
當應用開始脫離單機運行和訪問時,服務發現就誕生了。目前的網路架構是每個主機都有⼀個獨立的 IP 地址,服務發現基本都是通過某種方式獲取到服務所部署的 IP 地址。 DNS 協議是最早將⼀個網路名稱翻譯為網路 IP 的協議,在最初的架構選型中,DNS+LVS+Nginx 基本滿足所有 RESTful ...
當應用開始脫離單機運行和訪問時,服務發現就誕生了。目前的網路架構是每個主機都有⼀個獨立的 IP 地址,服務發現基本都是通過某種方式獲取到服務所部署的 IP 地址。
DNS 協議是最早將⼀個網路名稱翻譯為網路 IP 的協議,在最初的架構選型中,DNS+LVS+Nginx 基本滿足所有 RESTful 服務的發現,此時服務的 IP 列表通常配置在 nginx 或 LVS。後來出現 RPC 服務,服務的上下線更加頻繁,人們開始尋求⼀種能夠支持動態上下線並且推送 IP 列表變化的註冊中心產品。
互聯網軟體行業普遍熱捧開源產品,因為開源產品代碼透明、可以參與共建、有社區進行交流和學習,當然更重要是免費。個人開發者或者中小型公司往往會將開源產品作為選型首選。
1 開源產品
1.1 Zookeeper
經典服務註冊中心產品(雖然它最初的定位並不在於此),在很長⼀段時間里,是國人在提起 RPC 服務註冊中心時心裡想到的唯⼀選擇,這很大程度上與 Dubbo 在中國的普及程度有關。
1.2 Consul 和 Eureka
都出現於 2014 年:
- Consul 在設計上把很多分散式服務治理上要用到的功能都包含在內,可以支持服務註冊、健康檢查、配置管理、Service Mesh 等
- Eureka借微服務概念流行,與 SpringCloud 生態的深度結合,也獲取了大量的用戶
1.3 Nacos
則攜帶著阿裡巴巴大規模服務生產經驗,試圖在服務註冊和配置管理這個市場上,提供給用戶⼀個新的選擇。
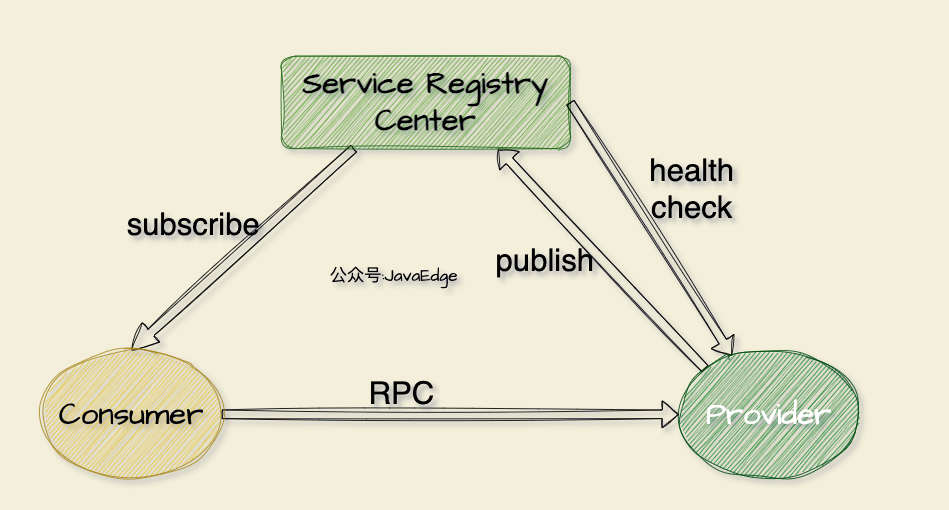
圖 1 服務發現:
1.4 開源產品的優勢
開發人員可以去閱讀源代碼,理解產品的功能設計和架構設計,同時也可以通過本地部署來測試性能,隨之而來的是各種產品的對比文章。
不過當前關於註冊中心的對比,往往停留在錶面的功能對比上,對架構或者性能並沒深入探討。
1.5 痛點
是服務註冊中心往往隱藏在服務框架背後,作為默默支持的產品。優秀的服務框架往往支持多種配置中心,但是註冊中心的選擇依然強關聯與服務框架,⼀種普遍的情況是⼀種服務框架會帶⼀個預設的服務註冊中心。這樣雖然免去了用戶在選型上的煩惱,但是單個註冊中心的局限性,導致用戶使用多個服務框架時,必須部署多套完全不同的註冊中心,這些註冊中心之間的數據協同也是⼀個問題。
本文從各個角度深度介紹 Nacos 註冊中心的設計原理,並試圖從我們的經驗和調研中總結和闡述服務註冊中心產品設計上應該去遵循和考慮的要點。
2 數據模型
註冊中心的核心數據:
- 服務的名字
- 它對應的網路地址
當服務註冊了多個實例時,我們需要對不健康的實例過濾或針對實例的⼀些特征進行流量分配,就需要在實例存儲⼀些如健康狀態、權重等屬性。隨服務規模擴大,漸漸的又需要在整個服務級別設定⼀些許可權規則、以及對所有實例都生效的⼀些開關,於是在服務級別又會設立⼀些屬性。再往後,我們又發現單個服務的實例又會有劃分為多個子集的需求,例如⼀個服務是多機房部署的,那麼可能需要對每個機房的實例做不同的配置,這樣又需要在服務和實例之間再設定⼀個數據級別。
對比
- Zookeeper 沒有針對服務發現設計數據模型,它的數據是以⼀種更加抽象的樹形 K-V 組織的,因此理論上可以存儲任何語義的數據
- Eureka 或者 Consul 都做到實例級的數據擴展,可滿足大部分的場景,不過無法滿足大規模和多環境的服務數據存儲
- Nacos 在經過內部多年生產經驗後提煉出的數據模型,則是⼀種服務-集群-實例的三層模型。基本滿足服務在所有場景下的數據存儲和管理。
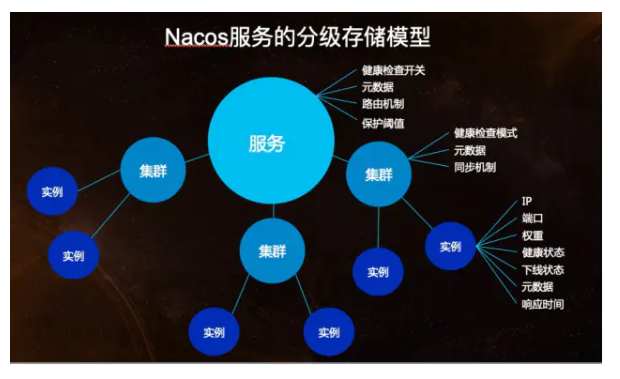
Nacos 的數據模型雖然相對複雜,但它不強制你使用它裡面的所有數據,在大多數場景下,你可以選擇忽略這些數據屬性,此時可降維成和 Eureka 和 Consul ⼀樣的數據模型。
數據的隔離模型
作為⼀個共用服務型的組件,需要能夠在多個用戶或者業務方使用情況下,保證數據的隔離和安全,這在稍微大⼀點的業務場景中非常常見。另⼀方面服務註冊中心往往會支持雲上部署,此時就要求服務註冊中心的數據模型能夠適配雲上的通用模型。
Zookeeper、Consul 和 Eureka 在開源層面都沒有很明確的針對服務隔離的模型,Nacos 則在⼀開始就考慮到如何讓用戶能夠以多種維度進行數據隔離,同時能夠平滑的遷移到阿裡雲上對應的商業化產品。
圖 3 服務的四層的數據邏輯隔離模型:
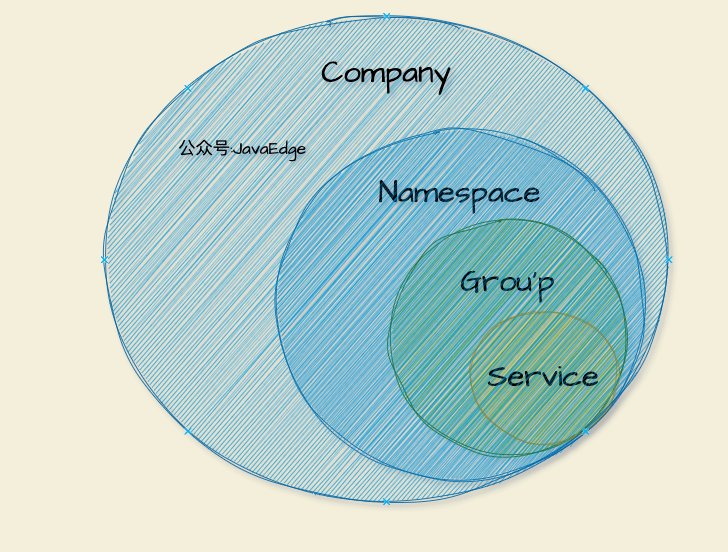
用戶賬號對應可能是⼀個企業或獨立的個體,這個數據⼀般情況不會透傳到服務註冊中心。⼀個用戶賬號可新建多個命名空間,每個命名空間對應⼀個客戶端實例,這個命名空間對應的註冊中心物理集群是可以根據規則進行路由的,這樣可以讓註冊中心內部的升級和遷移對用戶無感知,同時根據用戶的級別,為用戶提供不同服務級別的物理集群。
再往下是服務分組和服務名組成的二維服務標識,可以滿足介面級別的服務隔離。
Nacos 1.0.0 介紹的另外⼀個新特性是:臨時實例和持久化實例。在定義上區分臨時實例和持久化實例的關鍵是健康檢查的方式。臨時實例使用客戶端上報模式,而持久化實例使用服務端反向探測模式。臨時實例需要能夠自動摘除不健康實例,而且無需持久化存儲實例,那麼這種實例就適用於類 Gossip 的協議。右邊的持久化實例使用服務端探測的健康檢查方式,因為客戶端不會上報心跳,那麼自然就不能去自動摘除下線的實例。
圖 4 臨時實例和持久化實例:
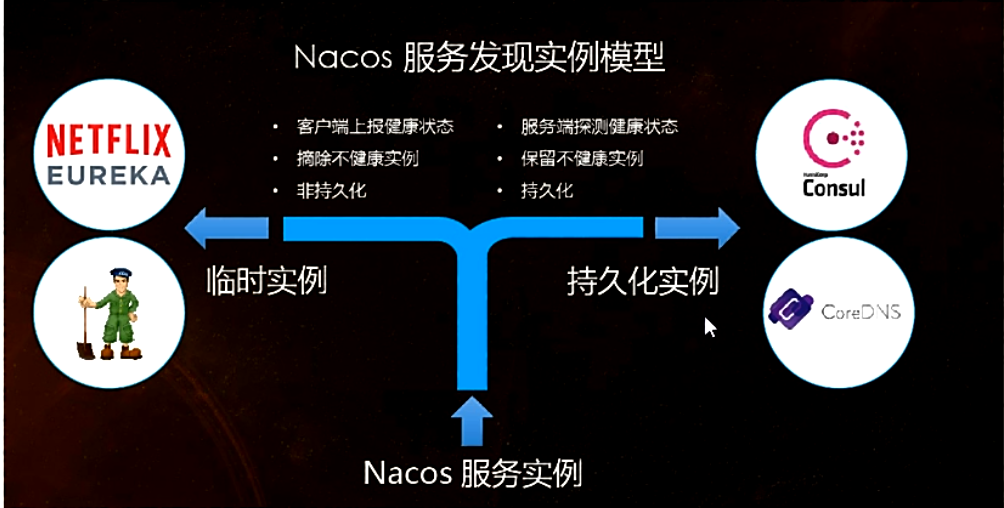
大中型公司,這兩種類型的服務都有:
- ⼀些基礎組件如資料庫、緩存等,這些往往不能上報心跳,這種類型的服務在註冊時,就需要作為持久化實例註冊
- 上層的業務服務,例如微服務或者 Dubbo 服務,服務的 Provider 端支持添加彙報心跳的邏輯,可使用動態服務的註冊方式
Nacos 2.0 沿用持久化及非持久化的設定,但有調整。Nacos 1.0 中持久化及非持久化的屬性是作為實例的⼀個元數據進行存儲和識別。導致同⼀個服務下可同時存在持久化實例和非持久化實例。但實際使用中,這種模式:
- 會給運維人員帶來極大的困惑和運維複雜度
- 從系統架構來看,⼀個服務同時存在持久化及非持久化實例的場景也是存在⼀定矛盾
導致該能力事實上未被廣泛使用。為簡化 Nacos 的服務數據模型,降低運維複雜度,提升 Nacos 易用性,在 Nacos2.0 中:
- 是否持久化的數據抽象至服務級別
- 不再允許⼀個服務同時存在持久化實例和非持久化實例,實例的持久化屬性繼承自服務的持久化屬性
3 數據⼀致性
分散式系統永恆話題,協議層面上看,⼀致性的選型已經很長時間沒有新的成員加入了。目前來看基本
可歸兩家:
- 基於 Leader 的非對等部署的單點寫⼀致性
- 對等部署的多寫⼀致性
選用服務註冊中心,沒有⼀種協議能覆蓋所有場景,如:
- 當註冊的服務節點不會定時發送心跳到註冊中心時,強⼀致協議看起來是唯⼀的選擇,因為無法通過心跳來進行數據的補償註冊,第⼀次註冊就必須保證數據不會丟失
- 而當客戶端會定時發送心跳來彙報健康狀態時,第⼀次的註冊的成功率並不是非常關鍵(當然也很關鍵,只是相對來說我們容忍數據的少量寫失敗),因為後續還可以通過心跳再把數據補償上來,此時 Paxos 協議的單點瓶頸就會不太划算了,這也是Eureka 為什麼不採用 Paxos 協議而採用自定義的 Renew 機制
這兩種數據⼀致性協議有各自使用場景,對服務註冊需求不同,就會導致使用不同協議。Zookeeper 在 Dubbo 體系下表現出的行為,其實採用 Eureka 的 Renew 機制更合適,因為 Dubbo 服務往 Zookeeper 註冊的就是臨時節點,需要定時發心跳到 Zookeeper來續約節點,並允許服務下線時,將 Zookeeper 上相應的節點摘除。Zookeeper 使用 ZAB 雖保證數據的強⼀致,但是它的機房容災能力的缺乏,無法適應⼀些大型場景。
Nacos 因為要支持多種服務類型的註冊,並能夠具有機房容災、集群擴展等必不可少的能力,1.0.0 正式支持 AP 和 CP 兩種⼀致性協議並存。1.0.0 重構數據的讀寫和同步邏輯,將與業務相關的 CRUD 與底層的⼀致性同步邏輯進行了分層隔離。然後將業務的讀寫(主要是寫,因為讀會直接使用業務層的緩存)抽象為 Nacos 定義的數據類型,調用⼀致性服務進行數據同步。在決定使用 CP 還是 AP ⼀致性時,使用⼀個代理,通過可控制的規則進行轉發。
目前的⼀致性協議實現,⼀個是基於簡化的 Raft 的 CP ⼀致性,⼀個是基於自研協議 Distro 的AP ⼀致性。Raft 協議不必多言,基於 Leader 進行寫入,其 CP 也並不是嚴格的,只是能保證⼀半所見⼀致,以及數據的丟失概率較小。Distro 協議則是參考了內部 ConfigServer 和開源 Eureka,在不藉助第三方存儲的情況下,實現基本大同小異。Distro 重點是做了⼀些邏輯的優化和性能的調優
圖 5 Nacos ⼀致性協議:

本文由博客一文多發平臺 OpenWrite 發佈!


