# 1.安裝Django 終端運行 ``` pip install django ``` 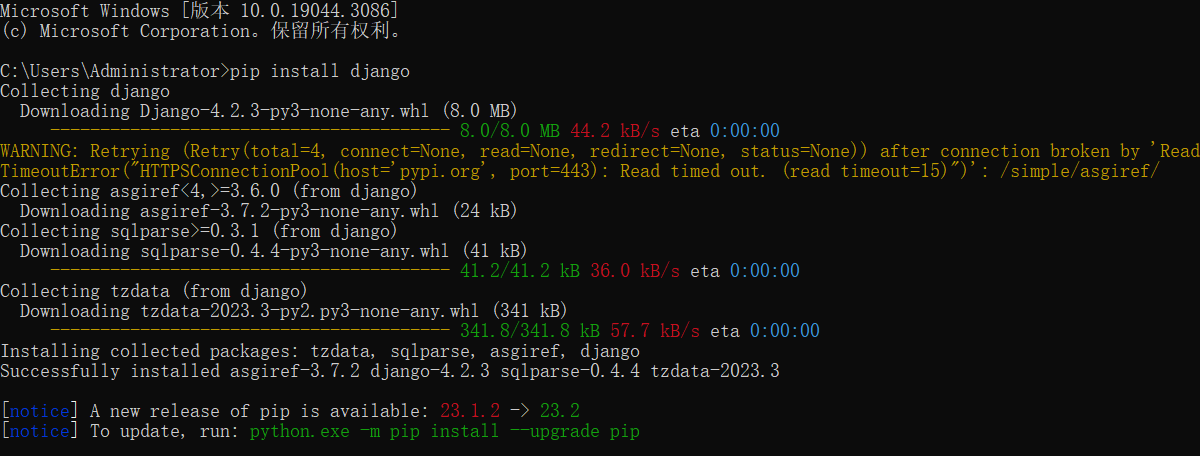 查看django是否安裝成功 ``` pyt ...
網路爬蟲,也稱為網頁爬蟲或者網頁蜘蛛,是一種用來自動瀏覽互聯網的網路機器人。它們會按照特定的規則,從網頁上獲取信息,然後將這些信息保存下來。網路爬蟲的名字來源於它們的工作方式,它們就像是在網路上爬行的蜘蛛,通過鏈接從一個網頁爬到另一個網頁。
工作原理
網路爬蟲的基本工作原理是按照一定的規則,自動地抓取網路信息。大體上,它的工作過程可以分為以下幾步:
-
初始URL: 爬蟲開始工作時,我們需要給它一些初始的URL。這些URL就像是爬蟲的"種子",提供了爬蟲的起點。
-
發送請求和獲取響應: 爬蟲會向這些URL發送請求,然後得到網頁的響應。這個過程就像是你在瀏覽器中輸入一個網址,然後瀏覽器顯示出網頁的過程。
-
解析網頁: 爬蟲會解析得到的網頁內容,從中提取出我們需要的信息,比如新聞的標題和內容、商品的價格和圖片等。
-
提取鏈接: 在解析網頁的過程中,爬蟲還會提取出網頁中的鏈接,然後將這些鏈接添加到待爬取的URL隊列中。
-
迴圈爬取: 爬蟲會重覆上述過程,不斷地從URL隊列中取出URL,發送請求,獲取響應,解析網頁,提取信息和鏈接,直到URL隊列為空,或者達到了我們設置的爬取深度。
這就是網路爬蟲的基本工作原理。它們就像是在網路上爬行的蜘蛛,通過鏈接從一個網頁爬到另一個網頁。
網路爬蟲的分類
按照工作方式,網路爬蟲可以分為兩類:一類是通用網路爬蟲,一類是聚焦爬蟲。
-
通用網路爬蟲: 通用網路爬蟲主要是搜索引擎使用的爬蟲,比如Google的Googlebot,它們的目標是儘可能地爬取整個網路。
-
聚焦爬蟲: 聚焦爬蟲則是針對特定的任務或者網站進行爬取,比如我們自己編寫的爬蟲,通常就是聚焦爬蟲。
網路爬蟲的應用
網路爬蟲有很多應用,比如搜索引擎的網頁索引,新聞的自動聚合,商品價格的監控等。在數據科學和機器學習領域,網路爬蟲也經常被用來收集訓練數據。
網路爬蟲的例子
這是一個簡單的Python網路爬蟲的例子,它使用requests庫發送請求,使用BeautifulSoup庫解析HTML,從Python官方網站上爬取所有PEP的標題。
import requests
from bs4 import BeautifulSoup
url = "https://www.python.org/dev/peps/"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
pep_list = soup.find('table', {"class": "list-table"}).findAll('tr')
for pep in pep_list[1:]:
number = pep.find('td', {"class": "pep-number"}).text
title = pep.find('td', {"class": "pep-title"}).text
print(f'{number}: {title}')
請求和響應
在網路爬蟲的工作過程中,發送請求和獲取響應是非常重要的一步。簡單來說,請求就是爬蟲向伺服器發送一個消息,告訴伺服器它想要獲取什麼信息,響應則是伺服器返回的消息,包含了爬蟲請求的信息。
HTTP協議是互聯網上應用最廣泛的一種網路協議,所有的WWW文件都必須遵守這個標準。一個HTTP請求包含三個部分:請求行、請求頭部和請求數據。同樣,HTTP響應也包含三個部分:狀態行、消息報頭和響應正文。
在Python中,我們常用的發送HTTP請求的庫有requests和urllib,其中requests更為簡單易用。
這是一個使用requests發送GET請求的例子:
import requests
response = requests.get('https://www.python.org')
print(response.status_code) # 列印狀態碼
print(response.text) # 列印響應內容
網頁解析
解析網頁是網路爬蟲的另一個重要步驟。網頁大部分是用HTML語言編寫的,HTML是一種標記語言,它的內容由一系列的標簽組成。我們可以通過解析HTML,提取出我們需要的信息。
Python中常用的HTML解析庫有BeautifulSoup和pyquery等,其中BeautifulSoup更為常用。
這是一個使用BeautifulSoup解析HTML的例子:
from bs4 import BeautifulSoup
html = """
<html>
<head>
<title>Test Page</title>
</head>
<body>
<h1>Welcome to the Test Page</h1>
<p>This is a <a href="https://www.example.com">link</a>.</p>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
title = soup.find('title').text
h1 = soup.find('h1').text
link = soup.find('a')['href']
print(f'Title: {title}')
print(f'H1: {h1}')
print(f'Link: {link}')
鏈接提取
鏈接提取是網路爬蟲的一項基本技能。通過提取網頁中的鏈接,網路爬蟲可以從一個頁面跳轉到另一個頁面,就像蜘蛛通過絲線在網上移動一樣。
在HTML中,鏈接通常由<a>標簽表示,鏈接的URL通常寫在href屬性中。我們可以用BeautifulSoup提取出所有的<a>標簽,然後讀取它們的href屬性,就可以得到所有的鏈接。
這是一個提取鏈接的例子:
from bs4 import BeautifulSoup
html = """
<html>
<body>
<a href="https://www.example.com">Link 1</a>
<a href="https://www.example2.com">Link 2</a>
<a href="https://www.example3.com">Link 3</a>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
links = soup.findAll('a')
for link in links:
print(link['href'])
這就是網路爬蟲的基本概念,它們# 網路爬蟲的概念
網路爬蟲,也稱為網頁爬蟲或者網頁蜘蛛,是一種用來自動瀏覽互聯網的網路機器人。它們會按照特定的規則,從網頁上獲取信息,然後將這些信息保存下來。網路爬蟲的名字來源於它們的工作方式,它們就像是在網路上爬行的蜘蛛,通過鏈接從一個網頁爬到另一個網頁。
推薦閱讀:
https://mp.weixin.qq.com/s/dV2JzXfgjDdCmWRmE0glDA
https://mp.weixin.qq.com/s/an83QZOWXHqll3SGPYTL5g