
正則表達式是一個強大的文本匹配工具。但是,對於初學者來說,眾多的符號和規則可能讓人難以理解。其實,你不需要記住所有的正則表達式語法!本文將分享一些簡單而實用的技巧,幫助理解正則表達式的核心概念,輕鬆使用正則表達式! 基礎入門 概念 正則表達式(Regular Expression,在代碼中常簡寫為r ...
基礎入門
概念
正則表達式(Regular Expression,在代碼中常簡寫為regex、regexp或RE)使用單個字元串來描述、匹配一系列符合某個句法規則的字元串搜索模式。搜索模式可用於文本搜索和文本替換。它用一系列字元定義搜索模式。
正則表達式的用途有很多,比如:
-
表單輸入驗證;
-
搜索和替換;
-
過濾大量文本文件(如日誌)中的信息;
-
讀取配置文件;
-
網頁抓取;
-
處理具有一致語法的文本文件,例如 CSV。
創建
正則表達式的語法如下:
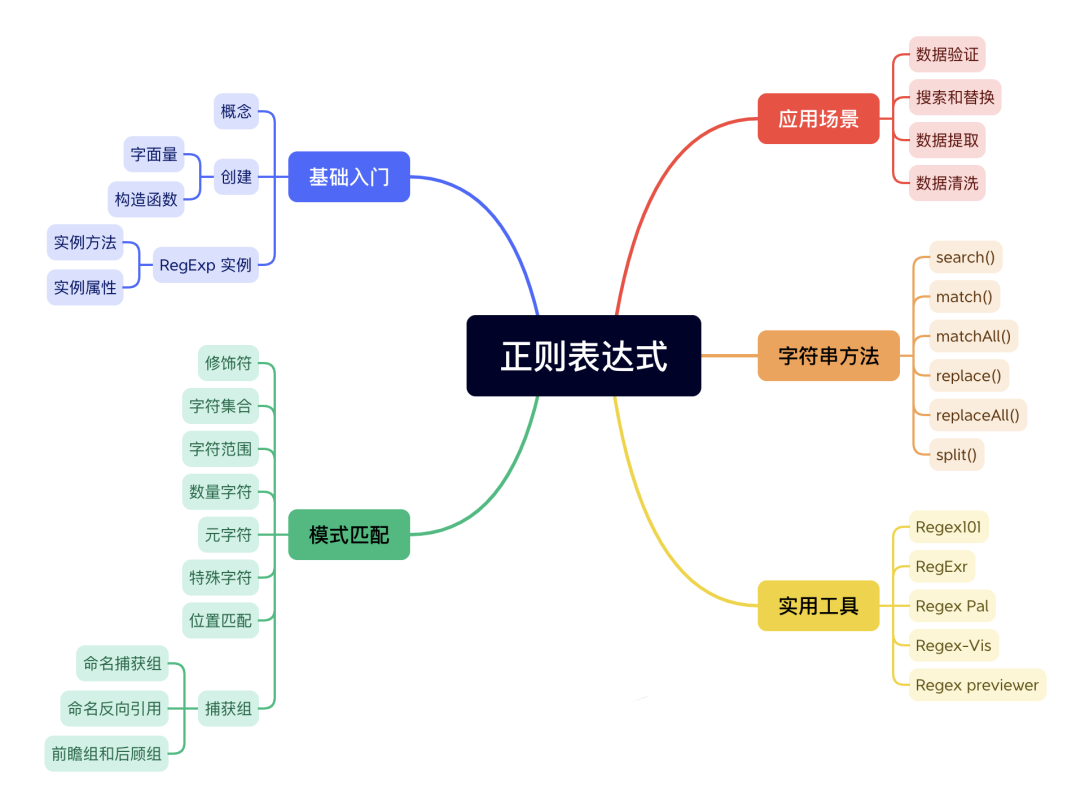
/正則表達式主體/修飾符(可選)先來看一個最基本的正則表達式:/處/,它只匹配到了字元串中的第一個“處”:
創建正則表達式的方式有兩種:
-
字面量:正則表達式直接放在
/ /之中:
const rex = /pattern/; -
構造函數:RegExp 對象表示正則表達式的一個實例:
const rex = new RegExp("pattern");這兩種方法的一大區別是對象的構造函數允許傳遞帶引號的表達式,通過這種方式就可以動態創建正則表達式。
通過這兩種方法創建出來的 Regex 對象都具有相同的方法和屬性:
let RegExp1 = /a|b/
let RegExp2 = new RegExp('a|b')
console.log(RegExp1) // 輸出結果:/a|b/
console.log(RegExp2) // 輸出結果:/a|b/RegExp 實例
實例方法
RegExp 實例置了test()和exec() 這兩個方法來校驗正則表達式。下麵來分別看一下這兩個方法。
(1)test()
test()用於檢測一個字元串是否匹配某個模式,如果字元串中含有匹配的文本,則返回 true,否則返回 false。
const regex1 = /a/ig;
const regex2 = /hello/ig;
const str = "Action speak louder than words";
console.log(regex1.test(str)); // true
console.log(regex2.test(str)); // false(2)exec()
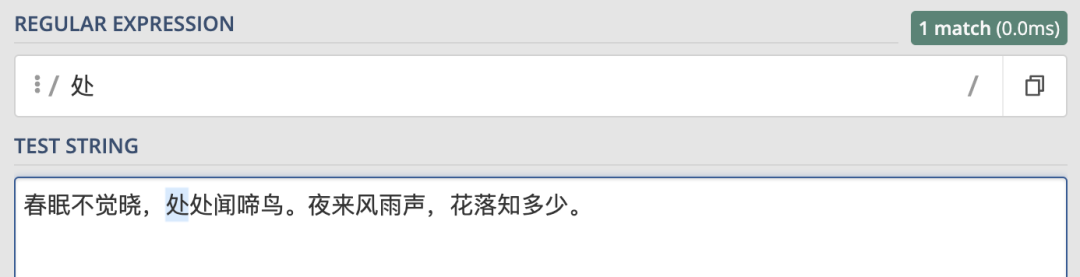
exec()用於檢索字元串中的正則表達式的匹配。該函數返回一個數組,其中存放匹配的結果。如果未找到匹配,則返回值為 null。
const regex1 = /a/ig;
const regex2 = /hello/ig;
const str = "Action speak louder than words";
console.log(regex1.exec(str)); // ['A', index: 0, input: 'Action speak louder than words', groups: undefined]
console.log(regex2.exec(str)); // null在當在全局正則表達式中使用 exec 時,每隔一次就會返回null,如圖:
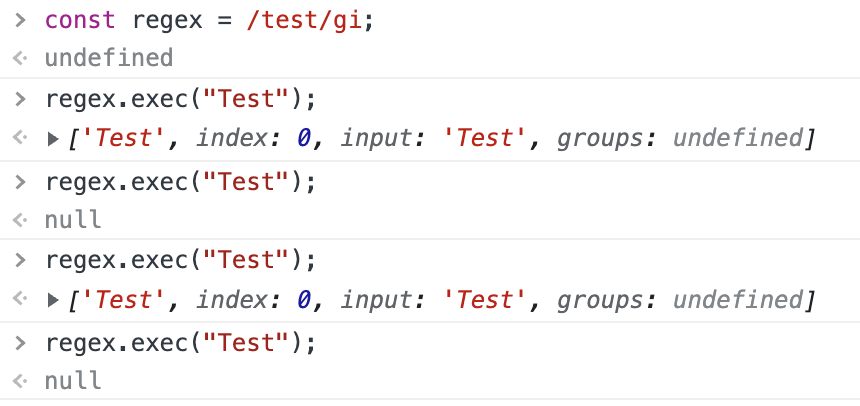
在設置了 global 或 sticky 標誌位的情況下(如 /foo/g or /foo/y),JavaScript RegExp 對象是有狀態的。他們會將上次成功匹配後的位置記錄在 lastIndex 屬性中。使用此特性,exec() 可用來對單個字元串中的多次匹配結果進行逐條的遍歷(包括捕獲到的匹配),而相比之下, String.prototype.match() 只會返回匹配到的結果。
為瞭解決這個問題,我們可以在運行每個exec命令之前將lastIndex賦值為 0:

實例屬性
RegExp 實例還內置了一些屬性,這些屬性可以獲知一個正則表達式的各方面的信息,但是用處不大。
| 屬性 | 描述 |
|---|---|
global |
布爾值,表示是否設置了g標誌 |
ignoreCase |
布爾值,表示是否設置了i標誌 |
lastIndex |
整數,表示開始搜索下一個匹配項的字元位置,從0算起 |
multiline |
布爾值,表示是否設置了m標誌 |
source |
正則表達式的字元串表示,按照字面量形式而非傳入構造函數重大的字元串模式匹配 |
模式匹配
關於正則表達式最複雜的地方就是如何編寫正則規則了,下麵就來看如何編寫正則表達式。
修飾符
正則表達式的修飾符是一種可以在正則表達式模式中添加的標記,用於修改搜索模式的行為。這些修飾符通常以單個字元形式出現在正則表達式的末尾,並且可以通過在正則表達式模式前添加該字元來啟用修飾符。
常見的修飾符如下:
-
g:表示全局模式,即運用於所有字元串; -
i:表示不區分大小寫,即匹配時忽略字元串的大小寫; -
m:表示多行模式,強制 $ 和 ^ 分別匹配每個換行符。
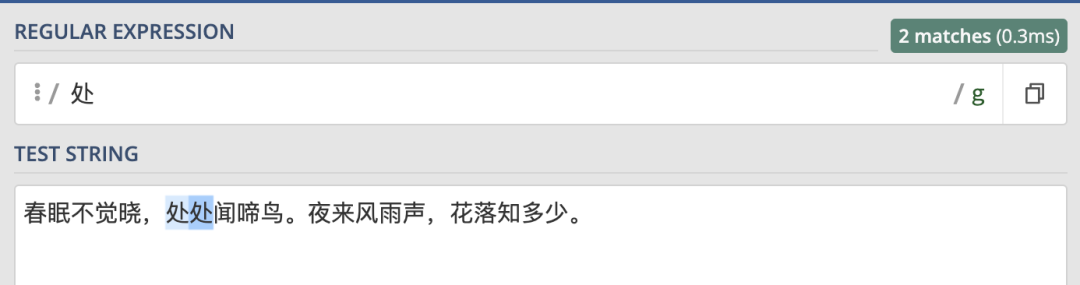
最開始的例子中,字元串中有兩個“處”,但是只匹配到了一個。這是因為正則表達式預設匹配第一個符合條件的字元。如果想要匹配所有符合條件的字元,就可以使用 g 修飾符:
/處/g這樣就匹配到了所有符合條件的字元:
i 修飾符就派上用場了。先來看下麵的表達式:
/a/g在進行匹配時,它匹配到了字元串中所有的 a 字元。但是最開始的 A 是沒匹配到的,因為兩者大小寫不一致:
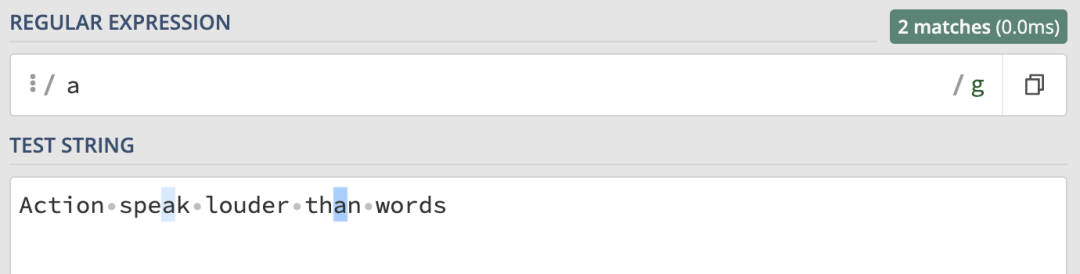
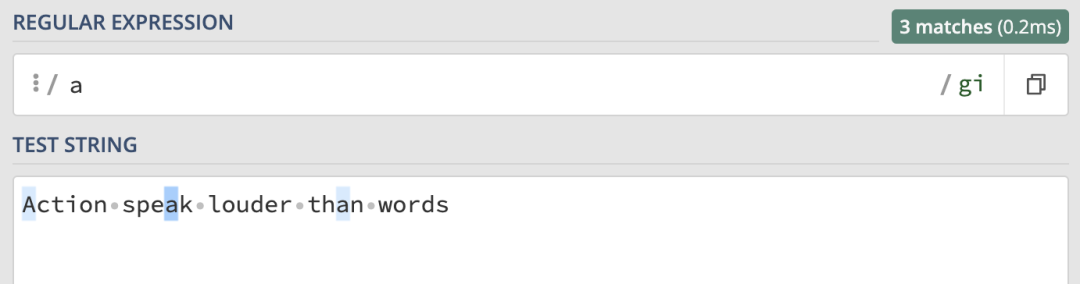
i 修飾符:
/a/gi這時所有的 a 都被匹配到了,無論是大寫還是小寫,總共匹配到了三個 a:
let regExp = new RegExp('[2b|^2b]', 'gi')
console.log(regExp) // 輸出結果:/[2b|^2b]/gi字元集合
如果我們想匹配 bat、cat 和 fat 這種類型的字元串該怎麼辦?可以通過使用字元集合來做到這一點,用 [] 表示,它會匹配包含的任意一個字元。這裡就可以使用/[bcf]at/ig:
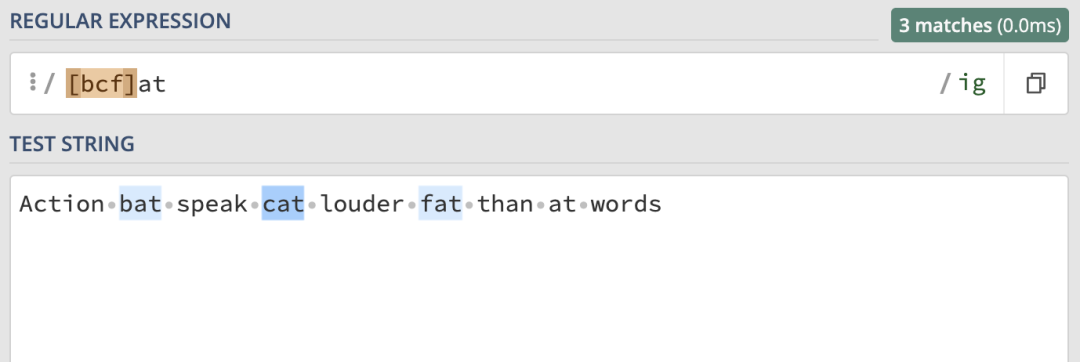
當然,字元集也可以用來匹配數字:
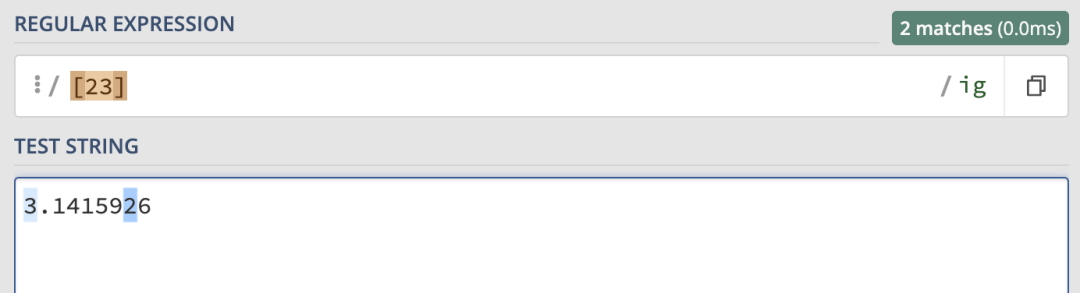
字元範圍
如果我們想要在字元串中匹配所有以 at 結尾的單詞,最直接的方式是使用字元集,併在其中提供所有的字母。對於這種在一個範圍中的字元, 就可以直接定義字元範圍,用-表示。它用來匹配指定範圍內的任意字元。這裡就可以使用/[a-z]at/ig:
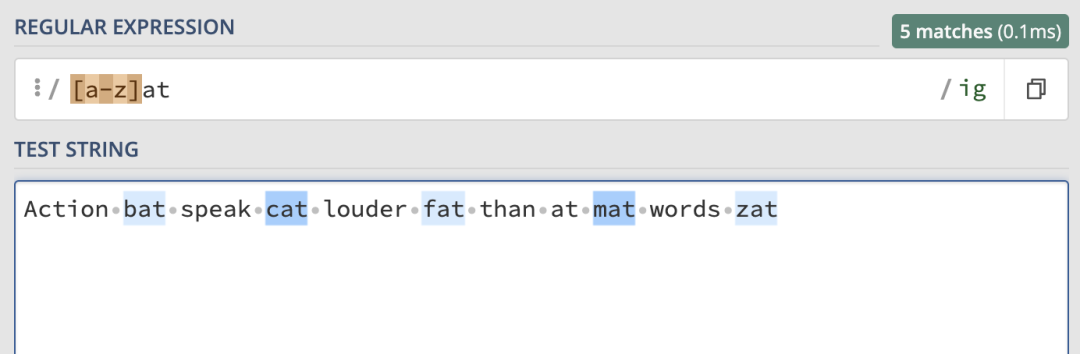
常見的使用範圍的方式如下:
-
部分範圍:
[a-f],匹配 a 到 f 的任意字元; -
小寫範圍:
[a-z],匹配 a 到 z 的任意字元; -
大寫範圍:
[A-Z],匹配 A 到 Z 的任意字元; -
數字範圍:
[0-9],匹配 0 到 9 的任意字元; -
符號範圍:
[#$%&@]; -
混合範圍:
[a-zA-Z0-9],匹配所有數字、大小寫字母中的任意字元。
數量字元
如果想要匹配三個字母的單詞,根據上面我們學到的字元範圍,可以這樣來寫:
[a-z][a-z][a-z]這裡我們匹配的三個字母的單詞,那如果想要匹配10個、20個字母的單詞呢?難道要一個個來寫範圍嗎?有一種更好的方法就是使用花括弧{}來表示,來看例子:
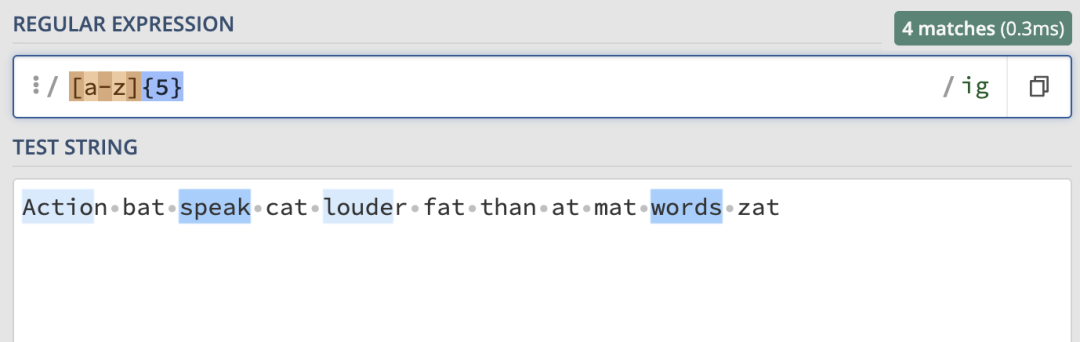
其實匹配重覆字元的完整語法是這樣的:{m,n},它會匹配前面一個字元至少 m 次至多 n 次重覆,{m}表示匹配 m 次,{m,}表示至少 m 次。
所以,當我們給5後面加上逗號時,就表示至少匹配五次:
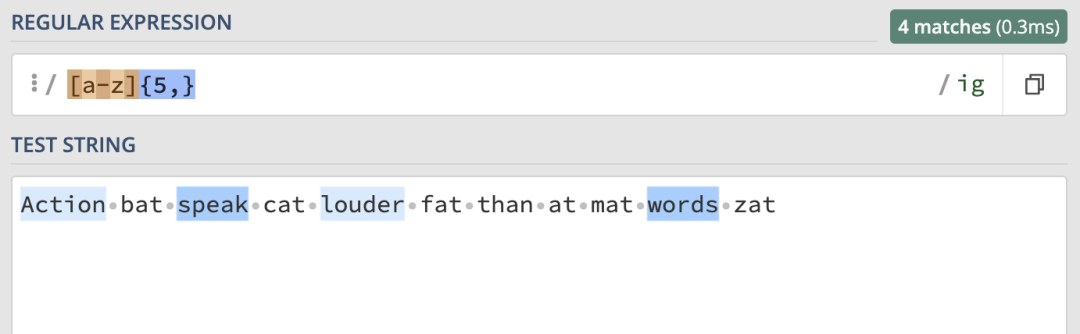
當匹配次數為至少4次,至多5次時,匹配結果如下:
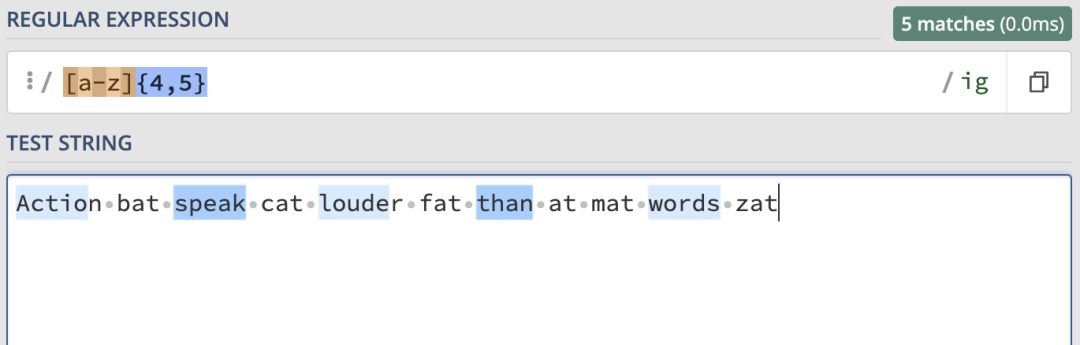
-
+:匹配前面一個表達式一次或者多次,相當於{1,}; -
*:匹配前面一個表達式0次或者多次,相當於{0,}; -
?:單獨使用匹配前面一個表達式零次或者一次,相當於{0,1},如果跟在量詞*、+、?、後面的時候將會使量詞變為非貪婪模式(儘量匹配少的字元),預設是使用貪婪模式。
來看一個簡單的例子,這裡我們匹配的正則表達式為/a+/ig,結果如下:
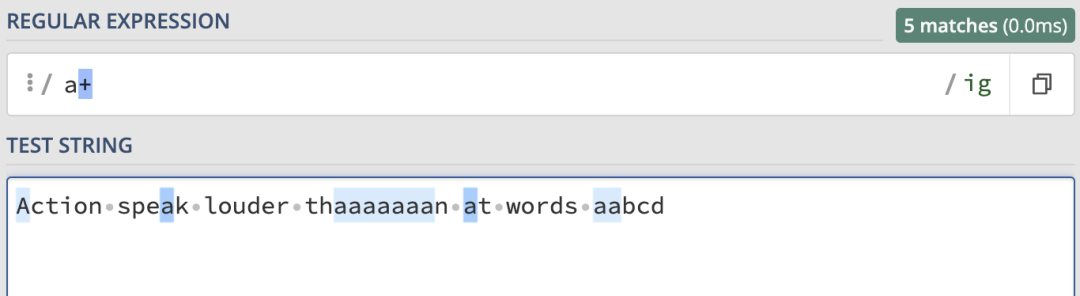
/a{1,}/ig的匹配結果是一樣的:
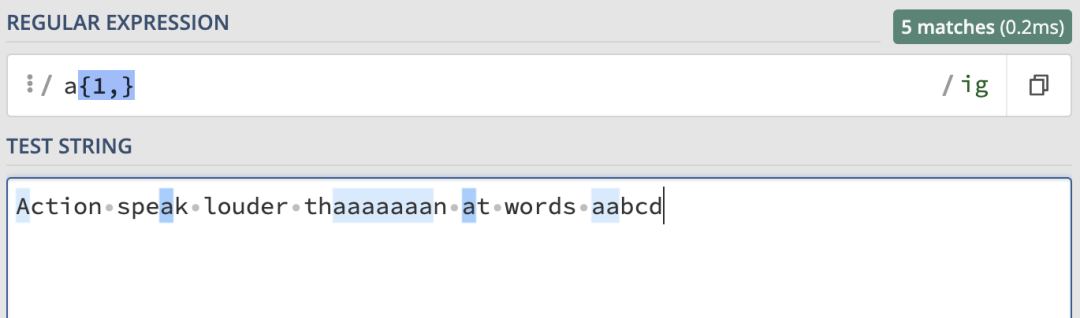
/[a-z]+/ig就可以匹配任意長度的純字母單詞:
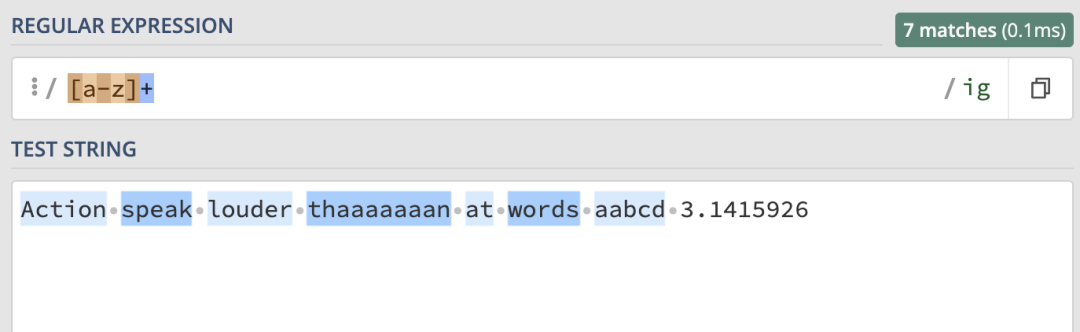
元字元
使用元字元可以編寫更緊湊的正則表達式模式。常見的元字元如下:
-
\d:相當於[0-9],匹配任意數字; -
\D:相當於[^0-9]; -
\w:相當於[0-9a-zA-Z],匹配任意數字、大小寫字母和下劃線; -
\W:相當於:[^0-9a-zA-Z]; -
\s:相當於[\t\v\n\r\f],匹配任意空白符,包括空格,水平製表符\t,垂直製表符\v,換行符\n,回車符\r,換頁符\f; -
\S:相當於[^\t\v\n\r\f],表示非空白符。
來看一個簡單的例子:
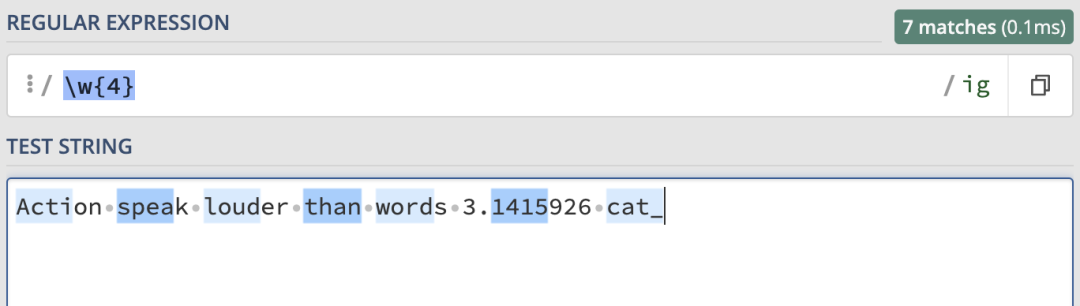
\d來匹配任意數字、字母和下劃線。這裡就匹配到了7個連續四位的字元。
特殊字元
使用特殊字元可以編寫更高級的模式表達式,常見的特殊字元如下:
-
.:匹配除了換行符之外的任何單個字元; -
\:將下一個字元標記為特殊字元、或原義字元、或向後引用、或八進位轉義符; -
|:邏輯或操作符; -
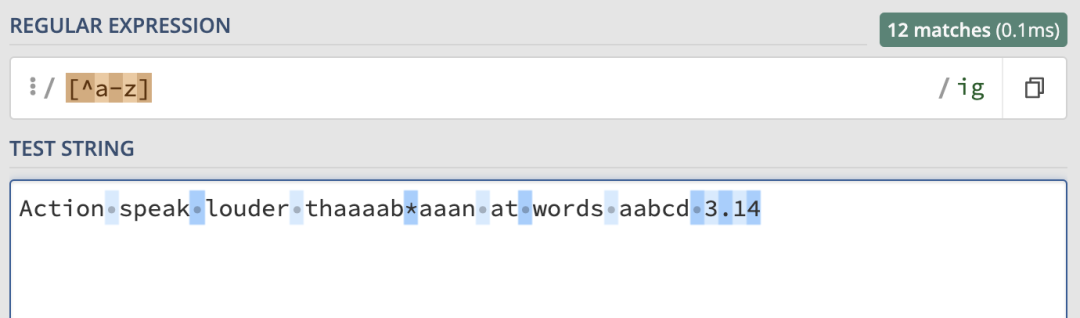
[^]:取非,匹配未包含的任意字元。
來看一個簡單的例子,如果我們使用 /ab*/ig 進行匹配,結果就如下:
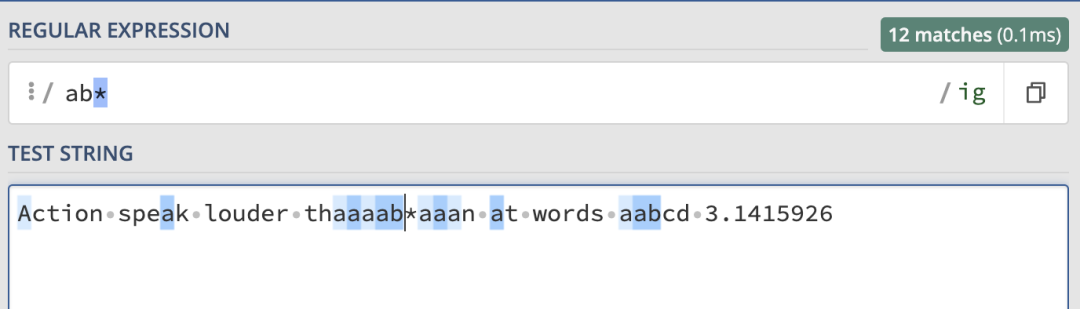
\ 對其進行轉義:
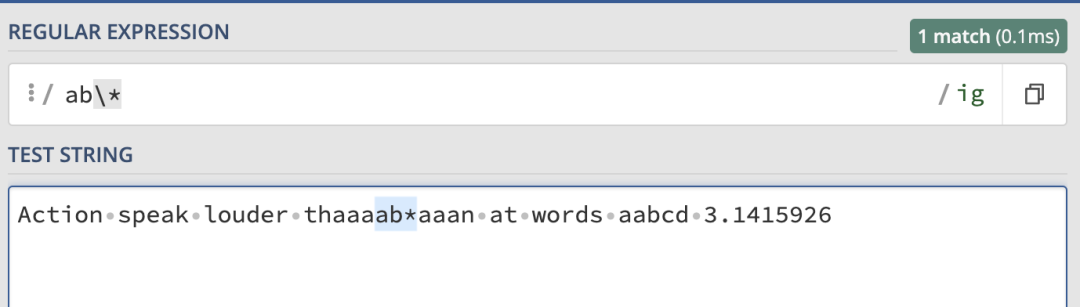
ab* 了。
或匹配也很簡單,來看例子,匹配規則為:/ab|cd/ig,匹配結果如下:
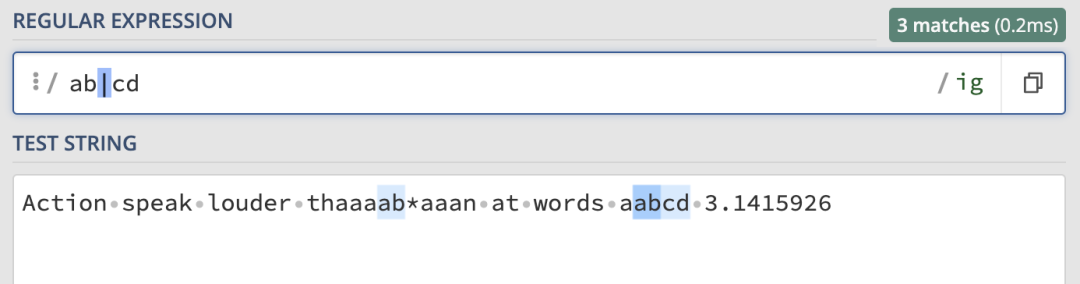
ab 和 cd 字元。那如果想要匹配 sabz 或者scdz呢?開頭和結尾是相同的,只有中間的兩個字元是可選的。其實只需要給中間的或部分加上括弧就可以了:
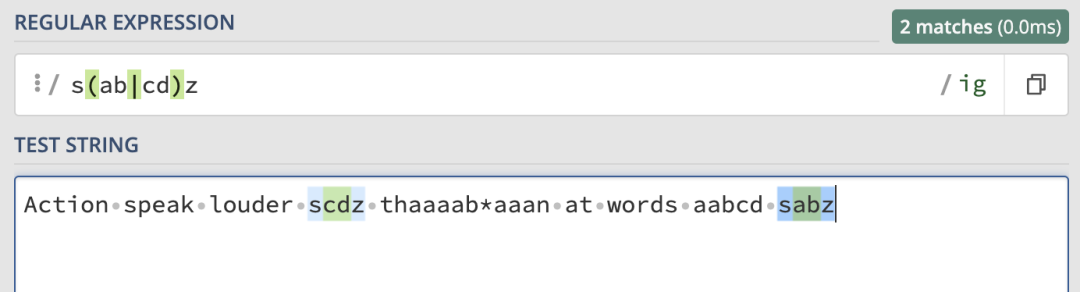
位置匹配
如果我們想匹配字元串中以某些字元結尾的單詞,以某些字元開頭的單詞該如何實現呢?正則表達式中提供了方法通過位置來匹配字元:
-
\b:匹配一個單詞邊界,也就是指單詞和空格間的位置; -
\B:匹配非單詞邊界; -
^:匹配開頭,在多行匹配中匹配行開頭; -
$:匹配結尾,在多行匹配中匹配行結尾; -
(?=p):匹配 p 前面的位置; -
(?!=p):匹配不是 p 前面的位置。
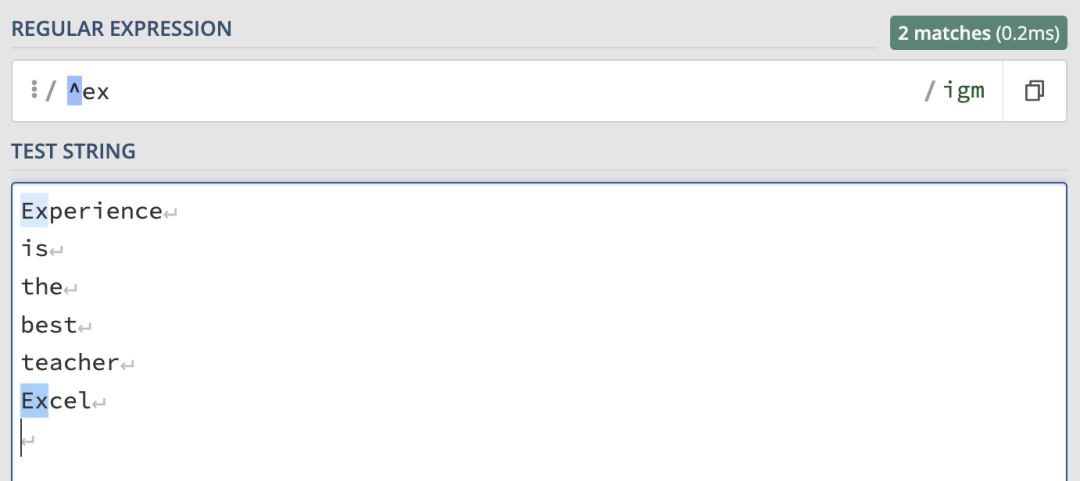
最常見的就是匹配開始和結束位置。先來看一個開始位置的匹配,這裡使用 /^ex/igm 來匹配多行中以ex 開頭的行:
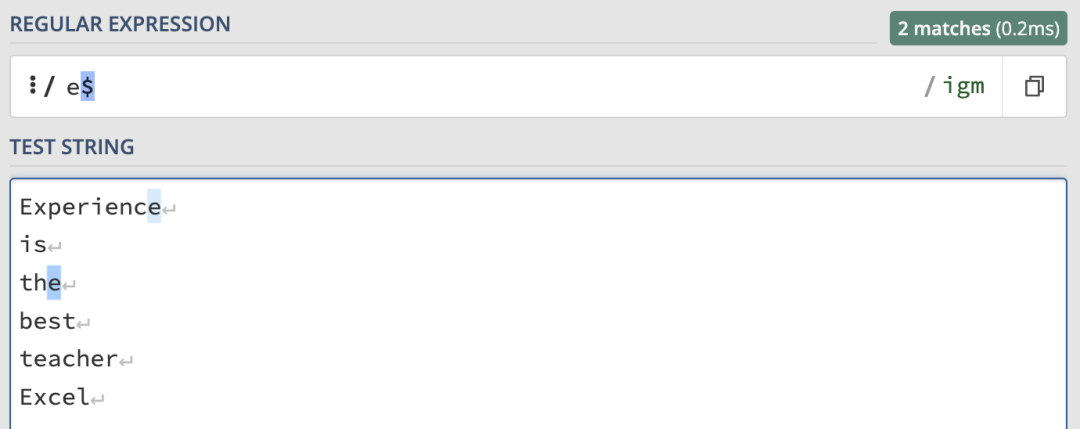
/e$/igm來匹配以 e 結尾的行:
\w+$ 來匹配每一行的最後一個單詞:
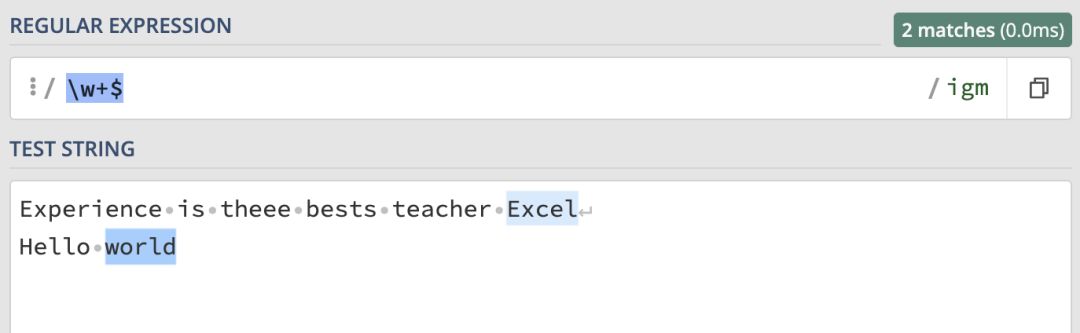
m 修飾符開啟了多行模式。
使用 /(?=the)/ig 來匹配字元串中the前的面的位置:
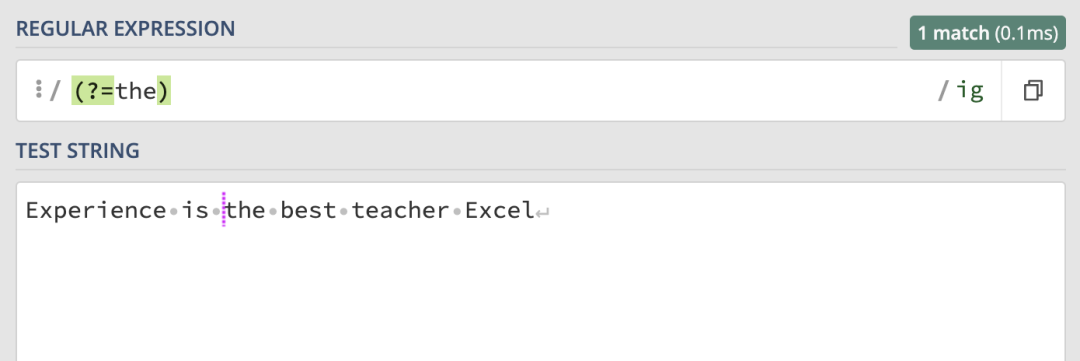
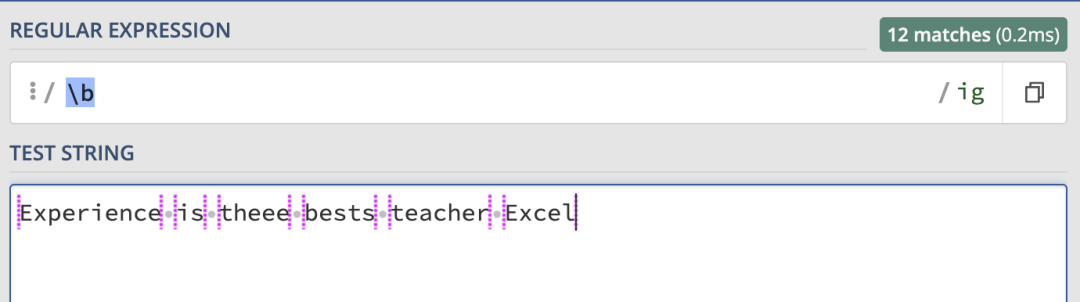
我們可以使用\b來匹配單詞的邊界,匹配的結果如下:
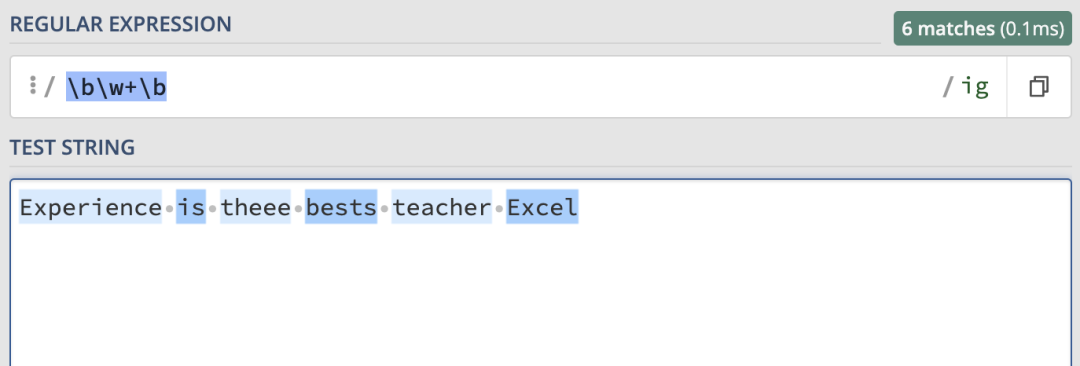
\b\w+\b,匹配結果如下:
捕獲組
正則表達式中的“捕獲組”是指使用括弧 () 將子模式括起來,以便於在搜索時同時匹配多個項或將匹配的內容單獨提取出來。組可以根據需要進行嵌套,形成複雜的匹配模式。
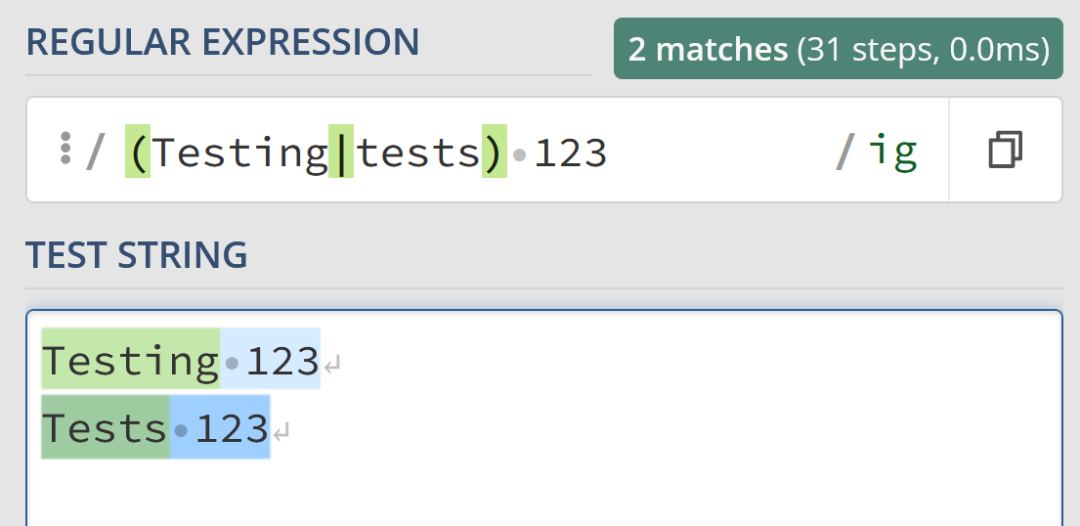
使用捕獲組,可以直接在正則表達式 /(Testing|tests) 123/ig 中匹配到 "Testing 123" 和 "Tests 123",而不需要重覆寫 "123" 的匹配項。
-
(...):捕獲組,用於匹配任意三個字元。 -
(?:...):非捕獲組,也是用於匹配任意三個字元,但不進行捕獲。
可以使用以下 JavaScript 將文本替換為Testing 234和tests 234:
const regex = /(Testing|tests) 123/ig;
let str = `
Testing 123
Tests 123
`;
str = str.replace(regex, '$1 234');
console.log(str);
// Testing 234
// Tests 234被括弧包圍的子模式稱為“捕獲組”,捕獲組可以從匹配的字元串中提取出指定的部分並單獨使用。這裡我們使用 $1 來引用第一個捕獲組 (Testing|tests)。也可以匹配多個組,比如同時匹配 (Testing|tests) 和 (123)。
const regex = /(Testing|tests) (123)/ig;
let str = `
Testing 123
Tests 123
`;
str = str.replace(regex, '$1 #$2');
console.log(str);
// Testing #123
// Tests #123"這隻適用於捕獲組。如果把上面的正則表達式變成這樣:
/(?:Testing|tests) (123)/ig;那麼只有一個被捕獲的組:(123),與之前相同的代碼將輸出不同的結果:
const regex = /(?:Testing|tests) (123)/ig;
let str = `
Testing 123
Tests 123
`;
str = str.replace(regex, '$1');
console.log(str);
// 123
// 123修改後的正則表達式只有一個捕獲組 (123)。因為 (?: ) 的語法用於創建非捕獲組,所以它不會將其內容作為一個捕獲組來使用。
命名捕獲組
雖然捕獲組非常有用,但是當有很多捕獲組時很容易讓人困惑。$3 和 $5 這些名字並不是一目瞭然的。為瞭解決這個問題,正則表達式引入了“命名捕獲組”的概念。例如,(?<name>...) 就是一個命名捕獲組,名為 "name",用於匹配任意三個字元。
可以像這樣在正則表達式中使用它來創建一個名為 "num" 的組,用於匹配三個數字:
/Testing (?<num>\d{3})/然後,可以在替換操作中像這樣使用它:
const regex = /Testing (?<num>\d{3})/
let str = "Testing 123";
str = str.replace(regex, "Hello $<num>")
console.log(str); // "Hello 123"命名反向引用
有時候需要在查詢字元串中引用一個命名捕獲組,這就是“反向引用”的用武之地。
假設有一個字元串,其中包含多個單詞,我們想要找到所有出現兩次或以上的單詞。可以使用具名捕獲組和命名反向引用來實現。
const regex = /\b(?<word>\w+)\b(?=.*?\b\k<word>\b)/g;
const str = 'I like to eat pizza, but I do not like to eat sushi.';
const result = str.match(regex);
console.log(result); // like這裡使用了具名捕獲組 (?<word>\w+)來匹配單詞,並將其命名為 "word"。然後使用命名反向引用 (?=.*?\b\k<word>\b) 來查找文本中是否存在具有相同內容的單詞。
前瞻組和後顧組
前瞻組(Lookahead)和後顧組(Lookbehind)是正則表達式中非常有用的工具,它們用於在匹配過程中進行條件約束,而不會實際匹配這些約束的內容。它們使得我們可以更精確地指定匹配模式。
前瞻組:
-
正向前瞻(
(?=...)):用於查找在某個位置後面存在的內容。例如,A(?=B)可以匹配 "A",但只有在後面跟著 "B" 時才進行匹配。 -
負向前瞻(
(?!...)):用於查找在某個位置後面不存在的內容。例如,A(?!B)可以匹配 "A",但只有在後面不跟著 "B" 時才進行匹配。
後顧組:
-
正向後顧(
(?<=...)):用於查找在某個位置前面存在的內容。例如,(?<=A)B可以匹配 "B",但只有在其前面跟著 "A" 時才進行匹配。 -
負向後顧(
(?<!...)):用於查找在某個位置前面不存在的內容。例如,(?<!A)B可以匹配 "B",但只有在其前面不跟著 "A" 時才進行匹配。
這些前瞻組和後顧組可以用於各種場景,例如:
-
在匹配郵箱地址時,使用正向前瞻來確保地址的結尾是以特定的功能變數名稱結尾。
-
在匹配密碼時,使用正向前瞻來確保密碼滿足特定的複雜度要求。
-
在提取文本中的日期時,使用正向後顧來確保日期的前面有特定的首碼。
例如,使用負向前瞻可以匹配 BC,但不會匹配 BA。
/B(?!A)/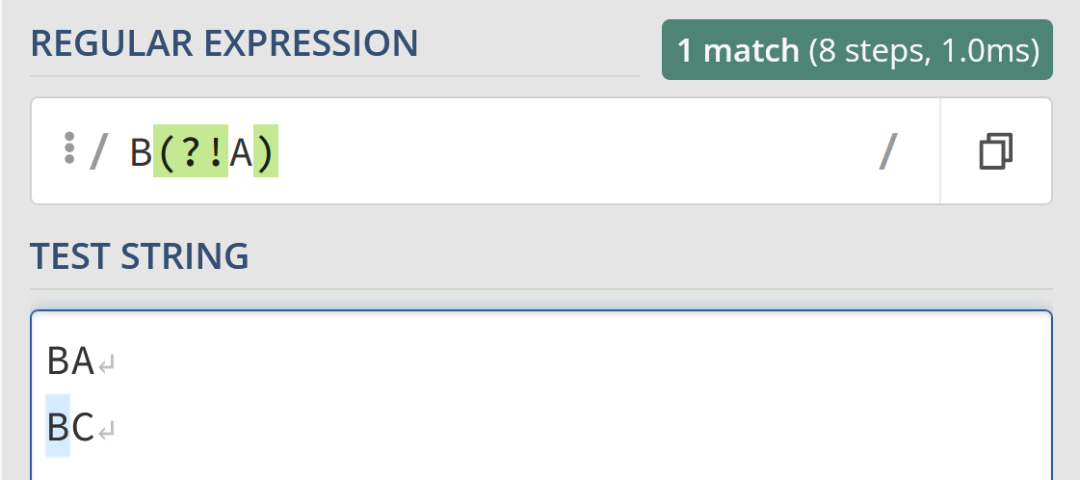
/^(?!Test).*$/gm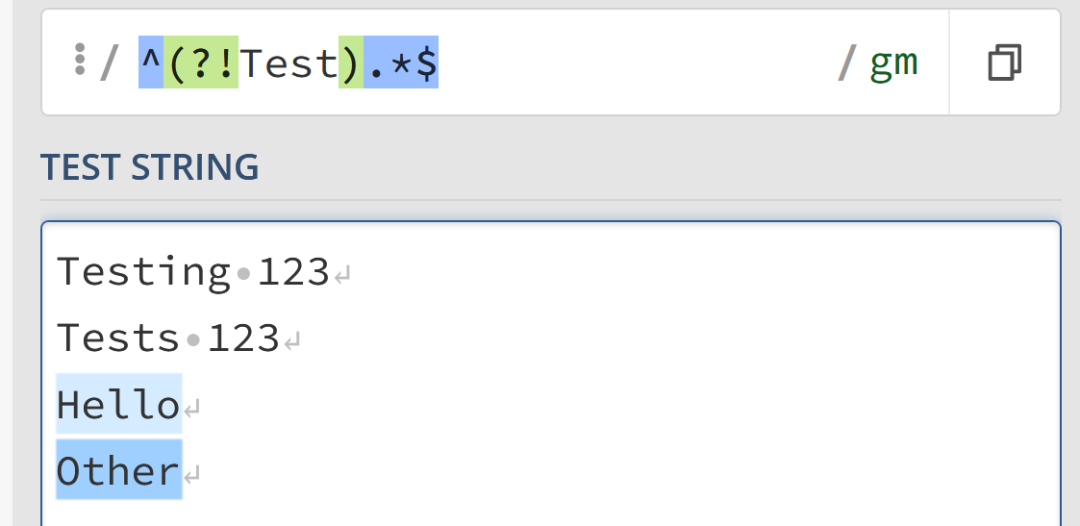
Hello 和 Other,但無法匹配 Testing 123 和 Tests 123。
同樣,可以將其切換為正向前瞻,以強制字元串必須以“Test”開頭:
/^(?=Test).*$/gm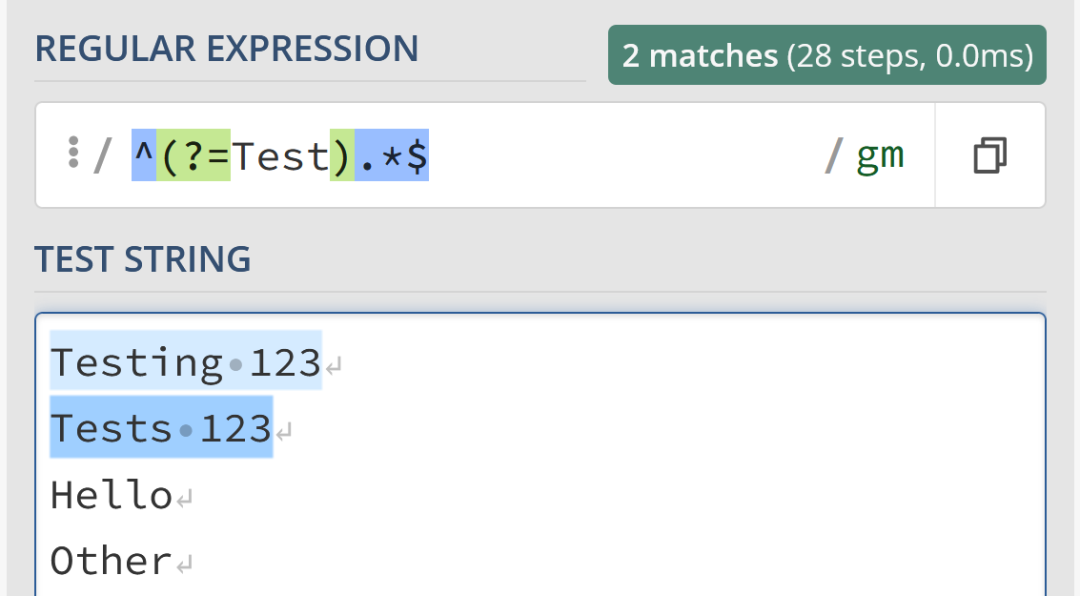
字元串方法
在 JavaScript 內置了 6 個常用的方法是支持正則表達式的,下麵來分別看看這些方法。
search()
search() 方法用於檢索字元串中指定的子字元串,或檢索與正則表達式相匹配的子字元串,並返回子串的起始位置。如果沒有找到任何匹配的子串,則返回 -1。
const regex1 = /a/ig;
const regex2 = /p/ig;
const regex3 = /m/ig;
const str = "Action speak louder than words";
console.log(str.search(regex1)); // 輸出結果:0
console.log(str.search(regex2)); // 輸出結果:8
console.log(str.search(regex3)); // 輸出結果:-1可以看到,search() 方法只會返回匹配到的第一個字元的索引值,當沒有匹配到相應的值時,就會返回-1。
match()
match() 方法可在字元串內檢索指定的值,或找到一個或多個正則表達式的匹配。如果沒有找到任何匹配的文本, match() 將返回 null。否則,它將返回一個數組,其中存放了與它找到的匹配文本有關的信息。
const regex1 = /a/ig;
const regex2 = /a/i;
const regex3 = /m/ig;
const str = "Action speak louder than words";
console.log(str.match(regex1)); // 輸出結果:['A', 'a', 'a']
console.log(str.match(regex2)); // 輸出結果:['A', index: 0, input: 'Action speak louder than words', groups: undefined]
console.log(str.match(regex3)); // 輸出結果:null可以看到,當沒有 g 修飾符時,就只能在字元串中執行一次匹配,如果想要匹配所有符合條件的值,就需要添加 g 修飾符。
matchAll()
matchAll() 方法返回一個包含所有匹配正則表達式的結果及分組捕獲組的迭代器。因為返回的是遍歷器,所以通常使用for...of迴圈取出。
for (const match of 'abcabc'.matchAll(/a/g)) {
console.log(match)
}
//["a", index: 0, input: "abcabc", groups: undefined]
//["a", index: 3, input: "abcabc", groups: undefined]需要註意,該方法的第一個參數是一個正則表達式對象,如果傳的參數不是一個正則表達式對象,則會隱式地使用 new RegExp(obj) 將其轉換為一個 RegExp 。另外,RegExp必須是設置了全局模式g的形式,否則會拋出異常 TypeError。
replace()
replace() 用於在字元串中用一些字元串替換另一些字元串,或替換一個與正則表達式匹配的子串。
const regex = /A/g;
const str = "Action speak louder than words";
console.log(str.replace(regex, 'a')); // 輸出結果:action speak louder than words可以看到,第一個參數中的正則表達式匹配到了字元串的第一個大寫的 A,並將其替換為了第二個參數中的小寫的 a。
replaceAll()
replaceAll() 方法用於在字元串中用一些字元替換另一些字元,或替換一個與正則表達式匹配的子串,該函數會替換所有匹配到的子字元串。
const regex = /a/g;
const str = "Action speak louder than words";
console.log(str.replaceAll(regex, 'A')); // 輸出結果:Action speAk louder thAn words需要註意,當使用一個 regex 時,您必須設置全局("g")標誌, 否則,它將引發 TypeError:"必須使用全局 RegExp 調用 replaceAll"。
split()
split() 方法用於把一個字元串分割成字元串數組。其第一個參數是一個字元串或正則表達式,從該參數指定的地方分割字元串。
const regex = / /gi;
const str = "Action speak louder than words";
console.log(str.split(regex)); // 輸出結果:['Action', 'speak', 'louder', 'than', 'words']這裡的 regex 用來匹配空字元串,所以最終在字元串的每個空格處將字元串拆成了數組。

