
1、伺服器mysql資料庫本地連接開發3306有安全風險,開發和運營過程中往往需要本地操作資料庫,遠程上去操作資料庫非常的不方便 2、在本地建隧道連接遠程資料庫,關閉伺服器連接,資料庫連接自動中斷,安全又方便 3、下麵是具體的操作流程,需要的小伙伴可以參考使用 圖1:選擇目標主機-》右鍵點擊屬性-》 ...
問題引出
在資料庫系統中對於文件I/O管理,通常有兩種選擇
- 開發者自己實現buffer bool來管理文件I/O讀入記憶體的數據
- 使用Linux操作系統實現的MMAP系統調用映射到用戶地址空間,並且利用對開發者透明的page cache來實現頁面的換入換出
理論介紹
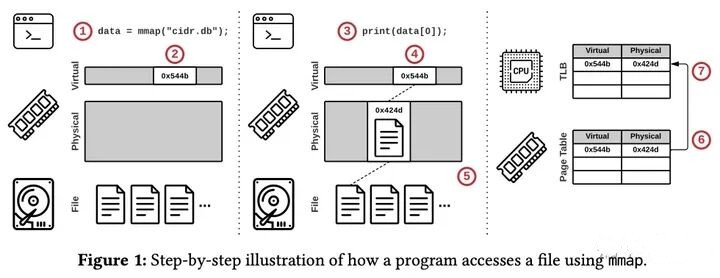
- 程式調用MMAP返回了指向文件內容的指針
- 操作系統保留了一部分虛擬地址空間,但是並沒有開始載入文件
- 程式開始使用指針獲取文件的內容
- 操作系統嘗試在物理記憶體獲取記憶體頁
- 由於記憶體頁此時不存在,因此觸發了頁錯誤,開始從物理存儲將第3步獲取的那部分內容載入到物理記憶體頁中
- 操作系統將虛擬地址映射到物理地址的頁表項(Page Table Entry)加入到頁表中
- 上述操作使用的CPU核心會將頁表項載入到頁表緩存(TLB)中
mmap的問題
問題1 事務安全
由於MMAP中頁面寫回存儲的時機不受程式控制,因此當commit還沒有發生時,可能會有一部分臟頁面已經寫回存儲了。此時原子性就會失效,在過程中的查詢會看到中間狀態。
問題2 I/O停頓
由於MMAP將文件載入到記憶體的過程是操作系統控制的,所以無法保證將要查詢的頁面在記憶體中,這時就會出現page cache的換入換出,導致I/O停頓。
問題3 錯誤處理
首先是MMAP對文件內容的校驗要以單個頁面為單位,不能基於多個頁面來做,因為有可能要使用的頁面會被換出。另外,對於一些使用記憶體不安全語言寫的資料庫系統(感覺大部分都是用記憶體不安全的C++寫的),指針錯誤可能導致頁面問題。使用buffer pool可以通過寫入前的檢查規避這個問題,但是MMAP會默默將錯誤的頁面寫到存儲中。
還有,MMAP要應對的系統調用會出現的SIGBUS信號報錯,相比之下使用其他I/O方式的buffer pool就能比較輕鬆的處理I/O錯誤。
問題4 性能問題
業界裡面大家普遍認為MMAP比傳統read/write更快,這主要基於以下兩點原因:
- 負責文件映射操作,並且處理page fault的是內核,而不是應用程式
- MMAP幫助避免了用戶空間中的額外的複製操作,相應的也減少了記憶體的占用
MMAP相對於傳統read/write I/O在目前高帶寬的存儲設備上是更差的。,原因如下:
- 單線程的頁面換出: 頁面換出是單線程的(使用kswapd),這點與CPU相關
- TLB shootdowns 當一個頁面失效時,每個核心的TLB都需要一次中斷來做刷新操作,這個操作可能會消耗幾千個時鐘周期,是非常耗時的。
RavenDB的CEO Reply
在構建資料庫時,使用 mmap 具有以下優點,操作系統將負責:
- 從磁碟讀取數據
- 讀取相同數據的不同線程之間的併發性
- 緩存和緩衝區管理
- 從記憶體中逐出頁
- 與機器中的其他進程很好地配合
- 跟蹤臟頁並寫入磁碟
對於 mmap 版本,我們需要計算頁面的地址,僅此而已。對於手動緩衝池,我們需要處理的任務列表很長。其中一些要求我們確保線程安全。例如,如果我們將一個頁面交給一個事務,我們需要跟蹤該頁面的狀態是否正在使用中。在交易完成之前,我們無法逐出此頁面。這意味著我們可能需要進行原子引用計數,這可能會非常高的成本。
實際上,資料庫中的數據訪問實際上並不是隨機的,即使您正在執行隨機讀取也是如此。有些頁面幾乎總是會被引用。B+樹中的根頁面就是一個很好的例子。它總是會被使用。在原子引用計數下,該頁面將成為瓶頸。
忽略緩衝池管理的這種開銷意味著您實際上並沒有比較等效的結構。我還應該指出,我可能忘記了緩衝池還需要管理的其他一些任務,這使它的生命周期大大複雜化。 這一點的原因是那裡有一個互斥鎖(以及鎖下的 I/O),這對於許多緩衝池來說是相當典型的。不考慮緩衝池管理的開銷會嚴重扭曲論文的結果。
解決4個問題
問題1 事務安全
作者並不在乎數據是否在我背後寫入記憶體,而關心的是 MVCC(一個與緩衝區管理完全分開的問題)
當事務提交並且較舊的事務不再需要舊版本的數據時,我可以將數據從修改後的緩衝區推送到 mmap 區域。這往往相當快(考慮到我基本上是在做 memcpy(),它以記憶體速度運行),除非必須將數據分頁
問題2 I/O停頓
作者實際措施是用一個專用線程來處理這種情況。實際上,這與使用非同步 I/O 處理它的方式並沒有太大區別。
另一個要處理的考慮因素是在內核級別映射的成本。我不是在談論 I/O 成本,但是如果您有許多線程出錯頁面,則會遇到頁表鎖定問題。我們之前遇到過這種情況,這被認為是操作系統級別的錯誤,但它顯然對資料庫有影響。但實際上,在大多數情況下,記憶體管理的開銷是相同的。如果您通過 mmap 閱讀或直接分配,則需要編排一些事情。請註意,如果您正在大量分配/釋放,則相同的頁表鎖定也會生效,因為您也在修改流程頁表。
問題3 錯誤處理
作者認為對於資料庫,處理 I/O 錯誤只有一個正確答案。崩潰,然後從頭開始運行恢復。如果 I/O 系統返回了錯誤,則不再有任何方法可以知道該錯誤的狀態。恢復的唯一方法是停止,重新載入所有內容(應用 WAL、運行恢復等)並恢復到穩定狀態。
問題4 性能問題
- 頁表爭用
- 單線程頁面逐出
- TLB擊落
第一個問題是我過去遇到過的問題。這是操作系統中的一個錯誤,已修複。在Windows和Linux中不再有單頁表。
另一方面,單線程驅逐是我們從未遇到過的事情。使用 Voron,我們使用MAP_SHARED映射記憶體,大多數時候,記憶體並不臟。如果系統需要記憶體,則只需丟棄未修改的共用頁面的記憶體即可在分配頁面時執行此操作。在此模型中,我們通常將大部分記憶體視為共用的、乾凈的。因此,驅逐事物的壓力並不大,可以根據需要進行。
TLB擊落問題不是我們曾經遇到過的問題。我們已經在具有4GB RAM的Raspberry PI上運行TB範圍資料庫,併在基準測試中對其進行了測試(遠遠超過記憶體容量)。有趣的是,B+Tree 性質意味著樹的上層已經在記憶體中,所以我們最終每個請求都有一個頁面錯誤。為了以顯著的方式實際觀察TLS擊落的成本,您需要具備:
- 非常快的 I/O
- 顯著超出記憶體的工作集
- 無需執行其他處理請求的工作


