
### 前言 說到MySQL的MTS,相信很多同學都不陌生,從5.6開始基於schema的並行回放,到5.7的LOGICAL_CLOCK支持基於事務的並行回放,這些內容都有文章講解,在本篇文章不再贅述。今天要講的是,你知道如何查看並行回放是否存在性能瓶頸嗎,是由於主庫事務行為導致無法並行回放,還是由 ...
前言
說到MySQL的MTS,相信很多同學都不陌生,從5.6開始基於schema的並行回放,到5.7的LOGICAL_CLOCK支持基於事務的並行回放,這些內容都有文章講解,在本篇文章不再贅述。今天要講的是,你知道如何查看並行回放是否存在性能瓶頸嗎,是由於主庫事務行為導致無法並行回放,還是由於worker線程不足,限制了並行回放的天花板?這都得從一個Note信息說起。
MY-010559
在開啟了多線程回放的從庫error log,我們經常能看到Note級別的日誌信息MY-010559
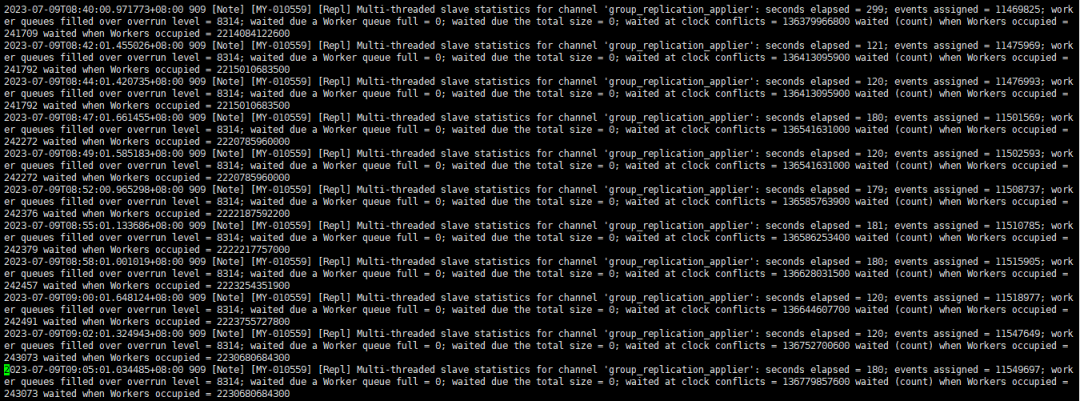
讓我們來看看這些日誌的含義
Seconds elapsed:當前時間與上次輸出日誌時間的間隔秒數
Events assigned:自slave協調線程啟動後,累計處理分發給worker線程的event數量。簡單理解為slave啟動後處理的event數量。
Worker queues filled over overrun level:worker線程處理的event隊列長度超過最大隊列數(目前代碼硬編碼16384)的90%的次數,如果0則說明未發生該情況。
Waited due to worker queue full:worker線程處理的event隊列長度達到最大(目前代碼硬編碼16384)的次數,如果為0則說明未發生該情況,是前面Worker queues filled over overrun level的情況升級。
Waited due to the total size:協調線程分發event大小達到replica_pending_jobs_size_max或者slave_pending_jobs_size_max限制而產生等待的次數。前面兩個參數是限制worker線程處理event隊列能夠申請的最大記憶體(即大事務)。如果遇到此種大事務,在回放該大事務之前,會等待其他worker線程處理完已分配event,然後再進行該大事務的回放,回放過程中,後續的event回放,也會進入等待狀態。總之,大事務回放特別影響並行回放的性能,只能串列回放。
Waited at clock conflicts:由於不能並行回放的累計等待時間,單位納秒。如果並行回放策略設置的是DATABASE而不是LOGICAL_CLOCK,該值一直為0。
Waited (count) when workers occupied:協調線程休眠次數。有兩種情況會累加此狀態值:1、worker線程達到最大隊列數(目前代碼硬編碼16384)的90%,此種情況協調線程最多休眠1毫秒;2、並行回放策略設置為LOGICAL_CLOCK時,由於沒有空閑的worker線程導致無法分配事務的第一個event而產生的等待,此種情況協調線程會一直處於等待狀態直到有空閑的worker線程能夠處理回放。
Waited when workers occupied:等待空閑的worker線程累計時間,單位納秒,對應Waited (count) when workers occupied的第二種等待情況。
代碼分析
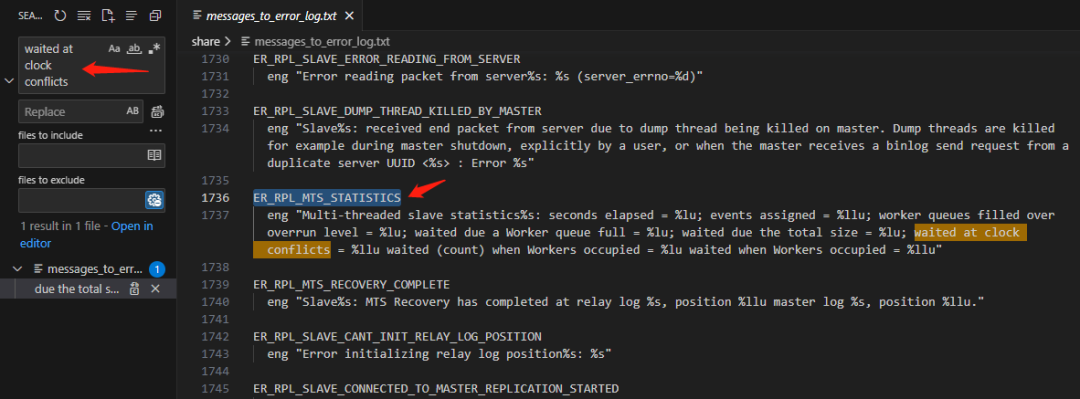
在8.0.26版本的代碼中,我們通過錯誤信息關鍵字waited at clock conflicts查找,發現信息記錄在變數ER_RPL_MTS_STATISTICS中,
繼續按變數查找,發現其使用在rpl_replica.cc文件的apply_event_and_update_pos函數中,主要邏輯代碼如下
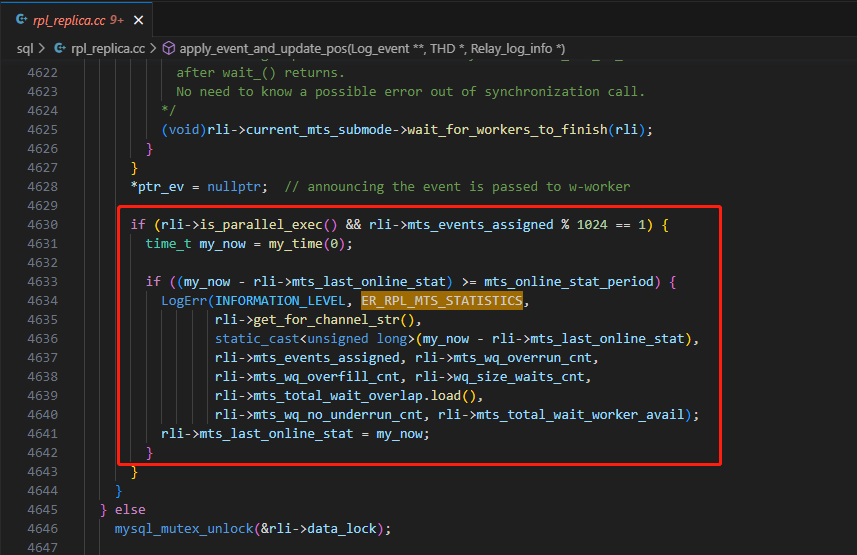
可以看到,滿足如下幾個條件,日誌信息就會輸出
- 並行回放為開啟狀態
- 並行回放的累計event數量對1024取模餘1
- 當前時間減去上次日誌時間間隔大於mts_online_stat_period(硬編碼120)秒
- error log日誌級別為info(log_error_verbosity=3)
上述幾個條件,和並行回放的事務繁忙程度並沒有太大的關係,滿足條件即會記錄日誌。假如一個事務有4個event,參數設置正常,每兩分鐘執行256個事務,就會輸出一條日誌信息,一秒鐘3個事務不到。
日誌解析觀察
在我的日誌文件中,取瞭如下兩條連續的信息
2023-07-09T08:58:01.001019+08:00 909 [Note] [MY-010559] [Repl] Multi-threaded slave statistics for channel 'group_replication_applier': seconds elapsed = 180; events assigned = 11515905; worker queues filled over overrun level = 8314; waited due a Worker queue full = 0; waited due the total size = 0; waited at clock conflicts = 136628031500 waited (count) when Workers occupied = 242457 waited when Workers occupied = 2223254351900
2023-07-09T09:00:01.648124+08:00 909 [Note] [MY-010559] [Repl] Multi-threaded slave statistics for channel 'group_replication_applier': seconds elapsed = 120; events assigned = 11518977; worker queues filled over overrun level = 8314; waited due a Worker queue full = 0; waited due the total size = 0; waited at clock conflicts = 136644607700 waited (count) when Workers occupied = 242491 waited when Workers occupied = 2223755727800
第一條解析信息如下:
. 本次日誌輸出時間點為2023-07-09T08:58:01.001019
. 與上次日誌輸出間隔時間為180秒
. 累計處理event數量為11515905
. worker線程處理的event隊列長度超過最大隊列數(目前代碼硬編碼16384)的90%的累計次數8314次
. worker線程處理的event隊列長度達到最大隊列數(目前代碼硬編碼16384)的累計次數為0次
. 回放event大小達到replica_pending_jobs_size_max或者slave_pending_jobs_size_max的次數為0
. 由於不能並行回放而產生的累計等待時間為136628031500納秒(約136.62秒)
. 協調線程累計休眠242457次
. 累計等待空閑worker線程的時間為2223254351900納秒(約2223.33秒)
第二條解析信息如下:
. 本次日誌輸出時間點為2023-07-09T09:00:01.648124
. 與上次日誌輸出間隔時間為120秒
. 累計處理event數量為11518977,新增處理event數量3072(為1024的3倍)
. worker線程處理的event隊列長度超過最大隊列數(目前代碼硬編碼16384)的90%的累計次數8314次,新增0次
. worker線程處理的event隊列長度達到最大隊列數(目前代碼硬編碼16384)的累計次數為0次
. 回放event大小達到replica_pending_jobs_size_max或者slave_pending_jobs_size_max的次數為0
. 由於不能並行回放而產生的累計等待時間為136644607700納秒(約136.64秒,新增等待約0.02秒)
. 協調線程累計休眠242457次,新增34次
. 累計等待空閑worker線程的時間為2223755727800納秒(約2223.38,新增等待約0.05秒)
通過上述信息,可以看出,在日誌階段,系統處於空閑狀態,處理事務數不多。 對比各個參數,在系統繁忙時,因為不能並行回放產生的等待時間為136.64秒,等待空閑的worker線程累計時間為2223.38,因此增大slave_parallel_workers的參數值,可以提升並行回放性能。
總結
[Note] [MY-010559]在我剛開始接觸時,以為是系統出現了異常產生的日誌,待真正瞭解其內容後,才發現通過該日誌可以幫助我們瞭解MTS運行情況,針對性的做優化調整。
參考鏈接https://dev.mysql.com/doc/refman/8.0/en/replication-threads-monitor-worker.html
Enjoy GreatSQL


