背景 由於是公司項目,所以不方便給出代碼或者視頻,只能列一些自己畫的流程圖。 大致情況如上,前端有7個顯示區。在對其進行滾動翻頁的時候,存在以下問題: 1. 連續滾輪翻頁,每次所有顯示區刷新完,進行下一次翻頁用時較久。(說人話就是,平均耗時翻頁時間長) 2. 連續滾輪翻頁,會出現一下子翻不動,然後連 ...
背景
由於是公司項目,所以不方便給出代碼或者視頻,只能列一些自己畫的流程圖。

大致情況如上,前端有7個顯示區。在對其進行滾動翻頁的時候,存在以下問題:
1. 連續滾輪翻頁,每次所有顯示區刷新完,進行下一次翻頁用時較久。(說人話就是,平均耗時翻頁時間長)
2. 連續滾輪翻頁,會出現一下子翻不動,然後連續刷新很多層的情況。且有的顯示區更新快,有的層更新更新很慢。
分析
通過分析代碼,調查log發現,翻頁切換平均耗時在600ms。其主要的業務邏輯如下:
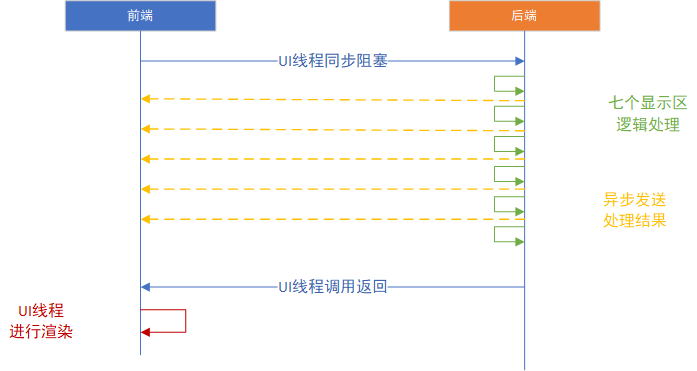
1.前端線程發送同步翻頁命令給後端
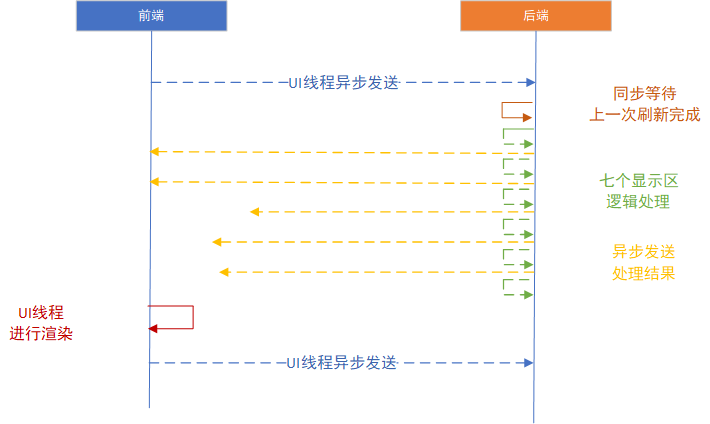
2.後端進行處理,共7個顯示區。前三個每個耗時30ms左右,後4個業務處理平均需要100ms。在後端處理過程中,已完成的場景數據,已經非同步發送給前端。
3.前端等到後端處理完數據,根據接收數據,進行前端繪製,耗時110ms左右。
問題
主要問題有三個:
1.後端處理邏輯耗時太長了,特別是後4個場景。
2.前端等到後端邏輯處理完,才可以UI渲染,中間白白等待,耗時過長
3.在前端連續翻頁情況下,有可能出現,第一次翻頁的場景還沒渲染完(只渲染了幾個區域,或者一個都沒有),就開始發送下一次渲染。造成“卡很久,然後一下次渲染好幾幀的現象”。
解決
優化有3點:
1.以空間換時間。把耗時的即時計算操作,提前計算好,存儲在記憶體中。那麼在翻頁過程中,就只是拷貝數據。
2.將圖像刷新從同步改成非同步。
2.1前端發送命令變成非同步(這裡最初同步是有一些業務需求,需要改造)
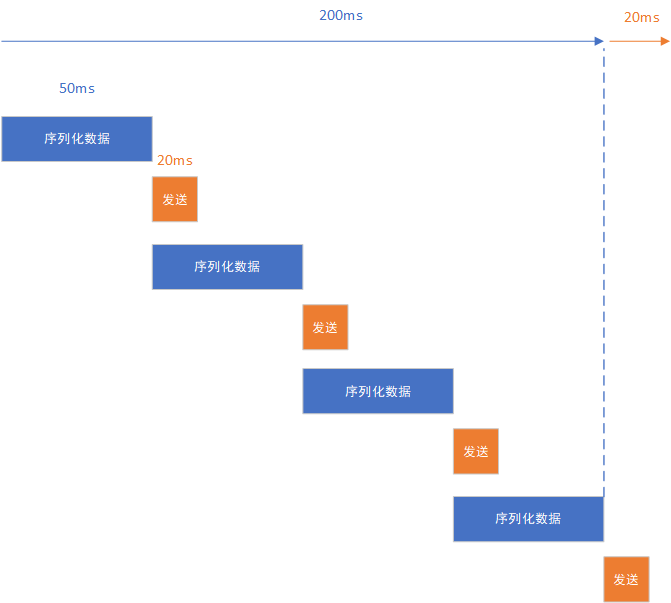
2.2我們的後端框架的刷新邏輯由兩部分組成:數據序列化+發送。如果採用同步,後面4個場景的序列化的總時間,大概需要200ms。如下圖所示。如果採用非同步,那前端阻塞的時間,就幾乎可以忽略不急
3.同步機制
前兩點優化以後,翻頁速度非常快。主要耗時只在後端序列化+發送數據+前端處理,可以達到200ms左右一次翻頁。但存在非同步刷新的問題。具體情況如下:
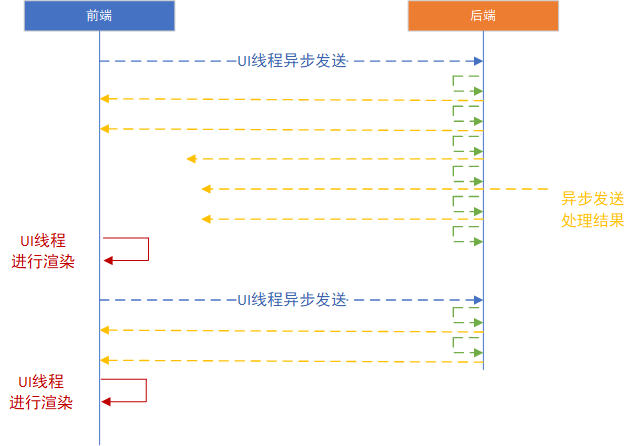
1.第一次翻頁後,後端發送給前端數據,前端還只收到前兩個場景的數據,並渲染。
2.前端收到翻頁指令,接著發送翻頁。後端發送7個場景,因為前幾個場景,數據少,很快又發到了前端。
3.前端渲染第二次翻頁的前幾個數據
4.前端渲染第一次和第二次的剩餘數據。
解決:
後端在收到翻頁指令以後,先等待自己上一次所有場景都刷新完,再接著序列化、發送。這樣前端數據就能最大程度的進行渲染了,不會出現錯位。
總結
最後的流程圖如下,從最初600ms左右延遲的卡頓翻頁,如今變成200ms左右的穩定翻頁,優化效果非常不錯。