
瀏覽記錄系統主要用來記錄京東用戶的實時瀏覽記錄,並提供實時查詢瀏覽數據的功能。線上用戶訪問一次商品詳情頁,瀏覽記錄系統就會記錄用戶的一條瀏覽數據,並針對該瀏覽數據進行商品維度去重等一系列處理並存儲。然後用戶可以通過我的京東或其他入口查詢用戶的實時瀏覽商品記錄,實時性可以達到毫秒級。目前本系統可以為京... ...
1. 系統介紹
瀏覽記錄系統主要用來記錄京東用戶的實時瀏覽記錄,並提供實時查詢瀏覽數據的功能。線上用戶訪問一次商品詳情頁,瀏覽記錄系統就會記錄用戶的一條瀏覽數據,並針對該瀏覽數據進行商品維度去重等一系列處理並存儲。然後用戶可以通過我的京東或其他入口查詢用戶的實時瀏覽商品記錄,實時性可以達到毫秒級。目前本系統可以為京東每個用戶提供最近200條的瀏覽記錄查詢展示。
2. 系統設計與實現
2.1 系統整體架構設計
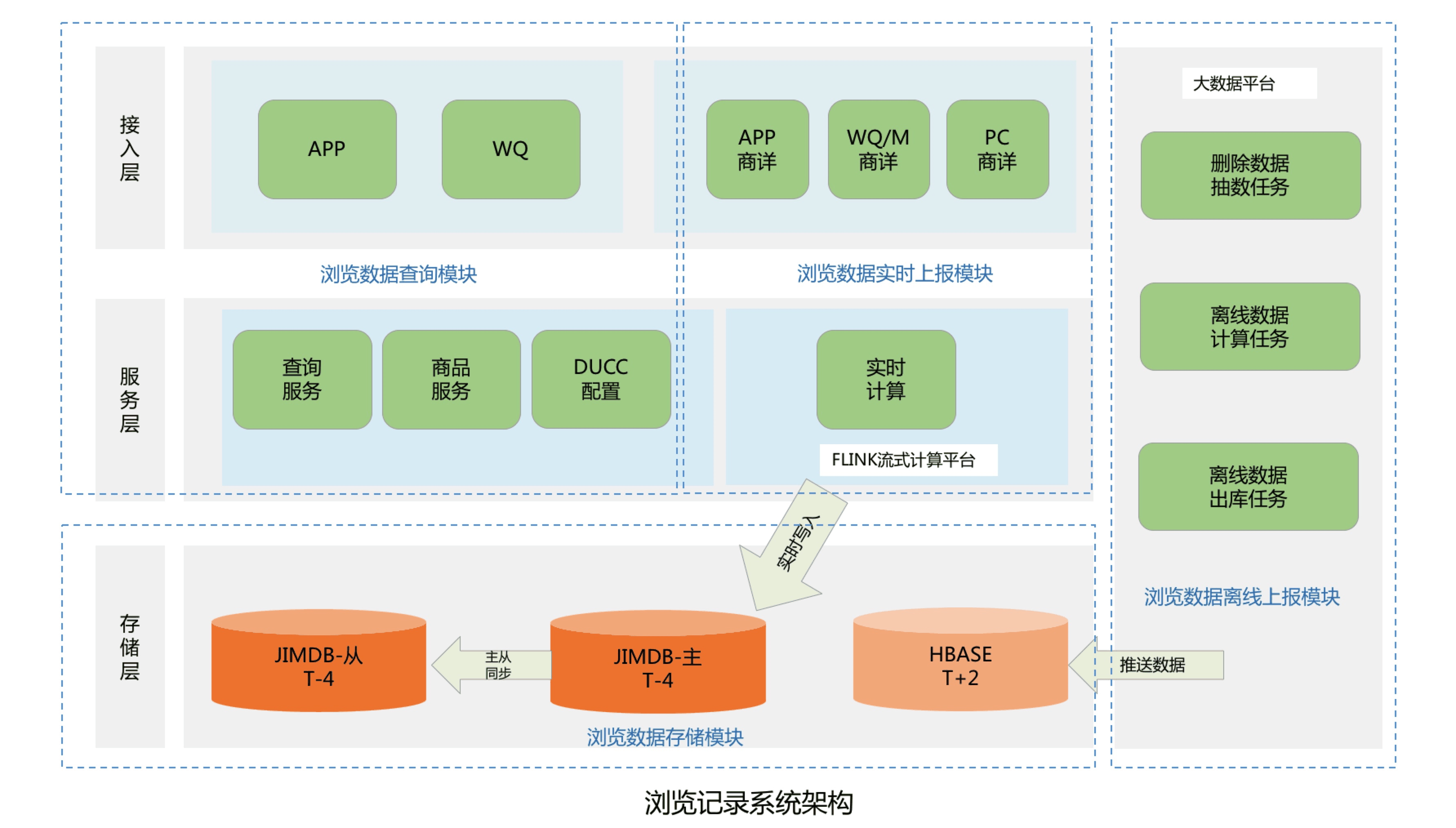
整個系統架構主要分為四個模塊,包括瀏覽數據存儲模塊、瀏覽數據查詢模塊、瀏覽數據實時上報模塊和瀏覽數據離線上報模塊:
- 瀏覽數據存儲模塊:主要用來存儲京東用戶的瀏覽歷史記錄,目前京東有近5億的活躍用戶,按照每個用戶保留最少200條的瀏覽歷史記錄,需要設計存儲近千億條的用戶瀏覽歷史數據;
- 瀏覽數據查詢模塊:主要為前臺提供微服務介面,包括查詢用戶的瀏覽記錄總數量,用戶實時瀏覽記錄列表和瀏覽記錄的刪除操作等功能;
- 瀏覽數據實時上報模塊:主要處理京東所有線上用戶的實時PV數據,並將該瀏覽數據存儲到實時資料庫;
- 瀏覽數據離線上報模塊:主要用來處理京東所有用戶的PV離線數據,將用戶歷史PV數據進行清洗,去重和過濾,最後將瀏覽數據推送到離線資料庫中。
2.1.1 數據存儲模塊設計與實現
考慮到需要存儲近千億條的用戶瀏覽記錄,並且還要滿足京東線上用戶的毫秒級瀏覽記錄實時存儲和前臺查詢功能,我們將瀏覽歷史數據進行了冷熱分離。Jimdb純記憶體操作,存取速度快,所以我們將用戶的(T-4)瀏覽記錄數據存儲到Jimdb的記憶體中,可以滿足京東線上活躍用戶的實時存儲和查詢。而(T+4)以外的離線瀏覽數據則直接推送到Hbase中,存儲到磁碟上,用來節省存儲成本。如果有不活躍的用戶查詢到了冷數據,則將冷數據複製到Jimdb中,用來提高下一次的查詢性能。
熱數據採用了JIMDB的有序集合來存儲用戶的實時瀏覽記錄,使用用戶名做為有序集合的KEY,瀏覽商品SKU作為有序集合的元素,瀏覽商品的時間戳作為元素的分數,然後針對該KEY設置過期時間為4天。
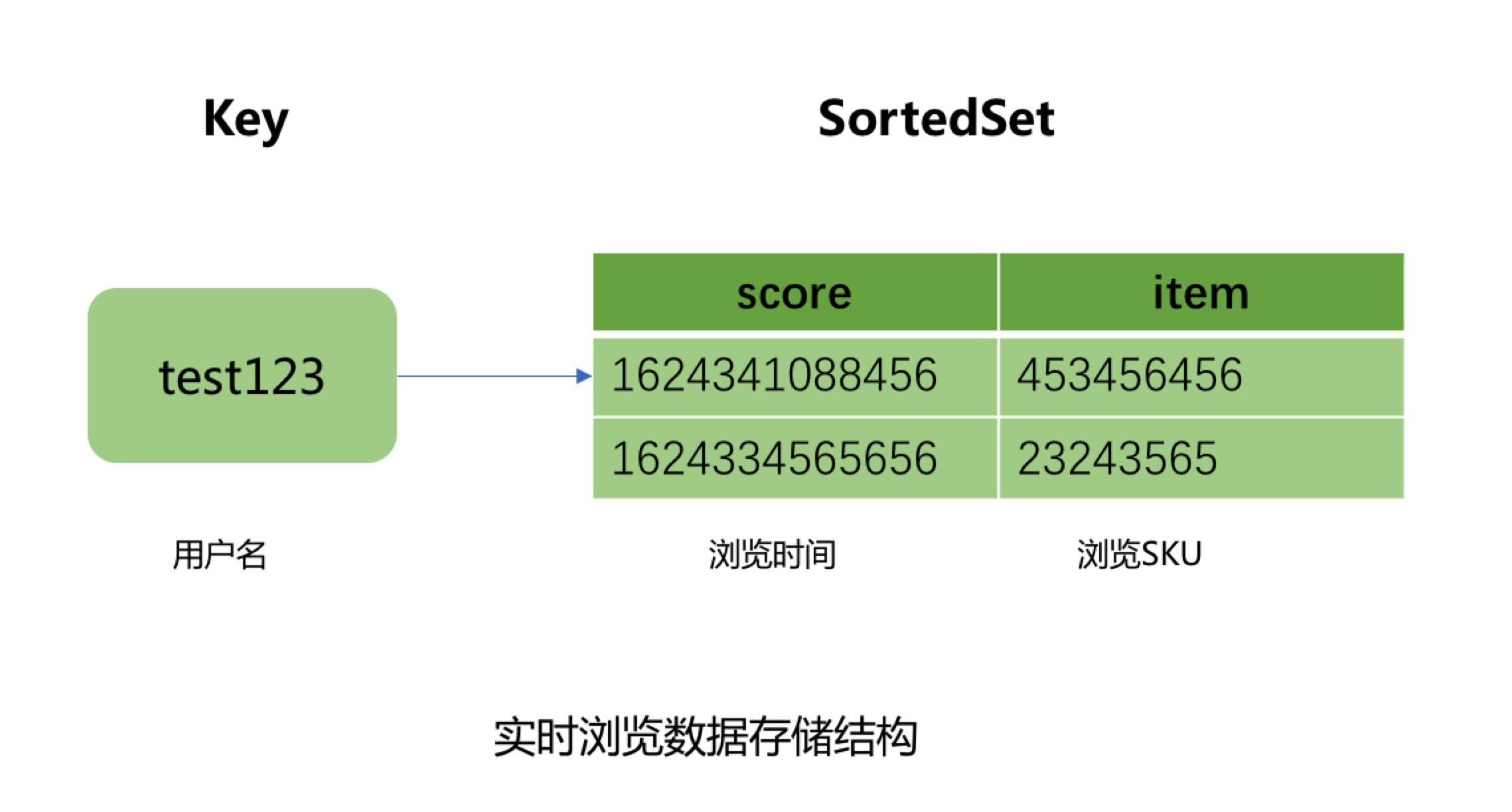
這裡的熱數據過期時間為什麼選擇4天?
這是因為我們的大數據平臺離線瀏覽數據都是T+1上報彙總的,等我們開始處理用戶的離線瀏覽數據的時候已經是第二天,在加上我們自己的業務流程處理和數據清洗過濾過程,到最後推送到Hbase中,也需要執行消耗十幾個小時。所以熱數據的過期時間最少需要設置2天,但是考慮到大數據任務執行失敗和重試的過程,需要預留2天的任務重試和數據修複時間,所以熱數據過期時間設置為4天。所以當用戶4天內都沒有瀏覽新商品時,用戶查看的瀏覽記錄則是直接從Hbase中查詢展示。
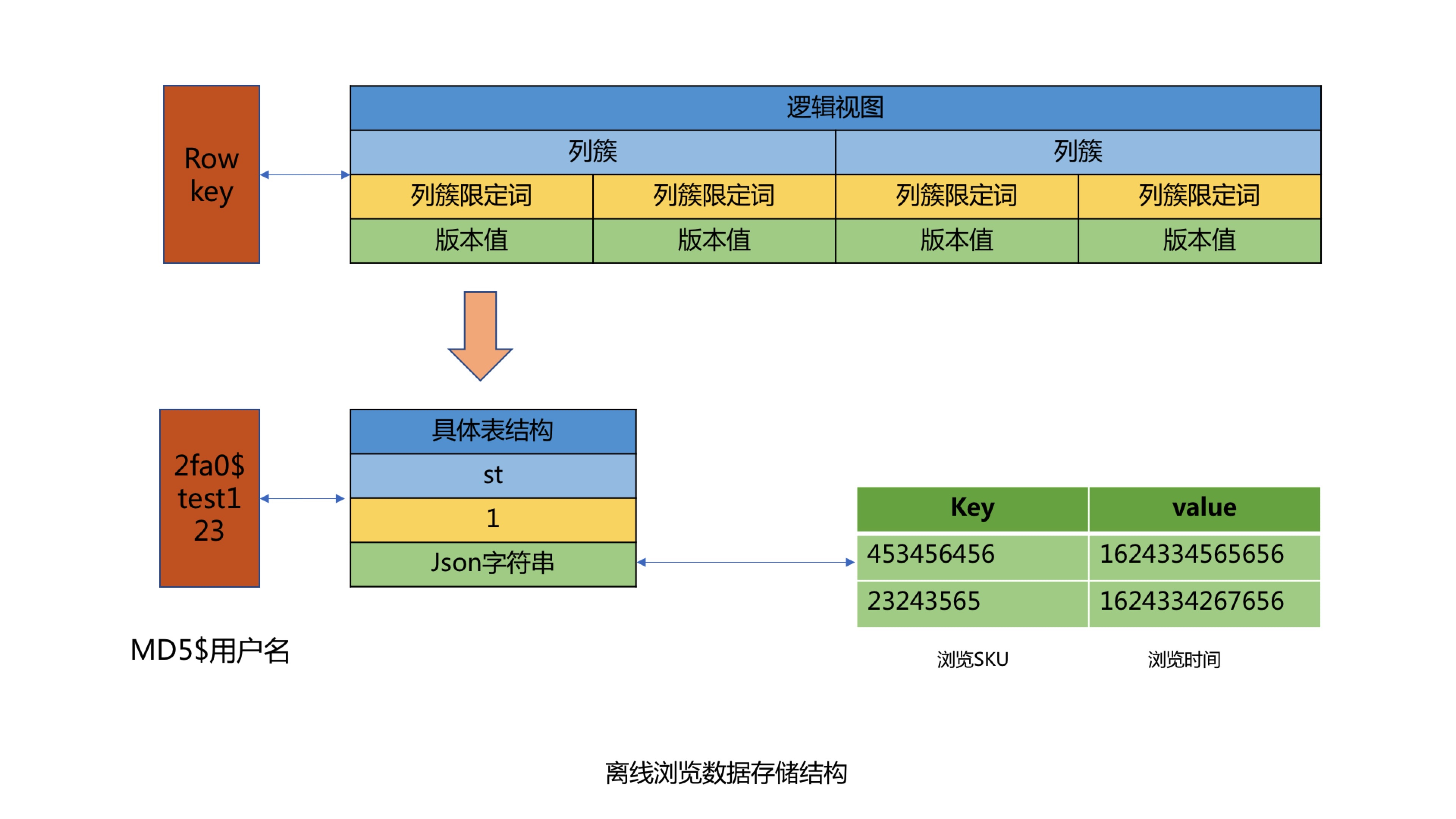
冷數據則採用K-V格式存儲用戶瀏覽數據,使用用戶名作為KEY,用戶瀏覽商品和瀏覽時間對應Json字元串做為Value進行存儲,存儲時需要保證用戶的瀏覽順序,避免進行二次排序。其中使用用戶名做KEY時,由於大部分用戶名都有相同的首碼,會出現數據傾斜問題,所以我們針對用戶名進行了MD5處理,然後截取MD5後的中間四位作為KEY的首碼,從而解決了Hbase的數據傾斜問題。最後在針對KEY設置過期時間為62天,實現離線數據的過期自動清理功能。
2.1.2 查詢服務模塊設計與實現
查詢服務模塊主要包括三個微服務介面,包括查詢用戶瀏覽記錄總數量,查詢用戶瀏覽記錄列表和刪除用戶瀏覽記錄介面。
- 查詢用戶瀏覽記錄總數量介面設計面臨的問題
1.如何解決限流防刷問題?
基於Guava的RateLimiter限流器和Caffeine本地緩存實現方法全局、調用方和用戶名三個維度的限流。具體策略是當調用發第一次調用方法時,會生成對應維度的限流器,並將該限流器保存到Caffeine實現的本地緩存中,然後設置固定的過期時間,當下一次調用該方法時,生成對應的限流key然後從本地緩存中獲取對應的限流器,該限流器中保留著該調用方的調用次數信息,從而實現限流功能。
2.如何查詢用戶瀏覽記錄總數量?
首先查詢用戶瀏覽記錄總數緩存,如果緩存命中,直接返回結果,如果緩存未命中則需要從Jimdb中查詢用戶的實時瀏覽記錄列表,然後在批量補充商品信息,由於用戶的瀏覽SKU列表可能較多,此處可以進行分批查詢商品信息,分批數量可以動態調整,防止因為一次查詢商品數量過多而影響查詢性能。由於前臺展示的瀏覽商品列表需要針對同一SPU商品進行去重,所以需要補充的商品信息欄位包括商品名稱、商品圖片和商品SPUID等欄位。針對SPUID欄位去重後,在判斷是否需要查詢Hbase離線瀏覽數據,此處可以通過離線查詢開關、用戶清空標記和SPUID去重後的瀏覽記錄數量來判斷是否需要查詢Hbase離線瀏覽記錄。如果去重後的時候瀏覽記錄數量已經滿足系統設置的用戶最大瀏覽記錄數量,則不再查詢離線記錄。如果不滿足則繼續查詢離線的瀏覽記錄列表,並與用戶的實時瀏覽記錄列表進行合併,並過濾掉重覆的瀏覽SKU商品。獲取到用戶完整的瀏覽記錄列表後,在過濾掉用戶已經刪除的瀏覽記錄,然後count列表的長度,並與系統設置的用戶最大瀏覽記錄數量做比較取最小值,就是該用戶的瀏覽記錄總數量,獲取到用戶瀏覽記錄總數量後可以根據緩存開關來判斷是否需要非同步寫入用戶總數量緩存。
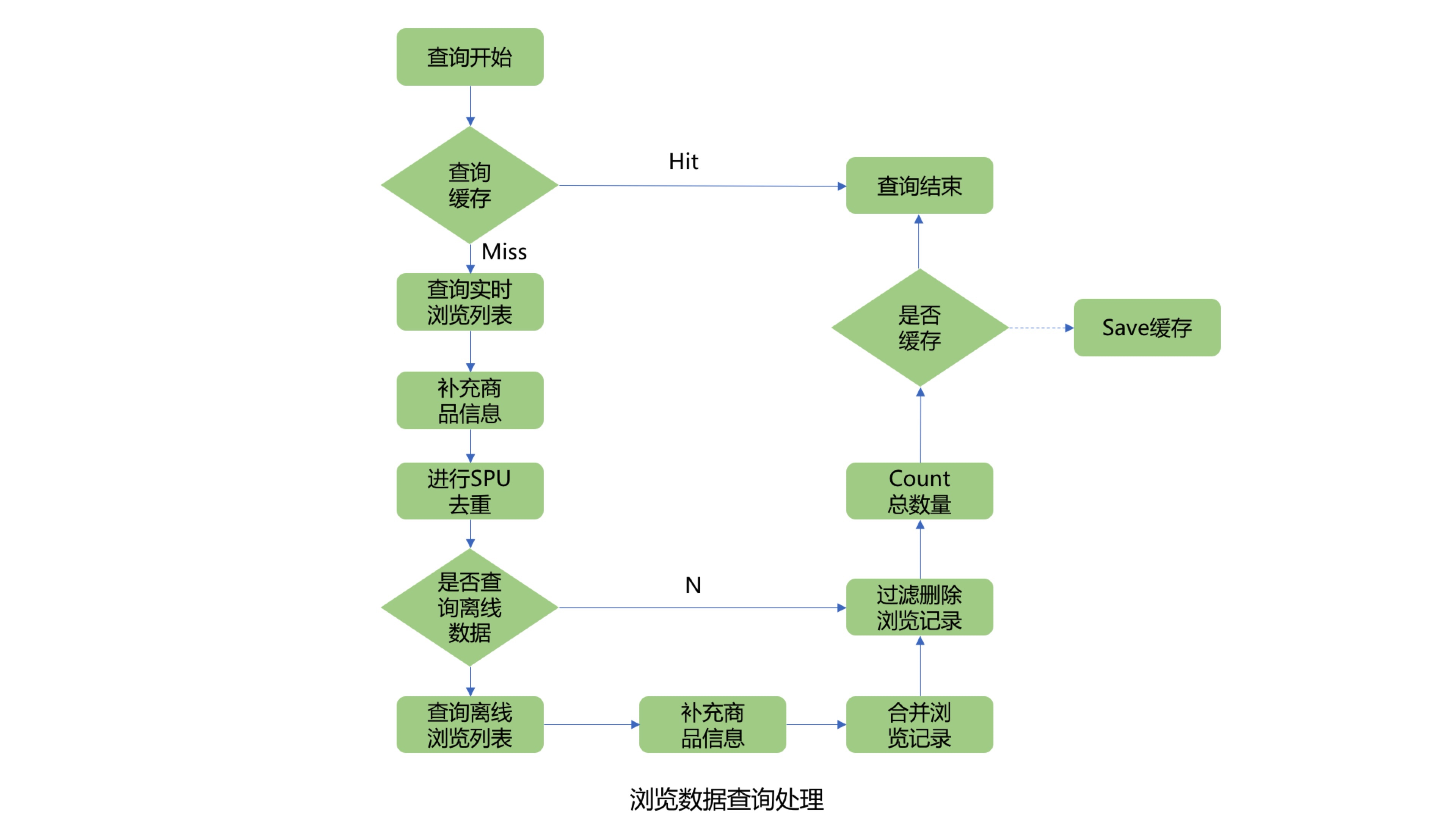
3.查詢用戶瀏覽記錄列表
查詢用戶瀏覽記錄列表流程與查詢用戶瀏覽記錄總數量流程基本一致。
2.1.2 瀏覽數據實時上報模塊設計與實現
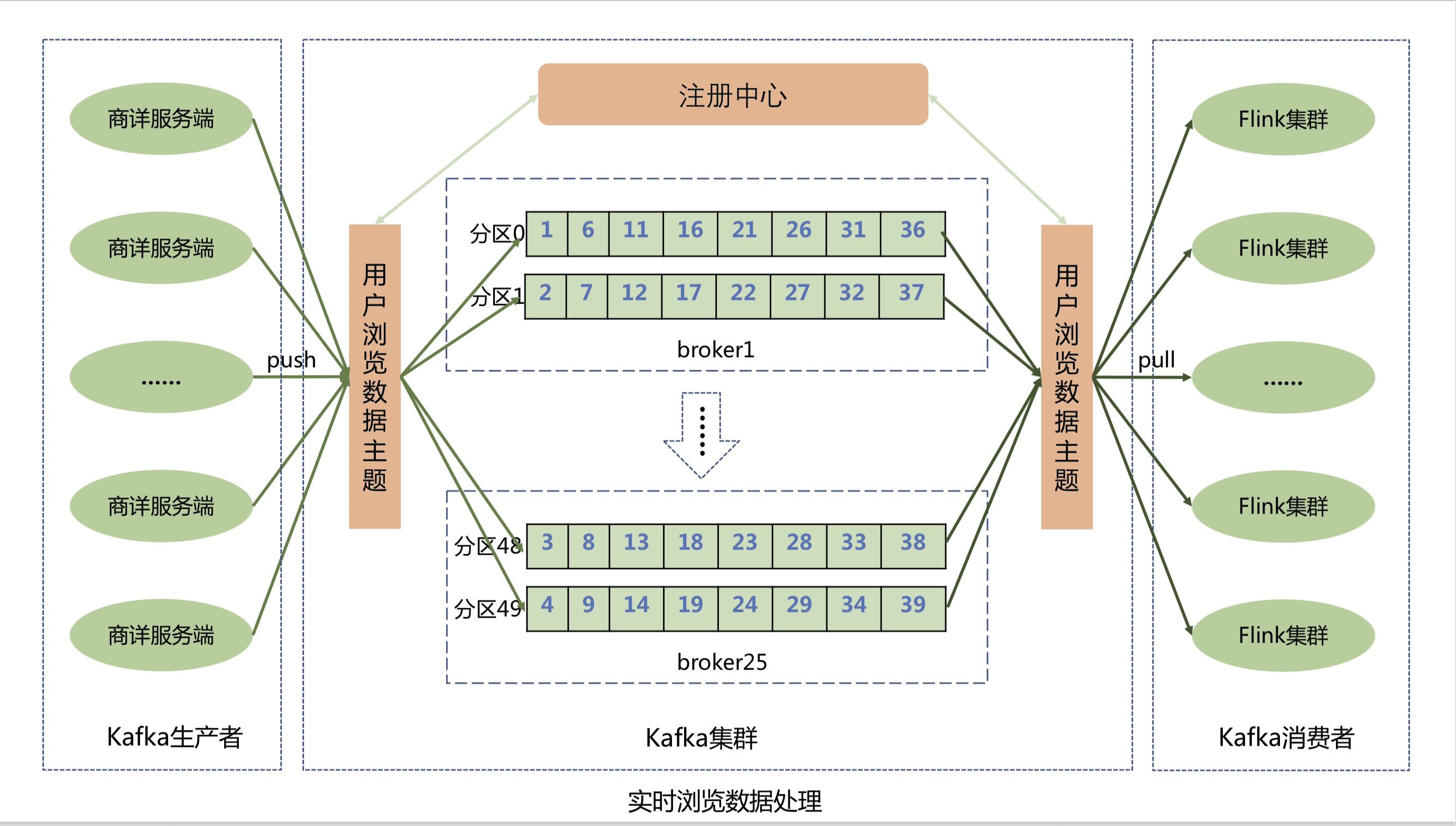
商詳服務端將用戶的實時瀏覽數據通過Kafka客戶端上報到Kafka集群的消息隊列中,為了提高數據上報性能,用戶瀏覽數據主題分成了50個分區,Kafka可以將用戶的瀏覽消息均勻的分散到50個分區隊列中,從而大大提升了系統的吞吐能力。
瀏覽記錄系統則通過Flink集群來消費Kafka隊列中的用戶瀏覽數據,然後將瀏覽數據實時存儲到Jimdb記憶體中。Flink集群不僅實現了橫向動態擴展,進一步提高Flink集群的吞吐能力,防止出現消息積壓,還保證了用戶的瀏覽消息恰好消費一次,在異常發生時不會丟失用戶數據並能自動恢復。Flink集群存儲實現使用Lua腳本合併執行Jimdb的多個命令,包括插入sku、判斷sku記錄數量,刪除sku和設置過期時間等,將多次網路IO操作優化為1次。
為什麼選擇Flink流式處理引擎和Kafka,而不是商詳服務端直接將瀏覽數據寫入到Jimdb記憶體中呢?
首先,京東商城做為一個7x24小時服務的電子商務網站,並且有著5億+的活躍用戶,每一秒中都會有用戶在瀏覽商品詳情頁,就像是流水一樣,源源不斷,非常符合分散式流式數據處理的場景。
而相對於其他流式處理框架,Flink基於分散式快照的方案在功能和性能方面都具有很多優點,包括:
- 低延遲:由於操作符狀態的存儲可以非同步,所以進行快照的過程基本上不會阻塞消息的處理,因此不會對消息延遲產生負面影響。
- 高吞吐量:當操作符狀態較少時,對吞吐量基本沒有影響。當操作符狀態較多時,相對於其他的容錯機制,分散式快照的時間間隔是用戶自定義的,所以用戶可以權衡錯誤恢復時間和吞吐量要求來調整分散式快照的時間間隔。
- 與業務邏輯的隔離:Flink的分散式快照機制與用戶的業務邏輯是完全隔離的,用戶的業務邏輯不會依賴或是對分散式快照產生任何影響。
- 錯誤恢復代價:分散式快照的時間間隔越短,錯誤恢復的時間越少,與吞吐量負相關。
第二,京東每天都會有很多的秒殺活動,比如茅臺搶購,預約用戶可達上百萬,在同一秒鐘就會有上百萬的用戶刷新商詳頁面,這樣就會產生流量洪峰,如果全部實時寫入,會對我們的實時存儲造成很大的壓力,並且影響前臺查詢介面的性能。所以我們就利用Kafka來進行削峰處理,而且也對系統進行瞭解耦處理,使得商詳系統可以不強制依賴瀏覽記錄系統。
這裡為什麼選擇Kafka?
這裡就需要先瞭解Kakfa的特性。
- 高吞吐、低延遲:kakfa 最大的特點就是收發消息非常快,kafka 每秒可以處理幾十萬條消息,它的最低延遲只有幾毫秒。
- 高伸縮性: 每個主題(topic) 包含多個分區(partition),主題中的分區可以分佈在不同的主機(broker)中。
- 持久性、可靠性: Kafka能夠允許數據的持久化存儲,消息被持久化到磁碟,並支持數據備份防止數據丟失,Kafka底層的數據存儲是基於Zookeeper存儲的,Zookeeper我們知道它的數據能夠持久存儲。
- 容錯性: 允許集群中的節點失敗,某個節點宕機,Kafka集群能夠正常工作。
- 高併發: 支持數千個客戶端同時讀寫。
Kafka為什麼這麼快?
-
Kafka通過零拷貝原理來快速移動數據,避免了內核之間的切換。
-
Kafka可以將數據記錄分批發送,從生產者到文件系統到消費者,可以端到端的查看這些批次的數據。
-
批處理的同時更有效的進行了數據壓縮並減少I/O延遲。
-
Kafka採取順序寫入磁碟的方式,避免了隨機磁碟定址的浪費。
目前本系統已經經歷多次大促考驗,且系統沒有進行降級,用戶的實時瀏覽消息沒有積壓,基本實現了毫秒級的處理能力,方法性能TP999達到了11ms。
2.1.3 瀏覽數據離線上報模塊設計與實現
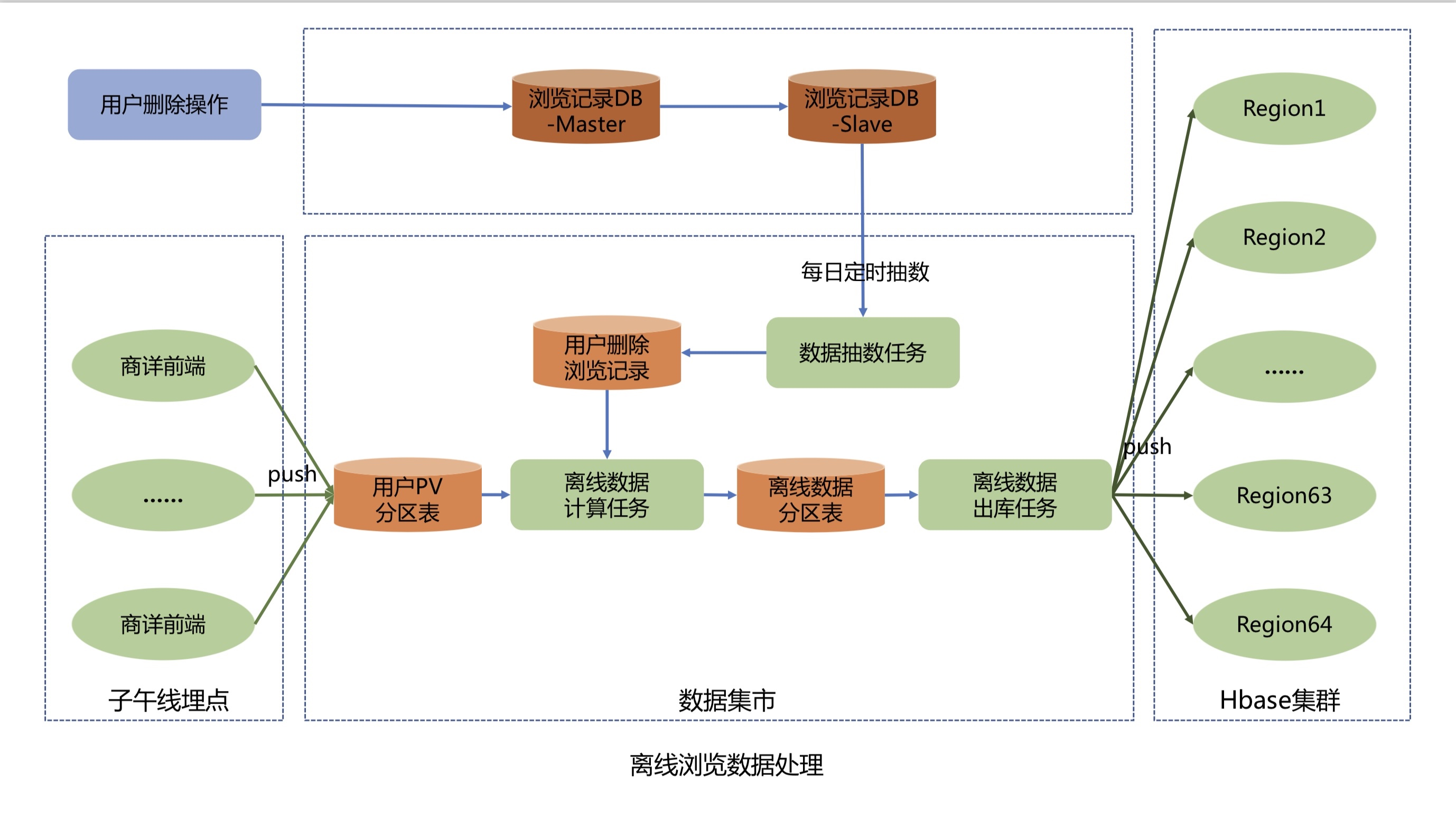
離線數據上報處理流程如下:
-
商詳前端通過子午線的API將用戶的PV數據進行上報,子午線將用戶的PV數據寫入到數據集市的用戶PV分區表中。
-
數據抽數任務每天凌晨2點33分從瀏覽記錄系統Mysql庫的用戶已刪除瀏覽記錄表抽數到數據集市,並將刪除數據寫入到用戶刪除瀏覽記錄表。
-
離線數據計算任務每天上午11點開始執行,先從用戶PV分區表中提取近60天、每人200條的去重數據,然後根據用戶刪除瀏覽記錄表過濾刪除數據,並計算出當天新增或者刪除過的用戶名,最後存儲到離線數據分區表中。
-
離線數據出庫任務每天凌晨2點從離線數據分區表中將T+2的增量離線瀏覽數據經過數據清洗和格式轉換,將T+2活躍用戶的K-V格式離線瀏覽數據推送到Hbase集群。
作者:京東零售 曹志飛
來源:京東雲開發者社區


