1.操作系統的多進程圖像 操作系統main函數中最後 if(!fork()) {init();} ,也就是main函數最後創建了第1個進程,init執行了shell(Windows)桌面。 操作系統管理和組織進程都使用PCB(Process Control Block),不同的程式的PCB放在不同的 ...
1.操作系統的多進程圖像
操作系統main函數中最後 if(!fork()) {init();} ,也就是main函數最後創建了第1個進程,init執行了shell(Windows)桌面。

操作系統管理和組織進程都使用PCB(Process Control Block),不同的程式的PCB放在不同的位置,用於記錄該進程運行時的狀態。操作系統對進程進行分類,例如等待執行的進程和等待某些事件完成的進程,例如等待磁碟讀寫。



- 新建態:系統完成創建進程的一系列工作。只能轉換到就緒態
- 就緒態:擁有除CPU之外的其他所需的所有資源。當擁有CPU時就可以轉換到運行態
- 運行態:用於CPU和所需的所有資源
- 當時間片到或者處理機被搶占了,就轉換到就緒態;
- 當進程用“系統調用”的方式申請某種系統資源或者請求等待某個事件的發生,則進入阻塞態(主動)
- 阻塞態:沒有所需要的資源。當所需要的資源得到分配時,進入就緒態(被動)
- 終止態:進程運行結束或者出現不可修複的錯誤時,由運行態轉到終止態

進程切換的三個部分:隊列操作+調度+切換
pCur.state = 'W'; // 啟動磁碟讀寫,將當前進程設置為阻塞狀態 schedule(); // 將pCur放到DiskWaitQueue schedule() { pNew = getNext(ReadyQueue); // 從就緒隊列找到下一個進程,調度函數演算法非常複雜 switch_to(pCur,pNew); // 保存當前進程的現場,把下一個進程的現場恢復 }
把當前進程的現場保存到pCur中(PCB),把切換程式的pNew(PCB)讀取到寄存器中

多個進程同時存在於記憶體的問題:不同進程的地址可能影響其他進程的代碼,這可能導致其他進程的崩潰。操作系統需要維護一張映射表,將記憶體映射到實際的記憶體地址中,把不同的進程隔離開來保證進程的安全,下圖中同樣對記憶體100的操作分別映射到了記憶體地址780和記憶體地址1260。
 但實際上多進程之間可能存在合作關係,比如印表機進程需要讀取word進程的內容來完成列印的工作,這時可以提交到共用緩衝區。但這裡可能存在一個問題,因為進程1和進程2是交替進行的,可能進程1首先讀取到空間7是空的,接下來切換到進程2也讀取到空間7是空的,開始向空間7寫入,接下來切換到進程1繼續在這裡寫入,會導致寫入緩衝區的內容是錯誤的。所以操作系統需要管理一個合理的進程推進順序。
但實際上多進程之間可能存在合作關係,比如印表機進程需要讀取word進程的內容來完成列印的工作,這時可以提交到共用緩衝區。但這裡可能存在一個問題,因為進程1和進程2是交替進行的,可能進程1首先讀取到空間7是空的,接下來切換到進程2也讀取到空間7是空的,開始向空間7寫入,接下來切換到進程1繼續在這裡寫入,會導致寫入緩衝區的內容是錯誤的。所以操作系統需要管理一個合理的進程推進順序。

2.用戶級線程
進程 = 資源(映射表) + 指令執行序列
線程是只切換指令,如PC和寄存器,而不切換映射表,這種切換保留了併發了優點,避免了進程切換的代價

舉例說明,對於瀏覽器來說,可以用一個線程接收伺服器數據,一個線程顯示文本,一個線程處理圖片,一個線程顯示圖片,它們不需要用多個映射表完全分離開,沒有必要用多個進程完成這些工作。我們需要的工作主要就是下麵看到的兩個部分,創建Create線程進行工作處理,使用Yield跳轉到另一個線程工作。
void WebExplorer(){ char URL[] = "http://cms.hit.edu.cn"; char buffer[1000]; pthread_create(..., GetData, URL, buffer); pthread_create(..., Show, buffer); } void GetData(char *URL, char *p) {...} void Show(char *p) {...};

線程切換的詳細過程:每個線程都有自己的棧。線程1執行過程中,首先調用函數B(),保護現場,將上一段程式的幀指針和函數B完成後PC應指向的地址壓入棧(參見【深入理解電腦系統】3.程式的機器級表示),接下來調用Yield()函數,保護現場,將之前的幀指針和Yield函數結束後的PC204壓入棧,接下來Yield函數將當前棧指針1000保存在TCB1中,並將棧指針切換到TCB2的棧指針2000,完成了線程間的切換。接下來線程2的Yield使得棧指針回到1000處,繼續上一個線程對應位置執行。下麵給出了用戶級線程的Create和Yield核心代碼。

void Yield(){ TCB1.esp = esp; //Thread Control Block esp = TCB2.esp; } void ThreadCreate(A){ TCB *tcb=malloc(); //申請空間保存TCB *stack=malloc(); //申請空間保存棧 *stack = A; //向棧中壓入數據 tcb.esp=stack; //將棧和TCB建立聯繫 }

3.內核級線程
用戶級線程存在的問題,用戶級線程在請求下載數據的過程中,理想情況是下載了一些後跳轉到顯示文本的線程執行,但實際上內核級線程不知道這些事情,由於等待網卡IO會阻塞這個進程,最後導致瀏覽器沒有實現我們需要的功能。

所以引入內核級線程,ThreadCreate是系統調用,會進入內核,Yield的調度由系統決定。

接下來看一下多核和多CPU,可以看到多核CPU只有一套MMU(記憶體映射),也就是多核心CPU在執行進程的時候,也需要切換記憶體映射再執行,只有多處理器才能並行運行多個進程。但這個時候內核級線程的優勢就體現出來了,多核CPU可以並行的執行同一進程不同線程的代碼,因為這些代碼共用一套記憶體映射。

對於內核級線程,它與用戶級線程的區別是
用戶級線程在用戶棧執行,多個用戶級線程對應了多個用戶棧,1個TCB(用戶態)關聯1個用戶棧;
內核級線程在用戶棧和內核棧都需要執行和調用函數,所以多內核級線程實際上對應了多套棧(包括用戶棧和內核棧),1個TCB(內核態)關聯1個用戶棧和1個內核棧。

int中斷指令會引起內核棧的切換,內核棧中記錄了用戶棧和用戶代碼兩部分內容。SS寄存器(棧頂段地址)和SP寄存器(偏移地址)的值,SS:SP是此時棧頂位置;PC記錄了用戶代碼程式運行的代碼位置,CS記錄了用戶代碼段基址


內核級線程的切換包含5個階段
1.中斷入口(進入切換):系統中斷線程1從用戶態進入內核態,用戶態寄存器的值保存到內核棧
2.中斷處理(引發切換):調用schedule函數,引起TCB切換。這裡有可能啟動磁碟讀寫或時鐘中斷,內核會調用schedule找到下一個要執行的TCB,然後用next指針指向這個TCB
3.內核棧切換(switch_to):把當前ESP寄存器放在current指向的TCB中,然後把next指向的esp賦給寄存器,完成內核棧指向地址的切換,現在ESP指向了下一個線程的TCB地址
4.中斷返回(iret):把TCB存儲的內核棧現場恢復出來
5.用戶棧切換:切換回用戶態PC指針還有對應的用戶棧

4.內核級線程實現
首先從這段代碼開始,main函數開始,首先遇到函數A,用戶棧中壓入A的返回地址(也就是B的初始地址),在A函數執行中遇到fork()函數,首先將系統調用號__NR_fork移入%eax寄存器,然後調用INT 0x80中斷,執行這條指令時PC自動加1,此時PC指向下一行mov res,%eax。觸發INT 0x80中斷後,cpu立刻找到用戶棧對應的內核棧,將當前時刻的SS和SP壓入內核棧,接下來將返回地址CSIP壓入內核棧,也就是mov res,%eax這一行。接下來執行system_call。

_system_call: cmpl $nr_system_calls-1,%eax # 調用號超出範圍就在eax設置-1並退出 ja bad_sys_call push %ds %es %fs # 保存原段寄存器值 pushl %edx %ecx %ebx # 一個系統調用最多帶3個參數,這裡存放了系統對應C語言函數調用的參數 movl $0x10,%edx # 設置ds和es到內核段 mov %dx,%ds mov %dx,%ex #edx的低16位賦值給ds和es指向內核數據段 movl $0x17,%edx mov %dx,%fs call _sys_call_table(,%eax,4) pushl %eax #系統調用返回值壓入棧
下圖為切換5段論的中斷入口和中斷出口。_system_call首先保護現場,將原段寄存器的值壓入棧,然後將調用的參數壓入棧,接下來調用sys_fork,他首先判斷判斷當前程式TCB是不是等於0,等於0說明已經就緒,如果不等於0說明線程阻塞,則應該重新調度reschedule(也就是切換5段論中間3段,切換TCB),完成後進行中斷返回ret_from_sys_call

下圖為切換5段論的中斷出口,對應入口的大量push壓入棧,出口把保存在TCB中的數據pop出棧

切換5段論中的switch_to使用的時TSS切換,是一個長跳轉。TR表示當前cpu對應的任務段,TR改變時會把寄存器中的內容全部保存到舊的TSS中,然後把新的TSS中所有內容都會載入到寄存器

創建一個線程最重要的就是做出可以切換的樣子。_sys_fork首先拷貝父進程的所有參數,這些參數都已經在中斷過程壓入內核棧,

copy_process的細節:創建棧。申請一頁記憶體用於保存PCB和內核棧,註意這裡內核棧重新創建,但ss和esp的棧與父進程一模一樣,也就是它可以和父進程用同樣的代碼同樣的棧,eip是int 0x80中斷的下一句話。最後如果創建了子進程,會把%eax置為0,所以從子進程返回到mov res,%eax的時候,res是0;但如果從父進程返回到mov res,%eax,res是非0,所以有一段經典代碼if(!fork()){子進程代碼段}else{父進程代碼段},這樣就實現了子進程和父進程都返回這個位置,但執行不同的代碼


如何讓子進程執行我們想要的代碼?下麵給出了更為詳細的代碼,如果非fork則執行代碼,如果是父進程則執行另一部分代碼。



5.CPU調度策略
吞吐量和響應時間之間有矛盾:響應時間小 -> 切換次數多 -> 系統內耗大 -> 吞吐量小
前臺任務和後臺任務的關註點不同:前臺任務關註響應時間(從提交到相應的時間間隔),後臺任務關註周轉時間(從提交到完成的時間間隔)
需要綜合考慮IO約束型任務和CPU約束型任務

應該綜合考慮花費時間短的程式優先執行來降低周轉時間,劃分時間片來降低響應時間,同時也應該為前臺和後臺應用劃分優先順序
6.進程同步與信號量
不同進程需要合作,例如印表機的列印隊列與word文檔之間的合作,這種同步是通過信號量控制的
進程同步就是控制進程交替執行的過程,保證多進程合作合理有序
假設有3個生產者進程P,1個消費者進程C,1個緩衝區,用信號量來表示緩衝區的狀態,這些進程就可以通過信號量實現進程同步(也就是進程的等待和喚醒)
(1)緩衝區滿,P1執行,P1發現緩衝區滿所以sleep,設置sem=-1(有1個進程等待,緩衝區缺少1個位置)
(2)P2執行,P2 sleep,設置sem=-2(有2個進程等待)
(3)C執行,列印1份文件,緩衝區增加1個空間,wakeup P1,設置sem=-1
(4)C再執行,緩衝區又增加1個空間,wakeup P2,設置sem=0
(4)C再執行,不需要喚醒進程,設置sem=1(緩衝區盈餘1個位置)
(5)P3執行,因為緩衝區還有內容,直接執行,設置sem=0
信號量的臨界區保護
信號量是一個共有的變數,大家一起修改一起使用,多進程切換過程中可能存在問題。下麵生產者P1和P2會修改empty信號量,調用生產者P1或P2時,他們都會首先讀取現在的信號量,接下來將信號量-1,並把這個值賦回給公共的信號量。接下來右圖給出了一種可能的調度,由於生產者P1在信號量-1之後沒有將該信號量賦值給公共的信號量,此時發生調度轉到了生產者P2,這就導致本來應該兩個生產者使信號量-2,但實際上只-1

解決方法:寫共用變數empty時阻止其他進程訪問,即上鎖的思想
臨界區:一次只允許一個進程進入的該進程的那一段代碼,在這裡就是每個進程中修改empty的這段代碼,這裡最重要的工作就是找到進程臨界區的代碼。核心思想就是進程進入臨界區代碼時進行一些操作,退出臨界區後再進行一些操作,基本原則是互斥進入,其次應該有空讓進,並且是有限等待的。
下麵是兩種臨界區控制的嘗試,分別為輪換法和標記法。
輪換法: 使用turn變數控制進入。首先看互斥進入,如果P0進入說明turn=0,如果P1進入說明turn=1,滿足互斥性,但是可能P0完成後將turn置為1,P1進程又在阻塞狀態,就導致P1進程不使用臨界區代碼,P0進程又無法進入臨界區代碼,不滿足有空讓進
標記法:如果進程想要進入自己的臨界區,就將自己的標記flag設置為true。首先看互斥性,如果P0進入說明flag[0]=true,flag[1]=false,如果P1進入說明flag[1]=true,flag[0]=false,滿足互斥性。接下來看有空讓進,兩個進程都會檢測對方是否想要進入臨界區,如果想要進入就謙讓,但有可能雙方同時調整了自己的標誌位,最後導致雙方互相謙讓,沒有人能進入臨界區,不滿足無限等待
這兩種標誌太對稱了,你也一樣我也一樣,最後卡死在這個地方

Peterson演算法:如果P0想要進入臨界區,修改P0的flag為true,並且修改turn下一次應該是進程1運行。
互斥性:
P0進入flag[0]=true,flag[1]=false或turn=0
P1進入flag[1]=true,flag[0]=false或turn=1
連起來看就是如果P0和P1同時進入時一定flag[0]=flag[1]=true,那麼只能turn=0=1,矛盾,滿足互斥性
有空讓進:P1不在臨界區時,出臨界區設置flag[1]=false,入臨界區前turn=0,P0都可以進入
無限等待:turn一定等於0或等於1,所以永遠有一個可以進入

多個進程進入臨界區的解決辦法:
1.麵包店演算法。仍然是標記和輪轉的結合,每個進程都會獲得一個序號,序號最小的進入,進程離開時序號為0,不為0的號就是標記。每個進入商店的客戶都會獲得一個號碼,號碼小的先得到服務。互斥進入一定滿足,因為大家號不一樣,有空讓進也滿足,最小序號的進入,有限等待也滿足,他是一個隊列。但代碼實現很複雜,有可能溢出,排號也很麻煩
2.硬體實現:最簡單的辦法實際上是阻止調度,臨界區出現問題的根本原因是調度,另一個進程操作了一個共有的變數。硬體提供了cli()關中斷和sti()開中斷,可以在cpu硬體中加一個標記,但多CPU不太好使
3.硬體原子指令法:鎖本質上就是一個變數,讓其他代碼不能同時執行這一段的代碼,也就是這段代碼不能因為調度被打斷。硬體提供了一種一次執行完畢的指令,如果x是true,則該指令返回true,在while處空轉;如果x是false,它會把x置為true,接下來返回false,進入臨界區執行,但其它代碼就無法進入了

7.信號量的代碼實現
8.實驗
1.嘗試體驗使用fork創建線程,main函數中實現了進程創建和執行不同的函數,cpuio_bound模擬了進程使用cpu和進行io
#include <stdio.h> #include <unistd.h> #include <time.h> #include <sys/times.h> #define HZ 100 void cpuio_bound(int last, int cpu_time, int io_time); int main(int argc, char * argv[]) { pid_t n_proc[10]; //子進程的PID號 int i; for(i=0;i<10;i++) { /* *fork()創建進程 *返回值為0則創建子進程成功並從子進程返回 *返回值為PID則是從父進程返回 *返回值小於0表示進程創建失敗 */ n_proc[i] = fork(); if(n_proc[i] == 0) { // 從子進程返回會進入下麵該代碼區 // 執行函數結束後return0結束子進程 cpuio_bound(20, 2*i, 20-2*i); return 0; else if(n_proc[i] < 0) { printf("Faild to fork child process %d!\n", i+1); return -1; } } // 父進程執行完創建子進程後會進入該代碼區列印子進程的PID for(i=0;i<10;i++) { printf("Child PID: %d\n", n_proc[i]); } wait(&i); return 0; } /* * 此函數按照參數占用CPU和I/O時間 * last: 函數實際占用CPU和I/O的總時間,不含在就緒隊列中的時間,>=0是必須的 * cpu_time: 一次連續占用CPU的時間,>=0是必須的 * io_time: 一次I/O消耗的時間,>=0是必須的 * 如果last > cpu_time + io_time,則往複多次占用CPU和I/O * 所有時間的單位為秒 */ void cpuio_bound(int last, int cpu_time, int io_time) { struct tms start_time, current_time; clock_t utime, stime; int sleep_time; while (last > 0) { /* CPU Burst */ times(&start_time); /* 其實只有t.tms_utime才是真正的CPU時間。但我們是在模擬一個 * 只在用戶狀態運行的CPU大戶,就像“for(;;);”。所以把t.tms_stime * 加上很合理。*/ do { times(¤t_time); utime = current_time.tms_utime - start_time.tms_utime; stime = current_time.tms_stime - start_time.tms_stime; } while ( ( (utime + stime) / HZ ) < cpu_time ); last -= cpu_time; if (last <= 0 ) break; /* IO Burst */ /* 用sleep(1)模擬1秒鐘的I/O操作 */ sleep_time=0; while (sleep_time < io_time) { sleep(1); sleep_time++; } last -= sleep_time; } }
8.1實現進程的內核級切換
內核創建流程:通過 int0x80 中斷進入 system_call 彙編函數,根據 __NR_fork 號調用 sys_fork 函數,該函數中調用了 copy_process 函數來創建自己的內核棧並牽手父進程的用戶棧
內核級線程切換流程: schedule 函數找到下一進程的PCB(進程式控制制塊)和LDT(局部描述符),調用 switch_to 彙編函數進行PCB和內核棧的切換,並彈出回用戶棧
Linux0.11中的 switch_to 是使用Intel提供的 ljmp 指令完成的,它將TSS中保存的寄存器映像完全覆蓋到CPU中實現進程切換,但這個指令大約需要200個時鐘周期,執行時間很長,本次實驗主要目的是:
- (1)重寫
switch_to - (2)將重寫的
switch_to和schedule()函數接在一起 - (3)修改
fork()
現在不使用 TSS 進行切換,而是採用切換內核棧的方式來完成進程切換,所以在新的 switch_to 中將用到當前進程的 PCB、目標進程的 PCB、當前進程的內核棧、目標進程的內核棧等信息(內核棧中記錄了用戶棧和用戶代碼兩部分內容;PCB中記錄了進程相關信息,如進程狀態,PID,I/O等)。
Linux 0.11 進程的內核棧和該進程的 PCB 在同一頁記憶體上(一塊 4KB 大小的記憶體),其中 PCB 位於這頁記憶體的低地址,棧位於這頁記憶體的高地址;另外,由於當前進程的 PCB 是用一個全局變數 current 指向的,所以只要告訴新 switch_to()函數一個指向目標進程 PCB 的指針就可以了。同時還要將 next 也傳遞進去,雖然 TSS(next)不再需要了,但是 LDT(next)仍然是需要的,也就是說,現在每個進程不用有自己的 TSS 了,因為已經不採用 TSS 進程切換了,但是每個進程需要有自己的 LDT,地址分離地址還是必須要有的,而進程切換必然要涉及到 LDT 的切換。(整個系統中一個處理器只有一個GDT(全局描述符),每個程式對應一個LDT(局部描述符),包含其代碼、數據、堆棧等)


8.1.1修改switch_to彙編代碼
首先修改 kernel/system_call.s 中的 switch_to 這段彙編代碼
switch_to: // 因為該彙編函數在c語言中調用,所以需要手動處理棧幀 pushl %ebp movl %esp,%ebp pushl %ecx pushl %ebx pushl %eax movl 8(%ebp),%ebx cmpl %ebx,current je 1f // --------pcb切換-------- movl %ebx,%eax xchgl %eax,current // ----TSS中內核棧指針重寫----- movl tss,%ecx addl $4096,%ebx movl %ebx,ESP0(%ecx) // -------切換內核棧------- movl %esp,KERNEL_STACK(%eax) movl 8(%ebp),%ebx movl KERNEL_STACK(%ebx),%esp // --------切換LDT-------- movl 12(%ebp),%ecx lldt %cx movl $0x17,%ecx mov %cx,%fs cmpl %eax,last_task_used_math jne 1f clts 1: popl %eax popl %ebx popl %ecx popl %ebp ret
switch_to這段代碼在 schedule 函數中進行調用,首先將當前ebp指向的幀指針地址壓入內核棧,之後將當前esp指向的地址賦值給幀指針,此時ebp指向的記憶體地址保存的是上一個幀指針的位置
接下來進行了三次壓棧操作,分別將三個寄存器的值保存到內核棧中
pushl %ebp movl %esp,%ebp
pushl %ecx pushl %ebc pushl %eax

第一行將ebp+8位置的值放到寄存器ebx中,然後對比ebx和全局變數current的值,如果相同則是同一進程,直接跳出該部分代碼(下圖第1列)
第二行代碼實現了ebx -> eax, eax和current交換,也就是此時ebx和current都指向下一進程的PCB,eax指向當前進程的pcb(下圖第2列)
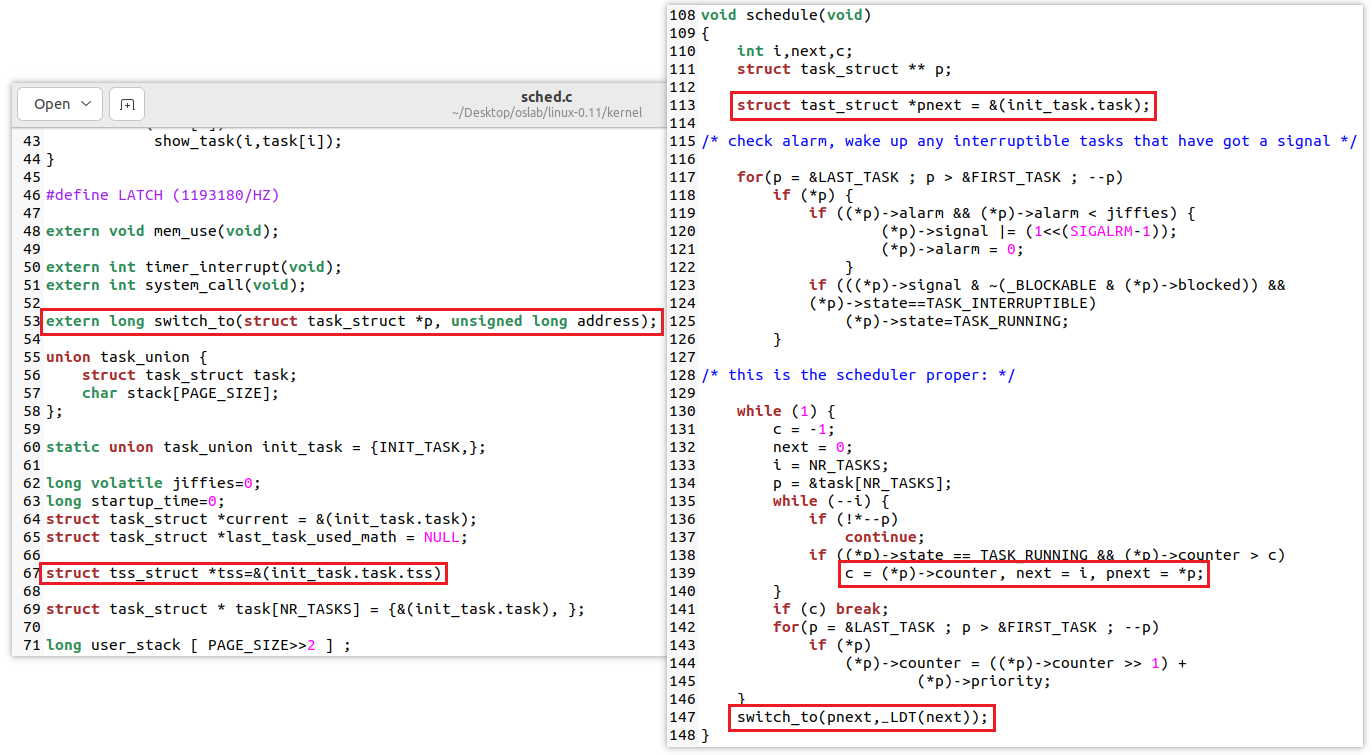
第三行,雖然現在不使用TSS進行進程切換,但這種中斷機制還需要保持,我們在 sched.c 中定義了全變數 struct tss_struct *tss=&(init_task.task.tss) ,也就是0號進程的TSS,所有進程共用這個TSS(下圖第3列)
ebx指向PCB地址,Linux0.11中進程的內核棧和PCB放在一塊大小為4K的記憶體段中,高地址開始是內核棧,低地址開始是PCB,所以ebx+4096實際上就是內核棧的地址,其中 ESP0=4 ,因為TSS中內核棧指針esp0就放在偏移為4的地方,也就是我們將內核棧的地址賦給了TSS中的內核棧地址,實現了內核棧指針的重寫
movl 8(%ebp),%ebx cmpl %ebx,current je 1f movl %ebx,%eax xchgl %eax,current movl tss,%ecx addl $4096,%ebx movl %ebx,ESP0(%ecx)
/* linux/sched.h */ struct tss_struct { long back_link; long esp0; /* ...... */ }

第一行完成了內核棧的切換。首先將當前進程esp保存到當前PCB的kernelstack中。此時ebx保存的是下一進程內核棧的地址,應該改成PCB地址,所以重新取ebp+8的位置放入ebx寄存器。接下來將ebx寄存器中保存的kernelstack地址讀入esp寄存器,實現內核棧esp的切換
第二行完成了LDT的切換。將下一進程的內核棧地址送入%ecx,載入LDT局部描述符等。
movl %esp,KERNEL_STACK(%eax) movl 8(%ebp),%ebx movl KERNEL_STACK(%ebx),%esp movl 12(%ebp),%ecx lldt %cx movl $0x17,%ecx mov %cx,%fs
/* linux/sched.h */ struct task_struct { long state; long counter; long priority; long kernelstack; // 需要增加變數 /* ...... */ }
至此 switch_to 彙編代碼全部寫完,我們需要給他添加全局標識符以及定義用到的變數

因為PCB結構增加了kernelstack,所以0號進程的PCB初始化時也應該改變,以及信號量對應的位置需要改變

8.1.2 修改fork.c代碼
我們修改完swtich_to彙編代碼實際上實現了內核級線程的切換,同樣我們創建線程的時候也需要構造出相同的樣子。第一段代碼是sys_fork系統調用函數,下麵是fork.c中copy_process()函數的完整代碼,調用了一個彙編函數。
sys_fork: call find_empty_process testl %eax,%eax js 1f push %gs pushl %esi pushl %edi pushl %ebp pushl %eax call copy_process addl $20,%esp 1: ret
// 添加外部聲明, 這裡使用了一段彙編來實現彈出棧信息到寄存器 extern long first_return_from_kernel(void); int copy_process(int nr,long ebp,long edi,long esi,long gs,long none, long ebx,long ecx,long edx, long fs,long es,long ds, long eip,long cs,long eflags,long esp,long ss) { struct task_struct *p; int i; struct file *f; p = (struct task_struct *) get_free_page(); if (!p) return -EAGAIN; task[nr] = p; *p = *current; /* NOTE! this doesn't copy the supervisor stack */ p->state = TASK_UNINTERRUPTIBLE; p->pid = last_pid; p->father = current->pid; p->counter = p->priority; p->signal = 0; p->alarm = 0; p->leader = 0; /* process leadership doesn't inherit */ p->utime = p->stime = 0; p->cutime = p->cstime = 0; p->start_time = jiffies; // 初始化內核棧 long* krnstack; // 這裡PAGE_SIZE是4096, p是PCB的地址,PCB地址加上4096就是內核棧地址 krnstack = (long*) (PAGE_SIZE + (long)p); // ss和sp等都是 copy_process() 函數的參數,來自父進程內核棧 *(--krnstack) = ss & 0xffff; *(--krnstack) = esp; *(--krnstack) = eflags; *(--krnstack) = cs & 0xffff; *(--krnstack) = eip; // “內核級線程切換五段論”中的最後一段切換,即完成用戶棧和用戶代碼的切換 // 依靠的核心指令就是 iret,回到用戶態程式,當然在切換之前應該恢復一下執行現場,主要就是 // eax,ebx,ecx,edx,esi,edi,gs,fs,es,ds 等寄存器的恢復. *(--krnstack) = ds & 0xffff; *(--krnstack) = es & 0xffff; *(--krnstack) = fs & 0xffff; *(--krnstack) = gs & 0xffff; *(--krnstack) = esi; *(--krnstack) = edi; *(--krnstack) = edx; // 處理 switch_to 返回,即結束後 ret 指令要用到的,ret 指令預設彈出一個 EIP 操作 *(--krnstack) = (long)first_return_from_kernel; // swtich_to 函數中的 “切換內核棧” 後的彈棧操作 *(--krnstack) = ebp; *(--krnstack) = ecx; *(--krnstack) = ebx; *(--krnstack) = 0; // 存放在 PCB 中的內核棧指針 指向 初始化完成時內核棧的棧頂 p->kernelstack = krnstack; if (last_task_used_math == current) __asm__("clts ; fnsave %0"::"m" (p->tss.i387)); if (copy_mem(nr,p)) { task[nr] = NULL; free_page((long) p); return -EAGAIN; } for (i=0; i<NR_OPEN;i++) if ((f=p->filp[i])) f->f_count++; if (current->pwd) current->pwd->i_count++; if (current->root) current->root->i_count++; if (current->executable) current->executable->i_count++; set_tss_desc(gdt+(nr<<1)+FIRST_TSS_ENTRY,&(p->tss)); set_ldt_desc(gdt+(nr<<1)+FIRST_LDT_ENTRY,&(p->ldt)); p->state = TASK_RUNNING; /* do this last, just in case */ return last_pid; }

8.1.3 修改sched.c函數
我們已經完成了關鍵的switch_to彙編代碼編寫,使得系統可以不使用TSS而是用內核級線程切換;同時我們也完成了fork.c函數的修改,使得我們創建的內核級線程對應了我們switch_to需要的樣子。
最後我們對sched.c進行修改,首先聲明外部函數switch_to,需要傳入當前PCB地址以及LDT地址,然後聲明我們在switch_to中需要的全局變數tss地址,最後修改schedule函數中的句子。