
一直以來,大數據量一直是爆炸性增長,每天幾十 TB 的數據增量已經非常常見,但雲存儲相對來說還是不便宜的。眾多雲上的大數據用戶特別希望可以非常簡單快速的將文件移動到更實惠的 S3、OSS 上進行保存,這篇文章就來介紹如何使用 SeaTunnel 來進行到 OSS 的數據同步。 首先簡要介紹一下 Ap ...

一直以來,大數據量一直是爆炸性增長,每天幾十 TB 的數據增量已經非常常見,但雲存儲相對來說還是不便宜的。眾多雲上的大數據用戶特別希望可以非常簡單快速的將文件移動到更實惠的 S3、OSS 上進行保存,這篇文章就來介紹如何使用 SeaTunnel 來進行到 OSS 的數據同步。
首先簡要介紹一下 Apache SeaTunnel,SeaTunnel 專註於數據集成和數據同步,主要解決以下問題:
-
數據源多樣:常用的數據源有數百種,版本不相容。隨著新技術的出現,出現了更多的數據源。用戶很難找到能夠全面快速支持這些數據源的工具。
-
複雜同步場景:數據同步需要支持離線-全量同步、離線-增量同步、CDC、實時同步、全庫同步等多種同步場景。
-
資源需求高:現有的數據集成和數據同步工具往往需要大量的計算資源或 JDBC 連接資源來完成海量小表的實時同步。這在一定程度上加重了企業的負擔。
-
缺乏質量和監控:數據集成和同步過程經常會丟失或重覆數據。同步過程缺乏監控,無法直觀瞭解任務過程中數據的真實情況
SeaTunnel 支持海量數據的高效離線/實時同步, 每天可穩定高效同步數百億級數據,已經有 B 站,騰訊雲,微博,360,Shopee 等數百家公司生產使用。
下麵步入今天的正題,今天具體來說是講 Apache SeaTunnel 產品與阿裡雲 OSS 的集成。
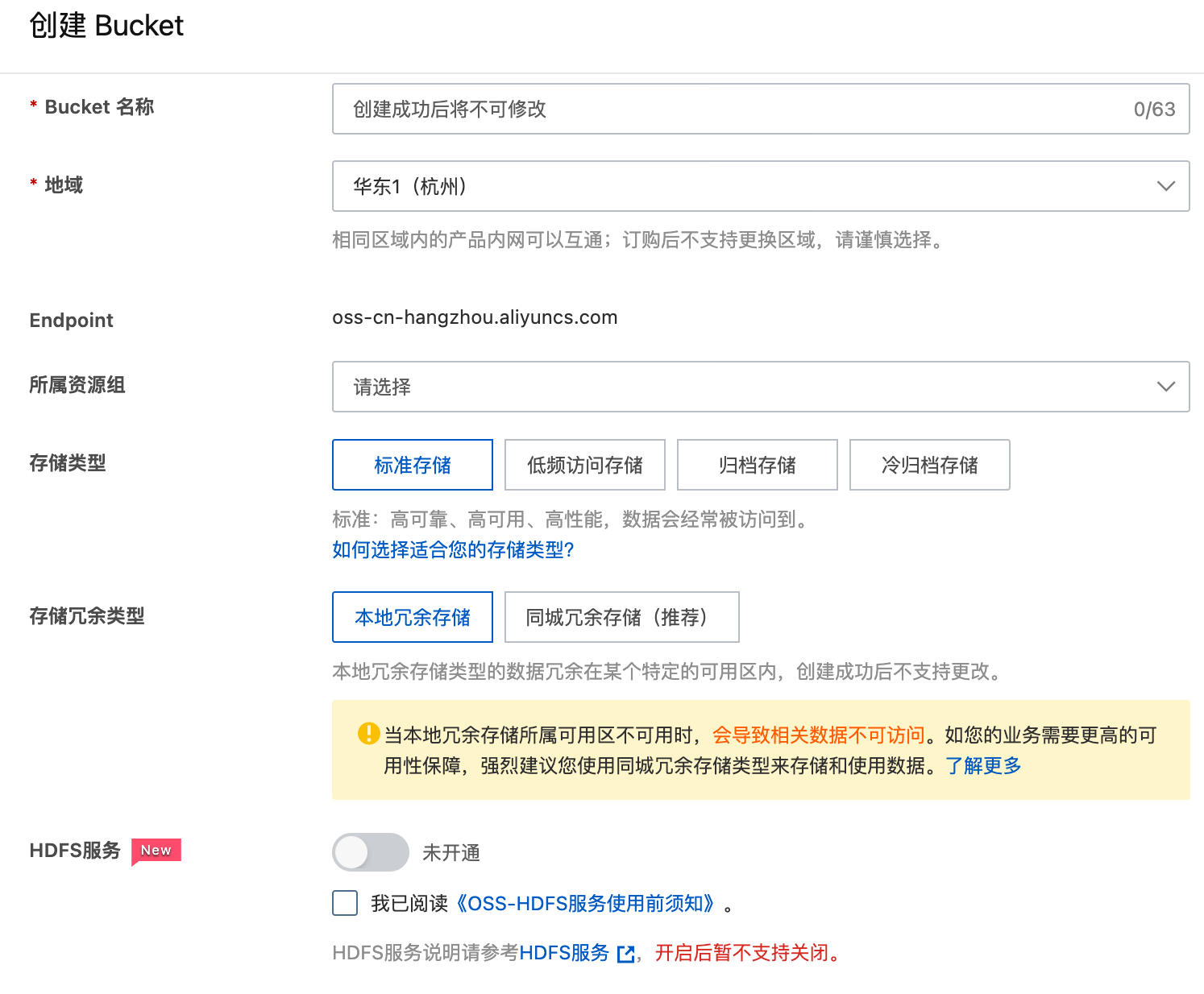
在阿裡雲 OSS 產品界面,開通 Bucket:
下麵是 SeaTunnel 的部署, SeaTunnel 支持多種部署方式: 單機,集群,K8s 等方式。由於 SeaTunnel 不依賴 Zookeeper 等第三方組件,所以整體部署非常簡單,具體請參考其官網:https://seatunnel.apache.org/docs/2.3.0/start-v2/locally/deployment
接下來是 SeaTunnel 使用過程,使用命令:
./bin/seatunnel.sh -m local -c ./config/localfile-oss.config
在 SeaTunnel 中,用戶可以通過 config 文件定製自己的數據同步需求,最大限度地發揮 SeaTunnel 的潛力。那麼接下來就給大家介紹一下如何配置 Config 文件
可以看到,config 文件包含幾個部分:env、source、transform、sink。不同的模塊有不同的功能。瞭解這些模塊後,您將瞭解 SeaTunnel 的工作原理。
用於添加一些引擎可選參數,無論是哪個引擎(Spark或Flink),這裡都要填寫相應的可選參數。
source 用於定義 SeaTunnel 需要從哪裡獲取數據,並將獲取的數據用於下一步。可以同時定義多個源。現在支持的來源檢查 SeaTunnel 的來源。每個 Source 都有自己特定的參數來定義如何取數據,SeaTunnel 也提取了每個 source 會用到的參數,比如parameter,用來指定 result_table_name 當前 source 產生的數據的名稱,方便供其他模塊後續使用。
本例中的 localfile-oss.config 配置文件內容介紹:
env {
# You can set SeaTunnel environment configuration here
execution.parallelism = 10
job.mode = "BATCH"
checkpoint.interval = 10000
#execution.checkpoint.interval = 10000
#execution.checkpoint.data-uri = "hdfs://localhost:9000/checkpoint"
}
source {
LocalFile {
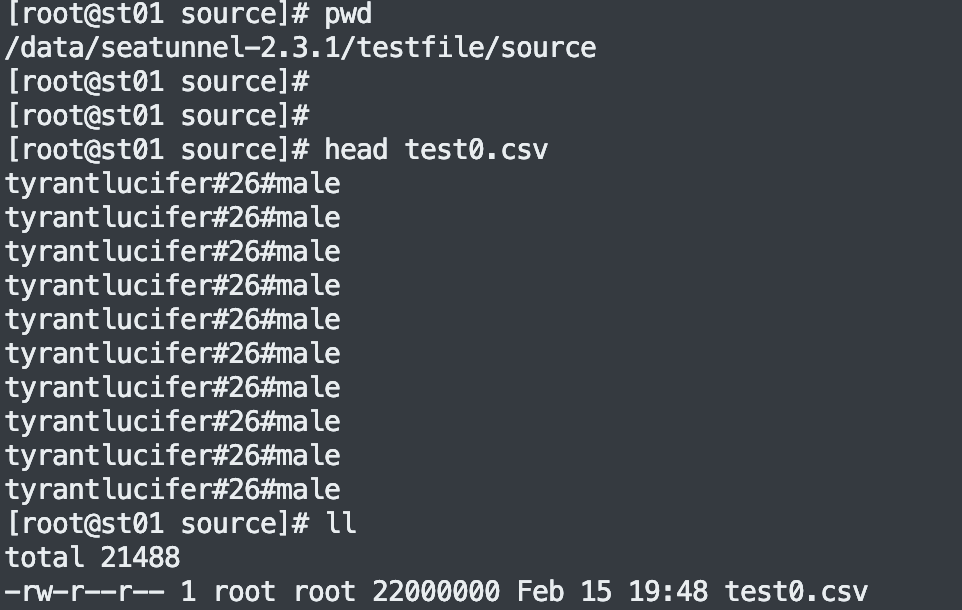
#本地待同步的數據文件夾, 本例子中只有一個 test0.csv 文件,具體內容參考下圖
path = "/data/seatunnel-2.3.1/testfile/source"
type = "csv"
delimiter = "#"
schema {
fields {
name = string
age = int
gender = string
}
}
}
}
sink {
OssJindoFile {
path="/seatunnel/oss03"
bucket = "oss://bucket123456654321234.cn-hangzhou.oss-dls.aliyuncs.com"
access_key = "I5t7VZyZSmMNwKsNv1LTADxW"
access_secret = "BinZ9J0zYxRbvG9wQUi6LiUjZElLTA"
endpoint = "cn-hangzhou.oss-dls.aliyuncs.com"
}
}
註:下圖本地待同步的數據文件夾, 本例子中只有一個 test0.csv 文件,具體內容
特別註意:如果是開通了 HDFS 的 OSS,有 2 個地方是不一樣的:1 是 bucket,1 是 endpoint 。如下紅色部分是開通了 HDFS 後的,被 “#” 註釋掉的是未開通 HDFS 的情況。
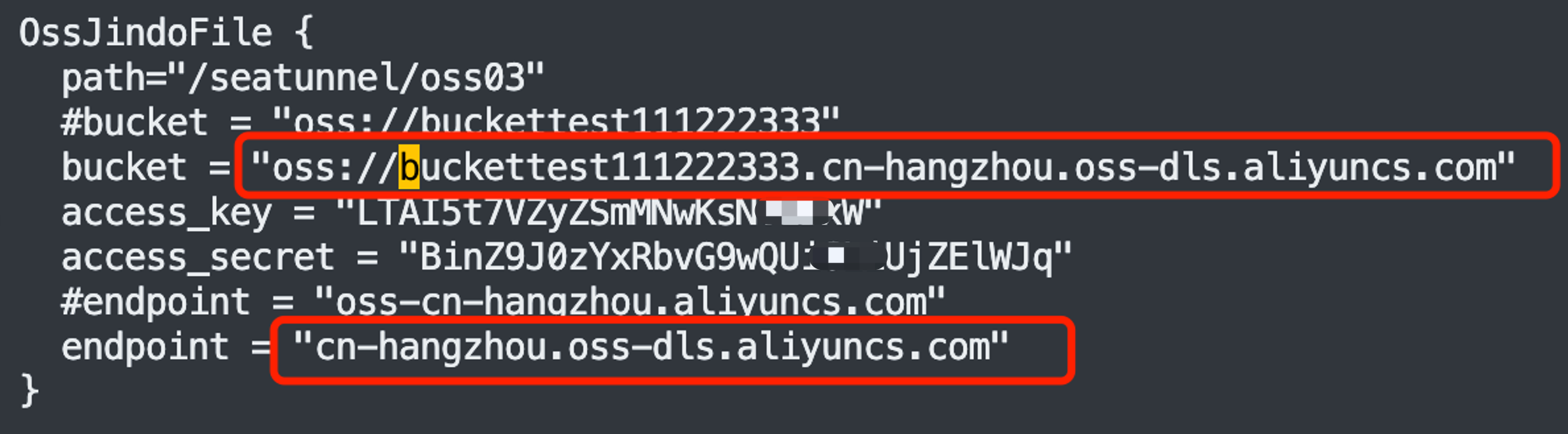
SeaTunnel 對這 2 種情況都是支持的,只是大家要註意一下配置 bucket 和 endpoint 時的不同!
執行運行命令後,我們可以從 SeaTunnel 控制台看下以下 SeaTunnel 本次同步情況的數據:
Job Statistic Information
Start Time : 2023-02-22 17:12:19
End Time : 2023-02-22 17:12:37
Total Time(s) : 18
Total Read Count : 10000000
Total Write Count : 10000000
Total Failed Count : 0
從阿裡雲界面上可以看到 OSS 端的監控數據:
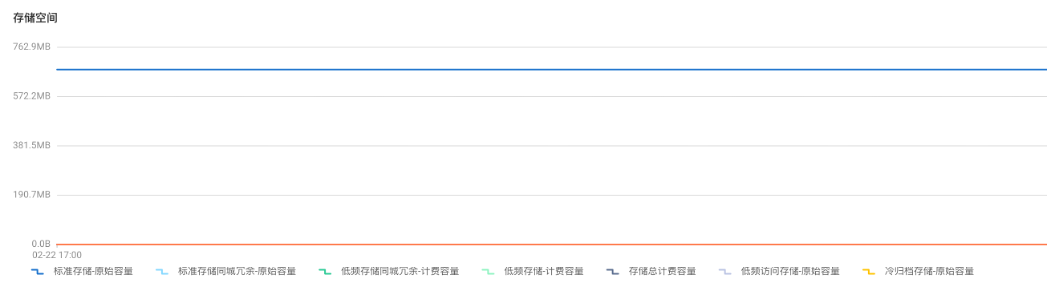
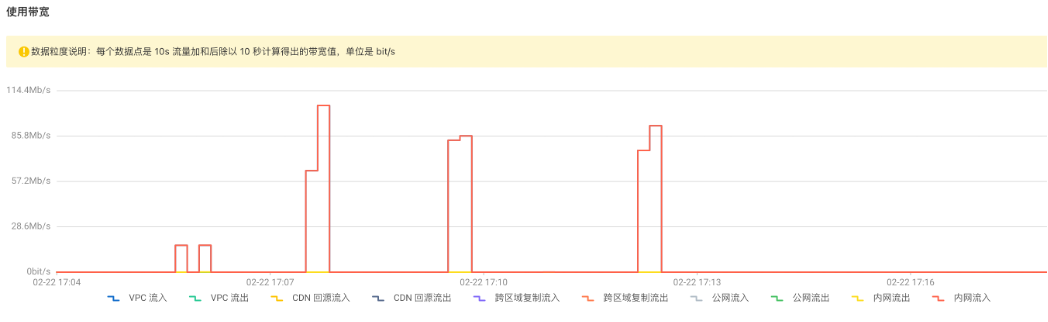
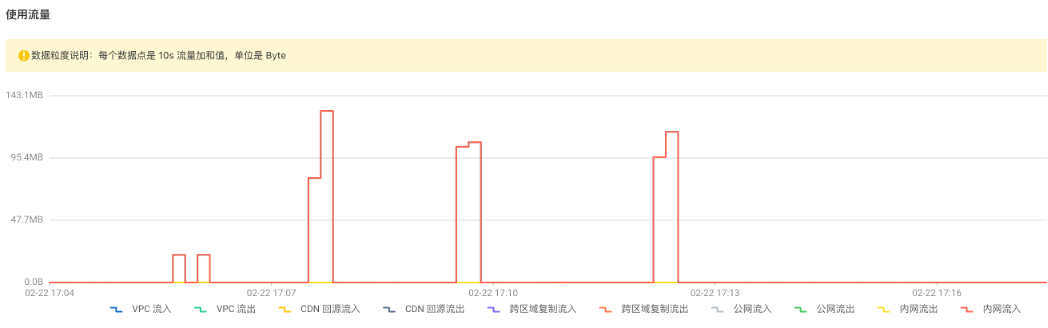
可以看出來 SeaTunnel 快速高效地同步了 1000萬數據量的本地文件!
最後,Apache SeaTunnel 目前已經支持了過百種數據源,併發布了 SeaTunnel Zeta 同步引擎,性能巨佳,還有群進行技術支持,歡迎對比,歡迎一試!感興趣的伙伴歡迎聯繫社區志願者微信: seatunnel1
參考:
1、https://seatunnel.apache.org/docs/2.3.0/start-v2/locally/deployment
2、https://seatunnel.apache.org/docs/2.3.0/start-v2/locally/quick-start-seatunnel-engine
3、https://seatunnel.apache.org
本文由 白鯨開源 提供發佈支持!


