
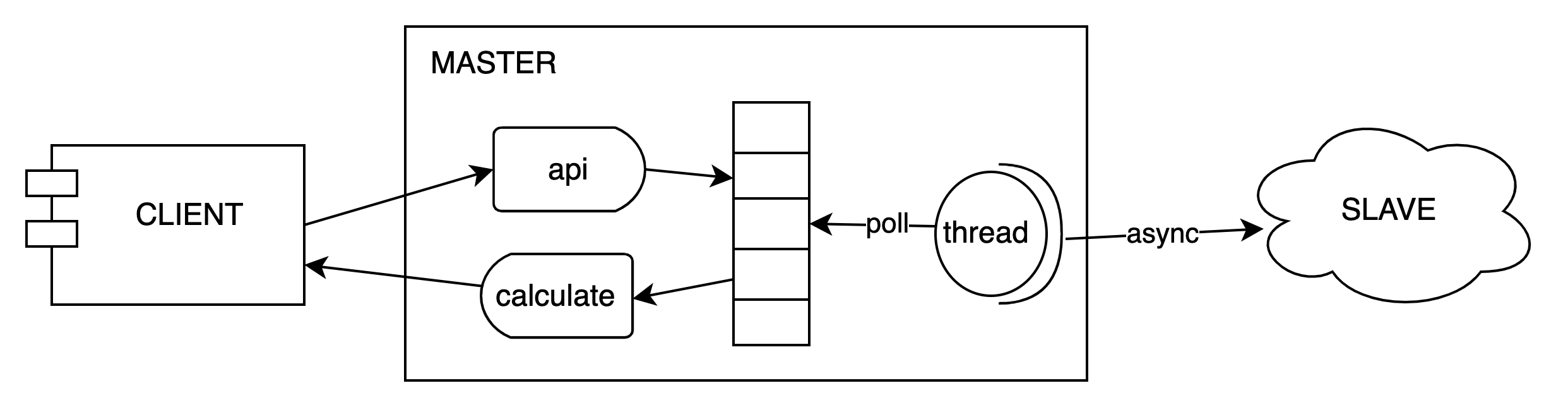
# 背景: ### 介紹 天網風控**靈璣**系統是基於記憶體計算實現的高吞吐低延遲線上計算服務,提供滑動或滾動視窗內的count、distinctCout、max、min、avg、sum、std及區間分佈類的線上統計計算服務。客戶端和服務端底層通過netty直接進行tcp通信,且服務端也是基於net ...
背景:
介紹
天網風控靈璣系統是基於記憶體計算實現的高吞吐低延遲線上計算服務,提供滑動或滾動視窗內的count、distinctCout、max、min、avg、sum、std及區間分佈類的線上統計計算服務。客戶端和服務端底層通過netty直接進行tcp通信,且服務端也是基於netty將數據備份到對應的slave集群。
低延遲的瓶頸
靈璣第1個版本經過大量優化,系統能提供較大的吞吐量。如果對客戶端設置10ms超時,服務端1wqps/core的流量下,可用率只能保證在98.9%左右,高併發情況下主要是gc導致可用率降低。如果基於cms 垃圾回收器。當一臺8c16g的機器在經過第二個版本優化後吞吐量超過20wqps的時候,那麼大概每4秒會產生一次gc。如果按照一次gc等於30ms。那麼至少分鐘顆粒度在gc時間的占比至少在(15*30/1000/60)=0.0075。也就意味著分鐘級別的tp992至少在30ms。不滿足相關業務的需求。
jdk17+ZGC
為瞭解決上述延遲過高的相關問題,JDK 11 開始推出了一種低延遲垃圾回收器 ZGC。ZGC 使用了一些新技術和優化演算法,可以將 GC 暫停時間控制在 10 毫秒以內,而在 JDK 17 的加持下,ZGC 的暫停時間甚至可以控制在亞毫秒級別。實測在平均停頓時間在10us左右,主要是基於一個染色指針和讀屏障做到大多數gc階段可以做到併發的,有興趣的同學可以瞭解下,並且jdk17是一個lts版本。
問題:
採用jdk17+zgc經過相關的壓測後,一切都在向著好的方向發展,但是在一種特殊場景壓測,需要將數據從北京數據中心同步給宿遷數據中心的時候,發現了一些詭異的事情
-
服務端容器的記憶體瘋漲,並且停止壓測後,記憶體只是非常緩慢的減少。
-
相關機器cpu一直保存在20%(已經無流量請求)
-
一直在次數不多的gc。大概每10s一次
排查之旅
記憶體泄漏排查
第一反應是遇到記憶體瘋漲和無法釋放該問題時,首先歸納為記憶體泄漏問題,感覺這題也簡單明瞭。開始相關記憶體泄漏檢查:先dump堆記憶體分析發現占用堆記憶體的是netty相關的對象,恰好前段時間也有個同學也分享了netty下的不合理使用netty byteBuf導致的記憶體泄漏,進一步增加了對netty記憶體泄露的懷疑。 於是開啟netty記憶體泄漏嚴格檢查模式 (加上jvm 參數Dio.netty.leakDetection.level=PARANOID),重新試跑並沒有發現相關記憶體泄漏日誌。好吧~!初步判定不是netty記憶體泄漏。
jdk與netty版本bug排查
會不會是netty與jdk17相容不好導致的bug? 回滾jdk8測試發現的確不存在這個問題,當時使用的是jdk17.0.7 版本。正好官方發佈了jdk17.0.8版本,並且看到版本介紹上有若幹的 Bug Fixes。所以又升級了jdk一個小版本,然而發現問題仍然在。會不會是netty的版本過低?正好看見gitup上也有類似的issue# https://github.com/netty/netty/issues/6125WriteBufferWaterMark's 並且在高版本疑似修複了該問題,修改了netty幾個版本重新壓測,然而發現問題仍然在。
直接原因定位與解決
經過上述兩次排查,發現問題比想象中複雜,應該深入分析下為什麼,重新梳理了下相關線索:
-
發現回滾至jdk8的時候,對應宿遷中心的集群接受到的備份數據量比北京中心發送的數據量低了很多
-
為什麼沒有流量了還一直有gc,cpu高應該是gc造成的(當時認為是zgc的記憶體的一些特性)
-
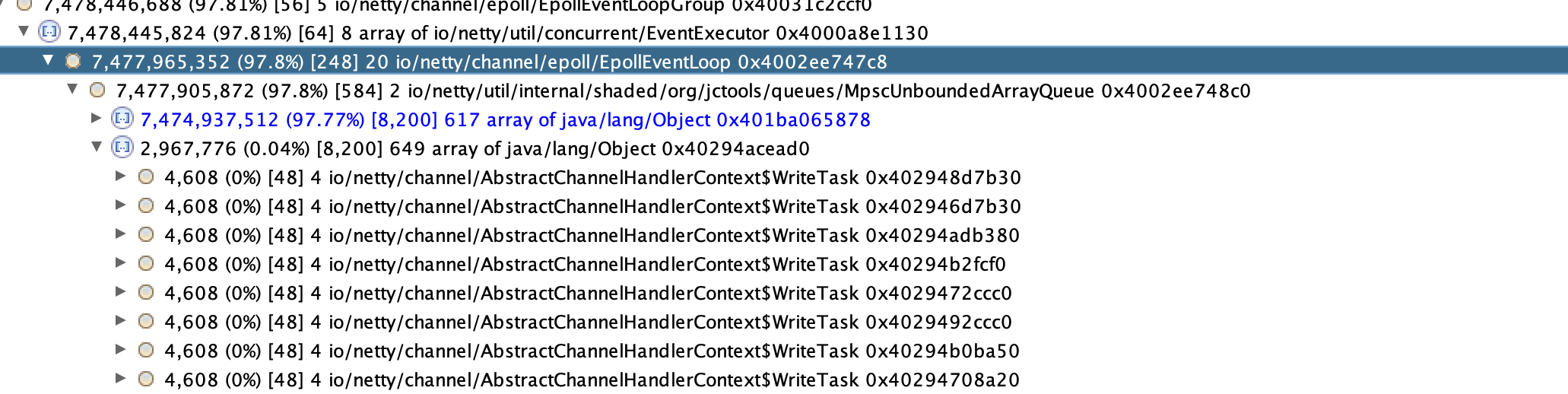
記憶體分析:為什麼netty的MpscUnboundedArrayQueue引用了大量的AbstractChannelHandlerContext$WriteTask對象,。MpscUnboundedArrayQueue是生產消費writeAndFlush任務隊列,WriteTask是相關的writeAndFlush的任務對象,正是因為大量的WriteTask對象及其引用導致了記憶體占用過高。
-
只有跨數據中心出現該問題,同數據中心數據壓測不會出現該問題。
分析過後已經有了基本的猜想,因為跨數據中心下機房延遲更大,單channel通道下已經沒法滿足同步數據能力,導致netty的eventLoop的消費能不足導致積壓。
解決方案:增加與備份數據節點的channel通道連接,採用connectionPool,每次批量同步數據的時候隨機選擇一個存活的channel進行數據通信。經過相關改造後發現問題得到瞭解決。
根因定位與解決
根因定位
雖然經過上述的改造,錶面上看似解決了問題,但是問題的根本原因還是沒有被髮現
-
1.如果是eventLoop消費能力不足,為什麼停止壓測後,相關記憶體只是緩慢減少,按理說應該是瘋狂的記憶體減少。
-
2.為什麼一直cpu在23%左右,按照平時的壓測數據,同步數據是一個流轉批的操作,最多也就消耗5%cpu 左右,多出來的cpu應該是gc造成的,但是數據同步應該並不多,不應該造成這麼多的gc壓力。
-
3.為什麼jdk8下不會存在該問題
推測應該是有個netty eventLoop消費耗時阻塞的操作導致消費能力大幅度下降。所以感覺還是netty的問題,於是開了netty的相關debug日誌。發現了一行關鍵日誌
[2023-08-23 11:16:16.163] DEBUG [] - io.netty.util.internal.PlatformDependent0 - direct buffer constructor: unavailable: Reflective setAccessible(true) disabled
順著這條日誌找到了本次的問題根因,為什麼一個直接記憶體的構造器不能使用會導致我們系統WriteTask消費阻塞, 帶著這個目的去查看相關的源碼。
源碼分析
- 一) netty 預設會用PooledByteBufAllocator來分配直接記憶體,採用類似jmelloc的記憶體池機制,每次記憶體不足的時候會通過創建io.netty.buffer.PoolArena.DirectArena#newChunk去預占申請記憶體。
protected PoolChunk<ByteBuffer> newChunk() {
// 關鍵代碼
ByteBuffer memory = allocateDirect(chunkSize);
}
}
- 二) allocateDirect()是申請直接記憶體的邏輯。大致就是如果能採用底層unsafe去申請、釋放直接記憶體和反射創建ByteBuffer對象,那麼就採用unsafe。否則就直接調用java的Api ByteBuffer.allocateDirect來直接分配記憶體並且採用自帶的Cleaner來釋放記憶體。這裡 PlatformDependent.useDirectBufferNoCleaner 是個關鍵點,其實就是USE_DIRECT_BUFFER_NO_CLEANER參數配置
PlatformDependent.useDirectBufferNoCleaner() ?
PlatformDependent.allocateDirectNoCleaner(capacity) : ByteBuffer.allocateDirect(capacity);
-
三) USE_DIRECT_BUFFER_NO_CLEANER 參數邏輯配置在PlatformDependent 類的static{}裡面。
關鍵邏輯:maxDirectMemory==0和!hasUnsafe()在jdk17下沒有特殊配置都是不滿足條件的,關鍵是PlatformDependent0.hasDirectBufferNoCleanerConstructor的判斷邏輯
if (maxDirectMemory == 0 || !hasUnsafe() || !PlatformDependent0.hasDirectBufferNoCleanerConstructor()) {
USE_DIRECT_BUFFER_NO_CLEANER = false;
} else {
USE_DIRECT_BUFFER_NO_CLEANER = true;
- 四) PlatformDependent0.hasDirectBufferNoCleanerConstructor()的判斷是看PlatformDependent0的DIRECT_BUFFER_CONSTRUCTOR是否NULL,回到了剛開的debug日誌,我們是可以看到在預設情況下DIRECT_BUFFER_CONSTRUCTOR該構造器是unavailable的(unavailable則為NULL)。以下代碼具體的邏輯判斷及其偽代碼。
1.開啟條件一:jdk9及其以上必須要開啟jvm參數 -io.netty.tryReflectionSetAccessible參數
2.開啟條件二:能反射獲取到一個 private DirectByteBuffer構造器,該構造器是通過記憶體地址和大小來構造DirectByteBuffer.(備註:如果在jdk9以上對java.nio有模塊許可權限制,需要加上jvm啟動參數--add-opens=java.base/java.nio=ALL-UNNAMED ,否則會報Unable to make private java.nio.DirectByteBuffer(long,int) accessible: module java.base does not "opens java.nio" to unnamed module)
所以這裡我們預設是沒有開啟這兩個jvm參數的,那麼DIRECT_BUFFER_CONSTRUCTOR為空值,對應第二部PlatformDependent.useDirectBufferNoCleaner()為false。
// 偽代碼,實際與這不一致
ByteBuffer direct = ByteBuffer.allocateDirect(1);
if(SystemPropertyUtil.getBoolean("io.netty.tryReflectionSetAccessible",
javaVersion() < 9 || RUNNING_IN_NATIVE_IMAGE)) {
DIRECT_BUFFER_CONSTRUCTOR =
direct.getClass().getDeclaredConstructor(long.class, int.class)
}
- 五) 現在回到第2步驟,發現PlatformDependent.useDirectBufferNoCleaner()在jdk高版本下預設值是false。那麼每次申請直接記憶體都是通過ByteBuffer.allocateDirect來創建。那麼到這個時候就已經定位到相關根因了,通過ByteBuffer.allocateDirect來申請直接記憶體,如果記憶體不足的時候會強制系統System.Gc(),並且會同步等待DirectByteBuffer通過Cleaner的虛引用回收記憶體。下麵是ByteBuffer.allocateDirect預占記憶體(reserveMemory)的關鍵代碼。大概邏輯是 觸達申請的最大的直接記憶體->判斷是否有相關的對象在gc回收->沒有在回收則主動觸發System.gc()來觸發回收->在同步迴圈最多等待MAX_SLEEPS次數看是否有足夠的直接記憶體。整個同步等待邏輯在親測在jdk17版本最多能1秒以上。
所以最根本原因:如果這個時候我們的netty的消費者EventLoop處理消費因為申請直接記憶體在達到最大記憶體的場景,那麼就會導致有大量的任務消費都會同步去等待申請直接記憶體上。並且如果沒有足夠的的直接記憶體,那麼就會成為大面積的消費阻塞。
static void reserveMemory(long size, long cap) {
if (!MEMORY_LIMIT_SET && VM.initLevel() >= 1) {
MAX_MEMORY = VM.maxDirectMemory();
MEMORY_LIMIT_SET = true;
}
// optimist!
if (tryReserveMemory(size, cap)) {
return;
}
final JavaLangRefAccess jlra = SharedSecrets.getJavaLangRefAccess();
boolean interrupted = false;
try {
do {
try {
refprocActive = jlra.waitForReferenceProcessing();
} catch (InterruptedException e) {
// Defer interrupts and keep trying.
interrupted = true;
refprocActive = true;
}
if (tryReserveMemory(size, cap)) {
return;
}
} while (refprocActive);
// trigger VM's Reference processing
System.gc();
int sleeps = 0;
while (true) {
if (tryReserveMemory(size, cap)) {
return;
}
if (sleeps >= MAX_SLEEPS) {
break;
}
try {
if (!jlra.waitForReferenceProcessing()) {
Thread.sleep(sleepTime);
sleepTime <<= 1;
sleeps++;
}
} catch (InterruptedException e) {
interrupted = true;
}
}
// no luck
throw new OutOfMemoryError
("Cannot reserve "
+ size + " bytes of direct buffer memory (allocated: "
+ RESERVED_MEMORY.get() + ", limit: " + MAX_MEMORY +")");
} finally {
if (interrupted) {
// don't swallow interrupts
Thread.currentThread().interrupt();
}
}
}
- 六) 雖然我們看到了阻塞的原因,但是為什麼jdk8下為什麼就不會阻塞從4步驟中看到java 9以下是設置了DIRECT_BUFFER_CONSTRUCTOR的,因此採用的是PlatformDependent.allocateDirectNoCleaner進行記憶體分配。 以下是具體的介紹和關鍵代碼
步驟一:申請記憶體前:通過全局記憶體計數器DIRECT_MEMORY_COUNTER,在每次申請記憶體的時候調用incrementMemoryCounter 增加相關的size,如果達到相關DIRECT_MEMORY_LIMIT(預設是-XX:MaxDirectMemorySize) 參數則直接拋出異常,而不會去同步gc等待導致大量耗時。。
步驟二:分配記憶體allocateDirectNoCleaner:是通過unsafe去申請記憶體,再用構造器DIRECT_BUFFER_CONSTRUCTOR通過記憶體地址和大小來構造DirectBuffer。釋放也可以通過unsafe.freeMemory根據記憶體地址來釋放相關記憶體,而不是通過java 自帶的cleaner來釋放記憶體。
public static ByteBuffer allocateDirectNoCleaner(int capacity) {
assert USE_DIRECT_BUFFER_NO_CLEANER;
incrementMemoryCounter(capacity);
try {
return PlatformDependent0.allocateDirectNoCleaner(capacity);
} catch (Throwable e) {
decrementMemoryCounter(capacity);
throwException(e);
return null; }
}
private static void incrementMemoryCounter(int capacity) {
if (DIRECT_MEMORY_COUNTER != null) {
long newUsedMemory = DIRECT_MEMORY_COUNTER.addAndGet(capacity);
if (newUsedMemory > DIRECT_MEMORY_LIMIT) {
DIRECT_MEMORY_COUNTER.addAndGet(-capacity);
throw new OutOfDirectMemoryError("failed to allocate " + capacity
+ " byte(s) of direct memory (used: " + (newUsedMemory - capacity)
+ ", max: " + DIRECT_MEMORY_LIMIT + ')');
}
}
}
static ByteBuffer allocateDirectNoCleaner(int capacity) {
return newDirectBuffer(UNSAFE.allocateMemory(Math.max(1, capacity)), capacity);
}
- 經過上述的源碼分析,已經看到了根本原因,就是ByteBuffer.allocateDirect gc 同步等待直接記憶體釋放導致消費能力嚴重不足導致的,並且在最大直接記憶體不足的情況下,大面積的消費阻塞耗時在申請直接記憶體,導致消費WriteTask能力接近於0,記憶體從而無法下降
總結
1.流程圖:
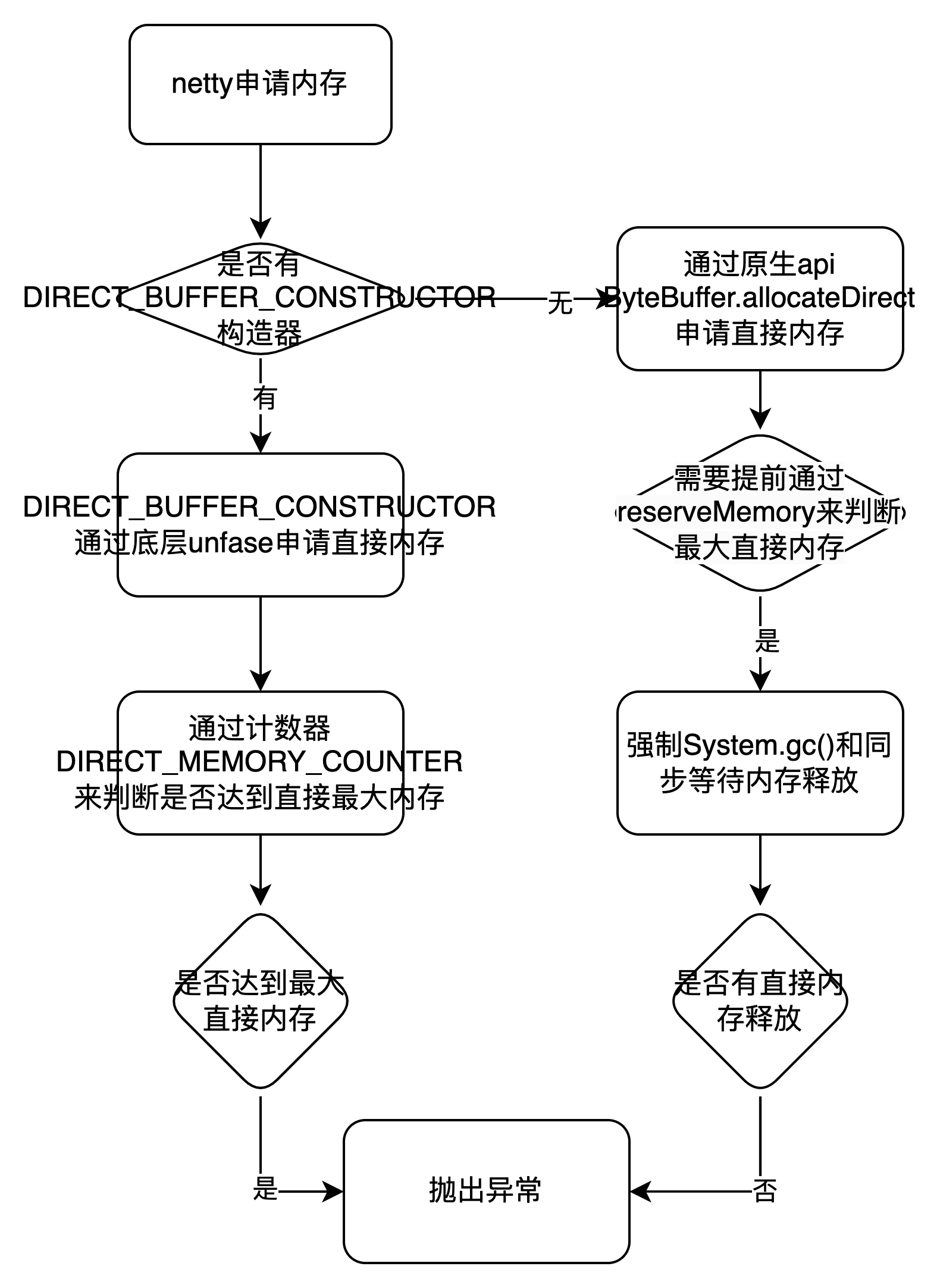
2.直接原因:
- 跨數據中心同步數據單channel管道同步數據能力不足,導致tcp環阻塞。從而導致netty eventLoop的消費WriteTask任務(WriteAndFlush)中的write能力大於flush能力,因此申請的大量的直接記憶體存放在ChannelOutboundBuffer#unflushedEntry鏈表中沒法flush。
3.根本原因:
- netty在jdk高版本需要手動添加jvm參數 -add-opens=java.base/java.nio=ALL-UNNAMED和-io.netty.tryReflectionSetAccessible 來開啟採用直接調用底層unsafe來申請記憶體,如果不開啟那麼netty申請記憶體採用ByteBuffer.allocateDirect來申請直接記憶體,如果EventLoop消費任務申請的直接記憶體達到最大直接記憶體場景,那麼就會導致有大量的任務消費都會同步去等待申請直接記憶體上。並且如果沒有釋放足夠的直接記憶體,那麼就會成為大面積的消費阻塞,也同時導致大量的對象累積在netty的無界隊列MpscUnboundedArrayQueue中。
4.反思與定位問題慢的原因:
-
預設同步數據這裡不會是系統瓶頸,沒有加上lowWaterMark和highWaterMark水位線的判斷(socketChannel.isWritable()),如果同步數據達到系統瓶頸應該提前能感知到拋出異常。
-
同步數據的時候調用writeAndFlush應該加上相關的異常監聽器(以下代碼2),若果能提前感知到異常OutOfMemoryError那麼更方便排查到相關問題。
(1)ChannelFuture writeAndFlush(Object msg)
(2)ChannelFuture writeAndFlush(Object msg, ChannelPromise promise);
-
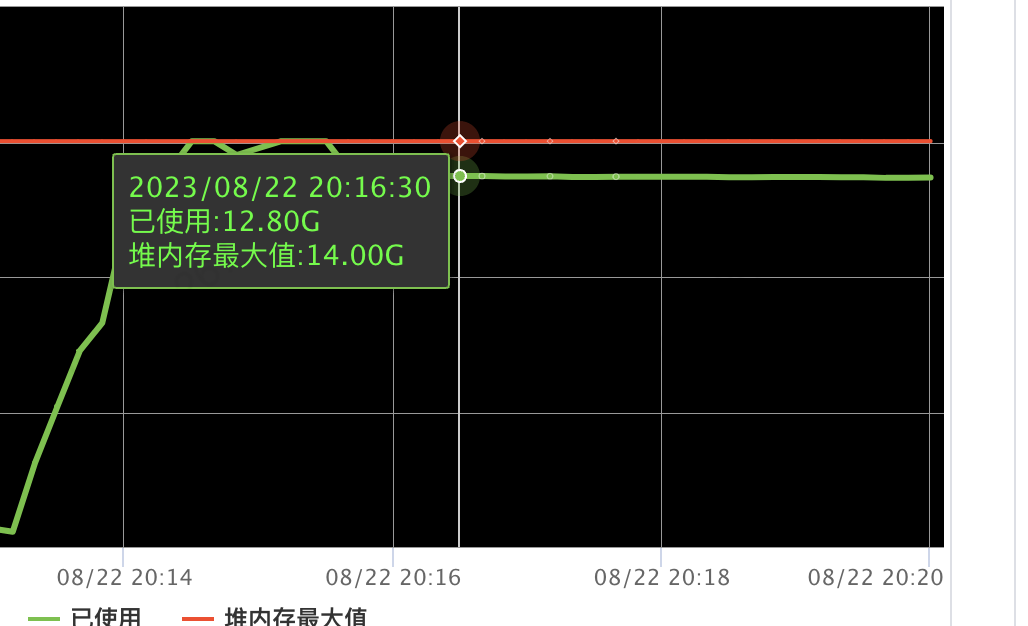
jdk17下監控系統看到的非堆記憶體監控並未與系統實際使用的直接記憶體統計一致,導致開始定位問題無法定位到直接記憶體已經達到最大值,從而並未往這個方案思考。
-
相關引用的中間件底層通信也是依賴於netty通信,如果有類似的數據同步也可能會觸發類似的問題。特別ump在高版本和titan使用netty的時候是進行了shade打包的,並且相關的jvm參數也被修改,雖然不會觸發該bug,但是也可能導致觸發系統gc。
ump高版本:jvm參數修改(低版本直接採用了底層socket通信,未使用netty和創建ByteBuffer) io.netty.tryReflectionSetAccessible->ump.profiler.shade.io.netty.tryReflectionSetAccessible
titan:jvm參數修改:io.netty.tryReflectionSetAccessible->titan.profiler.shade.io.netty.tryReflectionSetAccessible
作者:京東零售 劉鵬
來源:京東雲開發者社區 轉載請註明來源


