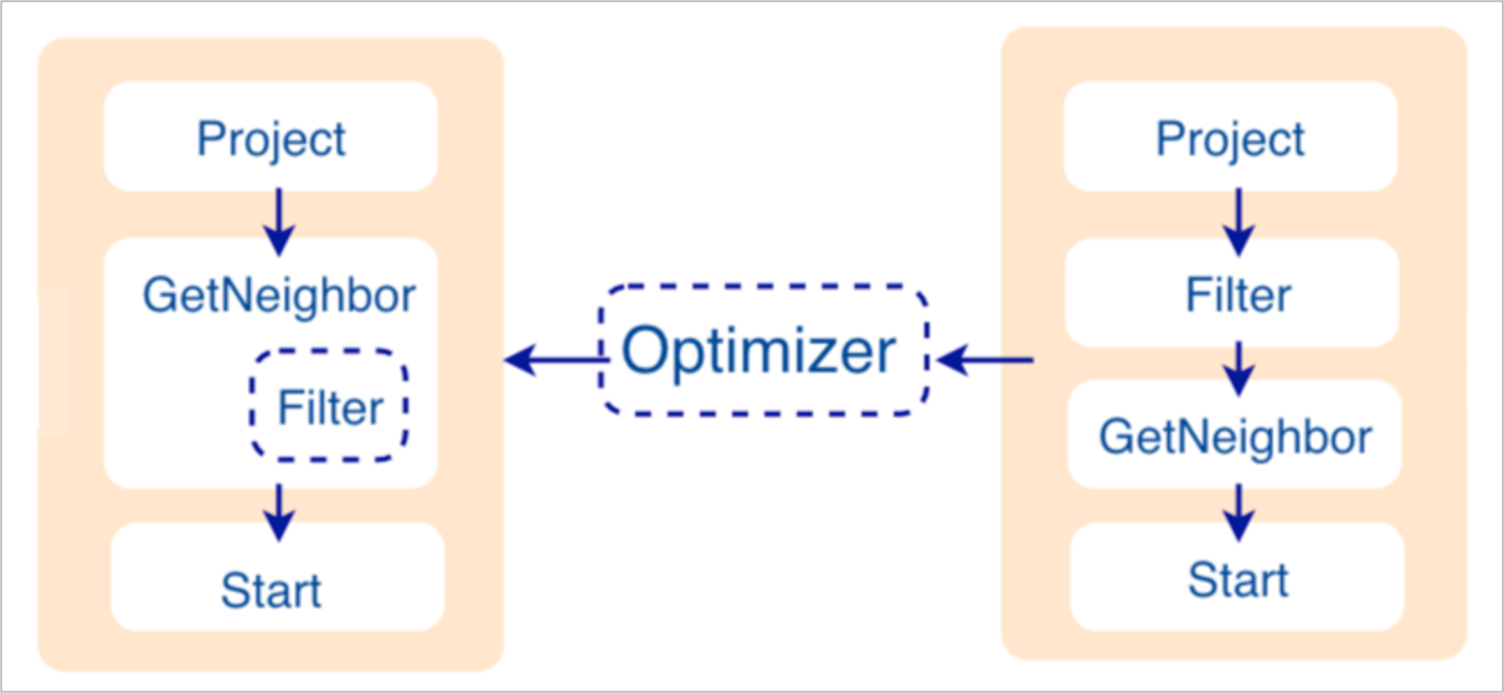
優化前
如上圖右側未優化的執行計劃,每個節點依賴另一個節點,例如根節點 Project 依賴 Filter、Filter 依賴 GetNeighbor,最終找到葉子節點 Start,才能開始執行(並非真正執行)。
在這個過程中,每個節點會有對應的輸入變數和輸出變數,這些變數存儲在一個哈希表中。由於執行計劃不是真正執行,所以哈希表中每個 key 的 value 值都為空(除了 Start 節點,起始數據會存儲在該節點的輸入變數中)。哈希表定義在倉庫 nebula-graph 內的 src/context/ExecutionContext.cpp 中。
例如哈希表的名稱為 ResultMap,在建立 Filter 這個節點時,定義該節點從 ResultMap["GN1"] 中讀取數據,然後將結果存儲在 ResultMap["Filter2"] 中,依次類推,將每個節點的輸入輸出都確定好。
優化過程
Planner 模塊目前的優化方式是 RBO(rule-based optimization),即預定義優化規則,然後對 Validator 模塊生成的預設執行計划進行優化。新的優化規則 CBO(cost-based optimization)正在開發中。優化代碼存儲在倉庫 nebula-graph 的目錄 src/optimizer/ 內。
RBO 是一個自底向上的探索過程,即對於每個規則而言,都會由執行計劃的根節點(示例是Project)開始,一步步向下探索到最底層的節點,在過程中查看是否可以匹配規則。
如上圖所示,探索到節點 Filter 時,發現依賴的節點是 GetNeighbor,匹配預先定義的規則,就會將 Filter 融入到 GetNeighbor 中,然後移除節點 Filter,繼續匹配下一個規則。在執行階段,當運算元 GetNeighbor 調用 Storage 服務的介面獲取一個點的鄰邊時,Storage 服務內部會直接將不符合條件的邊過濾掉,這樣可以極大地減少傳輸的數據量,該優化稱為過濾下推。
Executor
Executor 模塊包含調度器(Scheduler)和執行器(Executor),通過調度器調度執行計劃,讓執行器根據執行計劃生成對應的執行運算元,從葉子節點開始執行,直到根節點結束。如下圖所示。
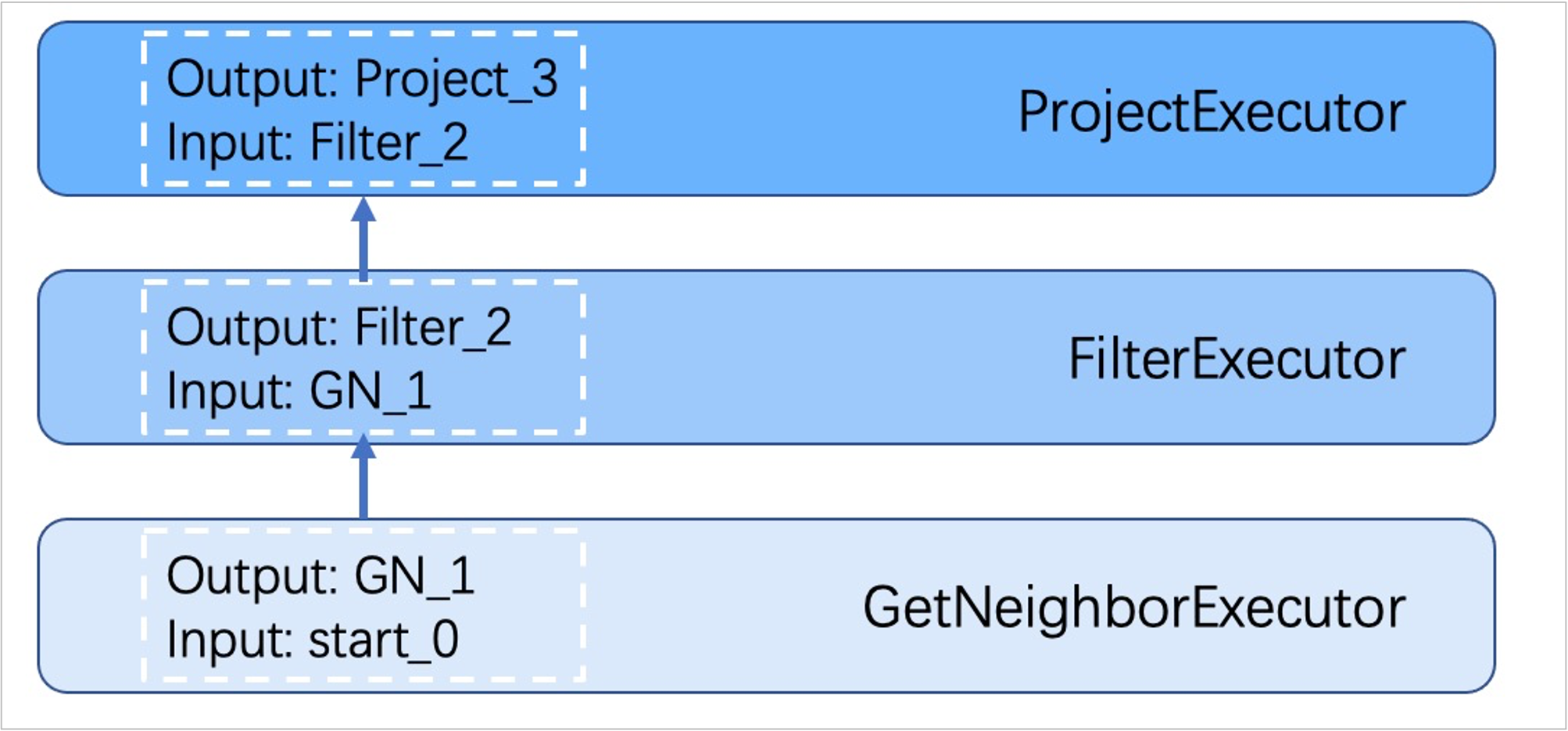
每一個執行計劃節點都一一對應一個執行運算元,節點的輸入輸出在優化執行計劃時已經確定,每個運算元只需要拿到輸入變數中的值進行計算,最後將計算結果放入對應的輸出變數中即可,所以只需要從節點 Start 一步步執行,最後一個運算元的輸出變數會作為最終結果返回給客戶端。
代碼結構
Nebula Graph 的代碼層次結構如下:
|--src
|--context //校驗期和執行期上下文
|--daemons
|--executor //執行運算元
|--mock
|--optimizer //優化規則
|--parser //詞法語法分析
|--planner //執行計劃結構
|--scheduler //調度器
|--service
|--util //基礎組件
|--validator //語句校驗
|--visitor
Storage服務
Nebula Graph 的存儲包含兩個部分,一個是 Meta 相關的存儲,稱為 Meta 服務,在前文已有介紹。
另一個是具體數據相關的存儲,稱為 Storage 服務。其運行在 nebula-storaged 進程中。本文僅介紹 Storage 服務的架構設計。
優勢
- 高性能(自研 KVStore)
- 易水平擴展(Shared-nothing 架構,不依賴 NAS 等硬體設備)
- 強一致性(Raft)
- 高可用性(Raft)
- 支持向第三方系統進行同步(例如全文索引)
Storage 服務架構
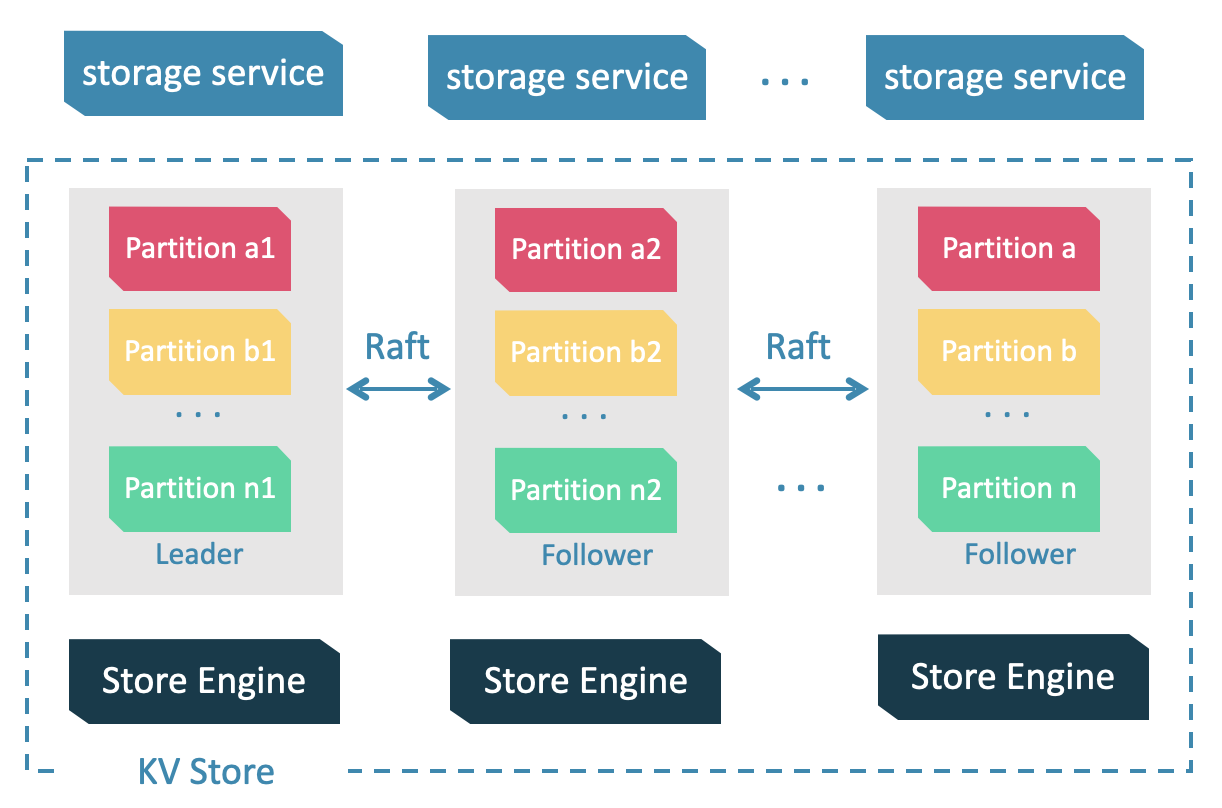
Storage 服務是由 nebula-storaged 進程提供的,用戶可以根據場景配置 nebula-storaged 進程數量,例如測試環境 1 個,生產環境 3 個。
所有 nebula-storaged 進程構成了基於 Raft 協議的集群,整個服務架構可以分為三層,從上到下依次為:
Storage interface 層
Storage 服務的最上層,定義了一系列和圖相關的 API。API 請求會在這一層被翻譯成一組針對分片的 KV 操作,例如:
- getNeighbors:查詢一批點的出邊或者入邊,返回邊以及對應的屬性,並且支持條件過濾。
- insert vertex/edge:插入一條點或者邊及其屬性。
- getProps:獲取一個點或者一條邊的屬性。
正是這一層的存在,使得 Storage 服務變成了真正的圖存儲,否則 Storage 服務只是一個 KV 存儲服務。
Consensus 層
Storage 服務的中間層,實現了 Multi Group Raft,保證強一致性和高可用性。
Store Engine 層
Storage 服務的最底層,是一個單機版本地存儲引擎,提供對本地數據的get、put、scan等操作。相關介面存儲在KVStore.h和KVEngine.h文件,用戶可以根據業務需求定製開發相關的本地存儲插件。
KVStore
Nebula Graph 使用自行開發的 KVStore,而不是其他開源 KVStore,原因如下:
- 需要高性能 KVStore。
- 需要以庫的形式提供,實現高效計算下推。對於強 Schema 的 Nebula Graph 來說,計算下推時如何提供 Schema 信息,是高效的關鍵。
- 需要數據強一致性。
基於上述原因,Nebula Graph 使用 RocksDB 作為本地存儲引擎,實現了自己的 KVStore,有如下優勢:
- 對於多硬碟機器,Nebula Graph 只需配置多個不同的數據目錄即可充分利用多硬碟的併發能力。
- 由 Meta 服務統一管理所有 Storage 服務,可以根據所有分片的分佈情況和狀態,手動進行負載均衡。
- 定製預寫日誌(WAL),每個分片都有自己的 WAL。
- 支持多個圖空間,不同圖空間相互隔離,每個圖空間可以設置自己的分片數和副本數。
數據存儲格式
圖存儲的主要數據是點和邊,Nebula Graph 將點和邊的信息存儲為 key,同時將點和邊的屬性信息存儲在 value 中,以便更高效地使用屬性過濾。
點數據存儲格式
相比 Nebula Graph 2.x 版本,3.x 版本的每個點多了一個不含 TagID 欄位並且無 value 的 key,用於支持無 Tag 的點。
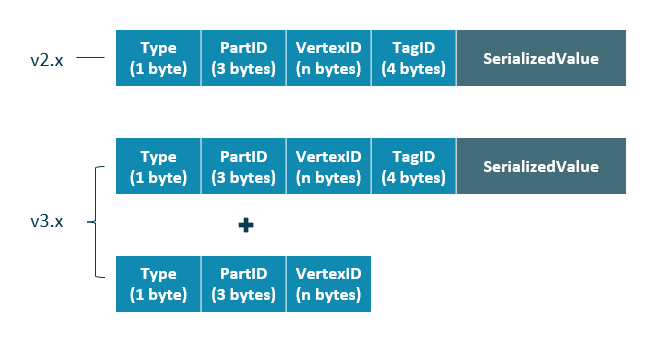
| 欄位 | 說明 |
|---|---|
| Type | key 類型。長度為 1 位元組。 |
| PartID | 數據分片編號。長度為 3 位元組。此欄位主要用於 Storage 負載均衡(balance)時方便根據首碼掃描整個分片的數據。 |
| VertexID | 點 ID。當點 ID 類型為 int 時,長度為 8 位元組;當點 ID 類型為 string 時,長度為創建圖空間時指定的fixed_string長度。 |
| TagID | 點關聯的 Tag ID。長度為 4 位元組。 |
| SerializedValue | 序列化的 value,用於保存點的屬性信息。 |
邊數據存儲格式

| 欄位 | 說明 |
|---|---|
| Type | key 類型。長度為 1 位元組。 |
| PartID | 數據分片編號。長度為 3 位元組。此欄位主要用於 Storage 負載均衡(balance)時方便根據首碼掃描整個分片的數據。 |
| VertexID | 點 ID。前一個VertexID在出邊里表示起始點 ID,在入邊里表示目的點 ID;後一個VertexID出邊里表示目的點 ID,在入邊里表示起始點 ID。 |
| Edge | type 邊的類型。大於 0 表示出邊,小於 0 表示入邊。長度為 4 位元組。 |
| Rank | 用來處理兩點之間有多個同類型邊的情況。用戶可以根據自己的需求進行設置,例如存放交易時間、交易流水號等。長度為 8 位元組, |
| PlaceHolder | 預留欄位。長度為 1 位元組。 |
| SerializedValue | 序列化的 value,用於保存邊的屬性信息。 |
屬性說明
Nebula Graph 使用強類型 Schema。
對於點或邊的屬性信息,Nebula Graph 會將屬性信息編碼後按順序存儲。由於屬性的長度是固定的,查詢時可以根據偏移量快速查詢。在解碼之前,需要先從 Meta 服務中查詢具體的 Schema 信息(並緩存)。同時為了支持線上變更 Schema,在編碼屬性時,會加入對應的 Schema 版本信息。
數據分片
由於超大規模關係網路的節點數量高達百億到千億,而邊的數量更會高達萬億,即使僅存儲點和邊兩者也遠大於一般伺服器的容量。因此需要有方法將圖元素切割,並存儲在不同邏輯分片(Partition)上。Nebula Graph 採用邊分割的方式。
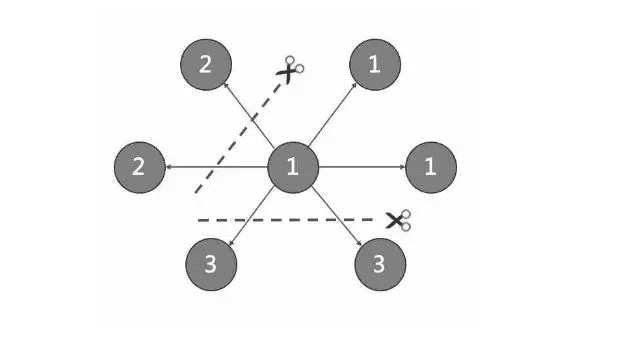
切邊與存儲放大
Nebula Graph 中邏輯上的一條邊對應著硬碟上的兩個鍵值對(key-value pair),在邊的數量和屬性較多時,存儲放大現象較明顯。邊的存儲方式如下圖所示。
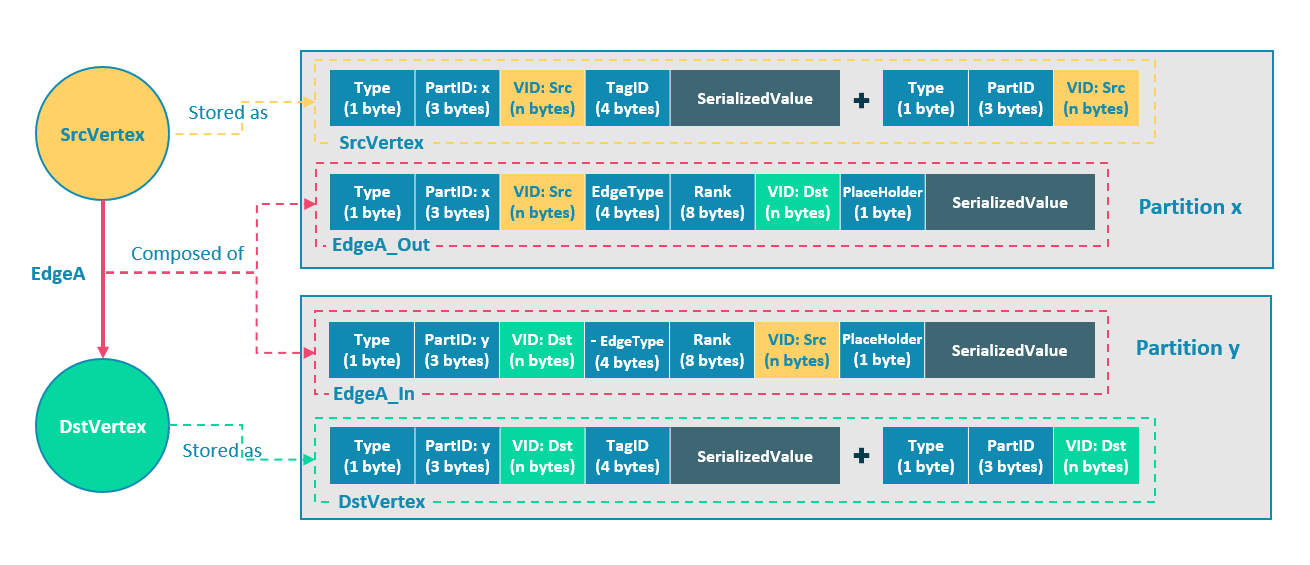
上圖以最簡單的兩個點和一條邊為例,起點 SrcVertex 通過邊 EdgeA 連接目的點 DstVertex,形成路徑(SrcVertex)-[EdgeA]->(DstVertex)。這兩個點和一條邊會以 6 個鍵值對的形式保存在存儲層的兩個不同分片,即 Partition x 和 Partition y 中,詳細說明如下:
- 點 SrcVertex 的鍵值保存在 Partition x 中。
- 邊 EdgeA 的第一份鍵值,這裡用 EdgeA_Out 表示,與 SrcVertex 一同保存在 Partition x 中。key 的欄位有 Type、PartID(x)、VID(Src,即點 SrcVertex 的 ID)、EdgeType(符號為正,代表邊方向為出)、Rank(0)、VID(Dst,即點 DstVertex 的 ID)和 PlaceHolder。SerializedValue 即 Value,是序列化的邊屬性。
- 點 DstVertex 的鍵值保存在 Partition y 中。
- 邊 EdgeA 的第二份鍵值,這裡用 EdgeA_In 表示,與 DstVertex 一同保存在 Partition y 中。key 的欄位有 Type、PartID(y)、VID(Dst,即點 DstVertex 的 ID)、EdgeType(符號為負,代表邊方向為入)、Rank(0)、VID(Src,即點 SrcVertex 的 ID)和 PlaceHolder。SerializedValue 即 Value,是序列化的邊屬性,與 EdgeA_Out 中該部分的完全相同。
EdgeA_Out 和 EdgeA_In 以方向相反的兩條邊的形式存在於存儲層,二者組合成了邏輯上的一條邊 EdgeA。EdgeA_Out 用於從起點開始的遍歷請求,例如(a)-[]->();EdgeA_In 用於指向目的點的遍歷請求,或者說從目的點開始,沿著邊的方向逆序進行的遍歷請求,例如例如()-[]->(a)。
如 EdgeA_Out 和 EdgeA_In 一樣,Nebula Graph 冗餘了存儲每條邊的信息,導致存儲邊所需的實際空間翻倍。因為邊對應的 key 占用的硬碟空間較小,但 value 占用的空間與屬性值的長度和數量成正比,所以,當邊的屬性值較大或數量較多時候,硬碟空間占用量會比較大。
如果對邊進行操作,為了保證兩個鍵值對的最終一致性,可以開啟 TOSS 功能,開啟後,會先在正向邊所在的分片進行操作,然後在反向邊所在分片進行操作,最後返回結果。
分片演算法
分片策略採用靜態 Hash 的方式,即對點 VID 進行取模操作,同一個點的所有 Tag、出邊和入邊信息都會存儲到同一個分片,這種方式極大地提升了查詢效率。
創建圖空間時需指定分片數量,分片數量設置後無法修改,建議設置時提前滿足業務將來的擴容需求。
多機集群部署時,分片分佈在集群內的不同機器上。分片數量在 CREATE SPACE 語句中指定,此後不可更改。
如果需要將某些點放置在相同的分片(例如在一臺機器上),可以參考公式或代碼。
下文用簡單代碼說明 VID 和分片的關係。
// 如果 ID 長度為 8,為了相容 1.0,將數據類型視為 int64。
uint64_t vid = 0;
if (id.size() == 8) {
memcpy(static_cast<void*>(&vid), id.data(), 8);
} else {
MurmurHash2 hash;
vid = hash(id.data());
}
PartitionID pId = vid % numParts + 1;
簡單來說,上述代碼是將一個固定的字元串進行哈希計算,轉換成數據類型為 int64 的數字(int64 數字的哈希計算結果是數字本身),將數字取模,然後加 1,即:
pId = vid % numParts + 1;
示例的部分參數說明如下。
| 參數 | 說明 |
|---|---|
| % | 取模運算。 |
| numParts | VID所在圖空間的分片數,即 CREATE SPACE 語句中的partition_num值。 |
| pId | VID所在分片的 ID。 |
例如有 100 個分片,VID為 1、101 和 1001 的三個點將會存儲在相同的分片。分片 ID 和機器地址之間的映射是隨機的,所以不能假定任何兩個分片位於同一臺機器上。
Raft
關於 Raft 的簡單介紹
分散式系統中,同一份數據通常會有多個副本,這樣即使少數副本發生故障,系統仍可正常運行。這就需要一定的技術手段來保證多個副本之間的一致性。
基本原理:Raft 就是一種用於保證多副本一致性的協議。Raft 採用多個副本之間競選的方式,贏得”超過半數”副本投票的(候選)副本成為 Leader,由 Leader 代表所有副本對外提供服務;其他 Follower 作為備份。當該 Leader 出現異常後(通信故障、運維命令等),其餘 Follower 進行新一輪選舉,投票出一個新的 Leader。Leader 和 Follower 之間通過心跳的方式相互探測是否存活,並以 Raft-wal 的方式寫入硬碟,超過多個心跳仍無響應的副本會認為發生故障。
因為 Raft-wal 需要定期寫硬碟,如果硬碟寫能力瓶頸會導致 Raft 心跳失敗,導致重新發起選舉。硬碟 IO 嚴重堵塞情況下,會導致長期無法選舉出 Leader。
讀寫流程:對於客戶端的每個寫入請求,Leader 會將該寫入以 Raft-wal 的方式,將該條同步給其他 Follower,並只有在“超過半數”副本都成功收到 Raft-wal 後,才會返回客戶端該寫入成功。對於客戶端的每個讀取請求,都直接訪問 Leader,而 Follower 並不參與讀請求服務。
故障流程:場景 1:考慮一個配置為單副本(圖空間)的集群;如果系統只有一個副本時,其自身就是 Leader;如果其發生故障,系統將完全不可用。場景 2:考慮一個配置為 3 副本(圖空間)的集群;如果系統有 3 個副本,其中一個副本是 Leader,其他 2 個副本是 Follower;即使原 Leader 發生故障,剩下兩個副本仍可投票出一個新的 Leader(以及一個 Follower),此時系統仍可使用;但是當這 2 個副本中任一者再次發生故障後,由於投票人數不足,系統將完全不可用。
Raft 多副本的方式與 HDFS 多副本的方式是不同的,Raft 基於“多數派”投票,因此副本數量不能是偶數。
Multi Group Raft
由於 Storage 服務需要支持集群分散式架構,所以基於 Raft 協議實現了 Multi Group Raft,即每個分片的所有副本共同組成一個 Raft group,其中一個副本是 leader,其他副本是 follower,從而實現強一致性和高可用性。Raft 的部分實現如下。
由於 Raft 日誌不允許空洞,Nebula Graph 使用 Multi Group Raft 緩解此問題,分片數量較多時,可以有效提高 Nebula Graph 的性能。但是分片數量太多會增加開銷,例如 Raft group 內部存儲的狀態信息、WAL 文件,或者負載過低時的批量操作。
實現 Multi Group Raft 有 2 個關鍵點:
- 共用 Transport 層
每一個 Raft group 內部都需要向對應的 peer 發送消息,如果不能共用 Transport 層,會導致連接的開銷巨大。
- 共用線程池
如果不共用一組線程池,會造成系統的線程數過多,導致大量的上下文切換開銷。
批量(Batch)操作
Nebula Graph 中,每個分片都是串列寫日誌,為了提高吞吐,寫日誌時需要做批量操作,但是由於 Nebula Graph 利用 WAL 實現一些特殊功能,需要對批量操作進行分組,這是 Nebula Graph 的特色。
例如無鎖 CAS 操作需要之前的 WAL 全部提交後才能執行,如果一個批量寫入的 WAL 里包含了 CAS 類型的 WAL,就需要拆分成粒度更小的幾個組,還要保證這幾組 WAL 串列提交。
leader 切換(Transfer Leadership)
leader 切換對於負載均衡至關重要,當把某個分片從一臺機器遷移到另一臺機器時,首先會檢查分片是不是 leader,如果是的話,需要先切換 leader,數據遷移完畢之後,通常還要重新均衡 leader 分佈。
對於 leader 來說,提交 leader 切換命令時,就會放棄自己的 leader 身份,當 follower 收到 leader 切換命令時,就會發起選舉。
成員變更
為了避免腦裂,當一個 Raft group 的成員發生變化時,需要有一個中間狀態,該狀態下新舊 group 的多數派需要有重疊的部分,這樣就防止了新的 group 或舊的 group 單方面做出決定。為了更加簡化,Diego Ongaro 在自己的博士論文中提出每次只增減一個 peer 的方式,以保證新舊 group 的多數派總是有重疊。Nebula Graph 也採用了這個方式,只不過增加成員和移除成員的實現有所區別。具體實現方式請參見 Raft Part class 里 addPeer/removePeer 的實現。
與 HDFS 的區別
Storage 服務基於 Raft 協議實現的分散式架構,與 HDFS 的分散式架構有一些區別。例如:
- Storage 服務本身通過 Raft 協議保證一致性,副本數量通常為奇數,方便進行選舉 leader,而 HDFS 存儲具體數據的 DataNode 需要通過 NameNode 保證一致性,對副本數量沒有要求。
- Storage 服務只有 leader 副本提供讀寫服務,而 HDFS 的所有副本都可以提供讀寫服務。
- Storage 服務無法修改副本數量,只能在創建圖空間時指定副本數量,而 HDFS 可以調整副本數量。
- Storage 服務是直接訪問文件系統,而 HDFS 的上層(例如 HBase)需要先訪問 HDFS,再訪問到文件系統,遠程過程調用(RPC)次數更多。
總而言之,Storage 服務更加輕量級,精簡了一些功能,架構沒有 HDFS 複雜,可以有效提高小塊存儲的讀寫性能。
參考文章
文章收錄於 GitHub倉庫JavaDeveloperBrain [Java工程師必備+學習+知識點+面試]:包含電腦網路知識、JavaSE、JVM、Spring、Springboot、SpringCloud、Mybatis、多線程併發、netty、MySQL、MongoDB、Elasticsearch、Redis、HBASE、RabbitMQ、RocketMQ、Pulsar、Kafka、Zookeeper、Linux、設計模式、智力題、項目架構、分散式相關、演算法、面試題

