本文分享自華為雲社區《GaussDB(DWS)性能調優:不等值關聯優化》,作者: 門前一棵葡萄樹。 場景1 使用場景:本案例適合滿足以下條件的場景 關聯條件使用OR連接 關聯條件中使用同一列做數據篩選 原始語句 SELECT t2.PARTNER_CHANNEL_CODE AS CHANNEL_ID ...
本文分享自華為雲社區《GaussDB(DWS)性能調優:不等值關聯優化》,作者: 門前一棵葡萄樹。
場景1
使用場景:本案例適合滿足以下條件的場景
- 關聯條件使用OR連接
- 關聯條件中使用同一列做數據篩選
原始語句
SELECT t2.PARTNER_CHANNEL_CODE AS CHANNEL_ID ,t1.COUNTRY_CODE ,t1.BRAND ,t2.CHANNEL_ID AS CHANNEL_ID2 FROM t1 LEFT JOIN t2 ON ( t2.CHANNEL_ID = t1.CHANNEL_ID AND t1.TYPE = 'DR' ) OR ( t2.PARTNER_CHANNEL_CODE = t1.CHANNEL_ID AND t1.TYPE = 'ALL' ) GROUP BY t2.PARTNER_CHANNEL_CODE ,t1.COUNTRY_CODE ,t1.BRAND ,t2.CHANNEL_ID
性能分析
通過查詢計劃分析發現,t1表和t2表關聯走了NEST LOOP,查詢整體耗時45S,NEST LOOP耗時占用整個查詢執行耗時的96%。因此考慮能否通過SQL改寫或HINT規避NEST LOOP。觀察發現t1表和t2表包含兩個關聯關聯條件,兩個關聯條件之間使用OR連接,屬於非等值關聯,因此不能走HASH JOIN。進一步分析SQL發現兩個關聯條件中都使用t1.TYPE進行過濾篩選:
(t2.CHANNEL_ID = t1.CHANNEL_ID AND t1.TYPE='DR') OR (t2.PARTNER_CHANNEL_CODE = t1.CHANNEL_ID AND t1.TYPE='ALL' )
該關聯條件包含以下三種關聯組合:
- t1表中t1.TYPE='DR'的行,只能使用第一個關聯條件與t2表關聯;
- t1表中t1.TYPE='ALL'的行,只能使用第二個關聯條件與t2表關聯;
- t1表中t1.TYPE NOT IN ('ALL','DR')的行,不與t2表關聯,直接補空。
t1表中的一行數據只能選擇這三個關聯條件中的一個與t2表關聯,因此該關聯條件可以改寫為不同關聯條件的UNION ALL(UNION會去重,不等價)。
優化改寫
改寫後SQL如下所示:
SELECT CHANNEL_ID ,COUNTRY_CODE ,BRAND ,CHANNEL_ID FROM ( SELECT t2.PARTNER_CHANNEL_CODE AS CHANNEL_ID ,t1.COUNTRY_CODE ,t1.BRAND ,t2.CHANNEL_ID AS CHANNEL_ID2 FROM t1 LEFT JOIN t2 ON t2.CHANNEL_ID = t1.CHANNEL_ID WHERE t1.TYPE = 'DR' UNION ALL SELECT t2.PARTNER_CHANNEL_CODE AS CHANNEL_ID ,t1.COUNTRY_CODE ,t1.BRAND ,t2.CHANNEL_ID AS CHANNEL_ID2 FROM t1 t2 ON t2.PARTNER_CHANNEL_CODE = t1.CHANNEL_ID WHERE t1.TYPE='ALL' UNION ALL SELECT t2.PARTNER_CHANNEL_CODE AS CHANNEL_ID ,t1.COUNTRY_CODE ,t1.BRAND ,t2.CHANNEL_ID AS CHANNEL_ID2 FROM t1 LEFT JOIN t2 ON FALSE WHERE t1.TYPE NOT IN ('ALL','DR') ) GROUP BY CHANNEL_ID,COUNTRY_CODE,BRAND,CHANNEL_ID
改寫後SQL變為三個子查詢的UNION ALL,執行時間縮減至1s以內,性能優化45倍。
場景二
使用場景:本案例適合滿足以下條件的場景
- 大表A不等值關聯小表B
- B的等值關聯欄位為主鍵
【原始語句】
SELECT T.CREATE_INVOICE_USER, T.PERIOD_ID, T.AP_INVOICE_ID, T.AP_INVOICE_NUM, T.AP_BATCH_NAME, EMP1.EMPLOYEE_NO, EMP1.EMPLOYEE_NAME FROM DWACTDI.DWR_AP_GLOBAL_INVOICE_DETAIL_F_I T LEFT JOIN DWRDIM_DW1.DWR_DIM_EMPLOYEE_D EMP1 ON (EMP1.SCD_ACTIVE_IND = 1 AND(T.CREATE_INVOICE_USER = EMP1.EMPLOYEE_NO OR SUBSTR(T.CREATE_INVOICE_USER, 2) = EMP1.EMPLOYEE_NO))
【性能分析】
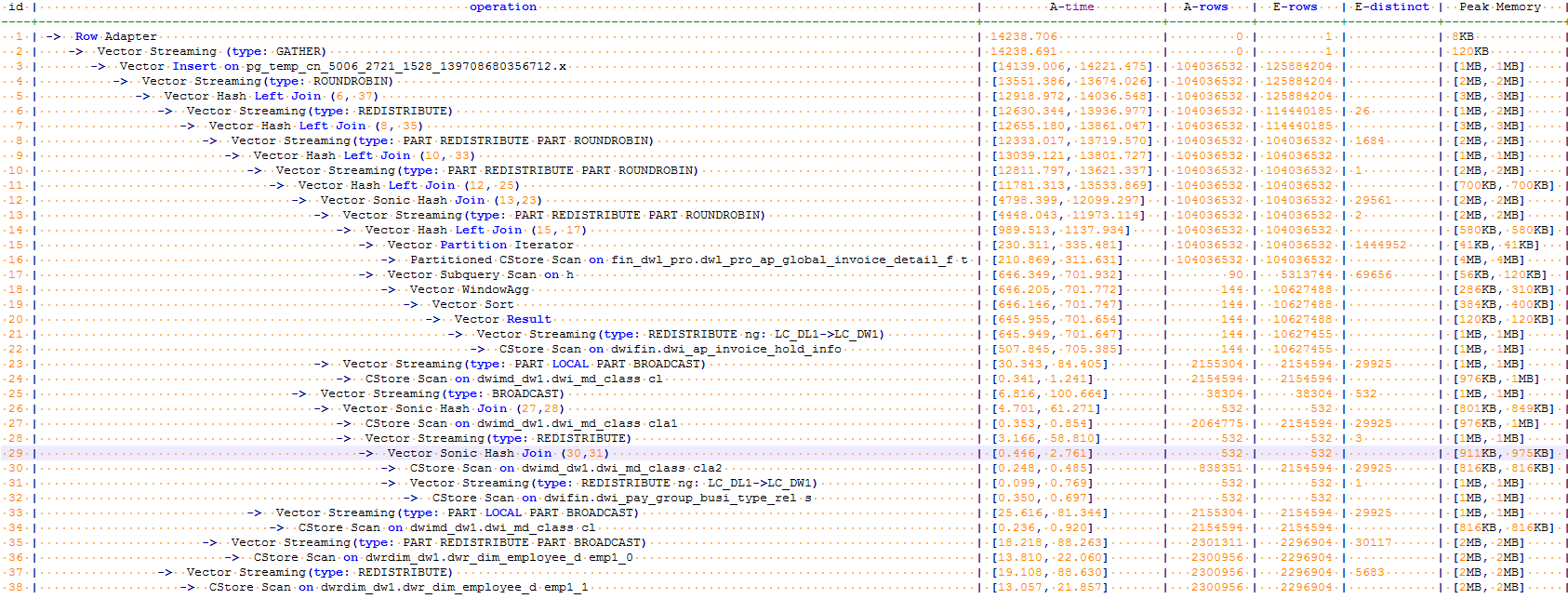
原始語句執行超時(超過1h),執行計劃如下。可以看到執行語句存在大表NestLoop操作
分析發現表dwrdim_dw1.dwr_dim_employee_d是維度表,且關聯列employee_no是主鍵
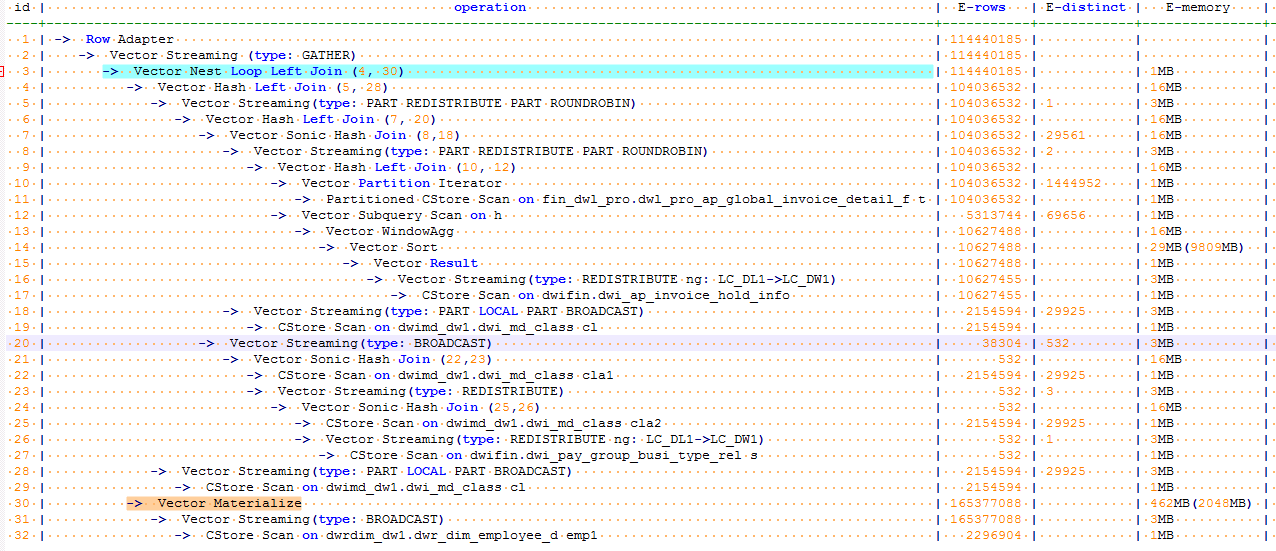
【優化改寫】
SELECT T.CREATE_INVOICE_USER, T.PERIOD_ID, T.AP_INVOICE_ID, T.AP_INVOICE_NUM, T.AP_BATCH_NAME, nvl(EMP1_0.EMPLOYEE_NO, EMP1_1.EMPLOYEE_NO) AS EMPLOYEE_NO, nvl(EMP1_0.EMPLOYEE_NAME, EMP1_1.EMPLOYEE_NAME) AS ERP_ACCOUNTANT_ENAME FROM DWACTDI.DWR_AP_GLOBAL_INVOICE_DETAIL_F_I T LEFT JOIN DWRDIM_DW1.DWR_DIM_EMPLOYEE_D EMP1_0 ON (EMP1_0.SCD_ACTIVE_IND = 1 AND(T.CREATE_INVOICE_USER = EMP1_0.EMPLOYEE_NO)) LEFT JOIN DWRDIM_DW1.DWR_DIM_EMPLOYEE_D EMP1_1 ON (EMP1_1.SCD_ACTIVE_IND = 1 AND(SUBSTR(T.CREATE_INVOICE_USER, 2) = EMP1_1.EMPLOYEE_NO))
改寫後執行信息如下