
# JVM運行時數據區 ## 簡介 JVM運行時數據區包括:JVM棧(虛擬機棧),堆,方法區,本地方法棧,PC寄存器。大概的劃分就是棧和堆,以及一些其他的結構。重點在JVM棧,堆,方法區。JVM規範指出:方法區在邏輯上屬於堆,但是實際的具體的JVM中並不屬於堆的一部分。 在JVM棧中會發生GC和Er ...
JVM運行時數據區
簡介
JVM運行時數據區包括:JVM棧(虛擬機棧),堆,方法區,本地方法棧,PC寄存器。大概的劃分就是棧和堆,以及一些其他的結構。重點在JVM棧,堆,方法區。JVM規範指出:方法區在邏輯上屬於堆,但是實際的具體的JVM中並不屬於堆的一部分。
在JVM棧中會發生GC和Error,但是在其他的記憶體區域中,可能沒有GC或者Error。
有些區域的生命周期是跟隨著虛擬機的,當虛擬機被關閉時,這部分的記憶體也被釋放出來。有些是跟隨線程的,當線程結束時,這部分的記憶體也被釋放出來。
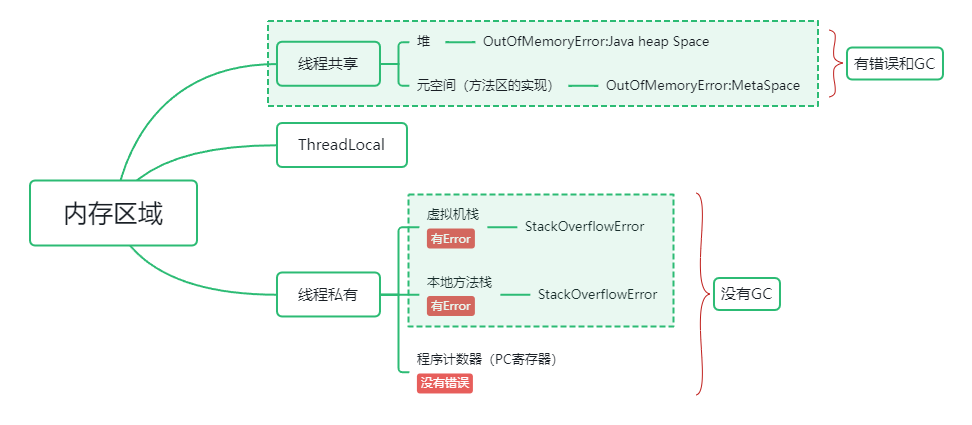
下圖展示了哪些區域是線程共用和線程私有的。
線程私有的:PC寄存器,棧,本地方法棧
線程間共用的:堆,堆外記憶體(永久代或元空間,代碼緩存)
每個JVM對應Java的RunTime類的對象,RunTime實例在每個JVM中只有一個。
運行時數據區的結構圖解:
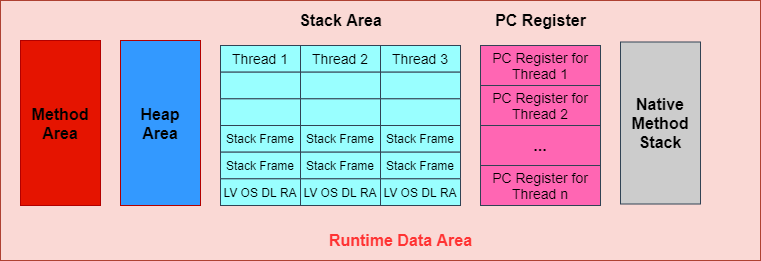
PC寄存器(程式計數器)
簡介
類似與電腦組成原理中提及的CPU的PC寄存器,但是CPU的PC寄存器是有實際硬體的,但是JVM的PC寄存器沒有實際的硬體部分,這個是每個線程私有的。
JVM的PC寄存器只是一塊很小很小的記憶體區域。
作用
- PC寄存器用來存儲指向下一條指令的地址,也就是即將執行的指令,由執行引擎讀取下一條指令,程式的分支,迴圈,跳轉,異常處理,線程恢復等基礎功能都需要PC寄存去來完成。
- PC寄存器是唯一一個在JVM規範中沒有規定任何OutOfMemoryError情況的區域。
常見問題
為什麼需要PC寄存器
- 因為CPU需要不停地切換線程,當切換回來的時候就需要知道該線程從哪裡開始繼續執行。
- 如果沒有這個機制,那麼切換線程應當不容易。有了這個機制之後,只需要讀取PC寄存去的指令就知道該執行哪一個指令,實現起來比較容易。
為什麼PC寄存器是線程私有的
因為需要準確記錄各個線程正在執行的當前的位元組碼指令,必須是線程私有的,如果不是線程私有的,意味著任意線程可以隨意更改任意線程的位元組碼指令,這會導致程式的錯誤。
JVM棧(虛擬機棧) 重點
簡介
棧是運行時的單位,堆是存儲的單位,既:棧存放著程式如何執行的問題,堆解決的時候數據存儲的問題。
具體特性:
- JVM棧是每個線程私有的。
- 每創建一個線程就會創建一個虛擬機棧,虛擬機棧的基本單位是棧幀(Stack Frame),棧幀對應著方法調用。
- 生命周期和線程一致。
- 沒有GC,有錯誤(下麵提及)。
- 訪問速度僅次於PC寄存器
- JVM對虛擬機棧的操作只有兩個
- 方法執行,伴隨著進棧
- 方法執行結束後,伴隨著出棧
JVM規範中允許JVM棧的大小是動態的或者固定的,以下是JVM棧中會遇到的Error
-
JVM棧大小為動態,遇到以下情況會拋出OutOfMemoryError異常
- 嘗試拓展時不能申請到足夠的記憶體
- 創建新線程時沒有足夠的記憶體創建對應的JVM棧
-
大小固定,遇到以下情況會拋出StackOverflow異常
- 線程申請的JVM棧的容量超過虛擬機所允許的最大容量
JVM棧的作用
保存著方法的局部變數,部分結果,並參與方法的調用與返回。
JVM棧的存儲單位
JVM棧存儲什麼
-
每個線程都有自己的棧,棧的數據都是以棧幀(Stack Frame)的格式存在。
-
每個方法都對應一個棧幀
-
棧幀時一個記憶體塊,是數據的集合,保存著方法運行中的各種數據信息。
棧運行原理
在一個運行中的線程,一個時間點上只有一個活動的棧幀,這個棧幀被稱為當前棧幀,對應的方法是當前方法,對應的類是當前類。
執行引擎運行的所有的位元組碼指令只針對當前棧幀來操作,如果當前棧幀調用了其他方法,那麼對應的棧幀也會被創建出來,進入棧中,成為當前棧幀。
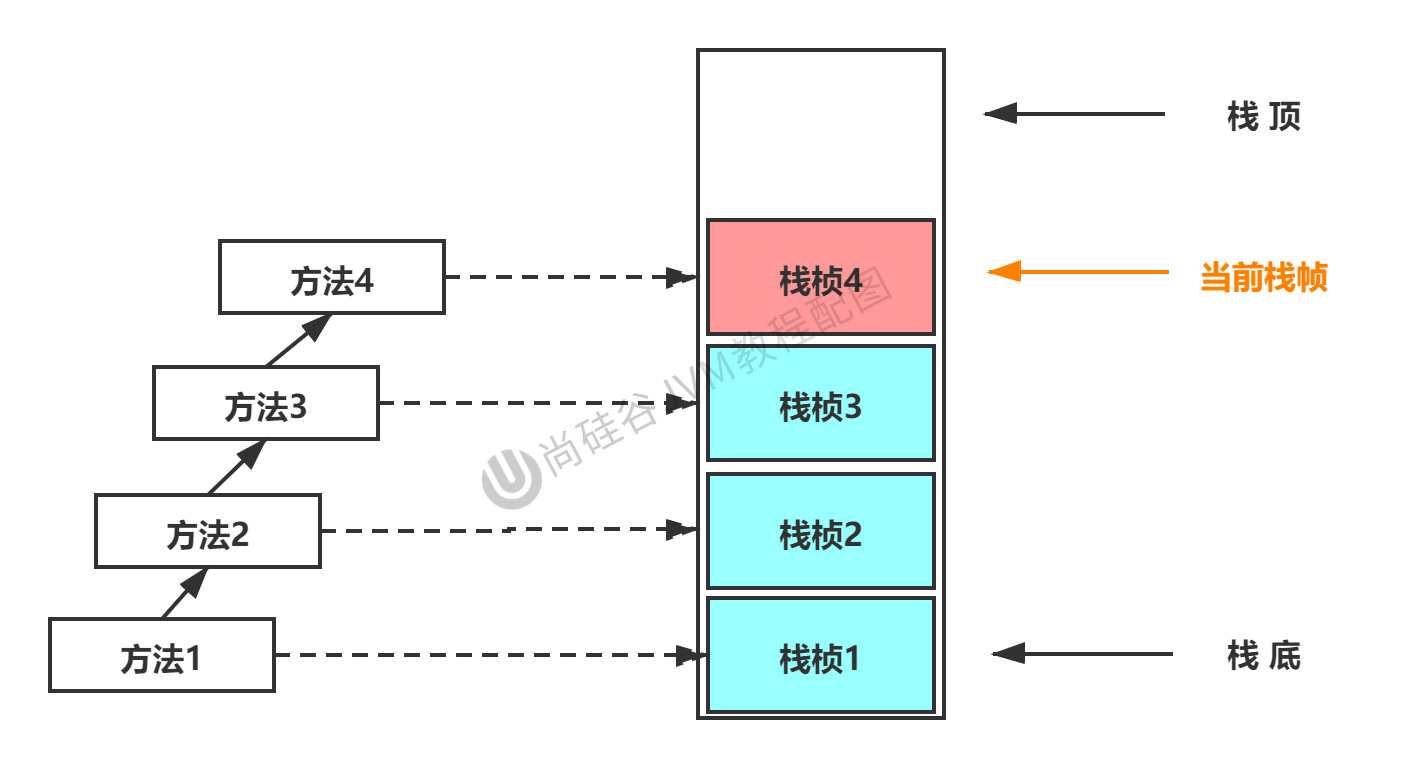
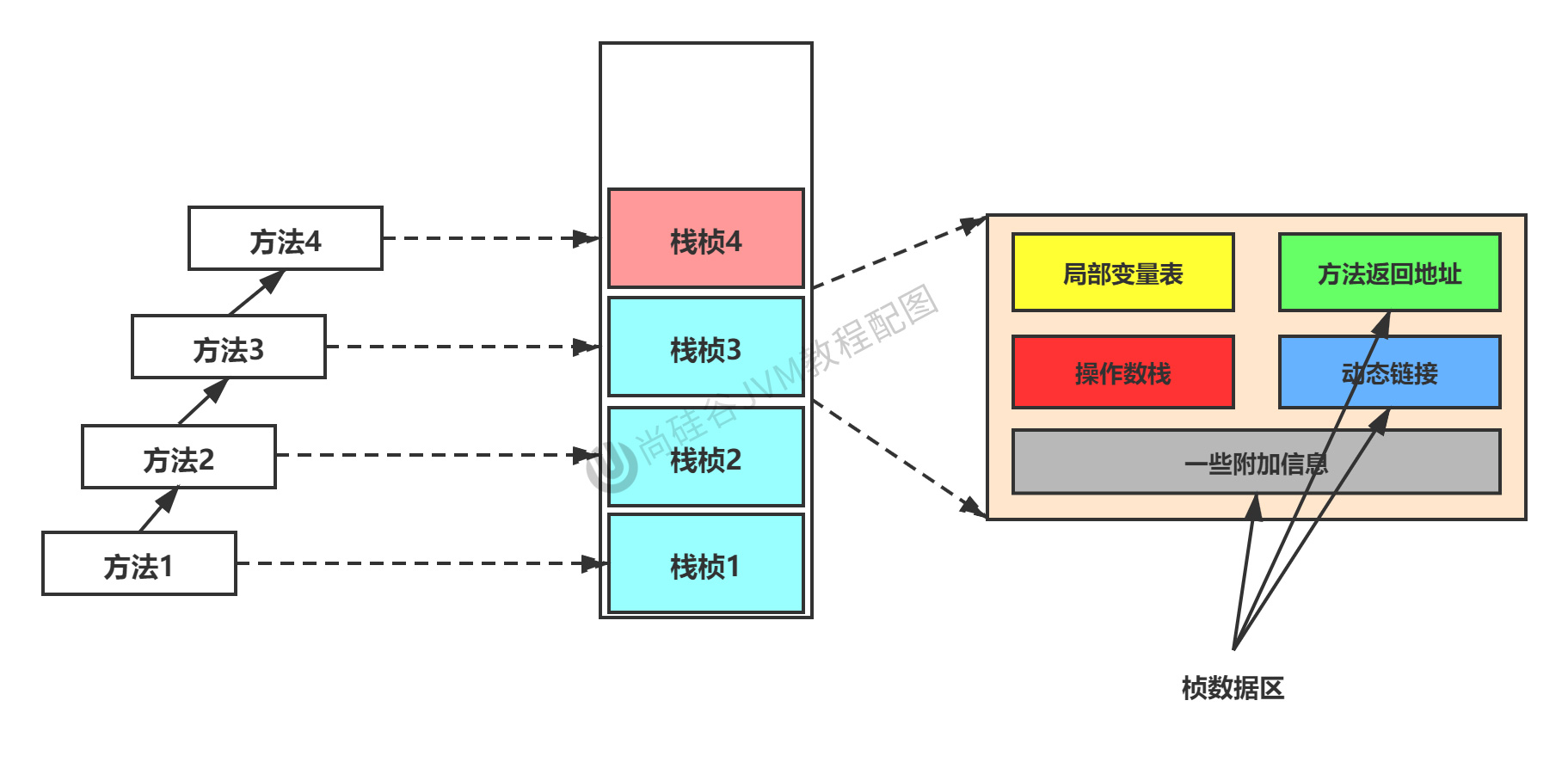
棧幀的內部結構
存儲著以下信息
- 局部變數表 Local Variables(重要)
- 操作數棧 Operand Stacks(重要)
- 方法返回地址
- 動態連接 Dynamic Linking
- 其他信息
局部變數表Local Variables
- 被稱為局部變數數組或本地變數表。
- 是一個數字數組,主要存儲方法參數和定義在方法內的局部變數,這些數據類型包括基本數據類型引用,對象引用,以及返回地址類型。
- 沒有安全問題
- 局部變數表的大小是在編譯期確定下來的,並且保存在方法的Code屬性的maximum local variables。運行期間不會改變局部變數表的大小。
局部變數表的基本單位是Slot(插槽),32位以內的類型占用一個Slot,
64位的類型占用兩個Slot。只有long和double類型占用兩個插槽,其餘都是占用一個插槽,非數值的類型,如boolean,則轉為int後再存儲。
形參和方法內局部變數會按照順序被覆制到每一個Slot上,但是有一個變數特殊,就是this。
如果是非靜態方法和構造器,第一個變數將是this,如果是靜態方法,局部變數表沒有this這個變數。
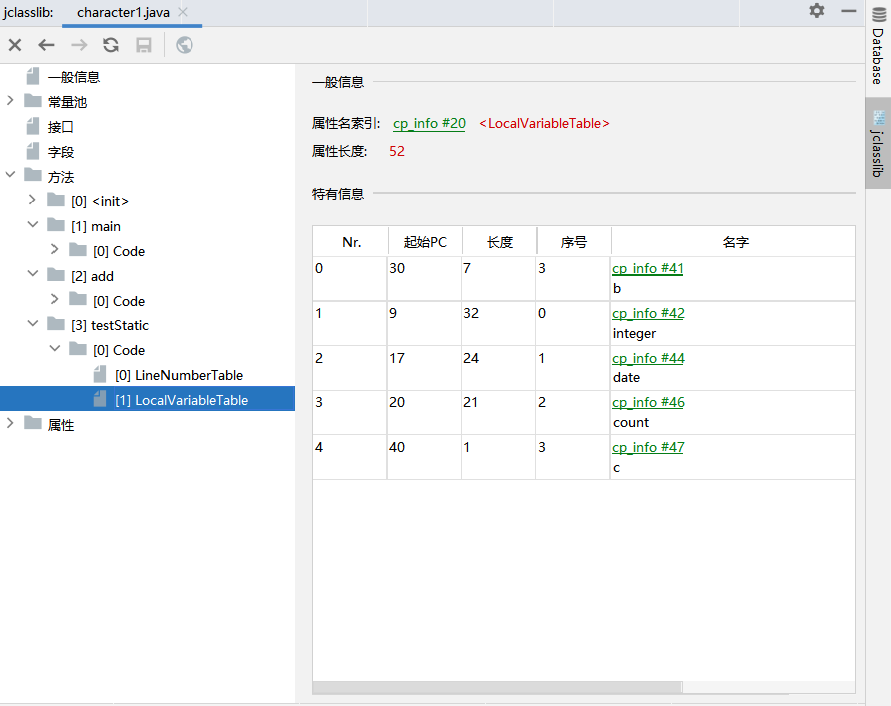
可以使用jclasslib軟體或idea中的jclasslib插件查看具體的局部變數表,如下圖所示。
局部變數表的具體細節
-
序號:該變數在保存在第幾個slot中,從0號開始
-
起始PC:位元組碼的第幾行開始
-
長度:變數的有效範圍的長度
-
名字:對應的變數的名字
比如三號變數b,起始PC是30,長度是7,意味著變數b的作用範圍是30-37,查詢LineNumberTable可知,第30-37號指令對應的行號為42-44。
對應的源碼
36 public static void testStatic() {
37 Integer integer = new Integer(1);
38 Date date = new Date();
39 int count = 18;
40 System.out.println(count);
41 {
42 int b = 10;
43 System.out.println(b);
44 }
45 int c = 8;
46 }
//下表為對應的LineNumberTable
//下表表明的是指令所對應的代碼行號,對應關係為:起始PC ------行號-1
//
Nr. 起始PC 行號
0 0 37
1 9 38
2 17 39
3 20 40
4 27 42
5 30 43
6 37 45
7 40 46
對應的位元組碼指令
0 new #10 <java/lang/Integer>
3 dup
4 iconst_1
5 invokespecial #11 <java/lang/Integer.<init> : (I)V>
8 astore_0
9 new #12 <java/util/Date>
12 dup
13 invokespecial #13 <java/util/Date.<init> : ()V>
16 astore_1
17 bipush 18
19 istore_2
20 getstatic #2 <java/lang/System.out : Ljava/io/PrintStream;>
23 iload_2
24 invokevirtual #9 <java/io/PrintStream.println : (I)V>
27 bipush 10
29 istore_3
30 getstatic #2 <java/lang/System.out : Ljava/io/PrintStream;>
33 iload_3
34 invokevirtual #9 <java/io/PrintStream.println : (I)V>
37 bipush 8
39 istore_3
40 return
Slot的重覆利用
棧幀中的局部變數表中的slot是可以復用的,如果一個局部變數過了其作用域,那麼在其作用域之後的聲明的新變數就有可能服用過期局部兩邊的槽位,達到節省資源的目的。
上面的例子剛好是一個slot重覆利用的例子,變數b和c都是存放在序號為3的slot上,正是因為在b結束後有一個新的變數c聲明出來。
補充說明
在棧幀中,與調優最密切相關的部分就是局部變數表。
局部變數表的變數是重要的垃圾回收根節點,只要被局部變數表中直接或間接引用的對象都不會被回收。
操作數棧
操作數棧也位於棧幀當中,屬於線程私有的,也被稱為表達式棧,Expression Stack。
作用
- 在方法執行中,根據位元組碼指令,往操作數棧中寫入數據或提取數據,也就是入棧和出棧。
- 主要保存著計算過程的中間結果,也是計算過程中便變數的臨時存儲空間。
說明
-
當一個方法剛開始執行時,新的棧幀會被創建出來,這個棧幀的操作數棧時空的 。
-
因為操作數棧是用數組實現的,所以每一個操作數棧都會有一個明確的數值表示其所需的最大深度,保存在方法的Code屬性中,為max_stack的值。
-
操作數棧中元素的數據類型必須與位元組碼指令的序列嚴格匹配,這由編譯器在編譯器期間進行險證,同時在類載入過程中的類檢驗階段的數據流分析階段要再次驗證
-
和棧幀一樣,一個棧的單位深度是32位。
-
操作數棧的任意元素可以是任意的Java數據類型。
-
如果調用方法有返回值的話,返回值會被壓入當前棧幀的操作數棧中
棧頂緩存技術
由於操作數是存儲在記憶體中的,因此頻繁地執行記憶體讀/寫操作必然會影響執行速度。為瞭解決這個問題,Hotspot JVM的設計者們提出了棧頂緩存(ToS,Top-of-Stack Cashing)技術,將棧頂元素全部緩存 在物理CPU的寄存器中,以此降低對記憶體的讀/寫次數,提升執行引擎的執行效率。
動態鏈接(或指向運行時常量池的方法引用)
介紹
也是棧幀的一部分。每一個棧幀內部都包含一個指向運行時常量池中該棧幀所屬方法的引用。包含這個引用的目的就是為了支持當前方法的代碼能夠實現動態鏈接(Dynamic Linking)。
比如:invokedynamic指令在Java源文件被編譯到位元組碼文件中時,所有的變數和方法引用都作為符號引用(Symbolic Reference)保存在class文件的常量池裡。
比如:描述一個方法調用了另外的其他方法時,就是通過常量池中指向方法的符號引用來表示的。
動態鏈接的作用
就是為了將符號引用轉換為調用方法的直接引用。
符號引用
可以看作是一個字元串,內容是這個方法的方法頭,拿上邊局部變數表的具體細節的例子來看,常量池如下方代碼塊所示,
Constant pool:
#1 = Methodref #15.#50 // java/lang/Object."<init>":()V
#2 = Fieldref #51.#52 // java/lang/System.out:Ljava/io/PrintStream;
#3 = String #53 // aaaa
#4 = Methodref #54.#55 // java/io/PrintStream.println:(Ljava/lang/String;)V
#5 = Class #56 // java/lang/Exception
#6 = Methodref #54.#57 // java/io/PrintStream.println:(Ljava/lang/Object;)V
省略剩下的。。。。。。。。
動態鏈接的理解
可以看到有一些是帶有Methodref 例如第五行的 #4 = Methodref,帶有Methodref 就是符號引用,但是這些只是一個字元串,並不能直接運行, 所以就需要使用符號引用來將靜態的字元串轉為可以運行的方法的引用,這些可運行方法的引用保存在方法區的運行時常量池中。
舉例,有個方法a,對應的運行時常量池的地址為0x00a13,那麼就需要一個東西來將a和0x00a13對應起來,這個東西就是動態鏈接。
方法的調用
在JVM中,將符號引用轉換為調用方法的直接引用與方法的綁定機制相關。
-
靜態鏈接:
- 當一個位元組碼文件被裝載進JVM內部時,如果被調用的目標方法在編譯期可知,且運行期保持不變時。這種情況下將調用方法的符號引用轉換為直接引用的過程稱之為靜態鏈接。
-
動態鏈接:
- 如果被調用的方法在編譯期無法被確定下來,也就是說,只能夠在程式運行期將調用方法的符號引用轉換為直接引用,由於這種引用轉換過程具備動態性,因此也就被稱之為動態鏈接。
對應的方法的綁定機製為:早期綁定(Early Binding)和晚期綁定(Late Binding)。綁定是一個欄位、方法或者類在符號引用被替換為直接引用的過程,這僅僅發生一次。
-
早期綁定:
- 早期綁定就是指被調用的目標方法如果在編譯期可知,且運行期保持不變時,即可將這個方法與所屬的類型進行綁定,這樣一來,由於明確了被調用的目標方法究竟是哪一個,因此也就可以使用靜態鏈接的方式將符號引用轉換為直接引用。
-
晚期綁定:
- 如果被調用的方法在編譯期無法被確定下來,只能夠在程式運行期根據實際的類型綁定相關的方法,這種綁定方式也就被稱之為晚期綁定。
虛方法和非虛方法
非虛方法:
-
如果方法在編譯期就確定了具體的調用版本,這個版本在運行時是不可變的。這樣的方法稱為非虛方法。
-
靜態方法、私有方法、final方法、實例構造器、父類方法都是非虛方法。
其他方法稱為虛方法,例如實例方法。
方法調用指令:
普通調用指令:
- invokestatic:調用靜態方法,解析階段確定唯一方法版本
- invokespecial:調用<init>方法、私有及父類方法,解析階段確定唯一方法版本
- invokevirtual:調用所有虛方法
- invokeinterface:調用介面方法
動態調用指令:
5. invokedynamic:動態解析出需要調用的方法,然後執行。
前四條指令固化在虛擬機內部,方法的調用執行不可人為干預,而invokedynamic指令則支持由用戶確定方法版本。其中invokestatic指令和invokespecial指令調用的方法稱為非虛方法,其餘的(final修飾的除外)稱為虛方法。
代碼中使用lambda表達式對應到位元組碼指令就會使用到invokedynamic進行調用。
動態返回地址(return address)
-
存放該調用方法的pc寄存器的值。例子:假如方法A調用方法B,動態返回地址就是調用方法B指令的下一條指令,調用方法B指令是第五條指令,那麼動態返回地址應該是第六條指令。
-
一個方法的結束,有兩種方式
-
- 遇到return,將返回值傳遞給上層方法調用者,簡稱正常完成出口(返回指令包括ireturn(返回值為boolean,byte,char,short,int),lreturn,freturn,dreturn,以及areturn,還有return 返回為void、實例初始化方法,類和介面的初始化方法)
- 異常完成出口,即碰到了異常,並且沒有在方法內進行處理,就會退出方法。方法在執行過程總拋出異常時的異常處理,儲存在一個異常處理表,方法在發生異常時候找到處理異常的代碼
-
無論通過哪種方式退出,在方法退出後都返回到該方法被調用的位置。方法正常退出時,調用者的pc計數器的值作為返回地址,即調用該方法的指令的下一條指令的地址,而通過異常退出的,返回地址是要通過異常表來確定,棧幀中一般不會保存這部分信息
-
本質上,方法的退出就是當前棧幀出棧的過程,此時,需要恢覆上層方法的數據區等信息,讓調用者方法繼續執行下去
-
正常完成出口和異常完成出口的區別在於,通過異常完成出口推出的不會給他的上層調用者產生任何的返回值。
本地方法棧
簡介
本地方法是指使用了native關鍵字修飾的方法,沒有方法體,是為了對接其他的編程語言。
普通的方法都是在JVM棧中進行管理,但是本地方法是在本地方法棧中進行管理。
- 當某個線程調用一個本地方法時,它就進入了一個全新的並且不再受虛擬機限制的世界。它和虛擬機擁有同樣的許可權。
- 本地方法可以通過本地方法介面來訪問虛擬機內部的運行時數據區。它甚至可以直接使用本地處理器中的寄存器
- 直接從本地記憶體的堆中分配任意數量的記憶體。
- 並不是所有的JVM都支持本地方法。因為Java虛擬機規範並沒有明確要求本地方法棧的使用語言、具體實現方式、數據結構等。如果JVM產品不打算支持native方法,也可以無需實現本地方法棧。
- 在Hotspot JVM中,直接將本地方法棧和虛擬機棧合二為一
堆(重點)
簡介
- 每個JVM中只有一個堆,也是JVM最大記憶體區域
- 堆大小可調節也可固定
- 在物理記憶體上可以不連續,但是邏輯上是連續的
- 所有的線程共用堆,但是也可以划出線程私有的緩衝區,稱為Thread Local Allocation Buffer,簡寫TLAB
- 《Java虛擬機規範》中對Java堆的描述是:所有的對象實例以及數組都應當在運行時分配在堆上。從實際使用角度看,數組和對象可能永遠不會存儲在棧上,因為棧幀中保存引用,這個引用指向對象或者數組在堆中的位置。
- 在方法結束後,堆中的對象不會馬上被移除,僅僅在垃圾收集的時候才會被移除。
- 堆,是GC(Garbage Collection,垃圾收集器)執行垃圾回收的重點 區域。
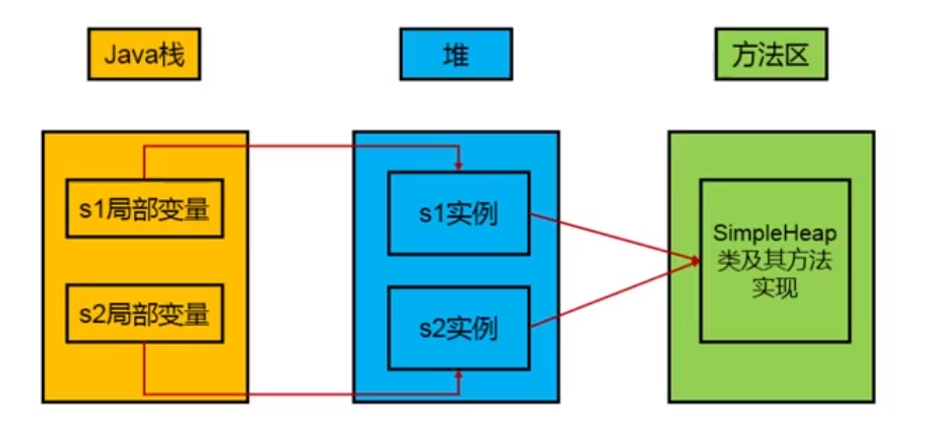
棧-堆-方法區三者聯繫如圖
堆的記憶體細分
Java7之前有三部分:新生代 Young Generation Space, 老年代 Old Generation Space ,永久代 Perment Space
Java8及其之後---新生代, 老年代,元空間 Meta Space
具體叫法:
新生代-新生區-年輕代
養老區-老年區-老年代
永久代-永久區
堆大小設置
Java堆區用於存儲Java對象實例,那麼堆的大小在JVM啟動時就已經設定好了,大家可以通過選項"—Xmx"和"—Xms"來進行設置。
“-Xms”用於表示堆區的起始記憶體,等價於-XX:InitialHeapSize
“-Xmx”則用於表示堆區的最大記憶體,等價於-XX:MaxHeapSize
一旦堆區中的記憶體大小超過“-Xmx”所指定的最大記憶體時,將會拋出OutOfMemoryError異常。
通常會將-Xms 和-Xmx兩個參數配置相同的值,其目的是為了能夠在java垃圾回收機制清理完堆區後不需要重新分隔計算堆區的大小,從而提高性能。
預設情況下,初始記憶體大小:物理電腦記憶體大小/64。最大記憶體大小:物理電腦記憶體大小/4
堆空間的內部細節
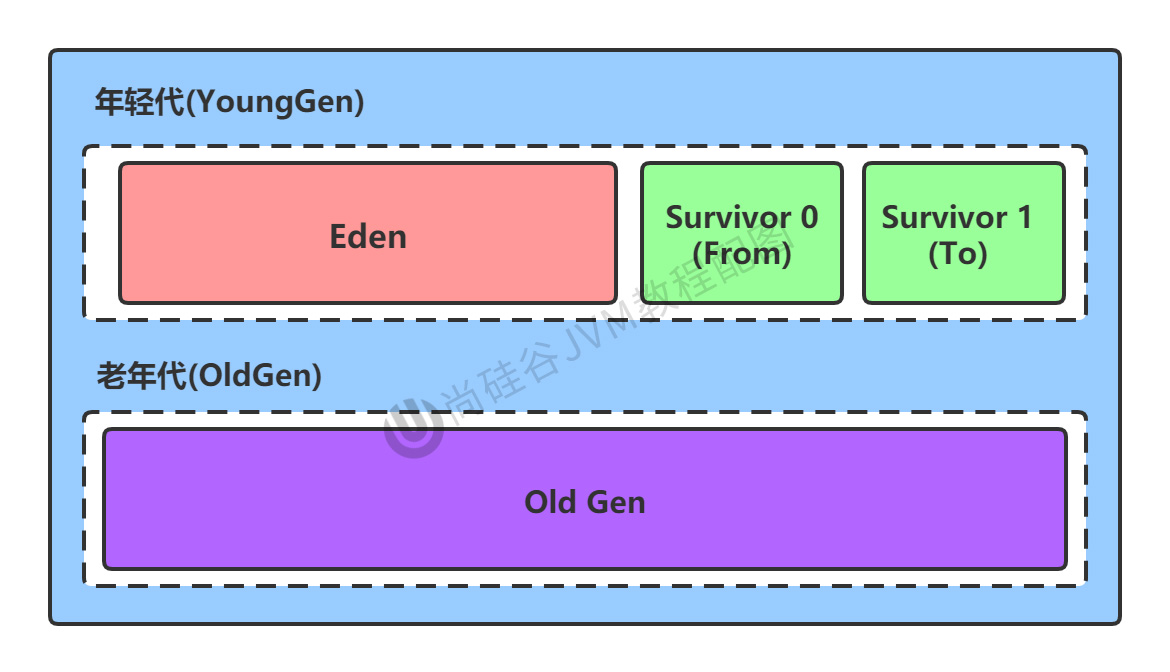
堆分為兩個代際區域,新生代和老年代,新生代和老年代的大小比例為1:2。
新生代中各個區域的記憶體比例為Eden:s0:s1為8:1:1。
註意的是這隻是JVM的預設比例,各個區域的比例和大小以及是否固定,都可以在VM Option中進行設置,但是大小會動態調整,所以需要手動設置參數,但一般不設置。
二者在邏輯上是連續的,但是實際記憶體中可以不連續。
新生代,新生代包括以下部分:
-
Eden區(伊甸園區)
-
Survivors0區(s0區)
-
Survivors1區(s1區)
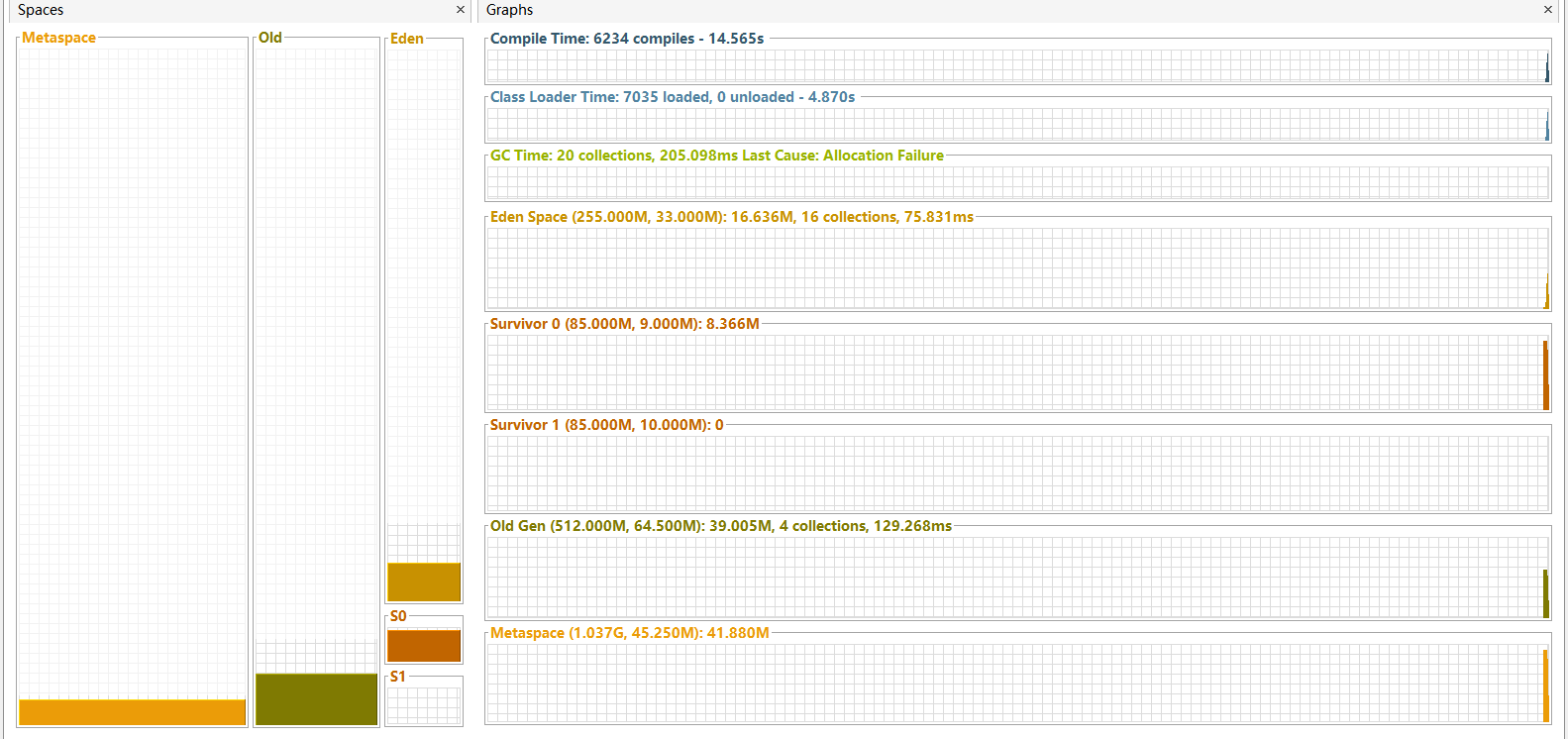
可以使用visualvm來查看JVM棧的具體情況
對象的分配細節
為新對象分配記憶體是一件非常嚴謹和複雜的任務,JVM的設計者們不僅需要考慮記憶體如何分配、在哪裡分配等問題,並且由於記憶體分配演算法與記憶體回收演算法密切相關,所以還需要考慮GC執行完記憶體回收後是否會在記憶體空間中產生記憶體碎片。
一般情況
- new的對象先放伊甸園區。此區有大小限制。
- 當伊甸園的空間填滿時,程式又需要創建對象,JVM的垃圾回收器將對伊甸園區進行垃圾回收(Minor GC),將伊甸園區中的不再被其他對象所引用的對象進行銷毀。再載入新的對象放到伊甸園區
- 然後將伊甸園中的剩餘對象移動到幸存者0區。
- 如果再次觸發垃圾回收,此時上次幸存下來的放到幸存者0區的,如果沒有回收,就會放到幸存者1區。
- 如果再次經歷垃圾回收,此時會重新放回幸存者0區,接著再去幸存者1區。6.啥時候能去養老區呢?可以設置次數。預設是15次。
特殊情況
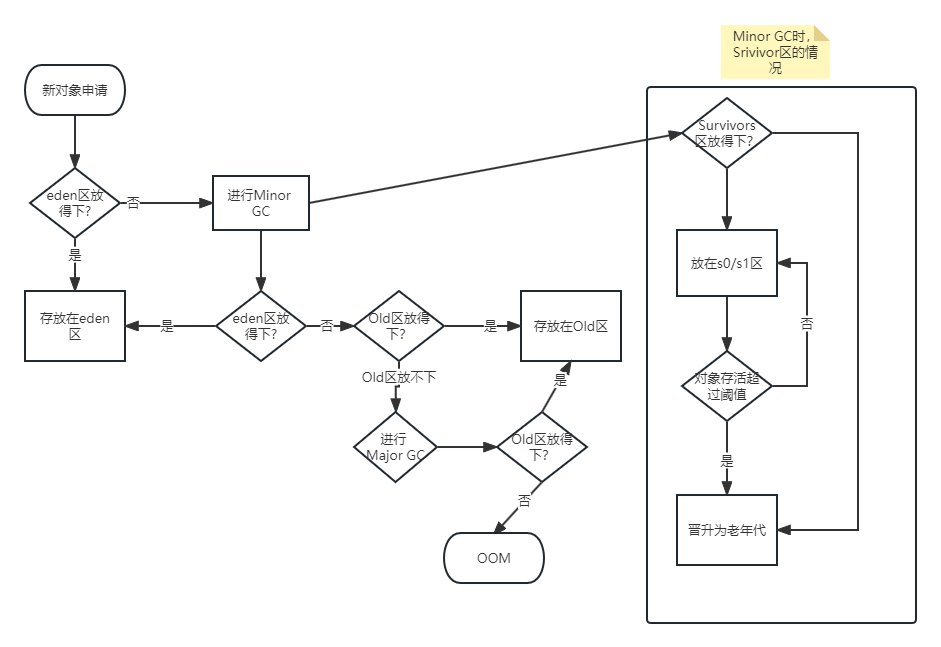
如圖所示,小總結:
- 對象大於Eden的存放順序:Eden->old,對象不大於Survivor為:Eden->Survivor->old
- 放不下時會進行GC,至於是哪種GC要看哪個區域大小不夠,如果是Eden區,進行Minor GC,Old區進行Major GC。
- Survivor區滿了不會自動觸發垃圾回收,只有在Eden區不夠用了,進行 Minor GC的時候,對Eden和Survivor進行回收。只有Eden區才能自動觸發Minor GC總結。
頻繁在新生代進行回收,較少在老年代回收,幾乎不在元空間回收。
堆為什麼要分代
研究發現,幾乎80%的對象的都是臨時對象。
為了優化GC性能,所以需要分代,將對象按照存活時間的不同進行劃分,那麼在進行垃圾回收的時候就可以重點關註存活時間短的區域了,如果沒有分代,那麼每次進行垃圾回收都會判斷全部對象是否為垃圾,這些判斷多了,性能也下降了。
TLAB
TLAB存在的原因
為了提高性能
解釋:
- 堆區是線程共用區域,任何線程都可以訪問到堆區中的共用數據
- 由於對象實例的創建在JVM中非常頻繁,因此在併發環境下從堆區中劃分記憶體空間是線程不安全的為避免多個線程操作同一地址,需要使用加鎖等機制,進而影響分配速度。
什麼是TLAB
從記憶體的角度來看,是一塊線程私有的緩衝區域,位於Eden區。
解釋:
-
從記憶體模型而不是垃圾收集的角度,對Eden區域繼續進行劃分,JVM為每個線程分配了一個私有緩存區域,它包含在Eden空間內。
-
多線程同時分配記憶體時,使用TLAB可以避免一系列的非線程安全問題,同時還能夠提升記憶體分配的吞吐量,因此我們可以將這種記憶體分配方式稱之為快速分配策略。
-
據我所知所有OpenJDK衍生出來的JVM都提供了TLAB的設計。
圖示
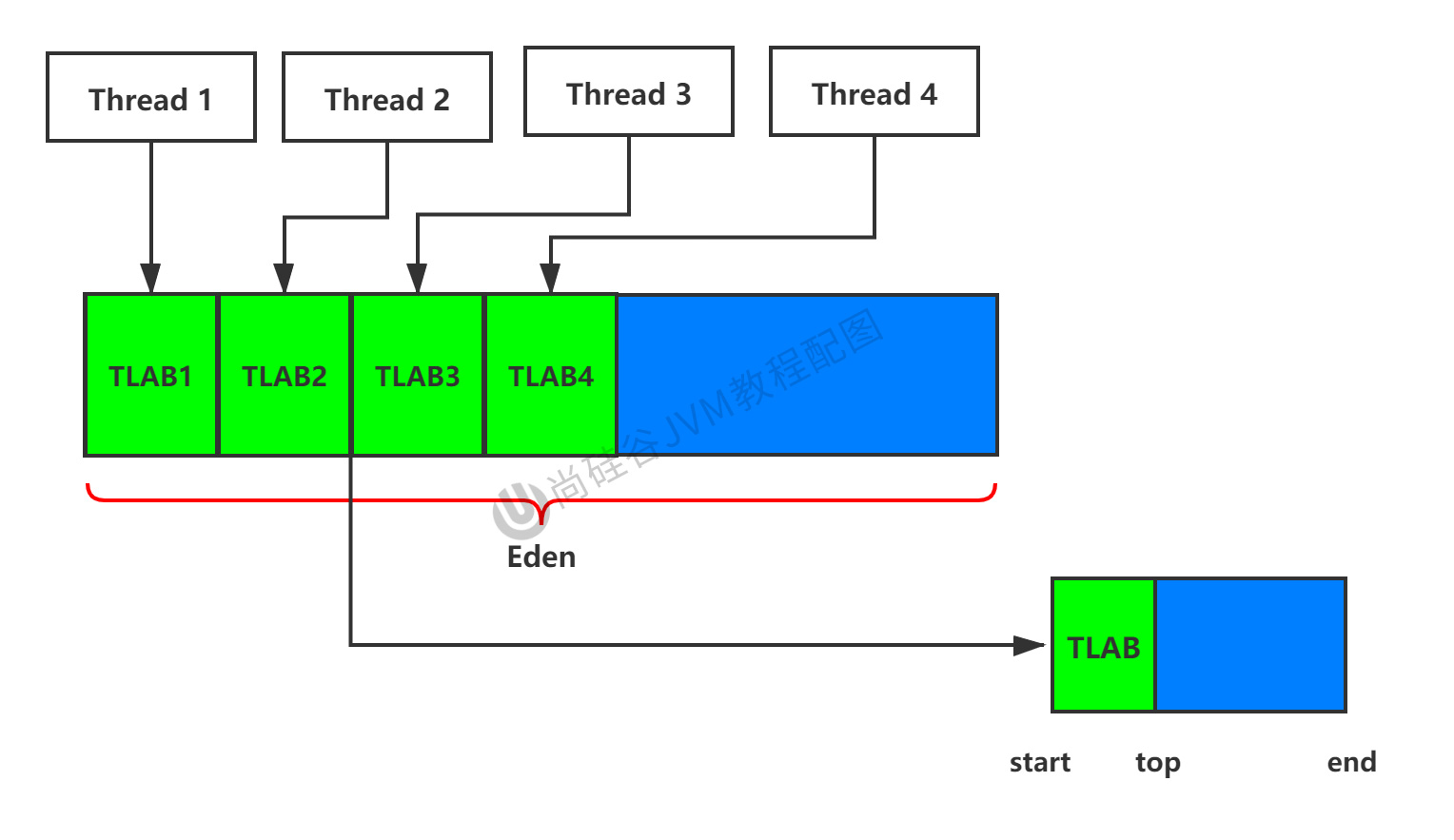
進一步說明
儘管不是所有的對象實例都能夠在TLAB中成功分配記憶體,但JVM確實是將TLAB作為記憶體分配的首選
在程式中,開發人員可以通過選項“-XXUseTLAB”設置是否開啟TLAB空間。
預設情況下,TLAB空間的記憶體非常小,僅占有整個Eden空間的1%,當然我們可以通過選項
“-XX:TLABWasteTargetPercent”設置TLAB空間所占用Eden空間的百 分比大小。
一旦對象在TLAB空間分配記憶體失敗時,JVM就會嘗試著通過使用加鎖機制確保數據操作的原子性,從而直接在Eden空間中分配記憶體。
JVM參數總結
官網說明
具體的參數
-XX:+PrintGCDetails
Enables printing of detailed messages at every GC. By default, this option is disabled.
列印每次GC的細節,預設關閉
-Xms:初始堆空間記憶體(預設為物理記憶體的1/64)
-Xmx:最大堆空間記憶體(預設為物理記憶體的1/4)
-Xmn:設置新生代的大小。(初始值及最大值)
-XX:NewRatio:配置新生代與老年代在堆結構的占比
-XX:SurvivorRatio:設置新生代中Eden和SO/S1空間的比例
-XX:MaxTenuringThreshold:設置新生代垃圾的最大年齡
其他說明
在JDK6之後,只要老年代的連續空間大於新生代對象總大小或者歷次晉升的平均大小就會進行Minor GC,否則就進行Full GC。
逃逸分析技術
概述
堆是否是對象分配的唯一選擇:是,但是有逃逸分析技術,但是HotSpot並沒有使用基於逃逸分析技術的代碼優化
如何將堆上的對象分配到棧,需要使用逃逸分析手段。
這是一種可以有效減少Java 程式中同步負載和記憶體堆分配壓力的演算法。
通過逃逸分析,Java Hotspot編譯器能夠分析出一個新的對象的引用的使用範圍從而決定是否要將這個對象分配到堆上。
逃逸分析的基本行為就是分析對象動態作用域:
- 當一個對象在方法中被定義後,對象只在方法內部使用,則認為沒有發生逃逸。
- 當一個對象在方法中被定義後,它被外部方法所引用,則認為發生逃逸。例如作為調用參數傳遞到其他地方中。
總結:能使用局部變數的就不要在方法外定義。
具體參數
-XX:+DoEscapeAnalysis 顯式開啟逃逸分析,在JDK6後預設開啟
-XX:+PrintEscapeAnalysis 查看逃逸分析的篩選結果。
基於逃逸分析技術的代碼優化
棧上分配
將堆分配轉化為棧分配。
JIT編譯器在編譯期間根據逃逸分析的結果,發現如果一個對象並沒有逃逸出方法的話,就可能被優化成棧上分配。分配完成後,繼續在調用棧內執行,I最後線程結束,棧空間被回收,局部變數對象也被回收。這樣就無須進行垃圾回收了。
常見的棧上分配的場景:
給成員變數賦值、方法返回值、實例引用傳遞。
同步省略
如果一個對象被髮現只能從一個線程被訪問到,那麼對於這個對象的操作可以不考慮同步,即使代碼中有同步塊,但是如果該代碼只能被一個線程發現,那麼在運行階段此同步代碼塊會被取出。
在動態編譯同步塊的時候,JIT編譯器可以藉助逃逸分析來判斷同步塊所使用的鎖對象是否只能夠被一個線程訪問而沒有被髮布到其他線程。如果沒有,那麼JIT編譯器在編譯這個同步塊的時候就會取消對這部分代碼的同步。這樣就能大大提高併發性和性能。這個取消同步的過程就叫同步省略,也叫鎖消除。
以下代碼便是同步省略的例子,因為變數hollis是在方法f中聲明的,那麼只有聲明該方法的線程才能訪問,因為hollis是局部變數,局部變數保存在棧幀中,棧幀是線程私有的。
public void f(){
Object hollis = new Object();
synchronized(hollis){
System.out.println(hollis);
}
}
分離對象或標量替換
聚合量:可以被分解為更小的數據和其他的聚合量,例如對象
標量:不能被拆分的數據,例如基本數據類型
有的對象可能不需要作為一個連續的記憶體結構存在也可以被訪問到,那麼對象的部分(或全部)可以不存儲在記憶體,而是存儲在棧中。
標量(Scalar)是指一個無法再分解成更小的數據的數據。Java中的原始數據類型就是標量。相對的,那些還可以分解的數據叫做聚合量(Aggregate),Java中的對象就是聚合量,因為他可以分解成其他聚合量和標量。
在JIT階段,如果經過逃逸分析,發現一個對象不會被外界訪問的話,那麼經過JIT優化,就會把這個對象拆解成若幹個其中包含的若幹個成員變數來代替。這個過程就是標量替換。
經過標量替換前的alloc方法
public static void main(String[] args) { alloc();
}
private static void alloc(){
Point point = new Point (1,2);
System.out.printin("point.x="+point.x+"; point.y="+point.y);
}
class Point{
private int x;
private int y;
}
經過標量替換後的alloc方法
private static void alloc(){
int x=1;
int y=2;
System.out.printin("point.x="+x+"; point.y="+y);
}
可以看到,Point這個聚合量經過逃逸分析後,發現他並沒有逃逸,就被替換成兩個聚合量了。那麼標量替換有什麼好處呢?就是可以大大減少堆記憶體的占用。因為一旦不需要創建對象了,那麼就不再需要分配堆記憶體了。
標量替換為棧上分配提供了很好的基礎。
具體參數
-XX:+EliminateAllocations:開啟了標量替換(預設打 開),允許將對象打散分配在棧上。
逃逸分析技術總結
該技術到目前為止沒有特別成熟。
其根本原因就是無法保證逃逸分析的性能消耗一定能高於他的消耗。雖然經過逃逸分析可以做標量替換、棧上分配、和鎖消除。但是逃逸分析自身也是需要進行一系列複雜的分析的,這其實也是一個相對耗時的過程。
一個極端的例子,就是經過逃逸分析之後,發現沒有一個對象是不逃逸的。那這個逃逸分析的過程就白白浪費掉了。
雖然這項技術並不十分成熟,但是它也是即時編譯器優化技術中一個十分重要的手段。
註意到有一些觀點,認為通過逃逸分析,JVM會在棧上分配那些不會逃逸的對象,這在理論上是可行的,但是取決於JVM設計者的選擇。
Oracle HotspotJVM中並未這麼做,這一點在逃逸分析相關的文檔里已經說明,所以可以明確所有的對象實例都是創建在堆上。
目前很多書籍還是基於JDK 7以前的版本,JDK已經發生了很大變化,intern字元串的緩存和靜態變數曾經都被分配在永久代上,而永久代已經被元數據區取代。但是,intern字元串緩存和靜態變數並不是被轉移到元數據區,而是直接在堆上分配。
方法區
下圖是棧、堆、方法區的關係。
棧保存著的是局部變數
堆保存著變數對應的數據
方法區保存著變數類型的信息
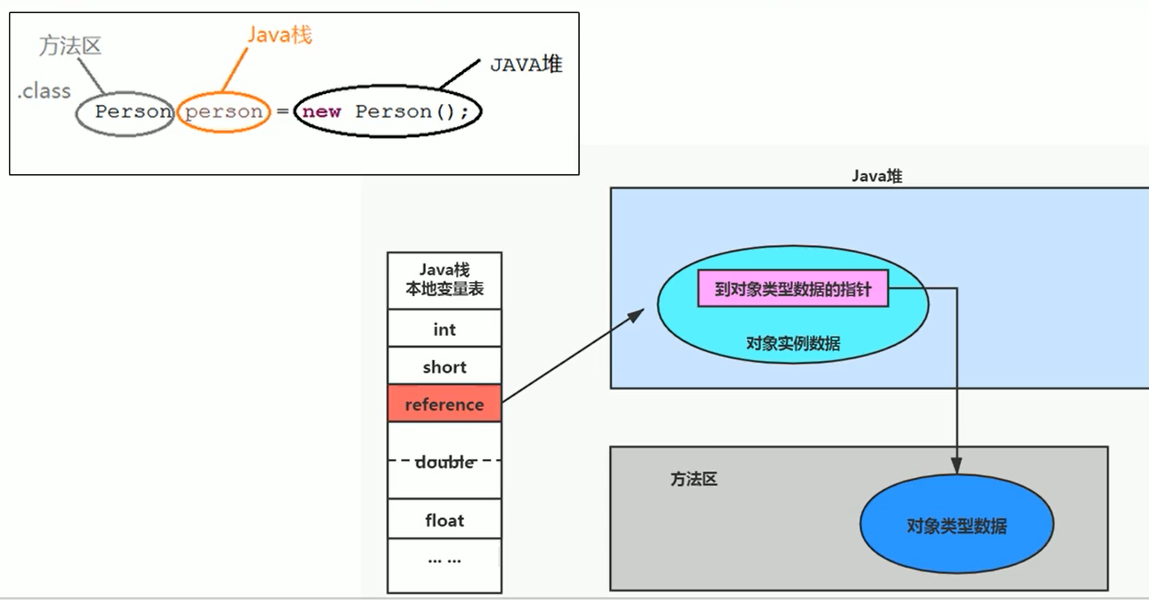
方法區 在哪個部分
JVM規範指出:方法區在邏輯上屬於堆,但是實際的具體的JVM中並不屬於堆的一部分。
基本理解
- 方法區(Method Area)與Java堆一樣,是各個線程共用的記憶體區域。
- 元空間,永久代是方法區的一個實現
- 方法區在JVM啟動的時候被創建,並且它的實際的物理記憶體空間中和Java堆區一樣都可以是不連續的。
- 方法區的大小,跟堆空間一樣,可以選擇固定大小或者可擴展。
- 方法區的大小決定了系統可以保存多少個類,如果系統定義了太多的類,導致方法區溢出,虛擬機同樣會拋出記憶體溢出錯誤:java.lang.OutofMemoryError: PermGen space 或者 java.lang.OutOfMemoryError: Metaspace
- 例如載入大量第三方的jar包,Tomcat部署過多的工程(30-50),大量的動態生成反射類。
- 關閉JVM就會釋放這個區域的記憶體。
HotSpot中方法區的演進
在jdk7及以前,習慣上把方法區,稱為永久代。jdk8開始,使用元空間取代了永久代。
In JDK 8, classes metadata is now stored in the native heap and this space is called Metaspace.
本質上,方法區和永久代並不等價。僅是對hotspot而言的。《Java虛擬機規範》
對如何實現方法區,不做統一要求。例如:BEA JRockit/ IBM J9中不存在永久代的概念。
元空間的本質和永久代類似,都是對JVM規範中方法區的實現。
元空間和永久代區別
元空間不在虛擬機設置的記憶體中,而是使用本地記憶體。
永久代、元空間二者並不只是名字變了,內部結構也調整了。
根據《Java虛擬機規範》的規定,如果方法區無法滿足新的記憶體分配需求時,將拋出OOM異常。
設置方法區的大小與OOM
方法區大小可以動態調整。JDK8之前和之後有所不同,這裡只介紹JDK8及其之後的參數設置
元數據區大小可以使用參數-XX:MetaspaceSize和-XX:MaxMetaspaceSize指定,設置方法區大小。
預設值依賴於平臺。windows下,-XX:MetaspaceSize是21M,如果- XX:MaxMetaspaceSize 的值是-1,即沒有限制。
方法區存儲內容
《深入理解Java 虛擬機》書中對方法區(Method Area)存儲內容描述如下:
它用於存儲已被虛擬機載入的類型信息、常量、靜態變數、即時編譯器編譯後的代碼緩存等。
類型信息
對每個載入的類型(類class、介面interface、枚舉enum、註解annotation),JVM必須在方法區中存儲以下類型信息:
①這個類型的完整有效名稱(全名=包名.類名)
②這個類型直接父類的完整有效名(對於interface或是java.lang.object,都沒有父類)
③這個類型的修飾符(public,abstract,final的某個子集)
④這個類型直接介面的一個有序列表
可以看作是類型所有靜態信息
域(Field)信息
JVM必須在方法區中保存類型的所有域的相關信息以及域的聲明順序。
域的相關信息包括:功能變數名稱稱、域類型、域修飾符(public, private,
protected,static,final,volatile, transient的某個子集)
方法(Method)信息
JVM必須保存所有方法的以下信息,同域信息一樣包括聲明順序:
- 方法名稱
- 方法的返回類型(或 void)
- 方法參數的數量和類型(按順序)
- 方法的修飾符(public,private, protected, static等)
- 方法的位元組碼(bytecodes)、操作數棧、局部變數表及大小(abstract和native方法除外)
- 異常表 abstract和native方法除外)
每個異常處理的開始位置,結束位置,等信息
non-final的類變數
-
靜態變數和類關聯在一起,隨著類的載入而載入,它們成為類數據在邏輯上的一部分。
-
類變數被類的所有實例共用,即使沒有類實例時你也可以訪問它。
運行時常量池(重要)
簡介
方法區,內部包含了運行時常量池。 位元組碼文件,內部包含了常量池。
要弄清楚方法區,需要理解清楚ClassFile,因為載入類的信息都在方法區。 要弄清楚方法區的運行時常量池,需要理解清楚ClassFile中的常量池。
ClassFile中的常量池是保存著靜態的信息,包括數值,方法的符號引用,類引用,字元串值,欄位引用。ClassFile中的常量池可以看作一張表,虛擬機指令通過這張表找到要執行的類名,方法名,參數名,參數類型,字面量等信息。
常量池表(Constant Pool Table)是Class文件的一部分,用於存放編譯期生成的各種字面量與符號引用,這部分內容將在類載入後存放到方法區的運行時常量池中。
運行時常量池,在載入類和介面到虛擬機後,就會創建對應的運行時常量池。
JVM為每個已載入的類型(類或介面)都維護一個常量池。池中的數據項像數組項一樣,是通過索引訪問的。
運行時常量池,相對於Class文件常量池的另一重要特征是:具備動態性。
java規範並不要求常量只能在運行時才產生,也就是說運行時常量池的內容並不全部來自class常量池,在運行時可以通過代碼生成常量並將其放入運行時常量池中,這種特性被用的最多的就是String.intern()。
運行時常量池類似於傳統編程語言中的符號表(symbol table),但是它所包含的數據卻比符號表要更加豐富一些。
總結:常量池和運行時常量池就像是類和實例的關係,常量池是類,運行時常量池是對象。運行時常量池存儲著一些真正的可以執行的東西
方法區的演變細節
| jdk1.6及之前 | 有永久代,靜態變數放在永久代上 |
|---|---|
| jdk1.7 | 有永久代,但在去永久代化,字元串常量池,靜態變數被移除,保存到堆中 |
| jdk1.8及之後 | 無永久代,類型信息,欄位,方法,常量保存在本地記憶體的元空間,但字元串常量池,靜態變數還是在堆 |
為什麼要將永久代替換為元空間
-
為永久代設置大小是很難確定的,如果類很多,過小會OOM,過大會導致浪費
-
很難對永久代進行調優
StringTable(字元串常量池)為什麼要放到堆
jdk7將StringTable放到堆中,因為永久代的垃圾回收效率低,就導致StringTable回收效率低,就會占用很多永久代的記憶體,如果放到堆中,就可以即使回收了
方法區的GC
方法區的垃圾回收主要回收兩部分:常量池廢棄的常量和不再使用的類型。
判定一個常量是否“廢棄”還是相對簡單,
而要判定一個類型是否屬於“不再被使用的類”的條件就比較苛刻了。需要同時滿足下麵三個條件:
-
該類所有的實例都已經被回收,也就是Java堆中不存在該類及其任何派生子類的實例。
-
載入該類的類載入器已經被回收,這個條件除非是經過精心設計的可替換類載入器的場景,如OSGi、JSP的重載入等,否則通常是很難達成的。
-
該類對應的java.lang.Class對象沒有在任何地方被引用,無法在任何地方通過反射訪問該類的方法。


