
#爬取豆瓣Top250圖書數據 項目的實現步驟 1.項目結構 2.獲取網頁數據 3.提取網頁中的關鍵信息 4.保存數據 **1.項目結構** 
2.獲取網頁數據
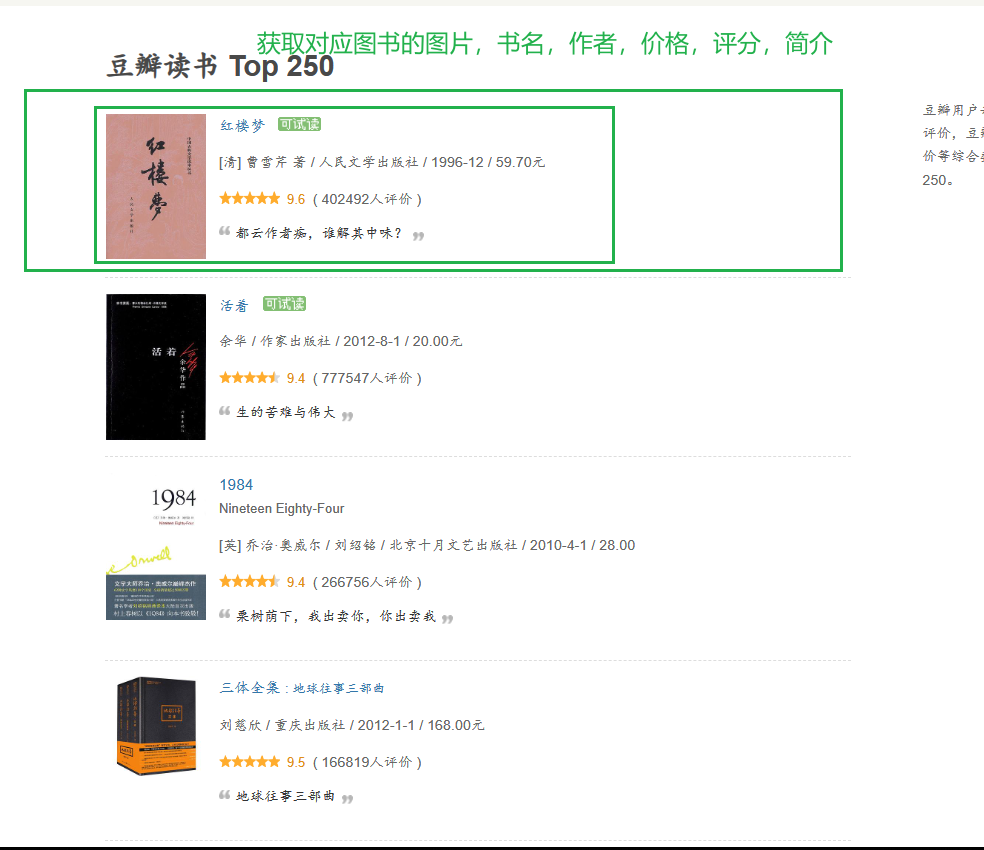
對應的網址為https://book.douban.com/top250
import requests
from bs4 import BeautifulSoup
"""
獲取網頁數據,解析數據,將相應的數據傳出
"""
def get_page(url):
headers = {
'User-Agent':'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) '
'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 '
'Mobile Safari/537.36 Edg/114.0.1823.43'
}
resp=requests.get(url,headers=headers)
soup=BeautifulSoup(resp.text,'html.parser')
return soup
3.提取網頁中的關鍵信息
獲取傳出的解析後的數據,獲取對應的圖片,書名,作者,價格,評價,簡介
from geturlcocument.get_document import get_page
import re
# 初始數據
pictures=[]
names=[]
authors=[]
prices=[]
scores=[]
sums=[]
def get_single():
# 網址地址
urls = [f"https://book.douban.com/top250?start={num}" for num in range(0,250,25)]
for url in urls:
# 獲取對應的網頁文本
text = get_page.get_page(url)
# 所有數據的集合
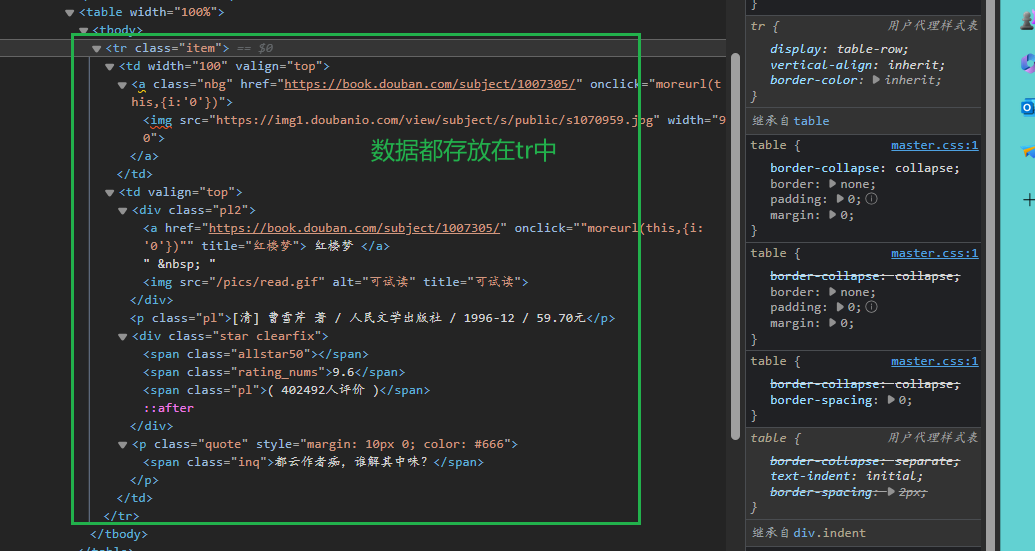
all_tr = text.find_all(name="tr", attrs={"class": "item"})
# 查找每個單項
for tr in all_tr:
# 數據類型:圖片,書名,作者,價格,評分,簡介
# 圖片
picture = tr.find(name="img")
picture = picture.get('src')
# print(picture)
# 書名
div = tr.find(name='div', attrs={'class': 'pl2'})
name = div.find('a').text
name = re.sub(r'\s+', '', name)
# 作者
author = tr.find(name='p', attrs={'class': 'pl'}).text
author = author.split('/')[0]
# 價格
price = author.split('/')[-1]
price = re.sub(r'元', '', price)
# 評分
score = tr.find(name='span', attrs={'class': 'rating_nums'}).text
try:
sum = tr.find(name='span', attrs={'class': 'inq'}).text
except AttributeError:
sum = ''
pictures.append(picture)
names.append(name)
authors.append(author)
prices.append(price)
scores.append(score)
sums.append(sum)
data = {
"picture": pictures,
"name": names,
"author": authors,
"price": prices,
"score": scores,
"sum": sums
}
return data
將獲取的數據存入到字典中,將數據傳出,使用re庫對相應的數據進行處理,運用異常檢錯
4.保存數據
獲取傳出的字典類型的數據,將數據存入到pandas的DataFrame類型中
from geturlcocument.get_single_docuemnt import get_single
import pandas as pd
# 獲取字典類型的數據
data=get_single.get_single()
# 用pandas的DataFrame類型存儲數據
df=pd.DataFrame(data)
df.to_csv('./books.csv',encoding='utf-8')
print('ending of data')
該項目完成!!!


