
最近需要在計算大文件的 MD5 值時顯示進度,於是我寫瞭如下的代碼: ``` cs public long Length {get; private set; } public long Position { get; private set; } public async Task Compute ...
最*需要在計算大文件的 MD5 值時顯示進度,於是我寫瞭如下的代碼:
public long Length {get; private set; }
public long Position { get; private set; }
public async Task ComputeMD5Async(string file, CancellationToken cancellationToken)
{
using var fs = File.OpenRead(file);
Length = fs.Length;
var task = MD5.HashDataAsync(fs, cancellationToken);
var timer = new PeriodicTimer(TimeSpan.FromMilliseconds(10));
while (await timer.WaitForNextTickAsync(cancellationToken))
{
Position = fs.Position;
if (task.IsCompleted)
{
break;
}
}
}
運行的時候發現不對勁兒了,我的校驗速度只能跑到 350MB/s,而別人的卻能跑到 500MB/s,相同的設備怎麼差距有這麼大?帶這個疑問我去看了看別人的源碼,發現是這麼寫的:
protected long _progressPerFileSizeCurrent;
protected byte[] CheckHash(Stream stream, HashAlgorithm hashProvider, CancellationToken token)
{
byte[] buffer = new byte[1 << 20];
int read;
while ((read = stream.Read(buffer)) > 0)
{
token.ThrowIfCancellationRequested();
hashProvider.TransformBlock(buffer, 0, read, buffer, 0);
_progressPerFileSizeCurrent += read;
}
hashProvider.TransformFinalBlock(buffer, 0, read);
return hashProvider.Hash;
}
這裡使用了 HashAlgorithm.TransformBlock 方法,它能計算輸入位元組數組指定區域的哈希值,並將中間結果暫時存儲起來,最後再調用 HashAlgorithm.TransformFinalBlock 結束計算。上述代碼中緩衝區 buffer 大小是 1MB,我敏銳地察覺到 MD5 計算速度可能與這個值有關,接著我又去翻了翻 MD5.HashDataAsync 的源碼。
// System.Security.Cryptography.LiteHashProvider
private static async ValueTask<int> ProcessStreamAsync<T>(T hash, Stream source, Memory<byte> destination, CancellationToken cancellationToken) where T : ILiteHash
{
using (hash)
{
byte[] rented = CryptoPool.Rent(4096);
int maxRead = 0;
int read;
try
{
while ((read = await source.ReadAsync(rented, cancellationToken).ConfigureAwait(false)) > 0)
{
maxRead = Math.Max(maxRead, read);
hash.Append(rented.AsSpan(0, read));
}
return hash.Finalize(destination.Span);
}
finally
{
CryptoPool.Return(rented, clearSize: maxRead);
}
}
}
源碼中最關鍵的是上面這部分,緩衝區 rented 設置為 4KB,與 1MB 相差甚遠,原因有可能就在這裡。
為了找到最佳的緩衝區值,我跑了一大堆 BenchMark,覆蓋了從 32B 到 64MB 的範圍。沒什麼技術含量,但工作量實在不小。測試使用 1GB 的文件,基準測試是對 1GB 大小的數組直接調用 MD5.HashData,實際的測試代碼如下,分別使用記憶體流 MemoryStream 和文件流 FileStream 作為入參 Stream,對比無硬碟 IO 和實際讀取文件的速度。
public async Task HashDataAsync(Stream stream)
{
var hash = MD5.Create();
byte[] buffer = new byte[1 << size];
int read = 0;
while ((read = await stream.ReadAsync(buffer)) != 0)
{
hash.TransformBlock(buffer, 0, read, buffer, 0);
}
hash.TransformFinalBlock(buffer, 0, read);
if (!(hash.Hash?.SequenceEqual(fileHash) ?? false))
{
throw new Exception("Compute error");
}
}
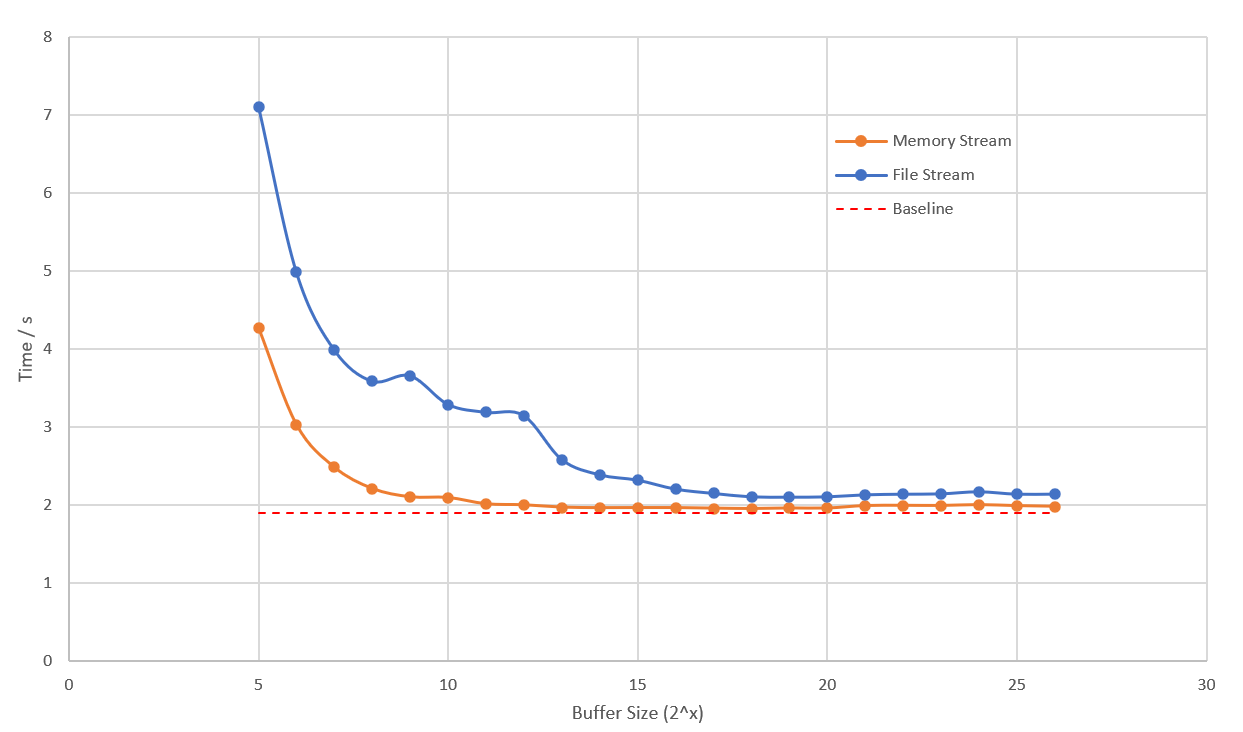
基準測試是那條紅色虛線,是所有測試結果中最快的。橙色的曲線是 MemoryStream 的測試結果,在緩存塊的 2KB 處降到了一個較低的位置,後續耗時無明顯下降。這證明 .NET 源碼中使用 4KB 大小的塊是一個合理的選擇,但是它沒有考慮文件 IO 的延遲影響。藍色的曲線是最接*顯示的測試結果,緩存塊大於 32KB 時的測試結果才接*於*穩。
總結一下,MD5.HashDataAsync 過慢的原因是文件 IO 影響到了計算速度。使用文件流進行 MD5 校驗的時候,緩衝區至少需要 64KB,總體速度才不會被文件 IO 拖後腿。

