
 提到數據處理,經常有人把它簡稱為“ETL”。但仔細說來,數據處理經歷了ETL、ELT、XX ETL(例 ...

提到數據處理,經常有人把它簡稱為“ETL”。但仔細說來,數據處理經歷了ETL、ELT、XX ETL(例如,Reverse ETL、Zero-ETL)到現在流行的EtLT架構幾次更迭。目前大家使用大數據Hadoop時代,主要都是ELT方式,也就是載入到Hadoop里進行處理,但是實時數據倉庫、數據湖的流行,這個ELT已經過時了,EtLT才是實時數據載入到數據湖和實時數據倉庫的標準架構。
本文主要講解下幾個架構出現的原因和擅長的場景及優缺點,以及為什麼EtLT逐步取代了ETL、ELT這些常見架構,成為全球主流數據處理架構,並給出開源實踐方法。
ETL時代(1990-2015)
在數據倉庫早期時代,數據倉庫提出者Bill Inmmon把數據倉庫定義為分主題的存儲和查詢的數據存儲架構,數據在存儲時就是按主題分門別類清洗好的數據。而實際情況也如此,大部分數據源是架構化數據源(例如,mysql、Oracle、SQLServer、ERP、CRM等等),而作為數據集中處理的數據倉庫大部分還是以OLTP時代查詢和歷史存儲為主的資料庫(DB2、Oracle),因此數據倉庫在面對複雜ETL處理時並不得心應手。而且這些資料庫購買成本都比較高,處理性能較弱,同時,各種各樣的軟體數據源越來越多。為了更方便地整合複雜的數據源、分擔數據計算引擎負擔、大量的ETL軟體出現,大家耳熟能詳的Informatica、Talend、Kettle都是那個年代的典型軟體產品,很多軟體至今還在很多企業的傳統架構當中配合數據倉庫使用。
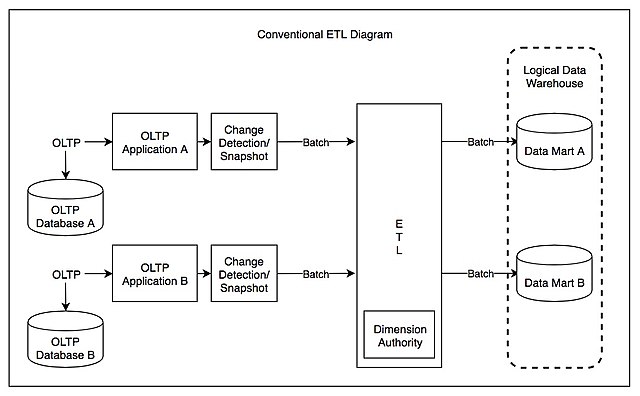
優點:技術架構清晰、複雜數據源整合順暢、ETL軟體分擔接近50%的數據倉庫工作
缺點:所有處理都由數據工程師實現,業務需求滿足時間較長;硬體成本幾乎投入雙份,數據量大時硬體成本過高
在數據倉庫早期和中期,數據源複雜性比較高的時候,ETL架構幾乎成為行業標準流行了20多年。
ELT時代(2005-2020)
隨著數據量越來越大,數據倉庫的硬體成本與ETL硬體成本雙向增長,而新的MPP技術、分散式技術出現導致在數據倉庫中後期和大數據興起時代,ETL的架構逐步走向ELT架構。例如,當年數據倉庫最大廠商Teradata、至今流行的Hadoop Hive架構,都是ELT架構。它們的特點就是,將數據通過各種工具,幾乎不做join,group等複雜轉化,只做標準化(Normolization)直接抽取到數據倉庫里數據準備層(Staging Layer),再在數據倉庫中通過SQL、H-SQL,從數據準備層到數據原子層(DWD Layer or SOR Layer);後期再將原子層數據進入彙總層(DWS Layey or SMA Layer),最終到指標層(ADS Layer or IDX Layer)。雖然Teradata面向的結構化數據,Hadoop面向非結構化數據,但全球大數據和數據倉庫幾乎用的同一套架構和方法論來實現3-4層數據存儲架構。
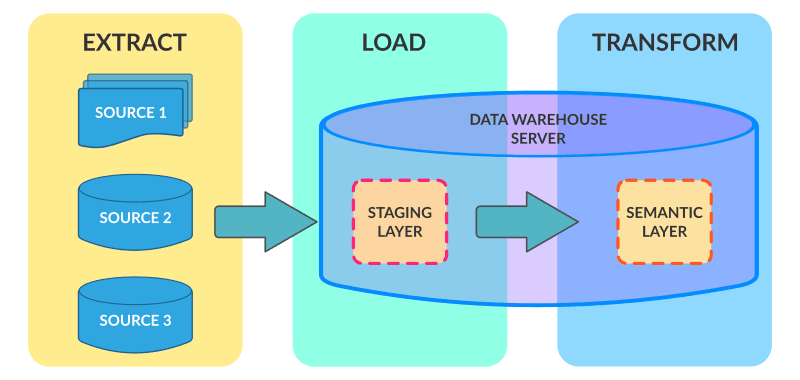
優點:利用數據倉庫高性能計算處理大數據量處理,硬體ROI更高;同時,複雜業務邏輯可以通過SQL來用數據分析師和懂業務邏輯的技術人員來處理,而無需懂ETL(如Spark, MapReduce)降低數據處理人員總成本。
缺點:只適用於數據源比較簡單、量比較大的情況,面對複雜的數據源明顯處理方式不足;同時直接載入,數據準備層到數據原子層複雜度過高,無法通過SQL處理,往往利用Spark、MapReduce處理,而數據重覆存儲率較高;無法支持實時數據倉庫等需求。
面對ELT的數據倉庫無法載入複雜數據源,實時性比較差的問題,曾經有一個過渡性解決方案被各種公司方法採用,叫做ODS(Operational Data Store)方案。將複雜的數據源通過實時CDC或者實時API或者短時間批量(Micro-Batch)的方式ETL處理到ODS存儲當中,然後再從ODS ELT到企業數據倉庫當中,目前,還有很多企業採用此種方式處理。也有部分企業,把ODS放置在數據倉庫當中,通過Spark、MapReduce完成前期的ETL工作,再在數據倉庫(Hive、Teredata、Oracle、DB2)當中完成後期的業務數據加工工作。
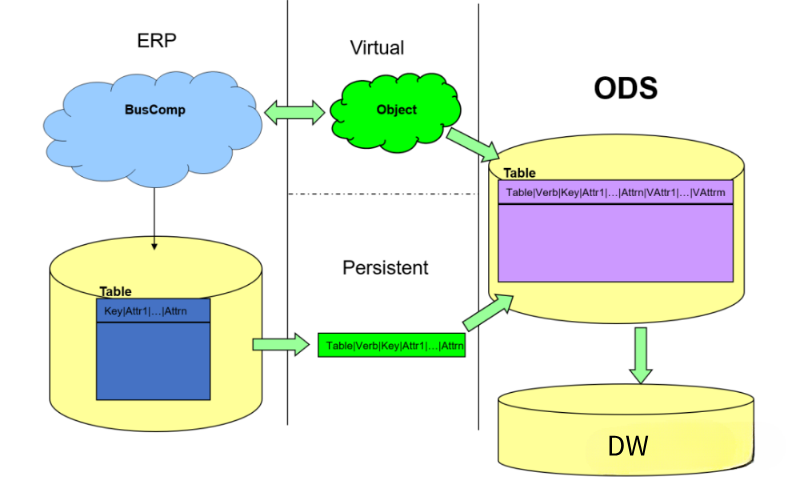
其實此時,EtLT初期的人群已經形成,它的特點是人群劃分開,複雜的數據抽取、CDC、數據結構化、規整化的過程,往往由數據工程師實現,我們叫做小“t”,它的目標是從源系統到數據倉庫底層數據準備層或者數據原子層;而複雜的帶有業務屬性的數據原子層到數據彙總層到數據指標層的處理(帶有Group by、Join等複雜操作)往往是擅長使用SQL的業務數據工程師或者數據分析師來處理。
而ODS架構的獨立項目也隨著數據量級變大和EtLT架構的出現逐步淡出歷史舞臺。
EtLT (2020-未來)
EtLT的架構是由James Densmore 在《Data Pipelines Pocket Reference 2021》中總結提到的一個現代全球流行的數據處理架構。EtLT也是隨著現代數據架構(Modern Data Infrastructure)變化而產生的。
EtLT架構產生的背景
現代數據架構架構有如下特點 ,導致EtLT架構出現:
- 雲、SaaS、本地混合複雜數據源
- 數據湖與實時數據倉庫
- 新一代大數據聯邦(Big Data Federation)
- AI應用大爆發
- 企業數據社群(Data Community)分裂
複雜數據源出現
現在全球企業運行當中,除了傳統的軟體、資料庫之外,雲和SaaS的出現將本已經很複雜的數據源情況更加複雜,於是面對SaaS的處理,北美企業提出了新的數據集成(Data Ingestion)的概念,例如 Fivetran,Airbyte,以解決SaaS數據進入數據倉庫(例如Snowflake)當中的ELT問題,它是傳統ELT架構在SaaS環境下的升級。而雲端數據存儲(例如,AWS Aruroa,AWS RDS,MongoDB Service等)和傳統線下資料庫與軟體(SAP、Oracle、DB2等)在混合雲架構(Hybrid Cloud)也在迅速增加數據源複雜性。傳統的ETL和ELT架構就無法滿足如此複雜環境的數據源處理。
數據湖與實時數據倉庫
在現代數據架構環境下,數據湖的出現融合了傳統的ODS和數據倉庫的特點,它可以做到貼源的數據變更和實時數據處理(例如 Apache Hudi, Apache Iceberg,Databricks Delta Lake),針對傳統的CDC(Change Data Capture)和實時數據流計算都做了數據存儲結構變化(Schema Evolution)和計算層面的支持。同時,實時數據倉庫理念出現,很多新型計算引擎(Apache Pinnot、ClickHouse、Apache Doris)都將支持實時ETL提上日程。而傳統的CDC ETL軟體或者實時計算流計算(Datastream Computing)對於數據湖和實時數據倉庫的支持,要麼是在新型存儲引擎支持要麼是在新型數據源連接方面存在很大問題,缺乏很好的架構和工具支持。
新一代大數據聯邦
在現代數據架構當中還有一種新型架構出現,它們以儘可能減少數據在不同數據存儲間流動,直接通過連接器或者快速數據載入後直接提供複雜數據查詢而見長,例如 Starburst的TrinoDB(前PrestDB)和基於Apache Hudi的OneHouse。這些工具都以數據緩存以及即席跨數據源查詢為目標,各種ETL、ELT工具亦無法支撐新型的Big Data Federation架構。
大模型大爆發
隨著2022年ChatGPT的出現,AI模型已經具備在企業應用中普及的演算法基礎,阻礙AI應用模型落地的更多的是數據的供給,數據湖和Big Data Federation出現解決了數據存儲和查詢問題。而數據供給側,傳統的ETL和ELT和流計算都形成了瓶頸,亦或無法快速打通各種複雜傳統、新興數據源、亦或無法用一套代碼同時支持AI訓練和AI線上的數據差異化需求。
企業數據社群分裂
隨著數據驅動和使用的深入,企業內部的數據使用者也快速增加,從傳統的數據工程師到數據分析師、AI人員甚至銷售分析師、財務分析師都有從企業數據倉庫當中提取數據的需求。因此,經歷了No-SQL,New-SQL各種變化之後,SQL還是成為企業最後面對複雜業務分析的唯一標準。大量分析師、業務部門工程師使用SQL來解決企業數據最後一公裡的問題,而複雜的非結構化數據處理,留給了專業數據工程師使用Spark、MapReduce、Flink處理。因此,兩批人群的需求產生了比較大的差異,傳統ETL,ELT架構無法滿足新型企業使用者的需求。
EtLT架構應運而生!
在上述背景下,數據處理逐步演化成為EtLT架構:
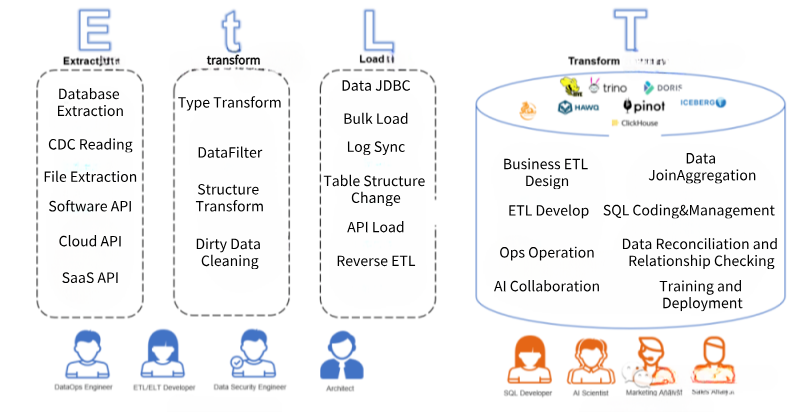
它拆分了原有ETL和ELT的結構,並力求實時和批量統一在一起處理以滿足實時數據倉庫和AI應用的需求:
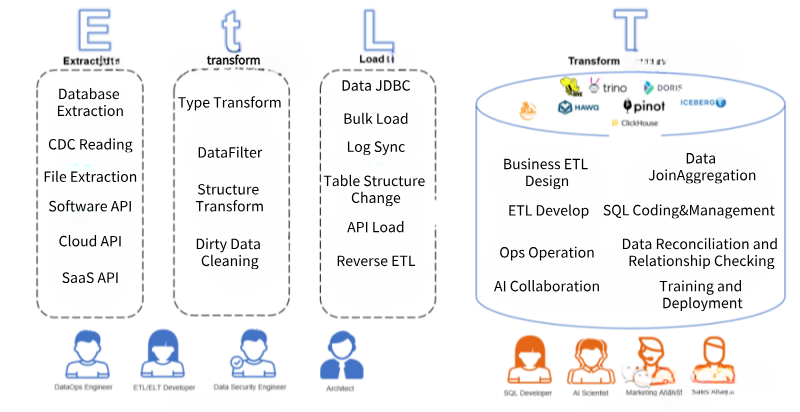
- E(xtract)抽取:從數據源角度來看,支持傳統的線下資料庫、傳統文件、傳統軟體同時,還要支持新興雲上資料庫、SaaS軟體API以及Serverless數據源的抽取;從數據抽取方式來看,需要支持實時CDC(Change Data Capture)對資料庫Binlog日誌的解析,也要支持實時計算(例如Kafka Streaming),同時也需要支持大批量數據讀取(多線程分區讀取、限流讀取等)。
- t(ransform)規範化:相對於ETL和ELT,EtLT多出了一個小t,它的目標是數據規範化(Data Normalization)將複雜、異構的抽取出來數據源,快速地變為目標端可載入的結構化數據,同時,針對CDC實時載入Binlog進行拆分、過濾、欄位格式變更,並支持批量和實時方式快速分發到最終Load階段。
- L(oad)載入:準確的說,載入階段已經不是簡單的數據載入,而是配合Et階段,將數據源的數據結構的變更、數據內容的變更以適合數據目標端(Data Target)的形式快速、準確的載入到數據目標當中,其中,對於數據結構的變化要支持同源數據結構變更(Schema Evolution),數據載入也應該支持大批量載入(Bulk Load)、SaaS載入(Reverse ETL)、JDBC載入等。確保既支持實時數據和數據結構的變化,還要支持大批量數據快速載入。
- (T)ransform轉化:在雲數據倉庫、線下數據倉庫或新數據聯邦的環境下,完成業務邏輯的加工,通常使用SQL方式,實時或批量地將複雜業務邏輯準確、快速變為業務端或者AI端使用的數據。
在EtLT架構下,使用者人群也有了明確的分工:
- EtL階段:以數據工程師為主,他們將複雜異構的混合數據源,變為數據倉庫或者數據聯邦可載入的數據,放到數據存儲當中,他們無需對企業指標計算規則有深入理解,但需要對各種源數據和非結構化數據變為結構化數據轉化有深入理解。他們需要確保的是數據的及時性、數據源到結構化數據的準確性。
- T階段:以數據分析師、各業務部門數據SQL開發者、AI工程師為主,他們深刻理解企業業務規則,可以將業務規則變為底層結構化數據上的SQL語句進行分析統計,最終實現企業內部的數據分析和AI應用的實現,他們需要確保的是數據邏輯關係、數據質量以及最終數據結果滿足業務需求。
EtLT 架構開源實踐
在新興的EtLT架構下,其實全球有不少開源實踐,例如在大T部分,DBT幫助企業分析師和業務開發者快速基於Snowflake開發相關數據應用。而以大數據任務可視化調度協同(Workflow Orchestration)見長的Apache DolphinScheduler也在規劃Task IDE,讓企業數據分析師可以在DolphinScheduler上直接調試Hudi、Hive、Presto、ClickHouse等的SQL任務並直接拖拽生成Workflow任務。
作為EtLT架構當中代表Apache SeaTunnel則是從雲、本地數據源多種支持開始起步,逐步支持SaaS和Reverse ETL,大模型數據供給等方面,逐步完善EtLT的版圖,可以看到SeaTunnel最新的Zeta計算引擎把複雜的Join,Groupby等複雜操作交給最終的數據倉庫端來實現,自己只完成歸一化、標準化的動作以達到實時數據和批量數據一套代碼和高效引擎處理的目標,而大模型支持也放入支持列表當中:
目前Apache SeaTunnel從2022年底加入Apache孵化器的20個連接器發展到現在1年增長了5倍,目前支持的數據源超過100(https://seatunnel.apache.org/docs/Connector-v2-release-state/),從傳統資料庫到雲上資料庫最終到SaaS的支持都在逐步完善。
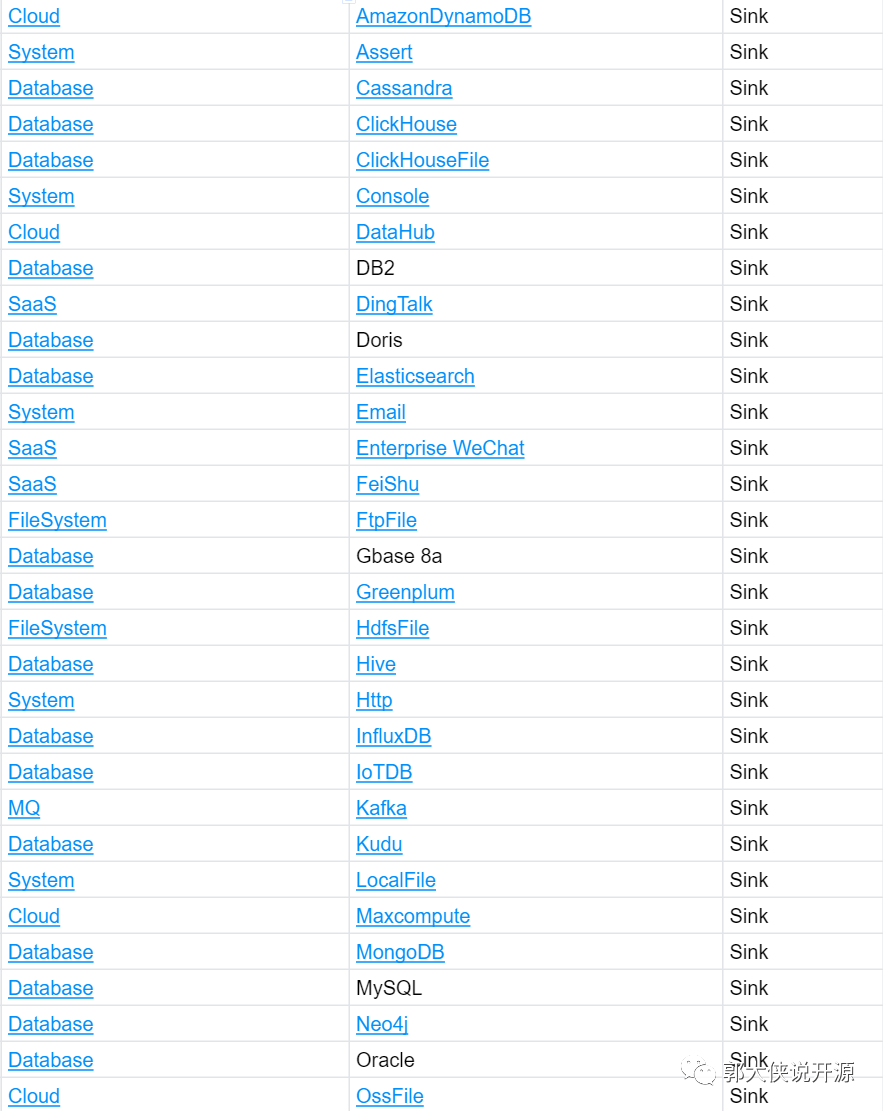
(參見https://seatunnel.apache.org/docs/2.3.2/category/source-v2瀏覽最新支持組件)
而Apache SeaTunnel 2.3.0 發佈的SeaTunnel Zeta引擎也支持數據分散式CDC,目標源數據表變更(SchemaEvolution)和整庫和多表同步諸多Feature和針對大數據量優異的性能贏得全球大量用戶(例如,印度第二大運營商Bharti Airtel,新加坡電商Shopee.com,唯品會Vip.com等)。相信隨著Connector數據量增多,SeaTunnel會贏得更多的企業用戶的青睞。
大模型的支持
更有意思的是現在SeaTunnel已經支持了對大模型訓練和向量資料庫的支撐,讓大模型可以直接和SeaTunnel支撐的100多種數據源交互(參見《圖書搜索領域重大突破!用 Apache SeaTunnel、Milvus 和 OpenAI 提高書名相似度搜索精準度和效率》),而現在SeaTunnel更可以利用ChatGPT直接生成SaaS Connector讓你的大模型和數據倉庫快速獲取互聯網上多種信息。
隨著AI、雲、SaaS的複雜性增加,企業對於實時CDC、SaaS和數據湖、實時數據倉庫裝載的需求,簡單的ETL架構已經很難滿足現有企業的需求,而具有面向企業不同階段的EtLT架構會在現代數據架構當中大放異彩。
而Apache SeaTunnel的目標就是是“連接萬源,同步如飛”。
SeaTunnel社區非常活躍,當前版本也在快速迭代,加入Apache SeaTunnel社區,當前2.3.x版本還有不少地方在快速變化,也歡迎大家一起來貢獻!
本文由 白鯨開源 提供發佈支持!


