
我們經常會說互聯網“三高”,那什麼是三高呢?我們常說的三高,高併發、高可用、高性能,這些技術是構建現代互聯網應用程式所必需的。對於京東618備戰來說,所有的中台系統服務,無疑都是圍繞著三高來展開的。對於一個程式員,或多或少都能說出一些跟三高系統有關的技術點,而我本篇文章的目的,就是幫大家系統的梳理一... ...
前言
我們經常會說互聯網“三高”,那什麼是三高呢?我們常說的三高,高併發、高可用、高性能,這些技術是構建現代互聯網應用程式所必需的。對於京東618備戰來說,所有的中台系統服務,無疑都是圍繞著三高來展開的。對於一個程式員,或多或少都能說出一些跟三高系統有關的技術點,而我本篇文章的目的,就是幫大家系統的梳理一下三高系統中的第一高:高可用性。
首先來說,互聯網的業務特點決定了他必須保證“三高”, 同時,高併發,高可用,高性能,這三高之間並不是孤立的,而是強相關。一個高可用的系統,一定也需要應對高併發場景對系統帶來的衝擊,保證系統在高流量訪問情況下,系統的服務的正常運轉。同時,一個能夠支撐高併發的系統也一定要滿足高性能,否則也無法實現高流量的承載。
回到我們本文的主旨,我們這裡所說的高可用性是指,系統在遇到任何困難的情況下仍能正常運行的能力。
在京東618備戰期間,系統的高可用對我們來說至關重要,因為系統的崩潰,不止帶來直接經濟上的損失,還會導致用戶信任的丟失。接下來我通過一張思維導圖展開我的分享,幫大家梳理一下一個高可用系統所需要考慮的技術點。
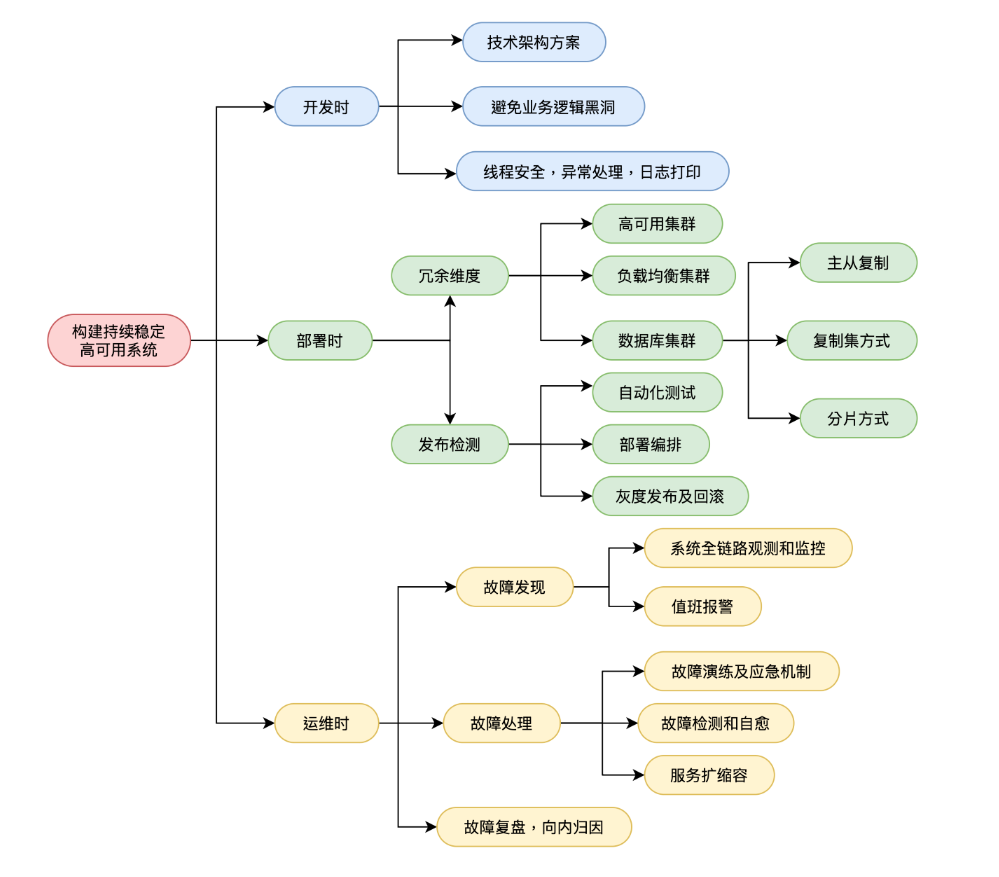
開發時
1. 首先技術架構方案選型很重要,切記避免過度設計。
比如我們常說的單體應用架構和微服務架構,兩種架構單純來對比,單體應用架構的可用率要比微服務架構高的。因為多服務之間的依賴一定會降低系統的可用率,比如一個依賴10個微服務的對外介面,假設每個服務的可用率是99%,那麼這個介面對外提供服務的整體可用率就直接降到了90.4%,這中間還要考慮到服務之間的網路延遲,數據一致性的問題。
還有例子就是中間件選擇,比如一個緩存業務場景,我可以用記憶體緩存,也可以使用redis分散式緩存,那麼使用哪個呢?使用記憶體緩存系統可用率會高,因為如果引來redis,系統的可用率又得乘以一個redis的可用率。當然如果我們的業務場景必須使用redis,那麼也是完全可以的,但這裡切記系統的過度設計,也是設計複雜的系統,也需要更多的高可用相關的保證,所付出的資源代價和運維代價也是幾何增長。
2. 其次就是代碼質量。
其實這個可能是很多人忽略的一點,因為很多人更喜歡高談闊論分散式,集群,壓測,故障演練等等,但在我看來,一個代碼開發質量的好壞,或者說一個程式員對代碼的掌控力,對系統可用性起到至關重要的作用。以下舉幾個代碼維度的例子。
第一個就是異常處理。一個代碼質量的好壞,要看他對異常處理能力,一個本科生的課程設計代碼,可能都是主業務邏輯,一條路寫到黑,不考慮任何異常情況,而一個畢業幾年的程式員,經歷過線上業務的拷打,可能會用在代碼里找到很多的try-catch,用於捕捉各種不確定邏輯,而一個資深程式員,反而他的代碼里你看不到任何try-catch, 因為他全部用AOP的方式實現了異常的捕捉。這就是代碼維度的考量,一個優秀的代碼,一定是防禦式編程,同時還會配合單元測試等。
第二個講述一個什麼是對代碼的掌控力。在大廠里,你更多場景是接手別人的老代碼。想必所有程式員都深有體會,接手別人的老代碼是一件極其痛苦的經歷,尤其是別人寫了一半的代碼。老話前人種樹後人乘涼,但在程式員圈,前人種樹,後人只能涼涼了..... 調侃歸調侃,但有些事情需要面對,前期你需要對業務場景和代碼邏輯進行抽絲剝繭的梳理,這個很重要。如果你無法對老代碼進行充分熟悉,那麼你就不敢去改寫和重構它,如果在不熟悉的前提下貿然修改代碼或者配置,然後上線,那麼很大幾率會帶來線上系統問題,影響系統可用率。換一個角度來說,我們寫的代碼未來也可能交接給別人,如何不讓別人痛苦,也是我們的責任。所以合理使用設計模式,遵循代碼規範,書寫代碼架構和設計文檔,這些也是很重要的一點,他的重要可能會關乎系統未來的可用率。
對於代碼開發這塊,京東技術平臺也沉澱了一些自己的經驗。內部有自己的java代碼開發規範說明文檔,也在京英學習平臺上可以進行考試。而京東的coding平臺,可以在你代碼提交時,配置代碼開發規範掃描和代碼安全性掃描,同時,可以配置代碼評審人,這些都可以用來提升我們代碼質量。
部署時
1. 冗餘性和備份
在部署維度,我們首先考慮的是冗餘性和備份設計,這個可能是大家已經很熟悉的情況了,我們可以通過集群的方式,多個伺服器、磁碟或者網路介面來減少故障點的數量。說到集群,根據實現方式和目的不同,我幫大家梳理一下集中集群類型:
(1)高可用集群。
有多個獨立伺服器組成的系統,旨在提高系統可用性,當主節點出現故障時,通過失敗轉移(Failover)讓備用節點自動接管服務。這個我們常見的有zookeeper集群,etcd集群等等,這類集群是基於共識演算法實現的, 通過選舉的方式,來保證當主節點故障時,可以有自動備份節點自動接管。
(2)負載均衡集群。
在負載均衡系統中,流量被分散到多個伺服器中,每個伺服器都獨立地處理請求。當一個伺服器負載過高或出現故障時,請求會自動被轉移到其他可用的伺服器上,從而保證系統的可用性和性能。負載均衡可以在多個層面上實現,包括應用層、傳輸層和網路層。在應用層負載均衡中,負載均衡器通常通過HTTP代理來分發請求,並根據請求的特定屬性(例如URL或Cookie)進行路由。在傳輸層負載均衡中,負載均衡器通常在傳輸層(例如TCP或UDP)上運行,並根據埠號或其他特定協議進行路由。在網路層負載均衡中,負載均衡器通常是一個獨立的網路設備,用於在不同的伺服器之間分髮網絡流量。
(3)資料庫集群。
這裡的資料庫可以理解為廣義資料庫,就是數據的存儲媒介。對於資料庫的的集群實現方式,分為如下幾個:主從複製,複製集,分區。
關於這幾種實現方案,這裡可以elasticsearch舉例說明。ES有分片和副本的概念,所謂的分片,就是將數據水平劃分到多個節點,每個節點存儲部分數據,當查詢數據時,需要在多個節點上進行查詢,最後將結果合併。分區可以實現數據的高可用性和可擴展性,但需要考慮數據一致性問題。
同時ES的每個分片都可以配置多個副本,副本跟主從複製類似,或者說更像一個集群內的高可用子集,允許多個副本實例同時存在,並支持自動故障轉移和成員選舉,保證了數據的高可用性和負載均衡。
此外,對於集群方案來說,還要額外考慮多機房部署問題,異地多活。換句話說,我所有服務實例,不能放在一個籃子里,因為網路的抖動和不穩定性,對系統可用性來說是很大的威脅。
2. 發佈檢測
在部署維度,第二個關鍵點是發佈檢測。有統計數據表明,我們大部分的穩定性問題來源於系統變更,也就是系統的發佈上線。那麼如何保證一個平穩的系統上線呢?
首先,要完善自動化測試和單元測試,每次發版前,必回歸測試,當然這塊如果交給人工來做,費時費力,不一定能起到他的效果,所有說,完善的自動化測試流程,對於系統穩定性部署來說,至關重要。
其次就是做好發佈的自動化,在發版過程中,減少人為參與,這樣也就減少了出錯的可能性。京東的行雲部署本身就支持部署編排,利用部署編排,可以穩定且高效的實線滾動發版。同時也可以在行雲上的流水線中配置CI/CD流程,實現繼續集成和持續部署的串聯。
最後就是要實現發版的可觀測,可灰度,可回滾。發版前要有checklist,發版時採用灰度發佈驗證的方式,可以降低因為發版引起的線上故障。最後如果發版發現失敗,可以實現快速的回滾操作。這個就要在發版前的checkList里,做好回滾流程的備案。
運維時
在運維時,我們的目標是能夠快速止損線上問題,做到問題早發現,快定位,速解決。
1. 系統全鏈路觀測和監控
在互聯網系統中,從用戶請求開始,經過所有的系統組件或服務,直到響應返回給用戶,對整個系統的性能、穩定性和可用性進行全面觀測和監控的過程。這包括了對硬體、網路、存儲、軟體等方面的觀測,監控。
在京東618備戰期間,所有應用系統都必須完成自建,完善UMP監控埋點,對核心介面方法的可用率,TP99,調用量進行實時監控,同時,也對需要對雲主機,中間件等資源維度,包括CPU,記憶體,資源占有率進行實時監控。
此外,針對監控,要做好日誌監控做好採集工作,因為日誌記錄了系統中各個組件或服務的運行狀態,可以提供豐富的信息用於問題排查和分析。
在京東內部採用logbook進行日誌採集,對於核心業務需要審計留存的,可以單獨搭建ELK,將歷史日誌存入ES中。
2. 值班與報警。
針對618備戰期間,需要額外安排固定人員進行每日值班,做到對線上問題可以及時反饋。
針對報警機制,有一點需要切記,要把握好報警的閾值問題,如果閾值偏低,會導致研發人員頻繁收到報警,導致警惕性降低。而如果閾值偏高,會錯過一些線上問題,導致問題沒有及時發現,致使故障擴大化。
3. 故障演練及應急機制。
京東內部有兩大利器,一個是ForceBot,一個是Chaos Monkey。
前者是做全鏈路軍演壓測用的,一般618大促前要進行三次軍演壓測,通過這些軍演,讓各個應用系統發現系統中的薄弱點,並針對性解決。forcebot是通過部署在全國各地的CDN節點,模擬真實用戶發起的大規模訪問流量,這種接近實戰的壓測,可以讓我們做到防患於未然,同時,通過壓測,可以針對性的優化服務資源,能夠更針對性的進行擴容。
第二個我們有時候會叫猴子搗亂測試,也會叫混沌測試。它能夠通過模擬包括網路,中間件,流量等在內的各種故障,通過故障的隨機註入,來演練我們對系統故障的反應能力。
這裡就該提到所謂的應急機制。該機制就像一本類似醫院給發的急救指南手冊,需要在日常做到對各種不確定的故障進行反應能力。比如遇到突發高流量,系統出現了熔斷,如何快速擴容雲主機和各類中間件資源;比如網路突然發生延遲,介面請求超時情況下,如何做好降級方案等等。
總結
本文寫於京東618備戰開門紅前夜值班之時。
以上的所有關於系統高可用的總結,都源於一次次的前人的實踐經驗總結出來的。每次備戰略細節有不同,但大的方向原則是不變的。
祝:京東618 大麥。
作者:京東物流 趙勇萍
來源:京東雲開發者社區


