
一、HBase簡介 HBase是一個開源的、分散式的、版本化的NoSQL資料庫(即非關係型資料庫),依托Hadoop分散式文件系統HDFS提供分散式數據存儲,利用MapReduce來處理海量數據,用Zookeeper作為其分散式協同服務,一般用於存儲海量數據。HDFS和HBase的區別在於,HDFS ...
一、HBase簡介
HBase是一個開源的、分散式的、版本化的NoSQL資料庫(即非關係型資料庫),依托Hadoop分散式文件系統HDFS提供分散式數據存儲,利用MapReduce來處理海量數據,用Zookeeper作為其分散式協同服務,一般用於存儲海量數據。HDFS和HBase的區別在於,HDFS是文件系統,而HBase是資料庫。HBase只是一個NoSQL資料庫,把數據存在HDFS上。可以把HBase當做是MySQL,把HDFS當做是硬碟。
二、HBase的數據結構
1、索引結構:LSM樹
傳統關係型數據普通索引採用B+樹。B+樹最大的性能問題是會產生大量的隨機IO,隨著新數據的插入,葉子節點會慢慢分裂,邏輯上連續的葉子節點在磁碟存儲上往往不連續,分離得很遠,隨機讀寫概率會變大,做範圍查詢時,會產生大量讀隨機IO。為了剋服B+樹的弱點,HBase引入了LSM樹的概念,即Log-Structured Merge-Trees,直譯為日誌結構合併樹。基於LSM樹實現的HBase的寫性能相比Mysql放棄部分磁碟讀性能,換取寫性能的大幅提升。
LSM樹嚴格來說不是一個具體的數據結構,更多是一種數據結構的設計思想。LSM樹不是一棵樹,而是由至少兩個存儲結構構成。假設這兩顆樹分別為C0和C1,C0比較小,全部駐於記憶體之中,具體可以是任何方便健值查找的數據結構。而C1則駐於機械硬碟。一條新的記錄先是從C0中插入,如果這一次的插入造成了C0數據量超出了閥值,那麼C0中的部分些數據片段則會直接合併到C1樹中。如果有多級樹,當C1體量越來越大就向C2合併,低級的樹在達到大小閾值後也會在磁碟中進行合併,以此類推,一直往上合併Ck。
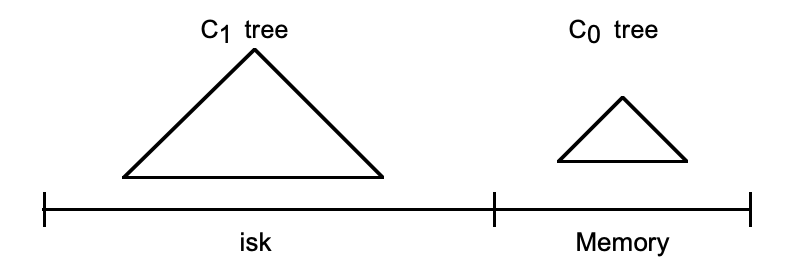
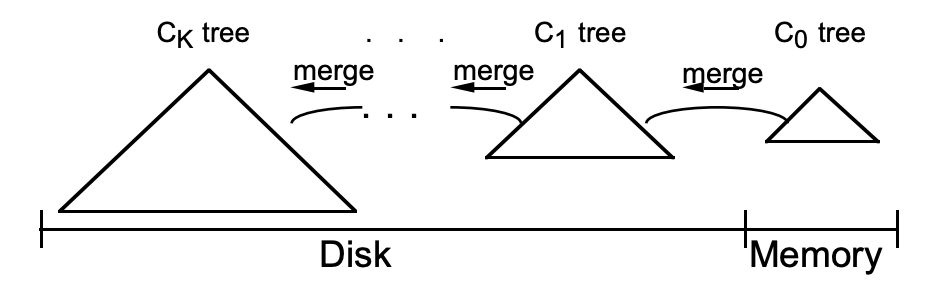
LSM樹的設計思想:
劃分不同等級的樹。將對數據的修改增量保持在記憶體中,數據更新只在記憶體中操作,沒有磁碟訪問。達到指定的大小限制後將這些修改操作批量寫入磁碟。由於記憶體的讀寫速率都比磁碟要快非常多,因此數據寫入記憶體的效率很高。隨著小樹越來越大,達到指定的閥值限制後將這些修改操作批量寫入磁碟,磁碟中的樹定期做多路歸併操作,合併成一棵大樹,以優化讀性能。隨機讀寫比順序讀寫慢很多,為了提升IO性能,需要將隨機操作變為順序操作。LSM樹使用日誌文件和一個記憶體存儲結構把隨機寫轉化成順序寫,讀寫獨立,數據從記憶體刷入磁碟時是預排序的,寫性能大幅提升。讀取的時候稍微麻煩,需要先看是否命中記憶體,如果讀取的是最近訪問過的數據則可以命中,否則需要訪問較多的磁碟文件。
使用LSM樹的資料庫除了HBase,還有nessDB、levelDB、TiDB、RocksDB等。

(圖中MongoDB只有WiredTiger(WT)存儲引擎既支持B-樹,又支持LSM樹存儲索引。)
2、存儲結構
HBase的LSM樹中存儲的是多個Key-Value結構組成的集合,每一個Key-Value一般都會用一個位元組數組來表示。這個位元組數組串設計如圖所示:
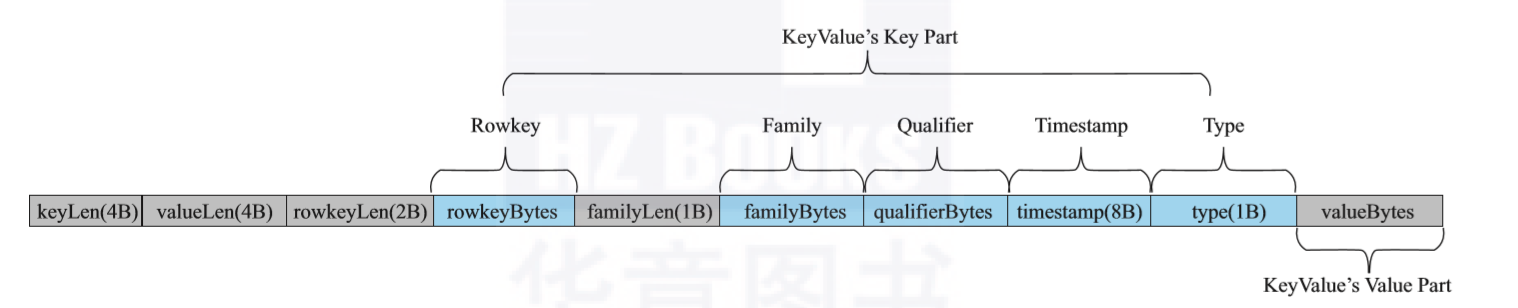
(圖源:胡爭,範欣欣《HBase原理與實踐》第二章《基礎數據結構與演算法》)
位元組數組主要分為以下幾個欄位。其中Rowkey、Family、Qualifier、Timestamp、Type這5個欄位組成KeyValue中的key部分。
• keyLen:用來存儲KeyValue結構中Key所占用的位元組長度。
• valueLen:用來存儲KeyValue結構中Value所占用的位元組長度。
• rowkeyLen:用來存儲rowkey占用的位元組長度。
• rowkeyBytes:用來存儲rowkey的二進位內容。
• familyLen:用來存儲Family占用的位元組長度。
• familyBytes:用來存儲Family的二進位內容。
• qualif ierBytes:用來存儲Qualif ier的二進位內。註意,HBase並沒有單獨分配位元組用來存儲qualif ierLen,因為可以通過keyLen和其他欄位的長度計算出qualif ierLen。
• timestamp:表示timestamp對應的long值。
• type:表示這個KeyValue操作的類型,HBase內有Put、Delete、Delete Column、DeleteFamily,等等。
HBase的LSM樹在記憶體一般採用跳躍表存儲,跳躍表的查找、刪除、插入的複雜度都是O(logN)。
LSM樹在磁碟中的數據結構也不是樹結構,而是Key-Value結構組成的序列,稱為SSTable(Sorted String Table)有序字元串表。當SSTable太大時,為了加快SSTable的讀取,可以將其劃分為多個塊,通過記錄每個塊的起始位置,構建每個SSTable的稀疏索引。這樣在讀SSTable前,通過索引就知道要讀取的數據塊磁碟位置了。SSTable索引需要永遠載入在記憶體里。寫是寫記憶體,因此隨機寫十分快。讀也是讀記憶體里的 SSTable的索引,並且這裡每一個SSTable索引如果用二分法查找,演算法複雜度大致在O(lg(n))與O(n)之間,因此隨機讀也不慢。
3、表結構
與傳統的關係型資料庫類似,HBase也以表的形式組織數據,表也由行和列組成,不同的是,HBase採用列式存儲。
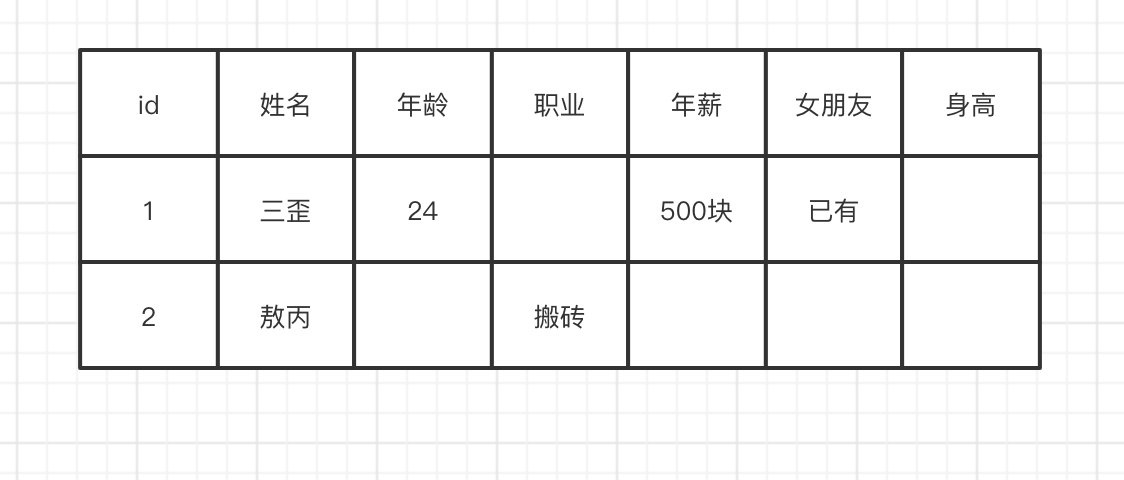
如上圖所示的表,如果採用列式存儲,會存成下圖的結構:
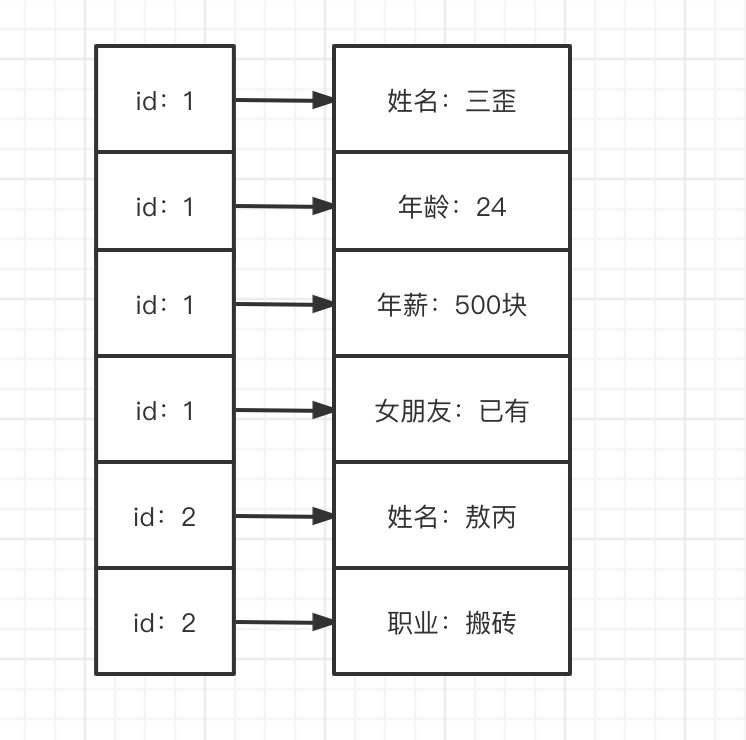
可以發現,列式存儲就是把每列抽出來,然後關聯上ID,實際上是用Key-Value結構保存的。這樣的優點在於,當表格中有空缺時,可以充分利用存儲空間。
對HBase來說,一行數據由一個行鍵(RowKey)和一個或多個相關的列以及它的值所組成。列的組成都是靈活的,行與行之間的列不需要相同。行鍵(RowKey)就是SSTable的key。
在HBase裡邊,先有列族(也叫“列簇”,Column Family),後有列。列族將一列或者多列組織在一起,HBase的每一個列都必須屬於某個列族。HBase的列都得歸屬到列族中,如圖所示:
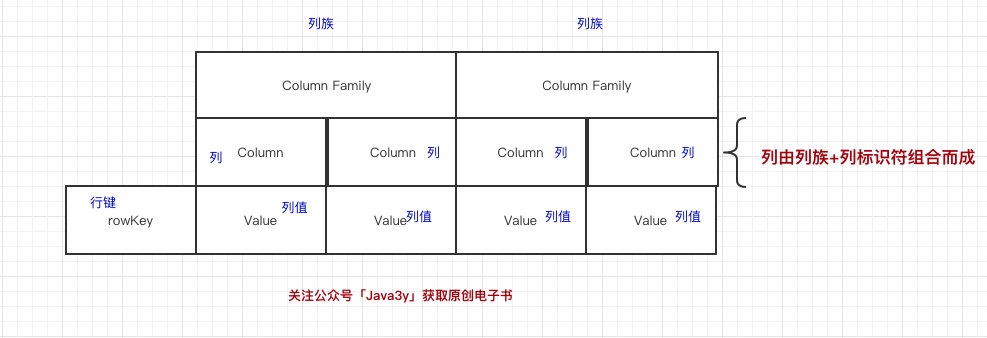
數據寫到HBase的時候都會被記錄一個時間戳,這個時間戳被我們當做一個版本。比如說,我們修改或者刪除某一條的時候,本質上是往裡邊新增一條數據,記錄的版本加一了而已。如圖所示:
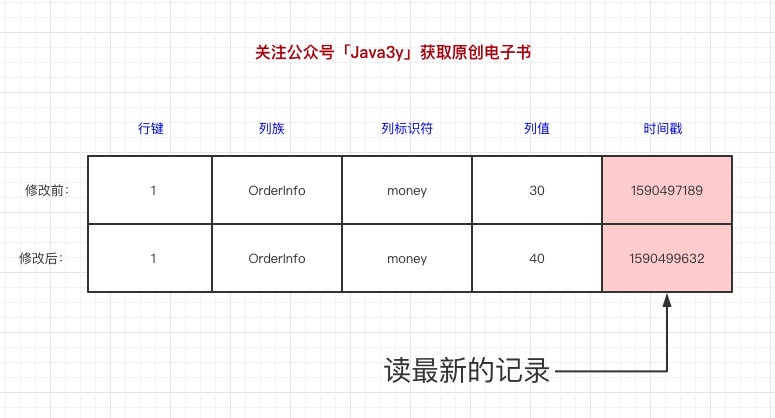
被更新和刪除的數據不會直接從磁碟上刪除,而是為數據添加一個刪除標記,查找時會跳過被刪除的鍵,DBA運維會定期刪除被標記刪除的數據。因此,如果存在頻繁覆蓋刪除需要提前向運維報備以免影響資料庫性能。
三、HBase的使用
1、HBase的讀寫
HBase提供了多種模式、多種語言的訪問介面。目前常用的包括Native Java API,Thrift和MapReduce模式。
(1)Java API是HBase提供的原生介面,具備完善的客戶端處理邏輯,直接與HBase Server進行通信,效率最高,但受限於語言限制;
(2)Thrift不受語言限制,但會占用額外的網路帶寬和處理時間;
(3)HBase還支持了MapReduce,可以通過編寫MapReduce任務進行批量數據操作。
使用GoLang和PHP語言搭建的項目顯然得用Thrift介面。
常用的HBase的數據操作get、scan和put三種。
(1)get實現隨機讀取功能,根據指定RowKey獲取惟一一條記錄。
(2)scan提供批量查詢功能,按照指定的條件獲取一批記錄。通過指定起始和中止的key,即可獲取所有包含在內的key對應的數據。可以通過setStartRow與setEndRow來限定範圍,也可以通過setFilter方法添加過濾器,這也是分頁、多條件查詢的基礎,用setCaching和setBatch方法能提高速度。
(3)put實現寫入,如果要批量導入大規模數據,還可以採用bulkimport的方式。
2、行鍵(RowKey)設計
Rowkey相當於HBase中數據的主鍵。HBase中的數據是按照RowKey的ASCII字典順序進行全局排序。可以使相關行彼此靠近存儲。如果Rowkey設計不當會引發熱點問題,即客戶端大量的讀寫請求都集中在一個或幾個節點上。從而導致性能下降。為防止數據寫入時出現熱點,數據被寫入時應寫入集群中的多個區域,而不是一次寫入一個區域(Hregion)。
設計原則:
1、唯一原則,要保證Rowkey的唯一性。若HBase中同一表插入相同Rowkey,則原先的數據會被覆蓋掉。設計Rowkey的時候,要充分利用這個排序的特點,將經常讀取的數據存儲到一塊,將最近可能會被訪問的數據放到一塊。
2、長度原則。Rowkey長度越短越好,一般不要超過16位元組。因為RowKey是一個二進位碼流,可以是任意字元串,最大長度64KB,實際應用中一般為10-100位元組,以byte[]形式保存。如果RowKey過長比如500個位元組,1000萬列數據僅RowKey就要占用5GB空間,非常影響HFile的存儲效率。
3、散列原則。用時間戳作為Rowkey的首碼會導致大量數據堆積在一個區域進而導致熱點問題。如果Rowkey是按時間戳的方式遞增,不要將時間放在二進位碼的前面,建議將Rowkey的高位作為散列欄位,低位放時間欄位。
3、列族(Column Family)的設計
設計原則:
1、列族的名稱儘可能短,甚至可以是一個字元。例如,“d”表示數據/預設值。
2、HBase當前不能很好地處理超過兩個或三個列族的數據,因此請保持列族的數量較少。最好使用一個列族。僅在數據訪問通常是列範圍的情況下才引入第二和第三列族。即,一次只查詢一個列族,通常不會查詢兩個列族。
3、將相同IO特性的列放入同一列族。
4、多個列族中的數據(行數)分佈大致均勻。
5、對於臨時性的列族可以設置失效時間。一旦達到到期時間,HBase將自動刪除行。
4、HBase Shell的安裝和使用
HBase自帶的操作工具只有HBase Shell這一命令行終端。通過HBase Shell工具,可以互動式地進行數據管理,包括插入數據、刪除數據等。雖然也有一些第三方圖形界面客戶端支持HBase,如DBeaver、BigInsights、HbaseGUI,但系統部的HBase只支持HBase Shell。
安裝HBase Shell需要先挑選一臺用於安裝的虛擬機,為該虛擬機安裝Java環境。之後在系統部奇麟大數據的客戶端管理頁面選擇“添加客戶端賬號”,申請為該虛擬機添加項目賬號。申請通過後勾選機器,單擊“部署Hadoop環境”在該機器上安裝HBase Shell。
安裝成功後,到虛擬機上使用sudo -iu命令先切換到項目賬號。然後切換到目錄cd $HBASE_HOME/bin,運行hbase shell,即可進入HBase Shell程式。
這裡列出幾個常用的HBase Shell命令:
| 名稱 | 命令表達式 |
| 查看存在哪些表 | list |
| 添加數據 | put '表名稱', '行鍵', '列族 : 列名', '值' |
| 查看一行數據 | get '表名稱', '行鍵' |
| 查看指定列族的一行數據 | get '表名稱', '行鍵', '列族' |
| 查看指定列族及列名的數據 | get '表名稱', '行鍵', '列族 : 列名', |
| 查看表中的數據總量 | count '表名' |
| 刪除一個單元格的數據 | delete '表名' ,'行鍵' , '列族 : 列名' |
| 刪除一行所有數據 | delete '表名' ,'行鍵' |
| 查看表的所有數據 | scan '表名'。註意,一般不應直接使用scan掃描整個表的海量數據。 |
| 查看一列數據 | scan '表名' , '列族 : 列名' |
| 查看幫助信息 | help |
5、MongoDB數據遷移HBase
使用kettle等工具可以把MongoDB資料庫遷移到HBase。也可以使用MapReduce處理,速度遠快於Java API和Thrift。
參考文獻:
胡爭,範欣欣.HBase原理與實踐M.北京:機械工業出版社,2019
O’Neil, P., Cheng, E., Gawlick, D., & O’Neil, E. (1996). The log-structured merge-tree (LSM-tree). Acta Informatica, 33(4), 351-385.

