
[數據資產](https://www.dtstack.com/dtinsight/dataassets?src=szsm=07)現在需要接入數棧內部相關應用的時候,支持查看血緣的類型從表、離線任務增加到需要表、離線任務、實時任務、API任務、指標、標簽等,需要支持數棧現有的所有應用任務,最終實現在[ ...
數據資產現在需要接入數棧內部相關應用的時候,支持查看血緣的類型從表、離線任務增加到需要表、離線任務、實時任務、API任務、指標、標簽等,需要支持數棧現有的所有應用任務,最終實現在數據資產平臺查看任務的完整應用鏈路。
雖然增加不同的任務,現階段資產實現的血緣大體上能夠滿足需求,但是也會出現問題,因此需要進行技術革新。本文將聚焦資產血緣的實現方案,並介紹袋鼠雲數棧在數據血緣建設過程中所遇到的挑戰和技術實現。
資產血緣的當前問題
現階段血緣展示內容重覆高
在資產的 A 任務血緣鏈路中,C/D 任務下游均為 E 任務,當我們同時打開了 C/D 任務的下游節點,就會發現大量的重覆節點出現,但本質上他們是一模一樣的任務節點,如下圖。
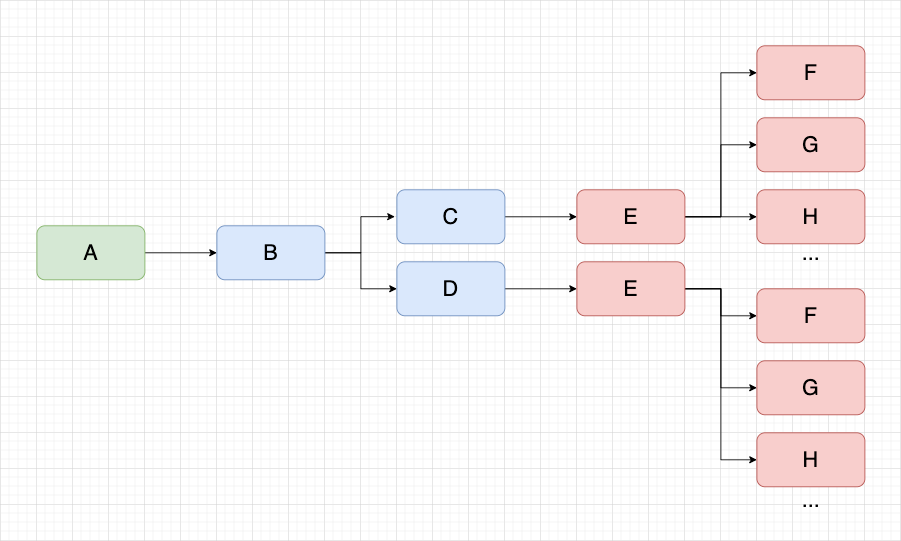
當一條血緣上的任務越多,出現上述問題的概率增大,會導致畫布內容顯示的都是重覆節點,查看血緣關係效率低下。
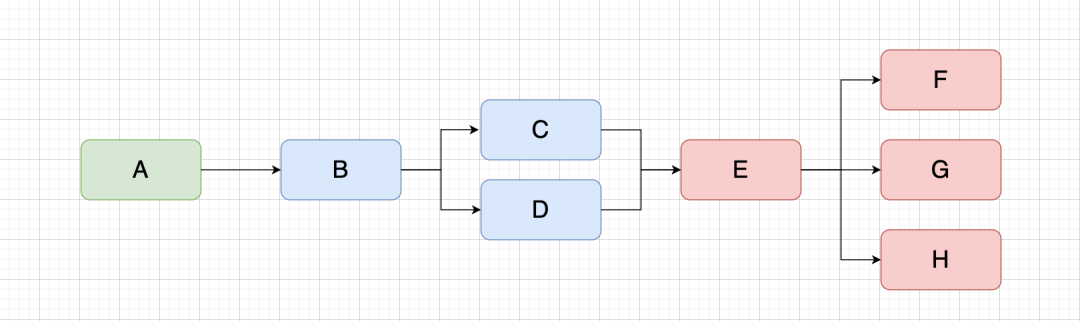
期望能夠做到同一個節點只在畫布中展示一次,在這個節點存在於畫布中時,後續再有相同節點就做共用,如下圖。
逆向血緣的展示
先簡單介紹一下,何為逆向血緣?用 API 任務舉例子來說:
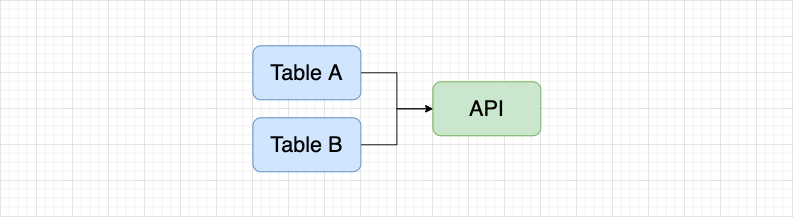
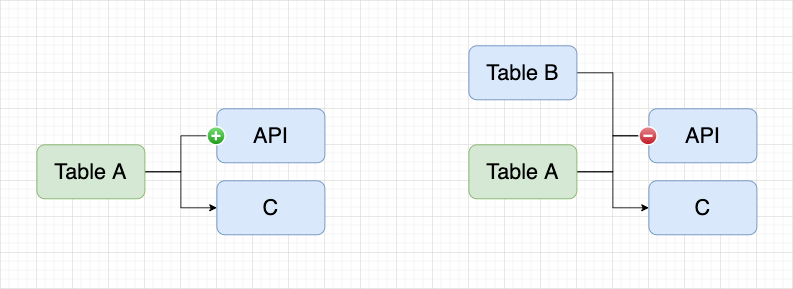
在 API 平臺中,通過 DQL 模式使用兩張表創建一個 API,在資產平臺以 API 任務進入血緣就會展示如下圖的血緣關係。如果 Table A 已經同步到了資產平臺,以 Table A 表進入血緣,希望展示如下圖的血緣關係。
由於 API 是由 Table A/B 共同生成的,因此需要在 API 左側展示加號,能夠將 Table B 載入出來,這就是逆向血緣,也是全鏈路實現的重要一環。
相似數據源
當同一個數據源被不同的引擎連接之後,會產生不同的數據源A或數據源A1,但是實際上底層是同一個數據源,被我們稱之為相似數據源。

此時任務1和任務2並不會有相關聯繫,但其實它兩用的是相同的底層表,展示是不符合期望的,希望能夠在血緣展示上將其視為同一張表,相關的任務也能關聯展示。
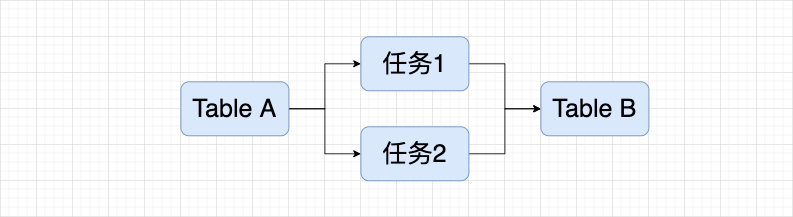
上述問題成為資產實現全鏈路血緣需要去實現或者優化的當前血緣方案的理由,下文將給出對應問題的解決方案。
資產血緣實現解決方案
前置內容瞭解
● 任務血緣數據結構
interface ITaskKinShip {
metaId: number; // 元Id
metaType: number; // 元類型
metaDataInfo: object; // 表、api、任務、標簽等的元數據信息的元數據信息
lineageTableId: string; // 血緣Id
tableKey: string; // 表key source.db.table
sonIds: number[]; // 子節點血緣定位Id list
fatherIds: number[]; // 父節點血緣定位Id list
sonLineage: ITaskKinShip[]; // 子表級血緣
fatherLineage: ITaskKinShip[]; // 父表級血緣
isOpen: boolean; // 是否存在逆向血緣
}
● 欄位血緣數據結構
interface IColumn {
columnId: string; // 欄位Id
columnName: string; // 欄位類型
columnType: string; // 欄位
lineageColumnId: string; // 欄位血緣定位Id
withManual: boolean; // 是否手動維護
withMasked: boolean; // 是否脫敏欄位
sonIds: number[]; // 子ID
fatherIds: number[]; // 父ID
columnKey: string; // 欄位key source.db.table.column
}
interface IColumnKinShip extends ITaskKinShip {
columns: IColumn[]; // 欄位血緣
}
● 血緣關係圖
· 初始化時預設展示3層:即只展示以數據表本節點為中心,上下游分別的一個節點,共3層
· 節點可擴展:點擊“+”按鈕,在節點前方或後方再展示出3個節點;點擊“-”按鈕,斷開該“-”按鈕對應的連線
· 右鍵:在非中心節點上,添加右鍵菜單“查看此節點血緣”;滑鼠右鍵可查看當前節點血緣,以該節點為中心的血緣
整體思路
● 實現節點共用
我們想要去實現節點共用,就會去判斷當前節點是否已經存在於 graph 中,如果存在我們就不再渲染節點,否則就去渲染節點,這樣就可以實現節點只被渲染一次。
對於每一個節點信息來說,tableKey 都是唯一的,因此我們將 tableKey 作為每一個 vertex 的唯一標識,在創建 vertex 時,傳入 tableKey 作為唯一標識。
createVertex = (treeData) => {
const { graph, Mx } = this.GraphEditor;
const rootCell = graph.getDefaultParent();
const style = this.GraphEditor.getStyles(treeData);
const doc = Mx.mxUtils.createXmlDocument();
const tableInfo = doc.createElement('table');
const { vertex, fatherLineage, sonLineage, ...newData } = treeData;
tableInfo.setAttribute('data', JSON.stringify(newData));
// 通過 tableKey 在當前 graph 查找 vertex
const cell = graph.getModel().getCell(treeData.tableKey);
// 如果能夠找到就不創建新的 vertex,否則創建
const newVertex =
cell ||
graph.insertVertex(
rootCell,
treeData.tableKey,
tableInfo,
20,
20,
VertexSize.width,
VertexSize.height,
style
);
return { rootCell, style, vertex: newVertex };
}
如果我們採用上述的想法,那這個節點可以同時成為中心節點的上游節點和下有節點,甚至就是中心節點。因此我們需要更改我們存儲節點的結構,需要存儲節點作為上游節點的信息以及作為下有節點的信息。
當從後端請求來數據之後,我們需要對數據做一個整理,不再存放在 state 中,而是將其存在以 tableKey 為 key,名為 vertexMap 的 Map 對象中。後續的渲染對象,也根據 vertexMap 去做渲染。
vertexMap 的定義如下,主要用於存儲 tableKey 為鍵值的節點信息。
vertexMap = new Map<
string,
{
rootData?: ITaskKinShip; // 節點作為根節點存儲的數據
parentData?: ITaskKinShip; // 節點作為上游節點存儲的數據
childData?: ITaskKinShip; // 節點作為下游節點存儲的數據
canDeleteData?: any; // 能夠被刪除的數據,用於刪除的時候判斷
}
>()
通過 checkData 方法來將後端給的數據處理到 vertexMap 中,重點是需要整合同為上游節點或者同為下游節點的數據。
checkData = (treeData: ITaskKinShip) => {
const {
tableKey,
isRoot = false,
isParent,
sonIds,
fatherIds,
sonLineage,
fatherLineage,
} = treeData;
const mapData = this.vertexMap.get(tableKey);
// 標識為根結點
if (mapData?.rootData) return true;
// 判斷是上游節點還是下游節點
const newKey = isRoot ? 'rootData' : isParent ? 'parentData' : 'childData';
// 如果不存在上游節點/下有節點的數據直接賦值
if (!mapData?.[newKey])
return this.vertexMap.set(tableKey, { ...mapData, [newKey]: treeData });
// 否則,需要整合相同節點的 sonIds/fatherIds sonLineage/fatherLineage,為後續的判斷提供依據
const nodeData = mapData[newKey];
const {
sonIds: exitSonIds,
fatherIds: exitFatherIds,
fatherLineage: exitFatherLineage,
sonLineage: exitSonLineage,
} = nodeDat
nodeData.sonIds = [...new Set(sonIds.concat(exitSonIds).filter((id) => id !== 'exist'))];
nodeData.fatherIds = [
...new Set(fatherIds.concat(exitFatherIds).filter((id) => id !== 'exist')),
];
nodeData.sonLineage = [...new Set(sonLineage.concat(exitSonLineage))];
nodeData.fatherLineage = [...new Set(fatherLineage.concat(exitFatherLineage))];
nodeData.isChildShow = nodeData.isChildShow || treeData.isChildShow;
nodeData.isParentShow = nodeData.isParentShow || treeData.isParentShow;
this.vertexMap.set(tableKey, { ...mapData, [newKey]: nodeData });
};
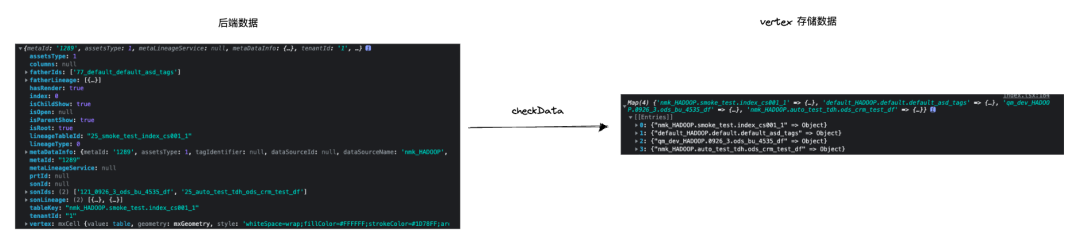
上述是對血緣數據的處理,對於整個血緣圖節點如下圖:
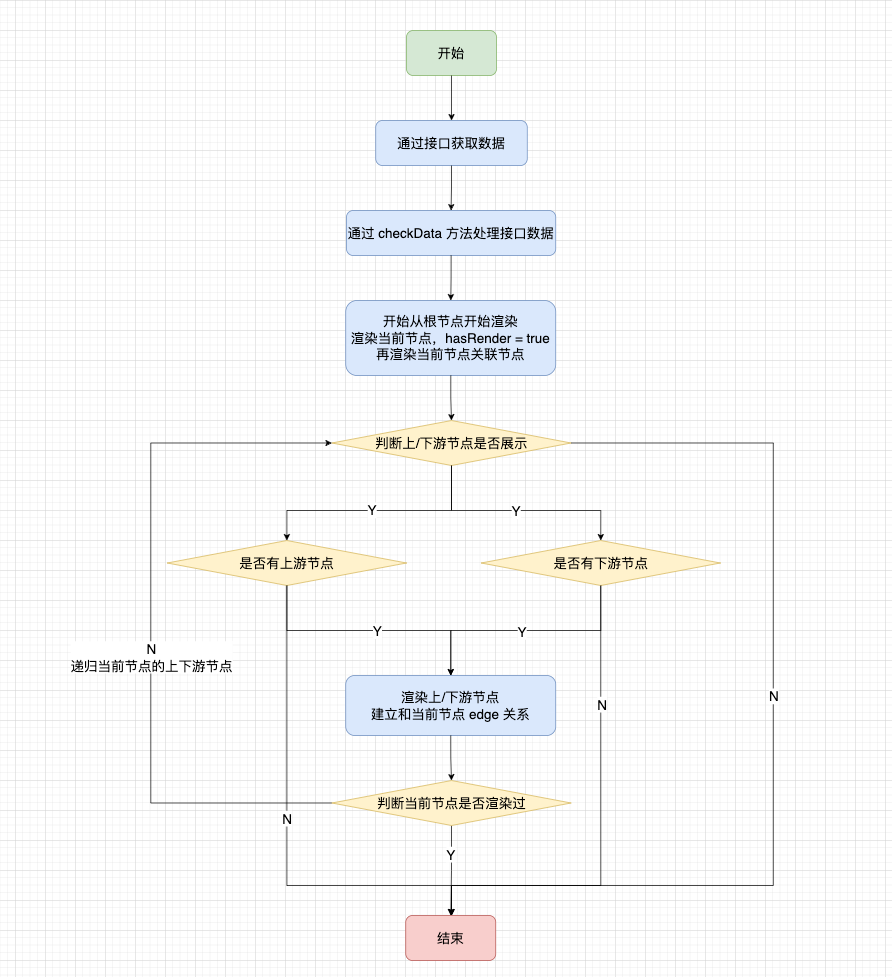
● 如何控制節點擴展
當我們的每一個節點被渲染出來的時候,可能會存在按鈕,可以展開上下三層的更多節點。由於節點共用以及需要支持逆向血緣的需求,因此按鈕的狀態會發生變化:
· 中心節點不會有按鈕
· 中心節點下游節點有下游血緣時,有右側按鈕;存在逆向血緣時,有左側按鈕
· 中心節點上游節點有上游血緣時,有左側按鈕;存在逆向血緣時,有右側按鈕
註意是否存在逆向血緣,通過後端介面的 isOpen 標識來做判斷。
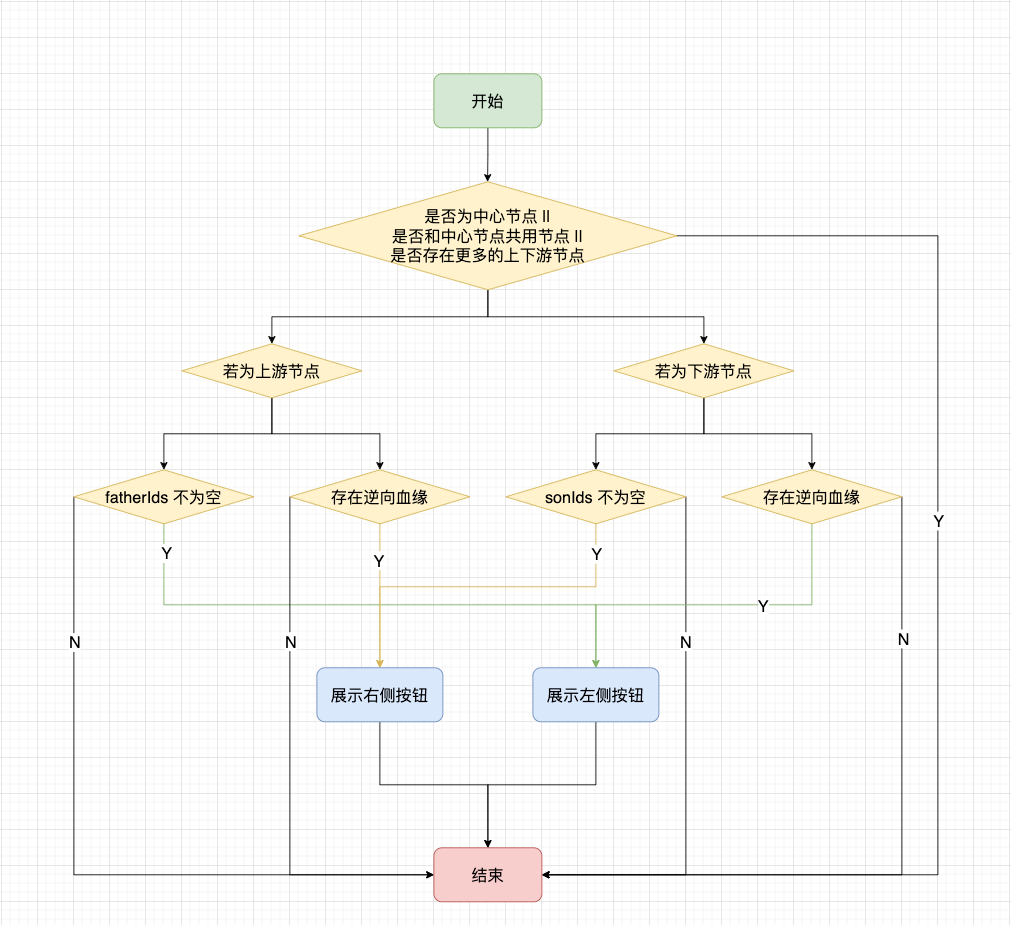
對於普通的 + 號來說,點擊 + 號時,一次性會請求三層數據;對於逆向血緣的 + 號來說,一次性請求一層數據;點擊 - 號來說,會將其後續的節點都收起來。
對於每一個節點來說,我們會添加 isParentShow/isChildShow 來表示當前節點上下游是否展開。
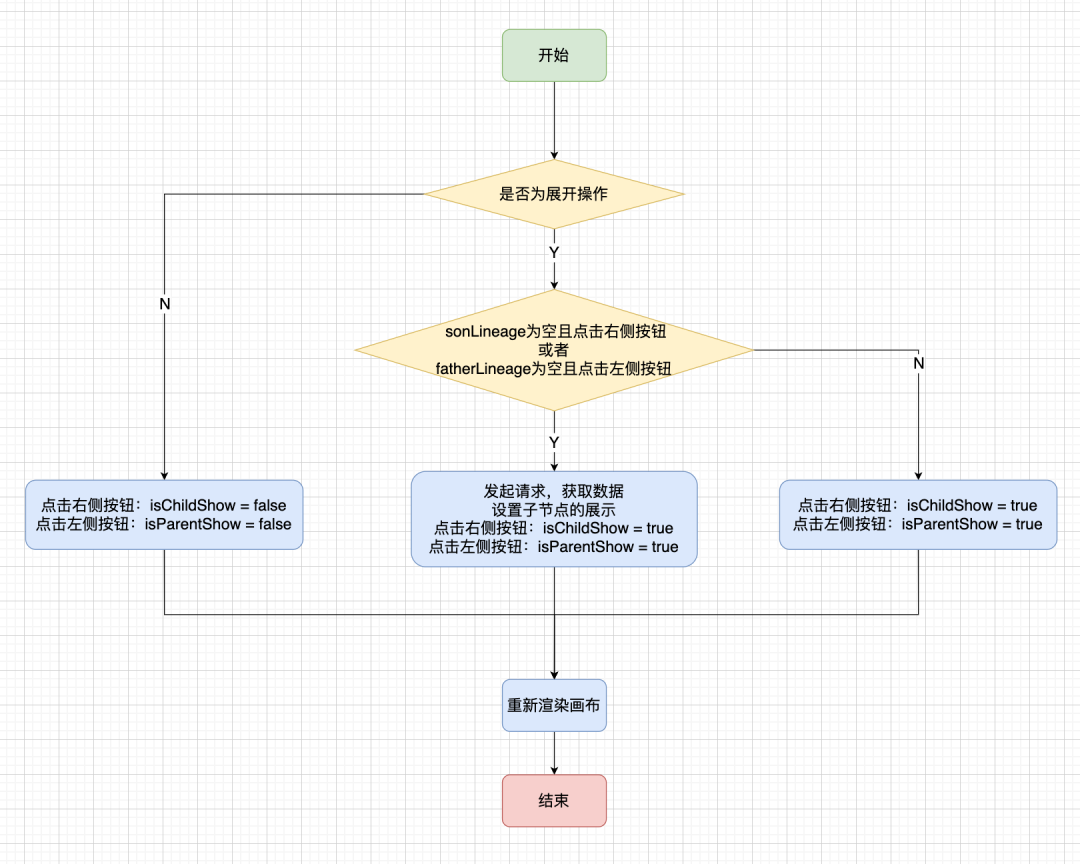
· 收起操作:如果點擊的按鈕處於展開狀態,則將相關聯節點收起。點擊右邊按鈕時,對當前節點設置 isChildShow = false;點擊左邊按鈕時,對當前節點設置isParentShow = false。
· 展開操作:如果點擊的按鈕處於收起狀態,則將相關聯節點展開。點擊右邊按鈕時,如果不存在 sonLineage 說明尚未獲取過血緣節點信息,向後端發起請求;否則對當前節點設置isChildShow = true。對於左邊按鈕也是如此。
相關的判斷流程如下圖:
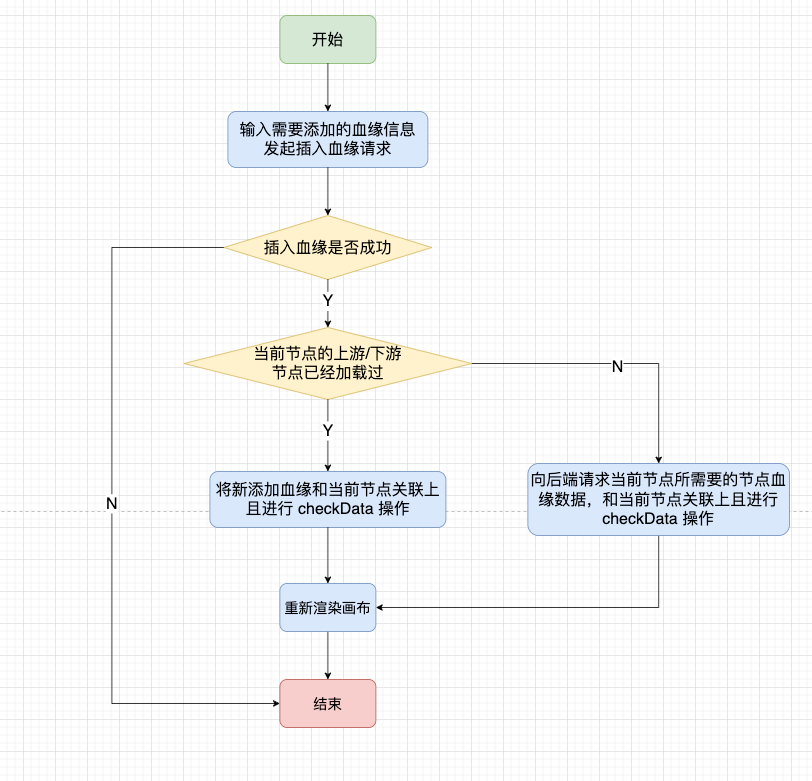
● 如何處理增加/刪除節點
我們可以採用右鍵去插入血緣表或者插入影響表。當我們去做插入血緣操作的時候,也分為兩種情況,判斷當前節點是否已經載入過上游、下游節點,如果載入過,直接把新血緣數據添加到 vertexMap 中;否則,向後端發起請求,獲取當前節點的血緣數據。
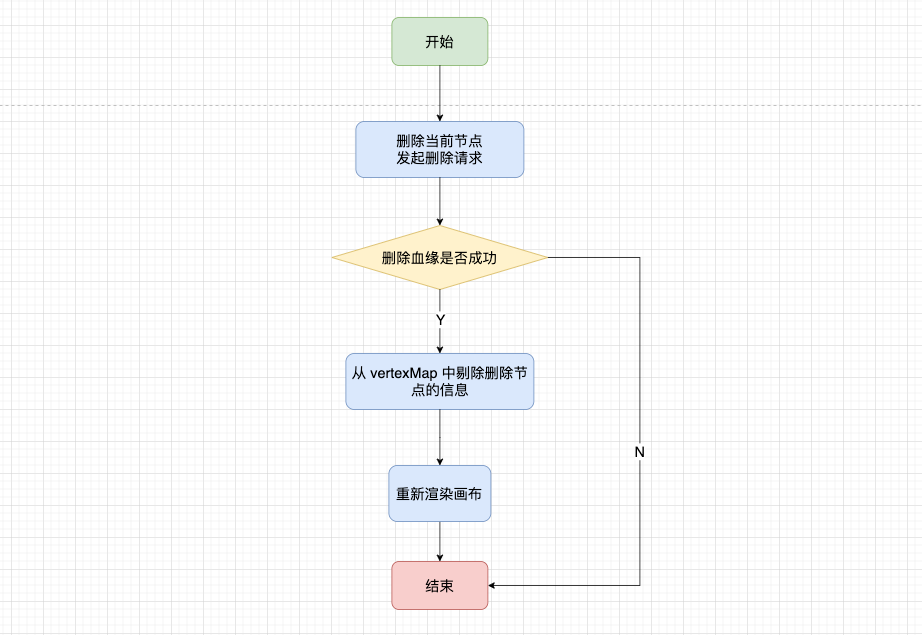
對於刪除節點來說,不能夠再像之前那樣找到其父級節點刪除對應節點之後再重新渲染畫布,對於節點共用來說,這會出現問題。在資產平臺來說,血緣節點分為兩種,一種是通過 sqlParser 解析出來的,不能夠進行手動刪除;另一種是我們通過右鍵手動添加的,是可以刪除的。
當我們遇到手動添加和解析出來的節點共用時,我們進行刪除就需要特殊處理,將解析出來節點的相關信息保留下來。
在我們插入節點的時候,我們會根據後端標識位 withManual 得知是解析還是手動添加的,使用 canDeleteData 維護手動添加的節點父級信息。
if (withManual) {
canDeleteData.push({
lineageTableId: obj.lineageTableId,
parentTableKey: obj.tableKey,
});
}
在最開始我們實現節點共用的時候,我們將同一個節點的 sonIds/sonLineage 等信息通過 checkData 方法整合在一起,刪除的時候應該配合 canDeleteData 把對應的數據一同清理掉。
刪除操作的大致流程如下圖:
● 處理特殊的類型節點
由於承接了各個應用的血緣展示,不乏一些特殊的節點,常規的方案無法滿足節點展示需求,因此需要做特殊處理。
對於實時的 FlinkSQL 就是需要特殊處理的,虛線框中的是 FlinkSQL 的相關內容,和映射源表、映射結果表連接的節點需要用虛線連接。
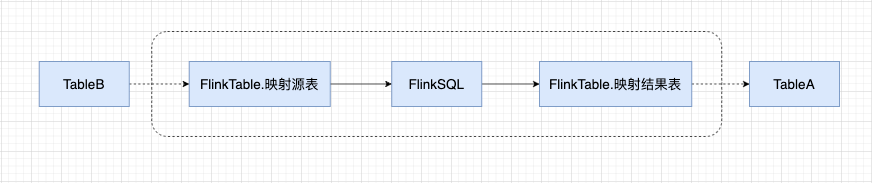
對於 FlinkSQL 的相關數據後端存放於 metaDataInfo 中,parentFlinkInfos 表示映射源表,sonFlinkInfos 表示映射結果表。
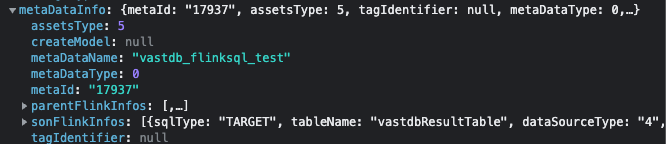
因此根據 FlinkSQL 所處的位置不同,會有不同的渲染邏輯:
· 中心節點
渲染 parentFlinkInfos 創建 parentFlinkTableNode 與 FlinkSQL 節點實線連接,parentFlinkTableNode 再和上游節點使用虛線連接;渲染 sonFlinkInfos 創建 sonFlinkTableNode 與 FlinkSQL 節點實線連接,創建的 sonFlinkTableNode 再和下游節點使用虛線連接。
· 上游節點
渲染 sonFlinkInfos 創建 sonFlinkTableNode 與當前節點虛線連接,渲染 FlinkSQL 節點和 sonFlinkTableNode 實線連接,渲染 parentFlinkInfos 創建 parentFlinkTableNode 與 FlinkSQL 節點實線連接,parentFlinkTableNode 再去和別的上游節點使用虛線連接。
· 下游節點
渲染 parentFlinkInfos 創建 parentFlinkTableNode 與當前節點虛線連接,渲染 FlinkSQL 節點和 parentFlinkTableNode 實線連接,渲染 sonFlinkInfos 創建 sonFlinkTableNode 與 FlinkSQL 節點實線連接,sonFlinkTableNode 再去和別的下游節點使用虛線連接。
● 相似數據源
在相似數據源上,前端並沒有對其做過的處理,均為後端判斷為相似數據源給到前端做相關展示。
● 欄位級血緣
上述講的都是表級血緣的實現,欄位級血緣也實現了節點共用等功能,整體思路和表級血緣一致。唯一需要註意的是實時的欄位血緣,如果存在兩個結果表時,會存在多個中心節點,所以需要遍歷,渲染兩個中心節點。
《數棧產品白皮書》:https://www.dtstack.com/resources/1004?src=szsm
《數據治理行業實踐白皮書》下載地址:https://www.dtstack.com/resources/1001?src=szsm
想瞭解或咨詢更多有關袋鼠雲大數據產品、行業解決方案、客戶案例的朋友,瀏覽袋鼠雲官網:https://www.dtstack.com/?src=szbky
同時,歡迎對大數據開源項目有興趣的同學加入「袋鼠雲開源框架釘釘技術qun」,交流最新開源技術信息,qun號碼:30537511,項目地址:https://github.com/DTStack


