
前言 前面說了很多Kafka的性能優點,有些童鞋要說了,這Kafka在企業開發或者企業級應用中要怎麼用呢?今天咱們就來簡單探究一下。 1、 使用 Kafka 進行消息的非同步處理 Kafka 提供了一個可靠的消息傳遞機制,使得企業能夠將不同組件之間的通信解耦,實現高效的非同步處理。在企業級應用中,可以通 ...
2 封底估算
在系統設計面試中,有時會要求你使用 "封底估算"(back-of-the-envelope estimation)來估算系統容量或性能需求。根據谷歌高級研究員傑夫-迪恩(Jeff Dean)的說法,"封底估算是你結合思想實驗和常見性能數字進行的估算,目的是讓你對哪些設計能滿足你的要求有一個良好的感覺"。
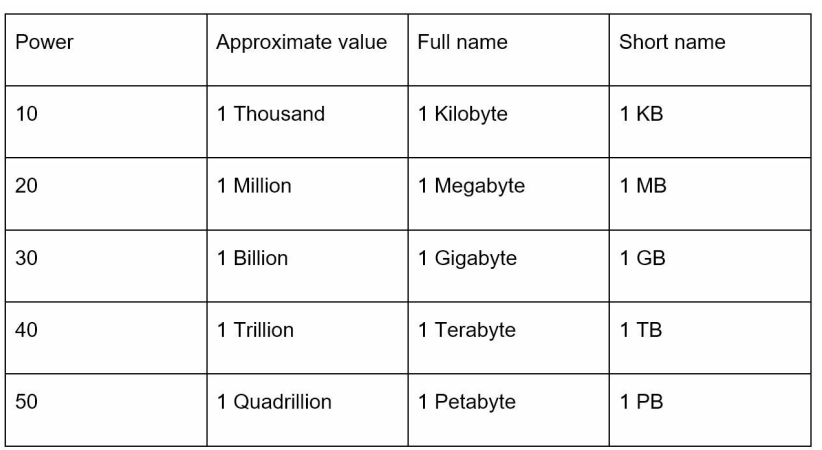
2.1 常用單位
| 2的方次 | 近似值 | 全稱 | 簡稱 |
|---|---|---|---|
| 10 | Thousand | 千位元組(Kilobyte) | KB |
| 20 | Million | 兆位元組(Megabyte) | MB |
| 30 | Billion | 千兆位元組(Gigabyte) | GB |
| 40 | Trillion | 太位元組(Terabyte) | TB |
| 50 | Quadrillion | 百億位元組(Petabyte) | PB |
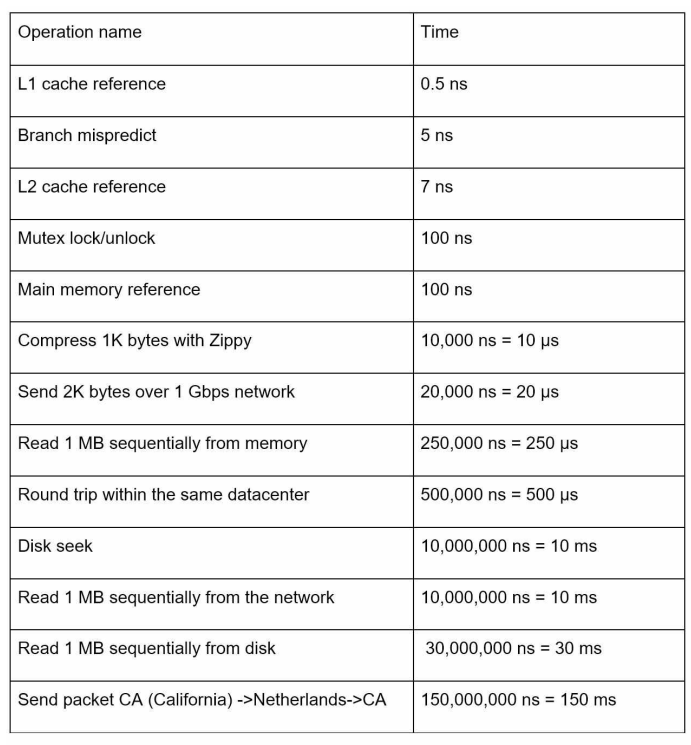
2.2 延遲
來自谷歌的迪恩博士揭示了 2010 年典型電腦操作的時長。隨著電腦速度越來越快、功能越來越強大,有些數字已經過時。不過,這些數字仍能讓我們瞭解不同電腦操作的快慢。
| 操作 | 時間 |
|---|---|
| L1緩存 | 0.5ns |
| 分支誤預測 | 5ns |
| 二級緩存 | 7ns |
| 互斥鎖定/解鎖 | 100ns |
| 主記憶體引用 | 100ns |
| Zippy壓縮1K位元組 | 10 μs |
| 1Gbps網路發送2K位元組 | 20 μs |
| 記憶體順序讀取1MB | 250μs |
| 同一數據中心內往返 | 500μs |
| 磁碟尋道 | 10ms |
| 網路順序讀取1MB | 10ms |
| 磁碟順序讀取1MB | 30ms |
| 發送數據包CA(California)->Netherlands->CA | 150ms |
谷歌的一名軟體工程師製作了一個工具,將Dean博士的數字可視化。該工具還考慮了時間因素。下圖顯示了截至 2020 年的可視化延遲數字(數字來源:參考資料 https://colin-scott.github.io/personal_website/research/interactive_latency.html )。

- 記憶體速度快,但磁碟速度慢。
- 儘可能避免磁碟尋道。
- 簡單的壓縮演算法速度快。
- 儘可能在通過互聯網發送數據前對其進行壓縮。
- 數據中心通常位於不同地區,在它們之間發送數據需要時間。
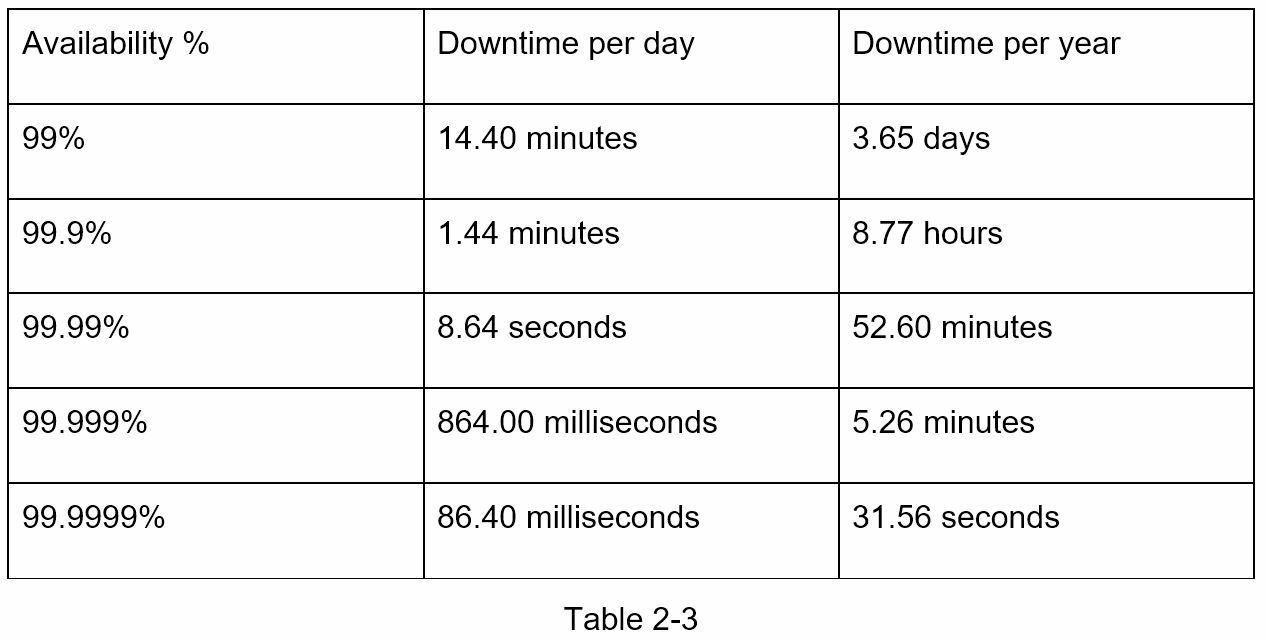
2.3 可用性數字
高可用性是指系統在理想的長時間內持續運行的能力。高可用性是以百分比來衡量的,100%表示服務沒有停機時間。大多數服務介於99%和100%之間。
服務水平協議(SLA:service level agreement)是服務提供商的常用術語。這是您(服務提供商)與客戶之間的協議,該協議正式規定了您的服務將提供的正常運行時間水平。雲服務提供商亞馬遜、谷歌和微軟將其 SLA 定義為 99.9% 或以上。正常運行時間傳統上以9為單位。9越多越好。
參考資料
- 軟體測試精品書籍文檔下載持續更新 https://github.com/china-testing/python-testing-examples 請點贊,謝謝!
- 本文涉及的python測試開發庫 謝謝點贊! https://github.com/china-testing/python_cn_resouce
- python精品書籍下載 https://github.com/china-testing/python_cn_resouce/blob/main/python_good_books.md
- Linux精品書籍下載 https://www.cnblogs.com/testing-/p/17438558.html
- https://www.drawio.com/doc/faq/
- J. Dean.Google Pro Tip: Use Back-Of-The-Envelope-Calculations To Choose The Best Design:
-
System design primer: https://github.com/donnemartin/system-design-primer
-
Latency Numbers Every Programmer Should Know:
https://colin-scott.github.io/personal_website/research/interactive_latency.html
- Amazon Compute Service Level Agreement:
https://aws.amazon.com/compute/sla/
- Compute Engine Service Level Agreement (SLA):
https://cloud.google.com/compute/sla
- SLA summary for Azure services: https://azure.microsoft.com/en-us/support/legal/sla/summary/
2.4 實例:估算新浪微博QPS和存儲需求
請註意以下數字僅用於本練習,並非新浪微博的真實數字。
假設
- 3億月活躍用戶。
- 50%的用戶每天使用。
- 用戶平均每天發佈2條微博。
- 10%的微博包含媒體內容。
- 數據存儲 5 年。
估計值:
每秒查詢次數 (QPS Query per second) 估計值:
- 日活躍用戶(DAU Daily active users) = 3億 * 50% = 1.5億
- 博文QPS = 1.5億*2條推文/24小時/3600秒 = ~3500
- 峰值QPS =2*QPS = ~7000
我們在此僅估算媒體存儲量。
- 平均微博大小
- weibo_id 64 位元組
- 文本 140 位元組
- 媒體 1 MB
- 媒體存儲量 每天1.5億 * 2 * 10% * 1 MB = 30TB
- 5年媒體存儲: 30TB * 365 * 5 = ~55PB
2.5 面試小結
封底估算的關鍵在於過程。解決問題比獲得結果更重要。面試官可能會測試你解決問題的能力。以下是一些應遵循的技巧:
-
圓周率和近似值。面試時很難進行複雜的數學運算。例如,"99987/ 9.1"的結果是什麼?沒有必要花費寶貴的時間來解決複雜的數學問題。不要求精確。使用整數和近似值對你有利。除法問題可簡化如下: "100,000/10".
-
寫下你的假設。最好寫下你的假設,以便日後參考。
-
標註單位。寫下 "5 "時,是指 5 KB 還是 5 MB?這可能會讓你感到困惑。寫下單位,因為 "5 MB "有助於消除歧義。


