
本文分享自華為雲社區《MRS大企業ERP流程實時數據湖加工最佳實踐》,作者:晉紅輕 。 本文將以ERP流程實踐為例介紹MRS實時數據湖方案的演進 案例實踐需求解析: 業務描述 AE表:會計分錄表,主要記錄財務相關信息,可用於成本核算等業務計算。為業務最主要的表,稱驅動表。 四通道表:實際為四個門店業 ...
本文分享自華為雲社區《MRS大企業ERP流程實時數據湖加工最佳實踐》,作者:晉紅輕 。
本文將以ERP流程實踐為例介紹MRS實時數據湖方案的演進
案例實踐需求解析:
業務描述
- AE表:會計分錄表,主要記錄財務相關信息,可用於成本核算等業務計算。為業務最主要的表,稱驅動表。
- 四通道表:實際為四個門店業務系統,主要記錄銷售記錄信息。為成本核算、科目報表分析等業務提供信息佐證。可稱為維表。
業務痛點
- 科目分析報表業務供數慢的痛點,數據時延高。
- 實際業務數據有內容更新,保證數據嚴格一致。
- 科目分析報表查詢僅支持公司、科目、時段等少量查詢條件。
實時數據湖方案優勢
- 實時數據湖方案做增量加工,將傳統供數壓力卸載到每天、每小時、每分鐘,100萬數據查詢只需要2min。
- 使用Hudi作為數據湖天然支持數據更新。
- 提供所有數據歸檔,可隨時回溯。
- 支持科目、批名、憑證名、合同號等31個查詢條件,大幅度減少用戶導出數據後篩選過濾時間。支持用戶基於頁面直接分析。
實時數據湖方案實施挑戰
- 流計算基於記憶體,峰值數據量過大會影響作業穩定性。
- 多流時延大,數據等待耗費大量記憶體資源,需考慮業務需求與使用資源的平衡。
流加工模型一:
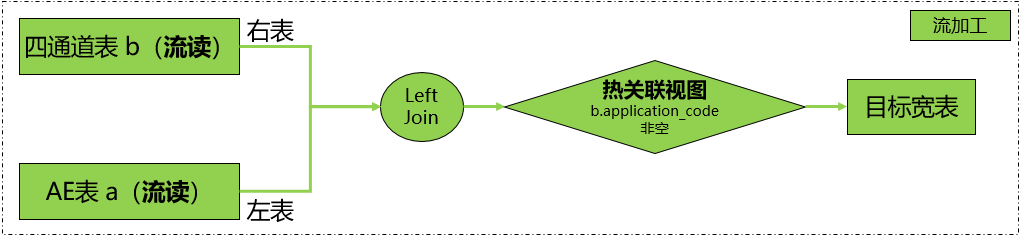
模型一特點
•Hudi表流讀能夠減少整體記憶體開銷,提高作業穩定性。
•以其中一條流為基準(左表),去比較另一條流(右表)
•會出現關聯缺失的情況,以驅動表(AE表)的視角(新增&更新)
•1)四通道流早到,並且ttl到期後數據丟失
•2)四通道流晚到,AE流ttl到期後數據丟失
模型一局限:
•目標寬表數據會出現不准的情況
•源端新增因為關聯不出有效結果造成目標寬表缺數 -> missing
•源端更改因為關聯不出有效結果造成目標寬表延時 -> delay
流加工模型二:
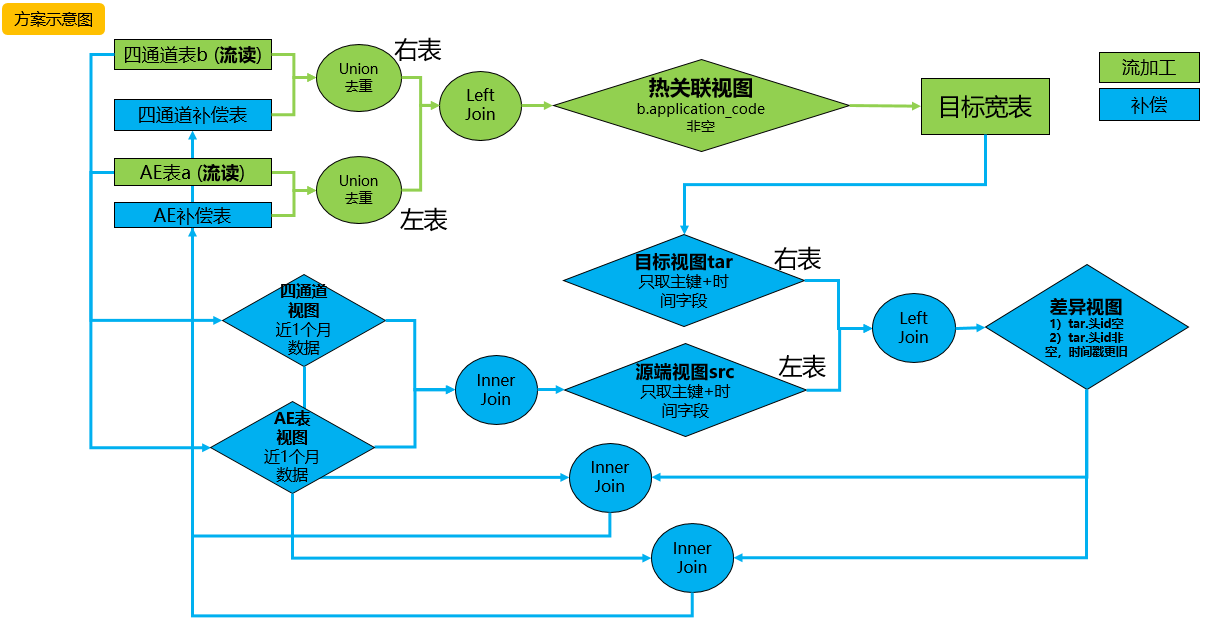
補償目的:
補償目的:基於業務邏輯,對比源端流表和目的端寬表數據內容,發現目標寬表缺失數據主要欄位,關聯源表完整內容找出缺失數據,並寫回源端表補償層。
missing&delay補償模擬:
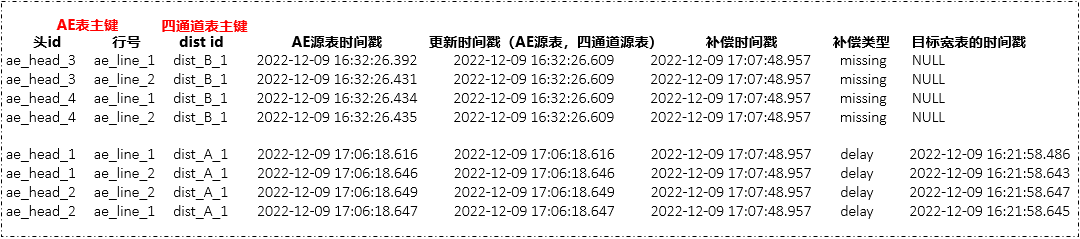
模型二特點:比較方案一增加補償機制,能夠對比源表(AE表,四通道表)以及目標寬表,找出缺失數據missing, delay。
模型二局限:實際情況雙流之間時延可能較大、對齊較難,雖然能夠使用補償機制找回缺失數據,但是這樣流加工任務主要角色會被弱化,同時會對補償任務造成更大壓力,數據時延會變大 。
流加工模型三(最終):
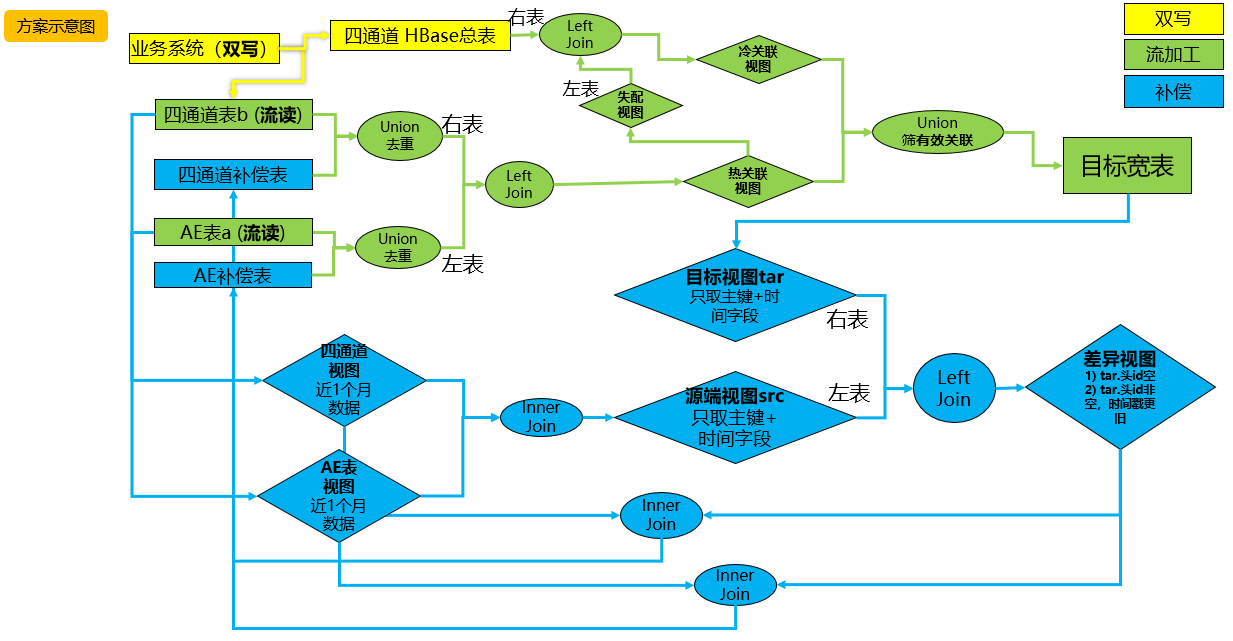
雙寫目的:業務系統持續向Hudi表,HBase表雙寫數據。Hudi表流讀,提供主要熱關聯數據,HBase存儲所有歷史數據,技術上就是維度表,為熱關聯失敗之後進行快速點查補數(lookup join)得到有效關聯。提高雙流關聯的命中率。減少流加工整體數據時延。
維表選型:

模型總結:



