
如果企業提供 IT 線上服務,那麼可觀測性能力是必不可少的。“可觀測性” 這個詞近來也越發火爆,不懂 “可觀測性” 都不好意思出門了。但是可觀測性能力的構建卻著實不易,每個企業都會用到一堆技術棧來組裝建設。比如數據收集,可能來自某個 exporter,可能來自 telegraf,可能來自 OTEL, ...
如果企業提供 IT 線上服務,那麼可觀測性能力是必不可少的。“可觀測性” 這個詞近來也越發火爆,不懂 “可觀測性” 都不好意思出門了。但是可觀測性能力的構建卻著實不易,每個企業都會用到一堆技術棧來組裝建設。比如數據收集,可能來自某個 exporter,可能來自 telegraf,可能來自 OTEL,可能來自某個日誌文件,可能來自 statsd,收集到數據之後還需要做各種過濾、轉換、聚合、採樣等操作,煩不勝煩,今天我們就給大家介紹一款開源的數據收集+路由器工具:Vector,解除你的上述煩惱。
Vector 簡介
Vector 通常用作 logstash 的替代品,logstash 屬於 ELK 生態,使用廣泛,但是性能不太好。Vector 使用 Rust 編寫,聲稱比同類方案快 10 倍。Vector 來自 Datadog,如果你瞭解監控、可觀測性,大概率知道 Datadog,作為行業老大哥,其他小弟拍馬難及。Datadog 在 2021 年左右收購了 Vector,現在 Vector 已經開源,地址是:
Vector 不止是收集、路由日誌數據,也可以路由指標數據,甚至可以從日誌中提取指標,功能強大。下麵是 Vector 的架構圖:
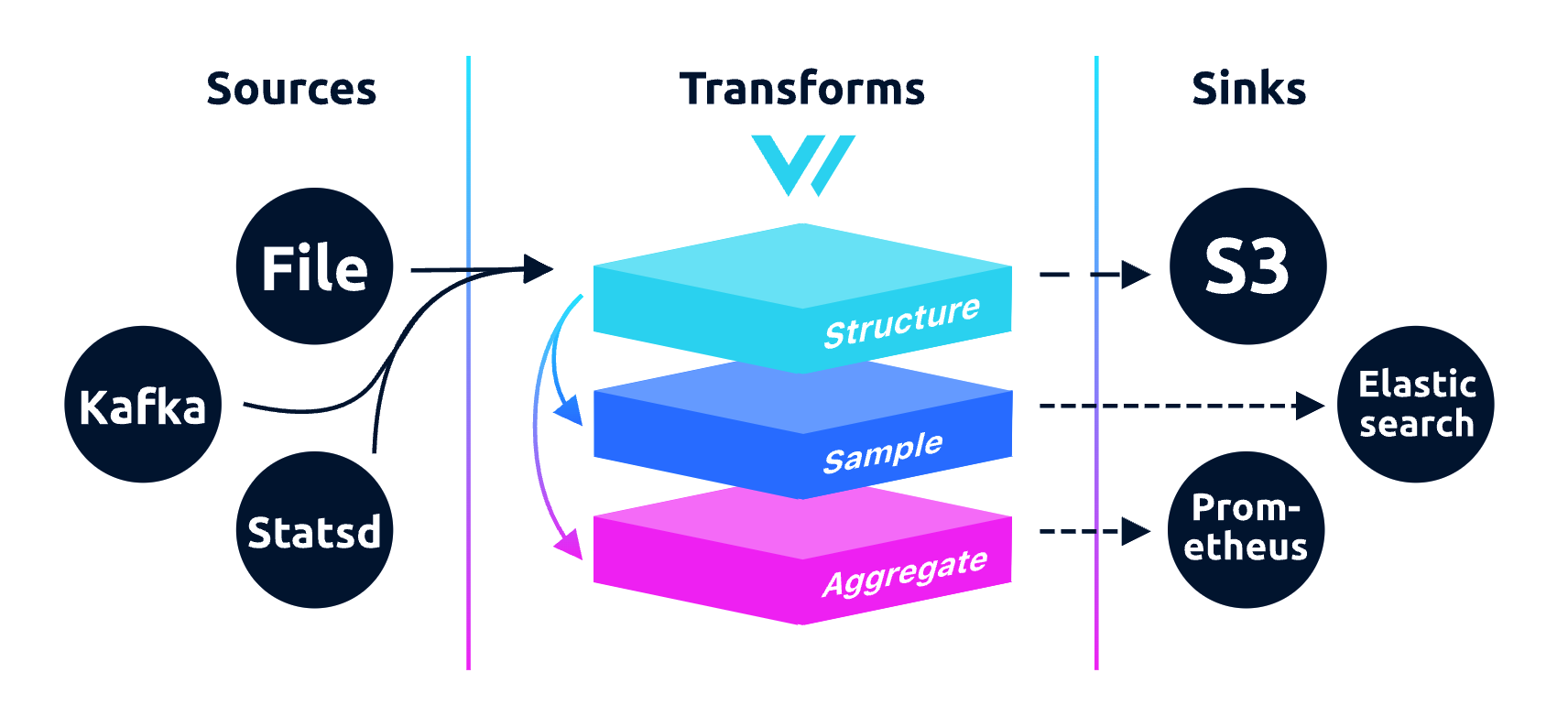
看起來和其他同類產品是類似的,核心就是 pipeline 的處理,有 Source 端做採集,有中間的 Transform 環節做數據加工處理,有 Sink 端做數據轉發。魔鬼在細節,Vector 有如下一些特點,讓它顯得卓爾不群:
- 超級快速可靠:Vector採用Rust構建,速度極快,記憶體效率高,旨在處理最苛刻的工作負載
- 端到端:Vector 致力於成為從 A 到 B 獲取可觀測性數據所需的唯一工具,並作為守護程式、邊車或聚合器進行部署
- 統一:Vector 支持日誌和指標,使您可以輕鬆收集和處理所有可觀測性數據
- 供應商中立:Vector 不偏向任何特定的供應商平臺,並以您的最佳利益為出發點,培育公平、開放的生態系統。免鎖定且面向未來
- 可編程轉換:Vector 的高度可配置轉換為您提供可編程運行時的全部功能。無限制地處理複雜的用例
Vector 安裝
Vector 的安裝比較簡單,一條命令即可搞定,其他安裝方式可以參考其 官方文檔。
curl --proto '=https' --tlsv1.2 -sSf https://sh.vector.dev | bashVector 配置測試
Vector 的配置文件可以是 yaml、json、toml 格式,下麵是一個 toml 的例子,其作用是讀取 /var/log/system.log 日誌文件,然後把 syslog 格式的日誌轉換成 json 格式,最後輸出到標準輸出:
[sources.syslog_demo]
type = "file"
include = ["/var/log/system.log"]
data_dir = "/Users/ulric/works/vector-test"
[transforms.remap_syslog]
inputs = [ "syslog_demo"]
type = "remap"
source = '''
structured = parse_syslog!(.message)
. = merge(., structured)
'''
[sinks.emit_syslog]
inputs = ["remap_syslog"]
type = "console"
encoding.codec = "json"首先,[sources.syslog_demo] 定義了一個 source,取名為 syslog_demo,這個 source 的類型是 file,表示從文件中讀取數據,文件路徑是 /var/log/system.log,data_dir 是存儲 checkpoint 數據不用關心,只要給一個可寫的目錄就行(Vector 自用)。然後定義了一個 transform,名字為 remap_syslog,指定這個 transform 的數據來源(即上游)是 syslog_demo,其類型是 remap,remap 是 Vector 里非常重要的一個 transform,可以做各類數據轉換,在 source 欄位里定義了一段代碼,其工作邏輯是:
- 來自 syslog_demo 這個 source 的日誌數據,日誌原文在 message 欄位里(除了日誌原文 message 欄位,Vector 還會對採集的數據附加 host、timestamp 等欄位),需要先解析成結構化的數據,通過 parse_syslog 這個函數做轉換
- 轉換之後,相當於把非結構化的日誌數據轉換成了結構化的數據,賦值給 structured 變數,然後通過 merge 函數把結構化的這個數據和原始就有的 host、timestamp 等欄位合併,然後把合併的結果繼續往 pipeline 後續環節傳遞
[sinks.emit_syslog] 定義了一個 sink,名字是 emit_syslog,通過 inputs 指明瞭上游數據來自 remap_syslog 這個 transform,通過 type 指明要把數據輸出給 console,即控制台,然後通過 encoding.codec 指定輸出的數據格式是 json。然後通過下麵的命令啟動 Vector:
vector -c vector.toml然後,你就會看到一堆的日誌輸出(當然,前提是你的機器上有 system.log 這個文件,我是 macbook,所以用的這個文件測試的),樣例如下:
ulric@ulric-flashcat vector-test % vector -c vector.toml
...
{"appname":"syslogd","file":"/var/log/system.log","host":"ulric-flashcat.local","hostname":"ulric-flashcat","message":"ASL Sender Statistics","procid":332,"source_type":"file","timestamp":"2023-09-27T07:31:22Z"}如上,就說明正常採集到了數據,而且轉換成了 json 並列印到了控制台,實驗成功。當然,列印到控制台只是個測試,Vector 可以把數據推給各類後端,典型的比如 ElasticSearch、S3、ClickHouse、Kafka 等。
Vector 部署模式
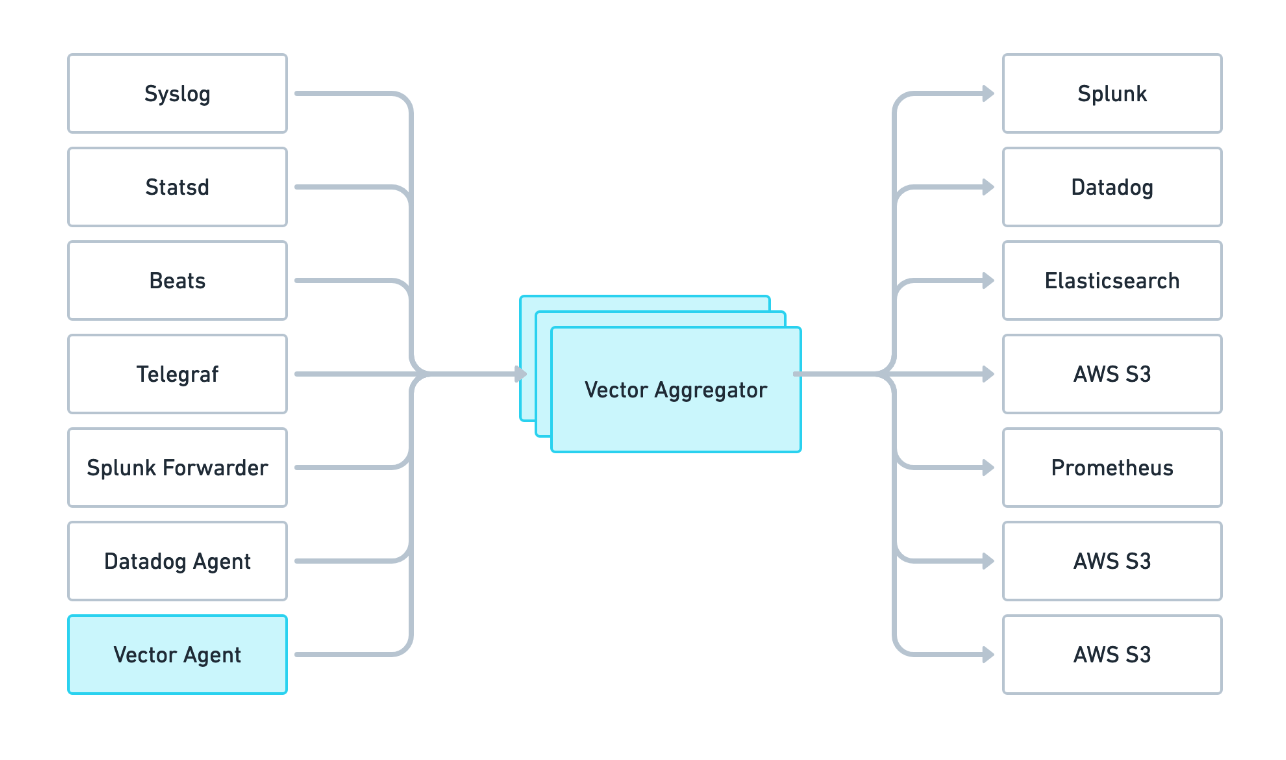
Vector 可以部署為兩個角色,既可以作為數據採集的 agent,也可以作為數據聚合、路由的 aggregator,架構示例如下:
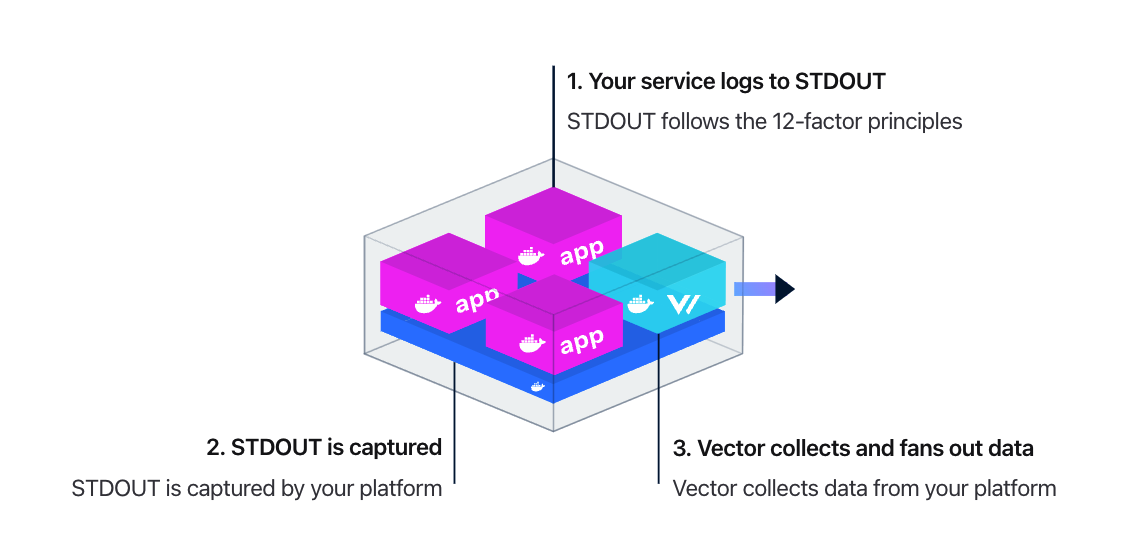
當 Vector 作為 agent 的時候,又有兩種使用模式:Daemon 和 Sidecar。Daemon 模式旨在收集單個主機上的所有數據,這是數據收集的推薦方式,因為它最有效地利用主機資源。比如把 Vector 部署為 DaemonSet,收集這個機器上的所有容器中應用的日誌,容器中的應用的日誌推薦使用 stdout 方式列印,符合雲原生 12 條要素。架構圖如下:
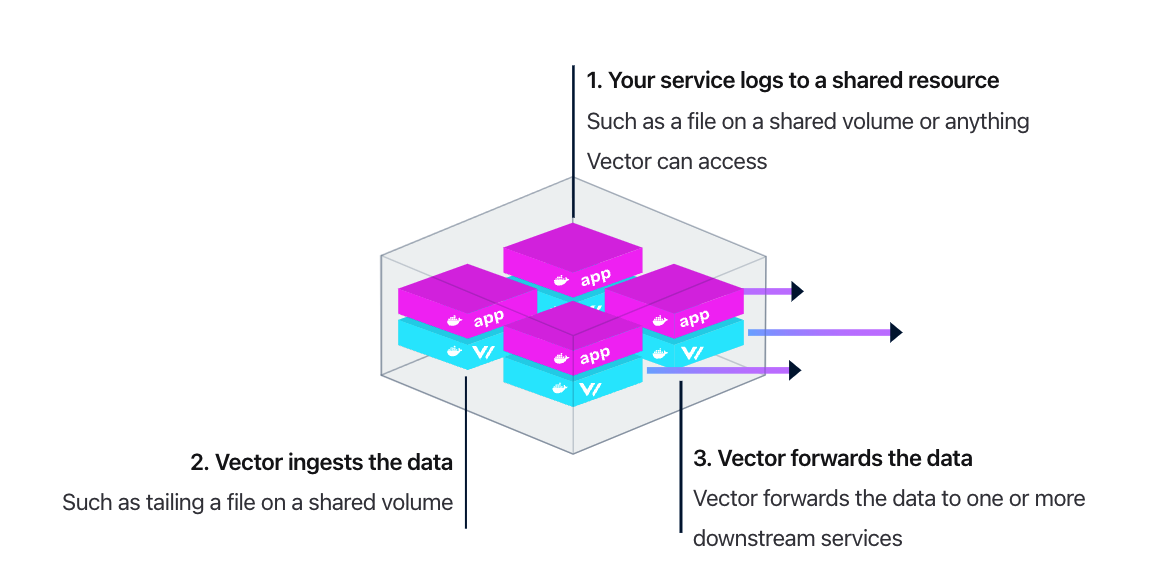
當然,也可以使用 Sidecar 模式部署,這樣占用的資源更多(畢竟,每個 Pod 里都要塞一個 Vector 容器),但是更靈活,服務所有者可以隨意搞自己的日誌收集方案,不用依賴統一的日誌收集方案。架構圖如下:
Vector 總結
夜鶯社區里已經有很多小伙伴從 logstash 遷移到了 Vector,並普遍表示 Vector YYDS,如果你還沒聽過 Vector,趕緊去試試吧。其他的我也不啰嗦,請各位移步 Vector 官方文檔,本文最重要的價值就是讓你知道有這麼個好東西 :-)
擴展閱讀:
- 鄙人專欄:運維監控系統實戰筆記,體系化學習監控知識
- 方法論:面向故障處理的可觀測性體系建設
- 白皮書:事件OnCall中心建設方法
- 好工具:FlashDuty - 一站式告警處理平臺:告警降噪、排班OnCall
- 好工具:Grafana 開源了一款 eBPF 採集器 Beyla
- 好工具:日誌存儲領域的後起之秀 VictoriaLogs


