
1 概覽 DataX 是一個異構數據源離線同步工具,致力於實現包括關係型資料庫(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各種異構數據源之間穩定高效的數據同步功能。 1.1 設計理念 為瞭解決異構數據源同步問題,DataX將複雜的網狀的同步鏈路變成了星型數據鏈路 ...
1 概覽
DataX 是一個異構數據源離線同步工具,致力於實現包括關係型資料庫(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各種異構數據源之間穩定高效的數據同步功能。
1.1 設計理念
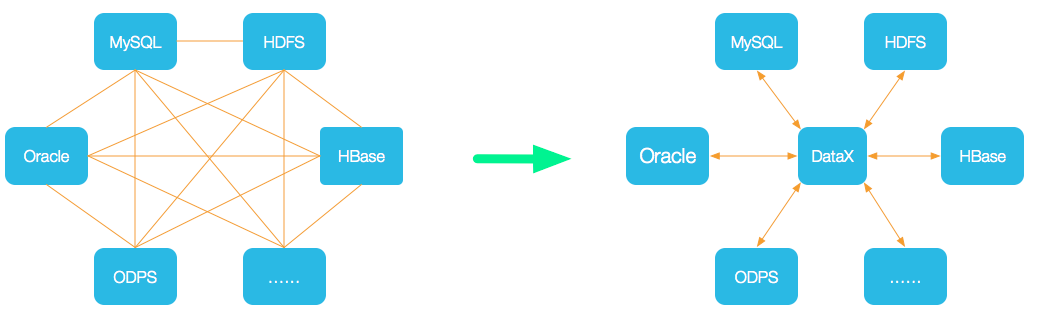
為瞭解決異構數據源同步問題,DataX將複雜的網狀的同步鏈路變成了星型數據鏈路,DataX作為中間傳輸載體負責連接各種數據源。
當需要接入一個新的數據源的時候,只需要將此數據源對接到DataX,便能跟已有的數據源做到無縫數據同步。
1.2 當前使用現狀
DataX在阿裡巴巴集團內被廣泛使用,承擔了所有大數據的離線同步業務,並已持續穩定運行了6年之久。目前每天完成同步8w多道作業,每日傳輸數據量超過300TB。
此前已經開源DataX1.0版本,此次介紹為阿裡雲開源全新版本DataX3.0,有了更多更強大的功能和更好的使用體驗。
2 框架設計

作為離線數據同步框架,採用Framework + plugin架構。將數據源讀取、寫入抽象成為Reader/Writer插件,納入到整個同步框架:
- Reader:數據採集模塊,採集數據源的數據,將數據發送給Framework
- Writer: 數據寫入模塊,不斷向Framework取數據,並將數據寫入到目的端
- Framework:連接reader和writer,作為兩者的數據傳輸通道,並處理緩衝,流控,併發,數據轉換等核心技術
3 插件體系
主流RDBMS資料庫、NOSQL、大數據計算系統都已接入。DataX目前支持:
| 類型 | 數據源 | Reader(讀) | Writer(寫) | 文檔 |
|---|---|---|---|---|
| RDBMS 關係型資料庫 | MySQL | √ | √ | 讀 、寫 |
| Oracle | √ | √ | 讀 、寫 | |
| OceanBase | √ | √ | 讀 、寫 | |
| SQLServer | √ | √ | 讀 、寫 | |
| PostgreSQL | √ | √ | 讀 、寫 | |
| DRDS | √ | √ | 讀 、寫 | |
| 達夢 | √ | √ | 讀 、寫 | |
| 通用RDBMS(支持所有關係型資料庫) | √ | √ | 讀 、寫 | |
| 阿裡雲數倉數據存儲 | ODPS | √ | √ | 讀 、寫 |
| ADS | √ | 寫 | ||
| OSS | √ | √ | 讀 、寫 | |
| OCS | √ | √ | 讀 、寫 | |
| NoSQL數據存儲 | OTS | √ | √ | 讀 、寫 |
| Hbase0.94 | √ | √ | 讀 、寫 | |
| Hbase1.1 | √ | √ | 讀 、寫 | |
| MongoDB | √ | √ | 讀 、寫 | |
| Hive | √ | √ | 讀 、寫 | |
| 無結構化數據存儲 | TxtFile | √ | √ | 讀 、寫 |
| FTP | √ | √ | 讀 、寫 | |
| HDFS | √ | √ | 讀 、寫 | |
| Elasticsearch | √ | 寫 |
DataX Framework提供了簡單的介面與插件交互,提供簡單的插件接入機制,只需要任意加上一種插件,就能無縫對接其他數據源。
4 核心架構
支持單機多線程模式完成同步作業運行,DataX作業生命周期的時序圖,從整體架構設計非常簡要說明DataX各個模塊相互關係。
4.1 核心模塊
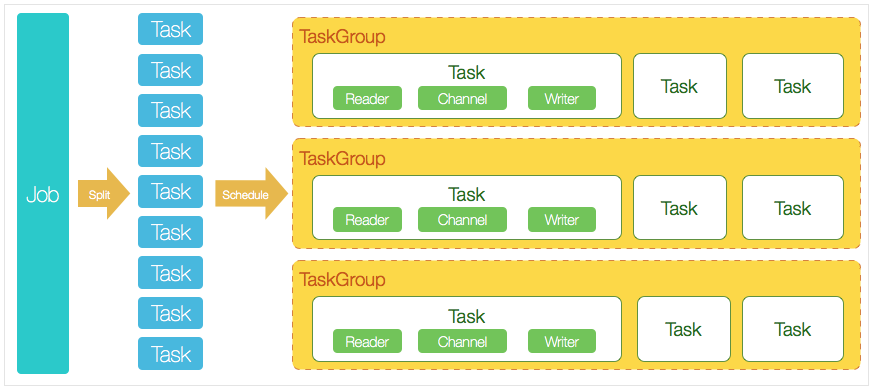
- DataX完成單個數據同步的作業,稱為Job,DataX接受到一個Job後,將啟動一個進程完成整個作業同步過程。DataX Job模塊是單個作業的中樞管理節點,承擔數據清理、子任務切分(將單一作業計算轉化為多個子Task)、TaskGroup管理等功能
- DataXJob啟動後,會根據不同的源端切分策略,將Job切分成多個小的Task(子任務),以便併發執行。Task便是DataX作業的最小單元,每一個Task都會負責一部分數據的同步工作
- 切分多個Task之後,DataX Job會調用Scheduler模塊,根據配置的併發數據量,將拆分成的Task重新組合,組裝成TaskGroup(任務組)。每一個TaskGroup負責以一定的併發運行完畢分配好的所有Task,預設單個任務組的併發數量為5
- 每一個Task都由TaskGroup負責啟動,Task啟動後,會固定啟動Reader—>Channel—>Writer的線程來完成任務同步工作
- DataX作業運行起來之後, Job監控並等待多個TaskGroup模塊任務完成,等待所有TaskGroup任務完成後Job成功退出。否則,異常退出,進程退出值非0
4.2 DataX調度流程
用戶提交一個DataX作業,並配置20個併發,將一個100張分表的mysql數據同步到odps。
DataX調度決策思路:
- DataXJob根據分庫分表切分成100個Task
- 根據20個併發,DataX計算共需分配4個TaskGroup
- 4個TaskGroup平分切分好的100個Task,每個TaskGroup負責以5個併發共計運行25個Task
對比 sqoop

5 核心優勢
5.1 可靠的數據質量監控
-
完美解決數據傳輸個別類型失真問題
DataX舊版對於部分數據類型(比如時間戳)傳輸一直存在毫秒階段等數據失真情況,新版本DataX3.0已經做到支持所有的強數據類型,每一種插件都有自己的數據類型轉換策略,讓數據可以完整無損的傳輸到目的端。
-
提供作業全鏈路的流量、數據量運行時監控
DataX3.0運行過程中可以將作業本身狀態、數據流量、數據速度、執行進度等信息進行全面的展示,讓用戶可以實時瞭解作業狀態。並可在作業執行過程中智能判斷源端和目的端的速度對比情況,給予用戶更多性能排查信息。
-
提供臟數據探測
在大量數據的傳輸過程中,必定會由於各種原因導致很多數據傳輸報錯(比如類型轉換錯誤),這種數據DataX認為就是臟數據。DataX目前可以實現臟數據精確過濾、識別、採集、展示,為用戶提供多種的臟數據處理模式,讓用戶準確把控數據質量大關!
豐富的數據轉換功能
DataX作為一個服務於大數據的ETL工具,除了提供數據快照搬遷功能之外,還提供了豐富數據轉換的功能,讓數據在傳輸過程中可以輕鬆完成數據脫敏,補全,過濾等數據轉換功能,另外還提供了自動groovy函數,讓用戶自定義轉換函數。詳情請看DataX3的transformer詳細介紹。
精準的速度控制
還在為同步過程對線上存儲壓力影響而擔心嗎?新版本DataX3.0提供了包括通道(併發)、記錄流、位元組流三種流控模式,可以隨意控制你的作業速度,讓你的作業在庫可以承受的範圍內達到最佳的同步速度。
"speed": {
"channel": 5,
"byte": 1048576,
"record": 10000
}
強勁的同步性能
DataX3.0每一種讀插件都有一種或多種切分策略,都能將作業合理切分成多個Task並行執行,單機多線程執行模型可以讓DataX速度隨併發成線性增長。在源端和目的端性能都足夠的情況下,單個作業一定可以打滿網卡。另外,DataX團隊對所有的已經接入的插件都做了極致的性能優化,並且做了完整的性能測試。性能測試相關詳情可以參照每單個數據源的詳細介紹:DataX數據源指南
健壯的容錯機制
DataX作業是極易受外部因素的干擾,網路閃斷、數據源不穩定等因素很容易讓同步到一半的作業報錯停止。因此穩定性是DataX的基本要求,在DataX 3.0的設計中,重點完善了框架和插件的穩定性。目前DataX3.0可以做到線程級別、進程級別(暫時未開放)、作業級別多層次局部/全局的重試,保證用戶的作業穩定運行。
-
線程內部重試
DataX的核心插件都經過團隊的全盤review,不同的網路交互方式都有不同的重試策略。
-
線程級別重試
目前DataX已經可以實現TaskFailover,針對於中間失敗的Task,DataX框架可以做到整個Task級別的重新調度。
極簡的使用體驗
易用:下載即可用,支持linux和windows,只需要短短幾步驟就可以完成數據的傳輸。請點擊:Quick Start
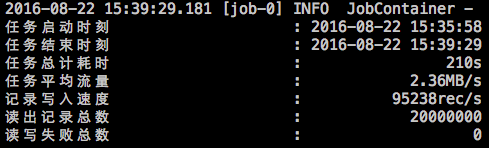
詳細:DataX在運行日誌中列印了大量信息,其中包括傳輸速度,Reader、Writer性能,進程CPU,JVM和GC情況等等。
傳輸過程中列印傳輸速度、進度

傳輸過程中會列印進程相關的CPU、JVM

任務結束後,列印總體運行情況
參考
本文由博客一文多發平臺 OpenWrite 發佈!


