
### 分享技術,用心生活 >背景:系統中有一個統計頁面載入特別慢,前端設置的40s超時時間都載入不出來數據,因為是個統計頁面,基本上一猜就知道是mysql的語句有問題,遺留了很久沒有解決,正好趁不忙的時候,下定決心一定把它給搞定! ## 1. 分析原因 (mysql5.7) 執行一下問題sql,可 ...
分享技術,用心生活
背景:系統中有一個統計頁面載入特別慢,前端設置的40s超時時間都載入不出來數據,因為是個統計頁面,基本上一猜就知道是mysql的語句有問題,遺留了很久沒有解決,正好趁不忙的時候,下定決心一定把它給搞定!
1. 分析原因
(mysql5.7)
執行一下問題sql,可以看到單表查就需要61s 這怎麼能忍受?

通過explain看一下執行計劃

挑重點,可以看到用命中了名為idx_first_date的索引,但是rows中掃描了1000多萬行的數據,這顯然是sql慢的根源。我們來查一下表數據量:
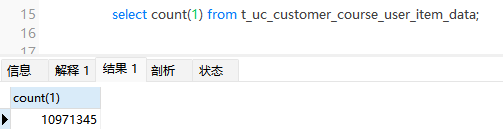
真真的千萬級的大表!
找到原因後,那麼就需要明確優化方向
- 通過設置分區
- 通過水平分表
- 通過優化sql
我們大概會有以上三種思路
分區方案會有諸多限制,比如可能會索引失效,占用記憶體,有主鍵限制等,故不採納
分表方案看來可行,通過縮小熱點數據,把非熱點數據全部放入分表。是可以達到效果。不過查詢表寫入日期後,發現最早在2021年。目前系統內查詢統計還會經常用到2021年數據。如果貿然分表後,帶來的連表查詢,數據管理問題等,現有代碼可能會出大問題。
那麼就只剩下優化sql這一條路了,雖然是千萬級數據的表,但是你要相信mysql是可以支撐的。
確定方向後,那就需要解決如何通過減少數據的掃描來實現提升性能。
通過sql可以看到,這個統計sql是根據日期查詢的,而且也命中了索引,那麼為什麼還會掃描這麼多數據呢?我們再去看下表的索引

發現貓膩了吧,idx_first_date是個聯合索引,再根據上圖key_len長度為67和最左匹配原則可知,mysql執行器是優先使用customer_id去掃描數據。所以幾乎全表掃描了。
我們把idx_first_date修改一下聯合索引的欄位順序,把first_date放在第一位,我們再來執行一下sql看下結果

1.6s!大呼!性能直接提升30倍!
你以為到這裡就結束了嗎?不不不!再看一張圖

發現了嗎,因為用了聯合索引,導致索引占用空間過大,比數據占用都大。我認為這裡存在濫用索引的現象。索引本身不止會占用空間,而且也會降低寫入性能,維護更新索引成本過高等。
把idx_first_date中的customer_id欄位去掉,再看下索引占用情況
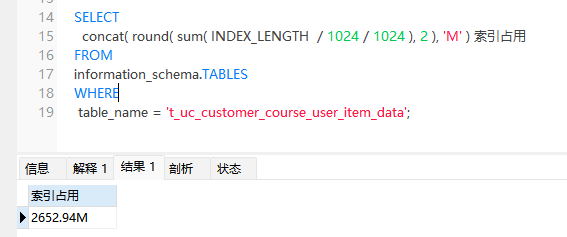
下降至2.6G,減少了將近1.4G的索引占用。
至此,這張千萬數據的大表慢sql已優化完,不僅提升了查詢性能,也減少了索引帶來的空間占用過大的問題。
本文由mdnice多平臺發佈


