
氣泡圖是一種多變數的統計圖表,可以看作是散點圖的變形。與散點圖不同的是,每一個氣泡都表示三個維度的數據,除了像散點圖一樣有X,Y軸,氣泡的大小可以表示另一個維度的數據。例如,x軸表示產品銷量,y軸表示產品利潤,氣泡大小代表產品市場份額百分比。 它可以幫助我們發現變數之間的模式、趨勢和異常值。通過氣泡 ...
氣泡圖是一種多變數的統計圖表,可以看作是散點圖的變形。
與散點圖不同的是,每一個氣泡都表示三個維度的數據,除了像散點圖一樣有X,Y軸,氣泡的大小可以表示另一個維度的數據。
例如,x軸表示產品銷量,y軸表示產品利潤,氣泡大小代表產品市場份額百分比。
它可以幫助我們發現變數之間的模式、趨勢和異常值。
通過氣泡的大小和顏色,我們可以同時比較多個變數的值,並且可以快速識別出具有較大或較小數值的數據點。
1. 主要元素
氣泡圖通常用於展示和比較數據之間的關係和分佈,可以展示三維(X,Y軸,氣泡大小),甚至四維數據(X,Y軸,氣泡大小,氣泡顏色)之間的關係。
它的主要元素包括:
- 橫軸和縱軸:氣泡圖通常使用橫軸和縱軸來表示兩個變數的值。這些變數可以是數值型、分類型或時間型。
- 氣泡大小:氣泡圖通過氣泡的大小來表示第三個變數的值。通常,氣泡的大小與該變數的值成正比,較大的氣泡表示較大的數值。
- 氣泡顏色:氣泡圖還可以使用顏色來表示第四個變數的值。不同的顏色可以用於區分不同的數據類別或者表示不同的數值範圍。

2. 適用的場景
氣泡圖適用的分析場景包括:
- 多變數關係分析:氣通過橫軸、縱軸和氣泡大小,可以同時呈現三個變數的信息,幫助我們發現變數之間的模式、趨勢和相關性。
- 數據聚類和分類:氣泡顏色可以用於區分不同的數據類別或者表示不同的數值範圍。這使得氣泡圖在數據聚類和分類分析中非常有用,可以幫助我們識別出不同群組或類別之間的差異和相似性。
- 比較分析:用於比較不同類別或不同時間點的數據。通過氣泡的大小和顏色,我們可以直觀地比較多個變數的值,快速識別出具有較大或較小數值的數據點,從而幫助我們理解數據的分佈和變化情況。
- 異常值檢測:幫助我們快速識別出具有異常數值的數據點。通過比較氣泡的大小和顏色,我們可以發現與其他數據點相比具有明顯不同數值的數據,從而幫助我們識別和分析異常情況。
3. 不適用的場景
氣泡圖在以下情況可能不適用:
- 大數據集:當數據集非常龐大時,氣泡圖可能不適合展示所有數據點,因為過多的氣泡可能會導致圖表混亂不清。
- 單變數分析:如果只需要分析單個變數的分佈或趨勢,氣泡圖可能過於複雜,不是最佳選擇。
- 離散數據:如果數據是離散的,而不是連續的數值型數據,氣泡圖可能無法有效地展示變數之間的關係。
4. 分析實戰
本次使用氣泡圖分析 2021年中歐之間的貿易數據情況。
氣泡圖可以分析三個維度的對比:
- 進口額:橫軸
- 出口額:縱軸
- 進出口總額:氣泡大小
4.1. 數據來源
數據來源國家統計局公開的數據,整理好的數據可從下麵的地址下載:
https://databook.top/nation/A06
用到的三個統計數據分別是:
- 中國同歐洲各國(地區)進出口總額:
A06050103.csv - 中國向歐洲各國(地區)出口總額:
A06050203.csv - 中國從歐洲各國(地區)進口總額:
A06050303.csv
fp = "d:/share/data/A06050103.csv"
df_total = pd.read_csv(fp)
fp = "d:/share/data/A06050203.csv"
df_output = pd.read_csv(fp)
fp = "d:/share/data/A06050303.csv"
df_input = pd.read_csv(fp)
4.2. 數據清理
數據清理步驟主要包括:
- 提取每個文件中2021年的數據
- 去除中歐整體的交易額數據,只保留和各個國家之間的貿易數據
- 合併進出口總額,進口額,出口額到一個數據集中
- 過濾多餘字元,生成一個表示國家的數據列
#提取每個文件中2021年的數據
df = df_total[df_total["sj"] == 2021]
#去除中歐整體的交易額數據,只保留和各個國家之間的貿易數據
data = df.loc[2:, ["zbCN", "value"]]
#重新映射列的名稱
data = data.rename(columns={"zbCN":"country", "value": "total"})
#過濾多餘字元,生成一個表示國家的數據列
data["country"] = data["country"].str.replace("中國同", "", regex=False)
data["country"] = data["country"].str.replace("進出口總額(萬美元)", "", regex=False)
df = df_input[df_input["sj"] == 2021]
#合併進出口總額,進口額,出口額到一個數據集中
data["input"] = df.loc[2:, ["value"]]
df = df_output[df_output["sj"] == 2021]
#合併進出口總額,進口額,出口額到一個數據集中
data["output"] = df.loc[2:, ["value"]]
data.head(5)
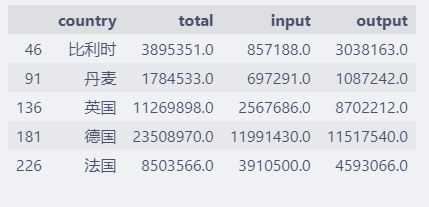
和歐洲的總體交易數據位於每個數據集的第一行,所用用 loc[2:, ...] 來過濾。
4.3. 分析結果可視化
with plt.style.context("seaborn-v0_8"):
fig = plt.figure()
ax = fig.add_axes([0.1, 0.1, 0.8, 0.8])
ax.scatter(
data["input"] / 10000,
data["output"] / 10000,
data["total"] / 10000,
c = np.random.rand(len(data)),
cmap="Accent",
alpha=0.6,
)
ax.set_xlabel("進口額(億元)")
ax.set_ylabel("出口額(億元)")
x = np.linspace(0, 1400, 7)
y = x
ax.plot(x, y, '-')
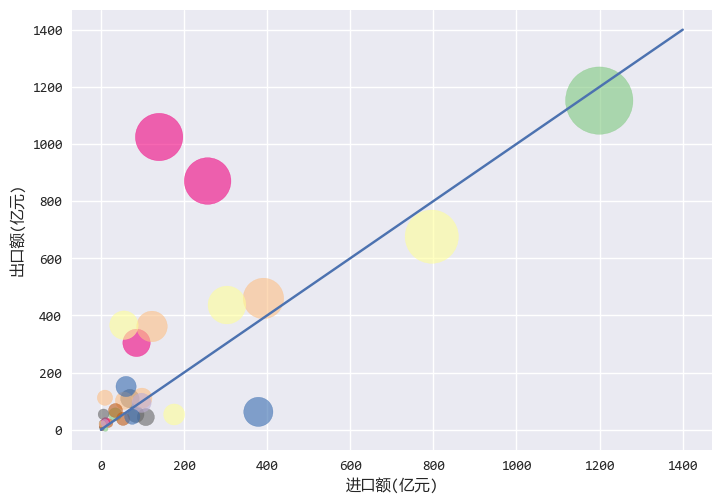
從圖中可以看出:
橫軸是進口額,縱軸是出口額,氣泡越大,進出口總額越大。
中間的藍色線表示進出口額度一樣,可以看出,大部分國家都在藍色線之上,
說明我國和大部分歐洲的貿易都是順差。
左下角有很多小氣泡,說明和大部分國家之間的進出口貿易額不高,也許是歐洲的小國家很多的緣故。


