
初始化? 給定一個字元串,求其最長迴文串,比如: aababa,最長迴文長度為 3,是ababa; abbabb,最長迴文長度為 2,是abba; 以上兩個迴文串有奇迴文和偶迴文,這樣處理比較繁瑣,需要我們進行分類討論。 所以我們第一步就是先將字元串統一處理為奇迴文。 也就是將每兩個字元串之間插入一 ...
初始化?
給定一個字元串,求其最長迴文串,比如:
aababa,最長迴文長度為 3,是ababa;
abbabb,最長迴文長度為 2,是abba;
以上兩個迴文串有奇迴文和偶迴文,這樣處理比較繁瑣,需要我們進行分類討論。
所以我們第一步就是先將字元串統一處理為奇迴文。
也就是將每兩個字元串之間插入一個占位符(隨便吧,我用的是 #),強制將所有的都改為奇迴文串,然後再在前面和後面各加入一個不同的字元,防止越界。
e.g.我們可以將aababa變換為@#a#a#b#a#b#a#%。
Code
int p=0;
s[p]='@';s[++p]='#';
for(int i=1;i<=n;++i){
s[++p]=t[i];
s[++p]='#';
}
s[p+1]='%';
實現?
對於正常的暴力,大概是 \(O(n^3)\) 的,不過你優化一下,你大概可以優化到 \(O(n^2)\)。
那麼暴力就有一個致命的缺陷:每次求完一個迴文串後,什麼信息都不能繼承,導致需要重新算一遍,這就很費時間好吧,則我們需要考慮一下,之前已經求出來的信息,能不能用在這次呢?
顯然是可以的。
我們可以定義一個數組 \(p\),\(p_i\) 表示 \(i\) 所在的字元為中心的最長迴文的半徑。
且可以發現一個性質,就是我們插入那些占位符的 \(p_i\) 是奇數,而原串中的字元的 \(p_i\) 都是偶數。(似乎沒什麼用)
並且我們記錄一個 \(mid\),表示在i之前所有的迴文中心中,迴文右端點最遠在哪,記 \(mx\) 表示這個最遠的右端點所對應的迴文中心
接下來,我們考慮如何用這個東西維護 \(p_i\)
這是需要分類討論的,即:
- 當 \(mid<i<mx\) 時,情況如下圖:
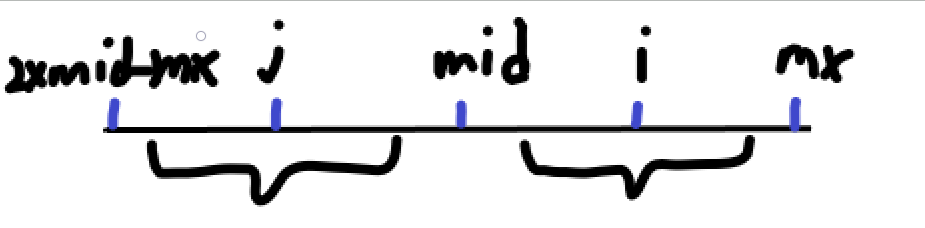
我們可以在 \(mid\) 的另一邊找到 \(i\) 的一個對稱點 \(j\),那麼 \([i-p_j,i+p_j]=[j-p_j,j+p_j]\)。但是要註意一下邊界情況,迴文的長度應該不超過 \(mid\times 2-mx\)(\(mx-i\) 也是一樣的),畢竟超過了就不能保證它相等了。
所以對於這種情況,我們可以將 \(p_i\) 的初值設為:\(min(p_{mid\times 2-i},mx-i)\)。然後暴力拓展即可。
- 當 \(i>mx\) 時:
我們找不到對稱點,只能暴力拓展。
最後考慮如何更新 \(mid\) 與 \(mx\):
我們需要能繼承的越多,那儘量要多些第一種情況,那麼當我們遇到某個右端點比 \(mx\) 大的時候,就可以更新了。
將 \(mid\to i,mx\to i+p_i\) 即可。
代碼
#include<bits/stdc++.h>
#define int long long
using namespace std;
const int N=22000005;
inline int read(){
int x=0,f=1;
char ch;
ch=getchar();
while(ch<'0'||ch>'9'){
if(ch=='-') f=-f;
ch=getchar();
}
while(ch>='0'&&ch<='9'){
x=x*10+(ch-'0');
ch=getchar();
}
return x*f;
}
int n;
char s[N],t[N];
int p[N];
void manacher(){
s[0]='@';
int q=0;
s[++q]='#';
for(int i=0;i<n;++i){
s[++q]=t[i];
s[++q]='#';
}
s[q+1]='%';//初始化
int mx=0,mid=0;
for(int i=1;i<=q;i++){
if(i<mx) p[i]=min(p[mid*2-i],mx-i);//繼承
while(s[i+p[i]+1]==s[i-p[i]-1]) ++p[i];//暴力拓展
if(p[i]+i>mx) mx=i+p[i],mid=i;//更新
}
}
signed main(){
cin>>t;
n=strlen(t);
manacher();
int ans=0;
for(int i=1;i<=2*n+1;++i)
ans=max(ans,p[i]);
cout<<ans;
return 0;
}


