
# 第1章 Kettle概述 ## 1.1 ETL簡介 ETL(Extract-Transform-Load的縮寫,即數據抽取、轉換、裝載的過程),對於企業或行業應用來說,我們經常會遇到各種數據的處理,轉換,遷移,所以瞭解並掌握一種ETL工具的使用,必不可少。 市面上常用的ETL工具有很多,比如Sq ...
第1章 Kettle概述
1.1 ETL簡介
ETL(Extract-Transform-Load的縮寫,即數據抽取、轉換、裝載的過程),對於企業或行業應用來說,我們經常會遇到各種數據的處理,轉換,遷移,所以瞭解並掌握一種ETL工具的使用,必不可少。
市面上常用的ETL工具有很多,比如Sqoop,DataX,Kettle,Talend等,作為一個大數據工程師,我們最好要掌握其中的兩到三種,這裡我們要學習的ETL工具是Kettle!
1.2 Kettle簡介
1.2.1 Kettle是什麼
Kettle是一款國外開源的ETL工具,純java編寫,可以在Window、Linux、Unix上運行,綠色無需安裝,數據抽取高效穩定。
Kettle 中文名稱叫水壺,該項目的主程式員MATT 希望把各種數據放到一個壺裡,然後以一種指定的格式流出。
Kettle這個ETL工具集,它允許你管理來自不同資料庫的數據,通過提供一個圖形化的用戶環境來描述你想做什麼,而不是你想怎麼做。
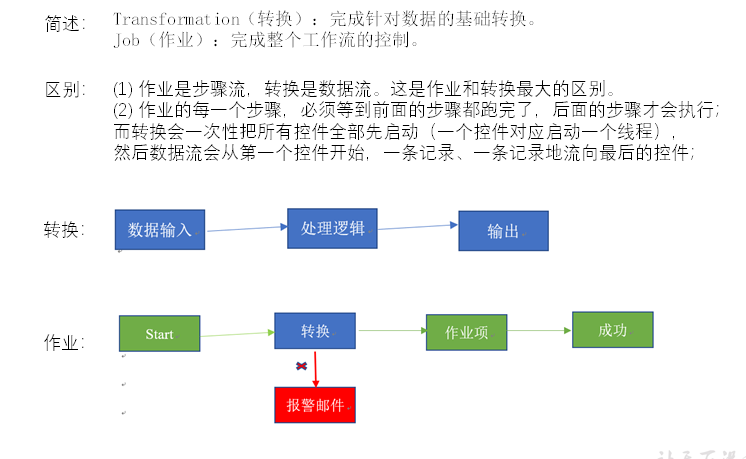
Kettle中有兩種腳本文件,transformation和job,transformation完成針對數據的基礎轉換,job則完成整個工作流的控制。
Kettle(現在已經更名為PDI,Pentaho Data Integration-Pentaho數據集成)。
1.2.2 Kettle的兩種設計
1.2.3 Kettle的核心組件

1.2.4 Kettle特點

第2章 Kettle安裝部署
2.1 Kettle下載
2.1.1 下載地址
官網地址
https://community.hitachivantara.com/docs/DOC-1009855
下載地址
https://sourceforge.net/projects/pentaho/files/Data Integration/
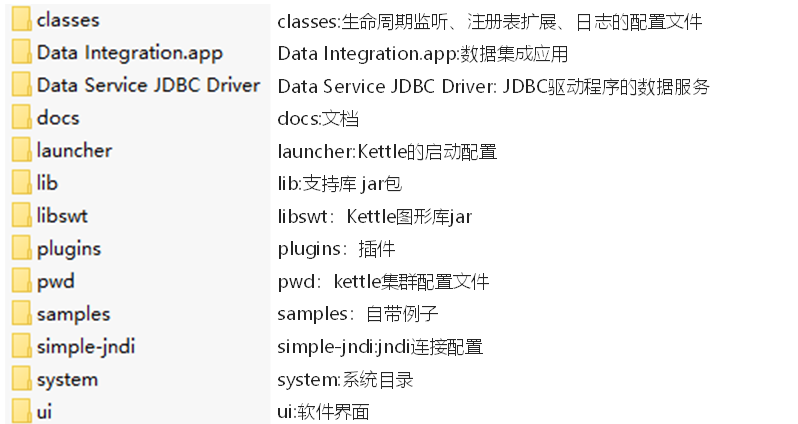
2.1.2 Kettle目錄說明
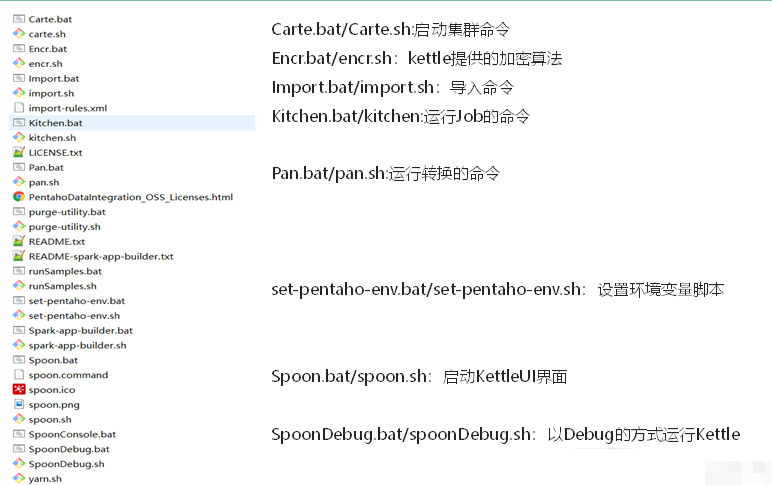
2.1.3 Kettle文件說明
2.2 Kettle安裝部署
2.2.1 概述
在實際企業開發中,都是在本地Windows環境下進行kettle的job和Transformation開發的,可以在本地運行,也可以連接遠程機器運行
2.2.2 安裝
- 安裝jdk,版本建議1.8及以上
- 下載kettle壓縮包,因kettle為綠色軟體,解壓縮到任意本地路徑即可
- 雙擊Spoon.bat,啟動圖形化界面工具,就可以直接使用了
2.3 Kettle界面簡介
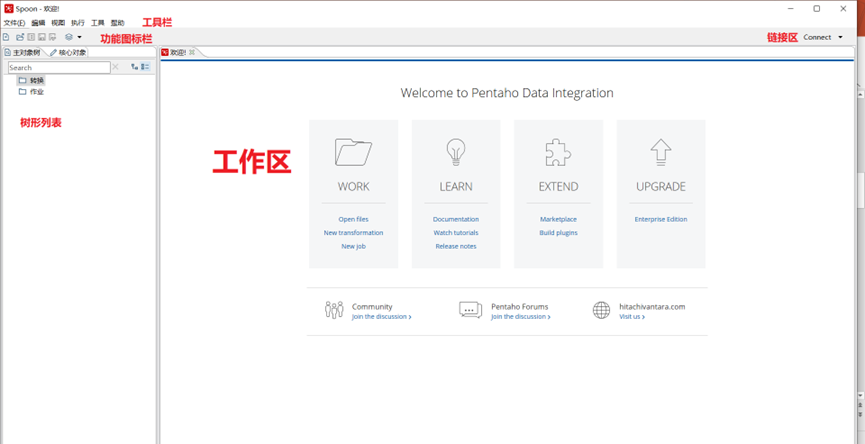
2.3.1 首頁
2.3.2 轉換
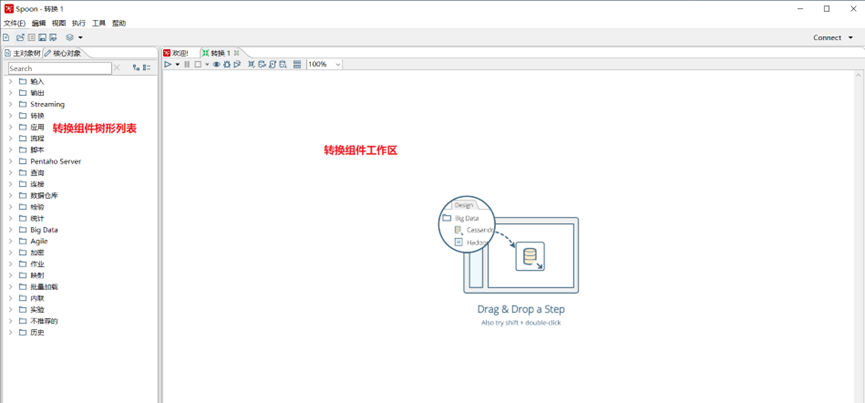
2.3.3 作業
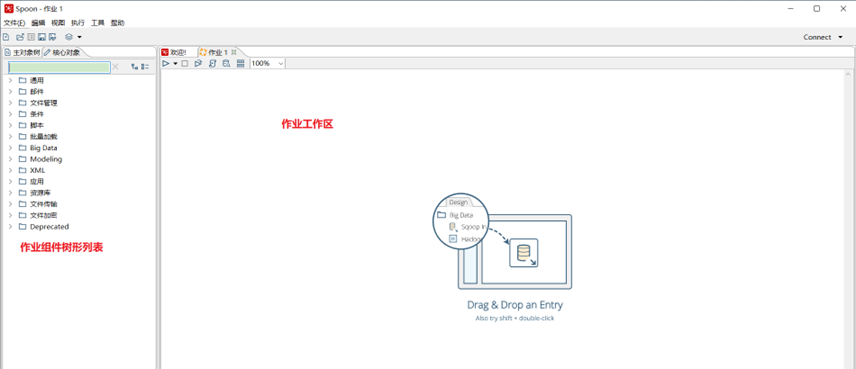
2.4 Kettle轉換初次體驗
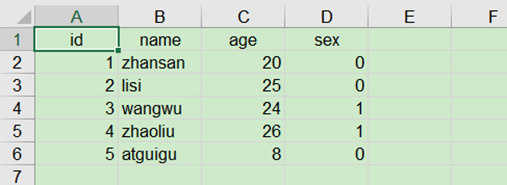
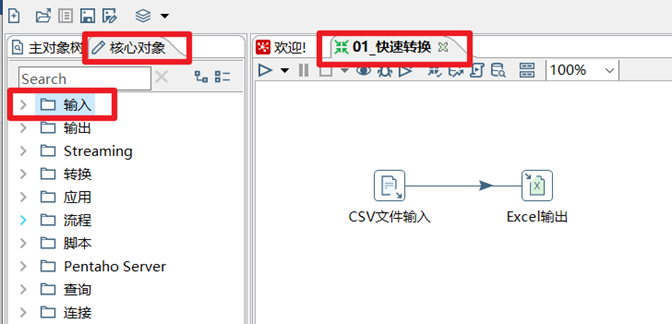
體驗案例:將csv文件用Kettle轉換成excel文件
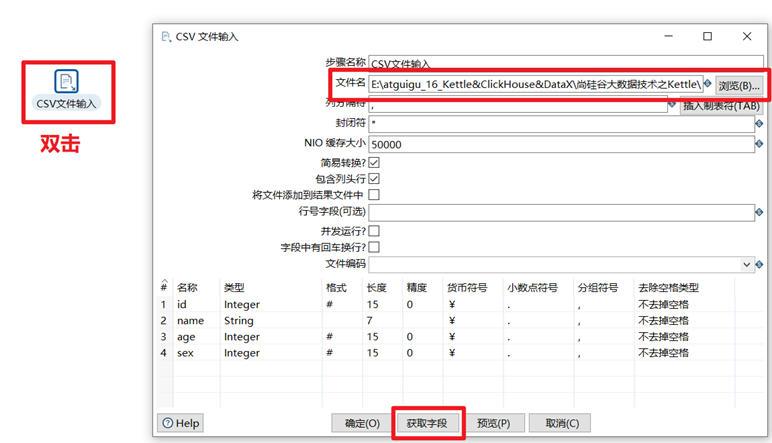
1) 在Kettle中新建一個轉換,然後選擇轉換下麵的“csv文件輸入”和“Excel輸出”控制項

2) 雙擊CSV文件輸入文件控制項,在彈出的設置框里找到對應的csv文件(尚矽谷大數據技術之Kettle\5.數據\input\01_kettle快速體驗.csv),然後點擊下麵的獲取欄位按鈕,將我們需要的欄位載入到kettle中
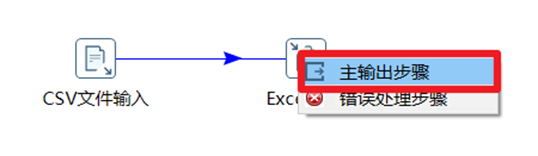
3)按住鍵盤SHIFT鍵,並且點擊滑鼠左鍵將兩個控制項鏈接起來,鏈接時選擇“主輸出步驟”

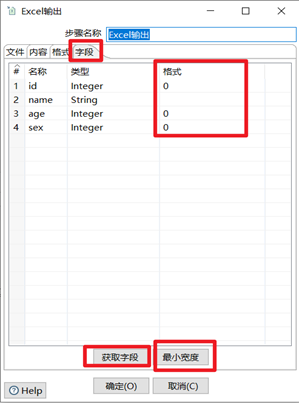
4)雙擊Excel輸出控制項,在彈出的設置框里設置文件輸出路徑和文件名稱,然後點擊上面的欄位框,依次點擊下麵的獲取欄位和最小寬度,獲取到輸出欄位。
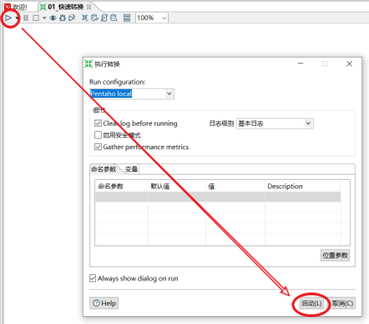
5)點擊左上角的啟動按鈕,在彈出的設置框里點擊啟動,執行該轉換。
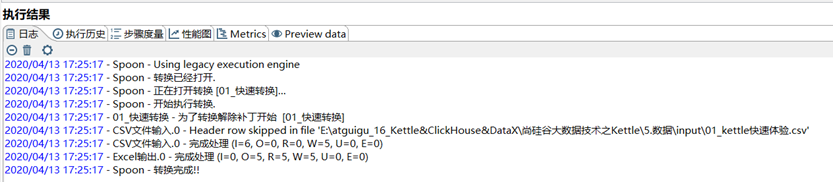
6)查看kettle下方執行結果日誌以及輸出路徑的Excel文件內容
2.5 Kettle核心概念
2.5.1 可視化編程
Kettle可以被歸類為可視化編程語言(Visula Programming Languages,VPL),因為Kettle可以使用圖形化的方式定義複雜的ETL程式和工作流。
可視化編程一直是Kettle里的核心概念,它可以讓你快速構建複雜的ETL作業和減低維護工作量。它通過隱藏很多技術細節,使IT領域更貼近於商務領域。
Kettle里的代碼就是轉換和作業。
2.5.2 轉換
轉換(transaformation)負責數據的輸入、轉換、校驗和輸出等工作。Kettle 中使用轉換完成數據 ETL 全部工作。轉換由多個步驟 (Step) 組成,如文本文件輸入,過濾輸出行,執行 SQL 腳本等。各個步驟使用跳 (Hop) 來鏈接。 跳定義了一個數據流通道,即數據由一個步驟流 (跳) 向下一個步驟。在 Kettle 中數據的最小單位是數據行(row),數據流中流動其實是緩存的行集 (RowSet) 。
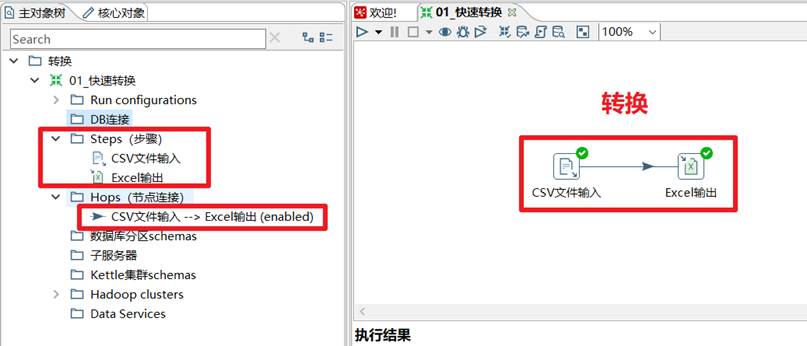
2.5.3 步驟(Step)
步驟(控制項)是轉換里的基本的組成部分,快速入門的案例中就存在兩個步驟,“CSV文件輸入”和“Excel輸出”。
一個步驟有如下幾個關鍵特性:
①步驟需要有一個名字,這個名字在同一個轉換範圍內唯一。
②每個步驟都會讀、寫數據行(唯一例外是“生成記錄”步驟,該步驟只寫數據)。
③步驟將數據寫到與之相連的一個或多個輸出跳(hop),再傳送到跳的另一端的步驟。
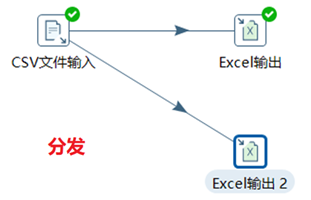
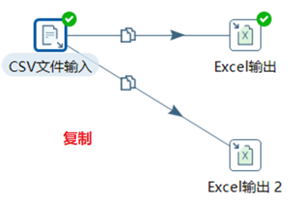
④大多數的步驟都可以有多個輸出跳。一個步驟的數據發送可以被設置為分發和複製,分發是目標步驟輪流接收記錄,複製是所有的記錄被同時發送到所有的目標步驟。
2.5.4 跳(Hop)
跳就是步驟之間帶箭頭的連線,跳定義了步驟之間的數據通路。
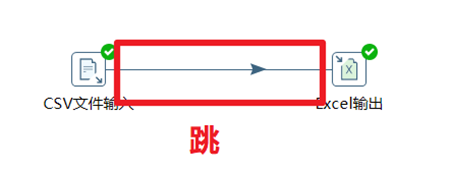
跳實際上是兩個步驟之間的被稱之為行集的數據行緩存,行集的大小可以在轉換的設置里定義。當行集滿了,向行集寫數據的步驟將停止寫入,直到行集里又有了空間。當行集空了,從行集讀取數據的步驟停止讀取,直到行集里又有可讀的數據行。
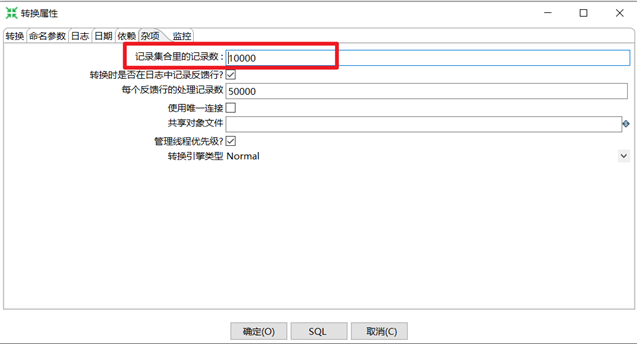
2.5.5 元數據
每個步驟在輸出數據行時都有對欄位的描述,這種描述就是數據行的元數據。
通常包含下麵一些信息。
①名稱:數據行里的欄位名是唯一的。
②數據類型:欄位的數據類型。
③格式:數據顯示的方式,如Integer的#、0.00。
④長度:字元串的長度或者BigNumber類型的長度。
⑤精度:BigNumber數據類型的十進位精度。
⑥貨幣符號:¥
⑦小數點符號:十進位數據的小數點格式。不同文化背景下小數點符號是不同的,一般是點(.)或逗號(,)。
⑧分組符號:數值類型數據的分組符號,不同文化背景下數字里的分組符號也是不同的,一般是點(.)或逗號(,)或單引號(’)
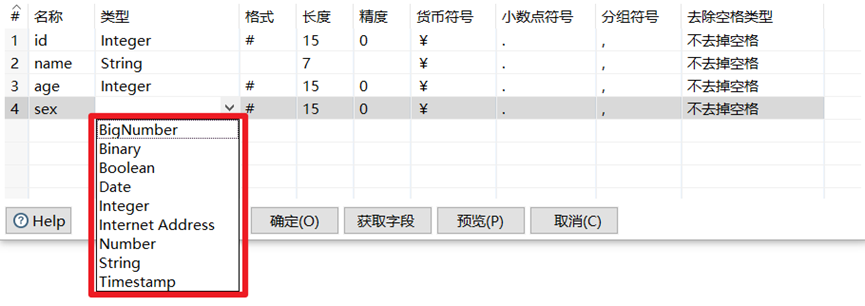
2.5.6 數據類型
數據以數據行的形式沿著步驟移動。一個數據行是零到多個欄位的集合,欄位包含下麵幾種數據類型。
①String:字元類型數據
②Number:雙精度浮點數。
③Integer:帶符號長整型(64位)。
④BigNumber:任意精度數據。
⑤Date:帶毫秒精度的日期時間值。
⑥Boolean:取值為true和false的布爾值。
⑦Binary:二進位欄位可以包含圖像、聲音、視頻及其他類型的二進位數據。
2.5.7 並行
跳的這種基於行集緩存的規則允許每個步驟都是由一個獨立的線程運行,這樣併發程度最高。這一規則也允許數據以最小消耗記憶體的數據流的方式來處理。在數據倉庫里,我們經常要處理大量數據,所以這種高併發低消耗的方式也是ETL工具的核心需求。
對於kettle的轉換,不能定義一個執行順序,因為所有步驟都以併發方式執行:當轉換啟動後,所有步驟都同時啟動,從它們的輸入跳中讀取數據,並把處理過的數據寫到輸出跳,直到輸入跳里不再有數據,就中止步驟的運行。當所有的步驟都中止了,整個轉換就中止了。
如果你想要一個任務沿著指定的順序執行,那麼就要使用下麵所講的“作業”!
2.5.8 作業
作業 (Job),負責定義一個完成整個工作流的控制,比如將轉換的結果發送郵件給相關人員。因為轉換(transformation)以並行方式執行,所以必須存在一個串列的調度工具來執行轉換,這就是 Kettle中的作業。
第3章 Kettle轉換
3.1 Kettle輸入控制項
輸入是轉換裡面的第一個分類,輸入控制項也是轉換中的第一大控制項,用來抽取數據或者生成數據。輸入是ETL裡面的E(Extract),主要做數據提取的工作。
由於Kettle中自帶的輸入控制項比較多,本文只挑出開發中經常使用的幾個輸入控制項來進行講解,詳情如下圖。
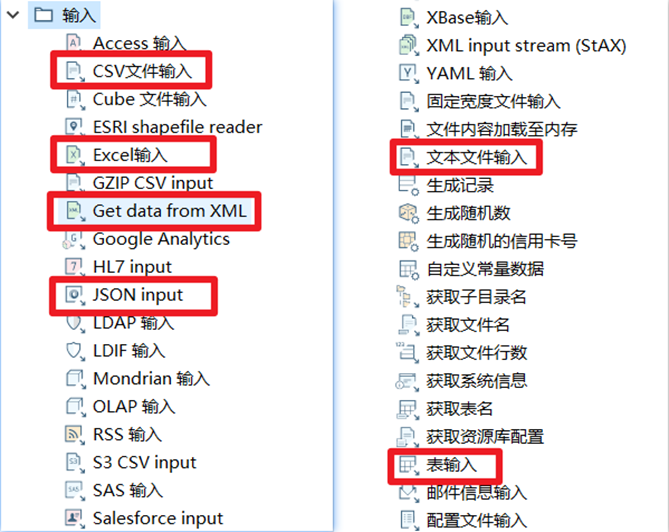
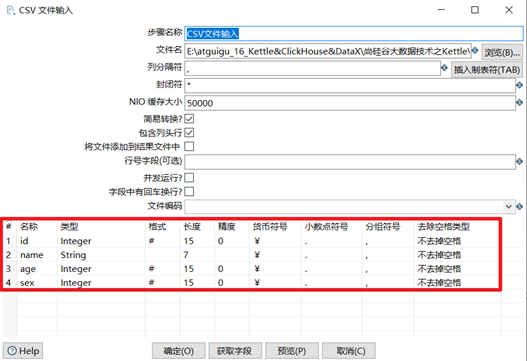
3.1.1 CSV文件輸入
CSV文件是一個用逗號分隔的固定格式的文本文件,這種文件尾碼名為.csv,可以用Excel或者文本編輯器打開。在企業裡面一般最常見的ETL需求就是將csv文件轉換為excel文件,如果用Kettle來做這個ETL工作,就需要用到本章節講解的CSV文件輸入控制項。
本章節任務:熟悉CSV文件輸入控制項,並嘗試將CSV文件轉換成Excel文件(可參考上面的快速體驗案例)。
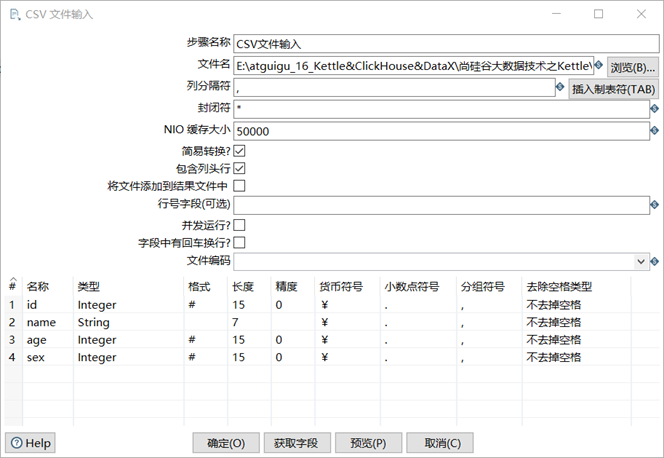
① 步驟名稱:可以修改,但是在同一個轉換裡面要保證唯一性,見名知意;
② 文件名:選擇對應的csv文件;
③ 列分隔符:預設是逗號;
④ 封閉符:結束行數據的讀寫;
⑤ NIO緩存大小:文件如果行數過多,需要調整此參數;
⑥ 包含列頭行:意思是文件中第一行是欄位名稱行,表頭不進行讀寫;
⑦ 行號欄位:如果文件第一行不是欄位名稱或者需要從某行開始讀寫,可在此輸入行號。
⑧ 併發運行?:選擇併發,可提高讀寫速度;
⑨ 欄位中有回車換行?:不要選擇,會將換行符做數據讀出;
⑩ 文件編碼:如果預覽數據出現亂碼,可更換文件編碼;
3.1.2 文本文件輸入
提取伺服器上的日誌信息是公司里ETL開發很常見的操作,日誌信息基本上都是文本類型,因此文本文件輸入控制項是kettle中常用的一個輸入控制項。使用文本文件輸入控制項步驟:
1) 添加需要轉換的日誌文件
2) 按照日誌文件格式,指定分隔符
3) 獲取下欄位,並給欄位設置合適的格式
4) 最後點下預覽記錄,看看能否讀到數據
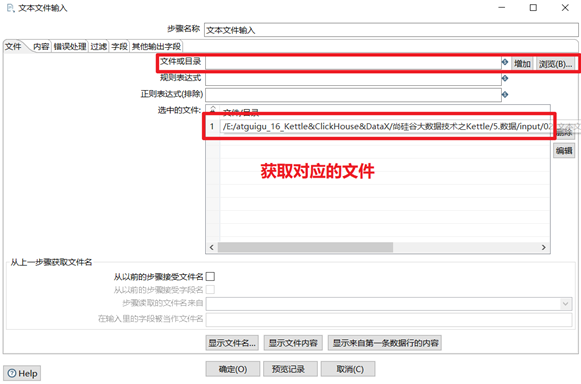
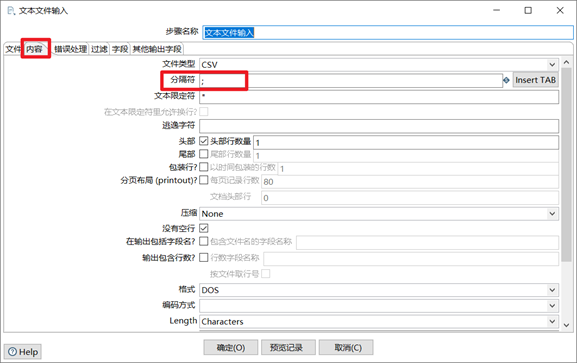
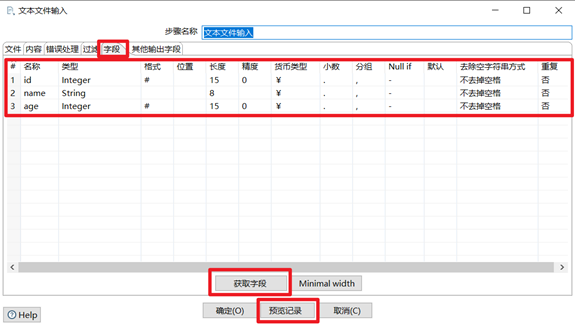
本章節任務:熟悉文本文件輸入控制項,並新建轉換,將txt日誌文件轉換為Excel文件

3.1.3 Excel輸入
Excel輸入控制項也是很常用的輸入控制項,一般企業里會用此控制項對大量的Excel文件進行ETL操作。使用Excel輸入控制項步驟如下:
1) 按照讀取的源文件格式指定對應的表格類型為xls還是xlsx
2) 選擇並添加對應的excel文件
3) 獲取excel的sheet工作表
4) 獲取欄位,並給每個欄位設置合適的格式
5) 預覽數據
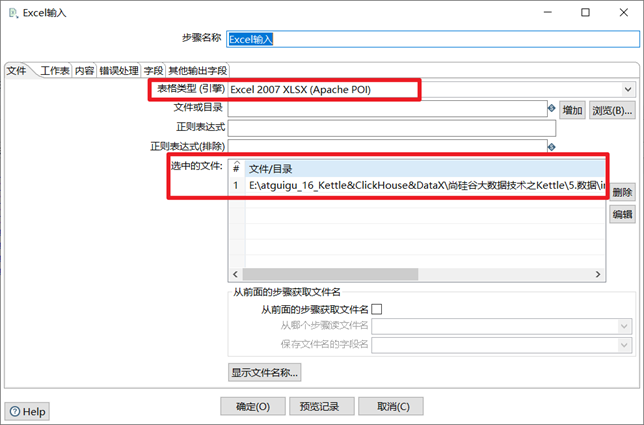
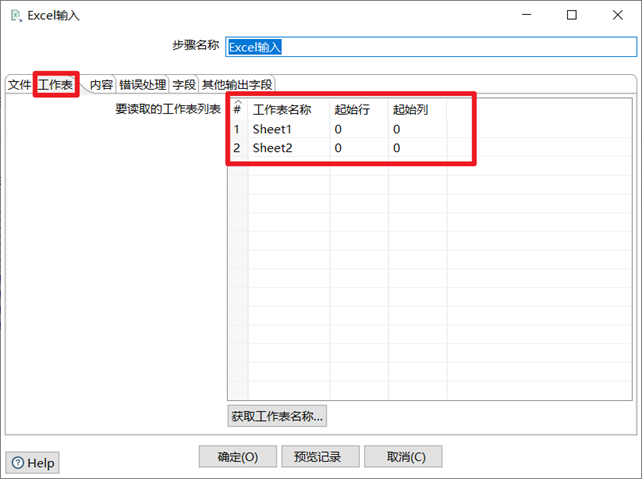
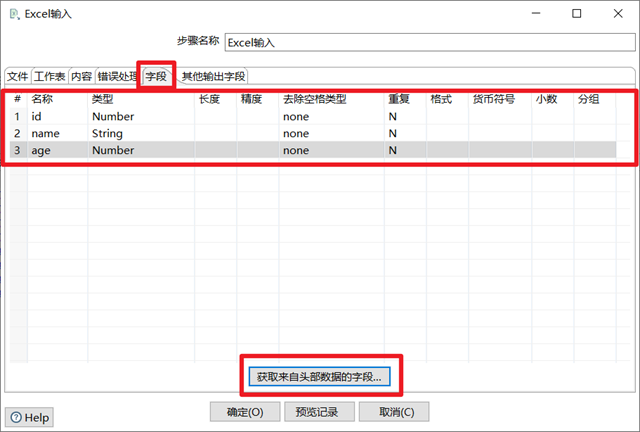
本章節任務:熟悉Excel輸入控制項,將excel文件的兩個sheet表格的數據重新寫到一個新的excel文件中
3.1.4 XML輸入
1)XML簡介
XML-可擴展標記語言eXtensible Markup Language,由W3C組織發佈,目前推薦遵守的是W3C組織於2000年發佈的XML1.0規範。XML用來傳輸和存儲數據,就是以一個統一的格式,組織有關係的數據,為不同平臺下的應用程式服務。

2) XPath簡介
XPath即為XML路徑語言(XML Path Language),它是一種用來確定XML文檔中某部分位置的語言。XPath基於XML的樹狀結構,提供在數據結構樹中找尋節點的能力。
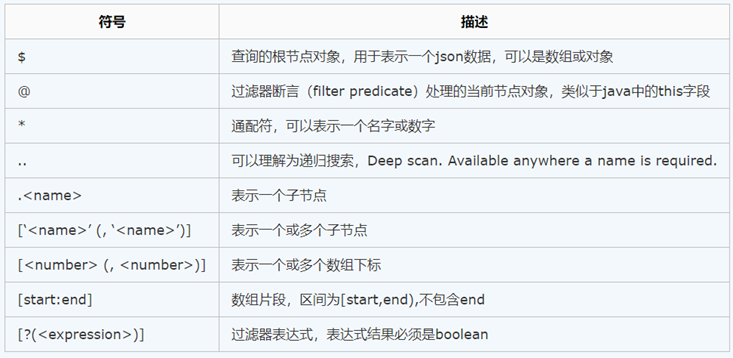
XPath 使用路徑表達式在 XML 文檔中選取節點。下麵列出了最有用的路徑表達式:

3) XML輸入控制項
瞭解XML和XPath概念以後,我們要開始學習Kettle的XML輸入控制項,企業里經常用此控制項進行XML文件的ETL操作。
- 瀏覽獲取xml文件,將xml文件添加到kettle中
- 獲取xml文檔的所有路徑,設置合適的迴圈讀取路徑
- 獲取欄位,獲得自己想要讀取的所有欄位,並且設置適當的格式
- 預覽數據,看看能否讀取到自己想要的數據
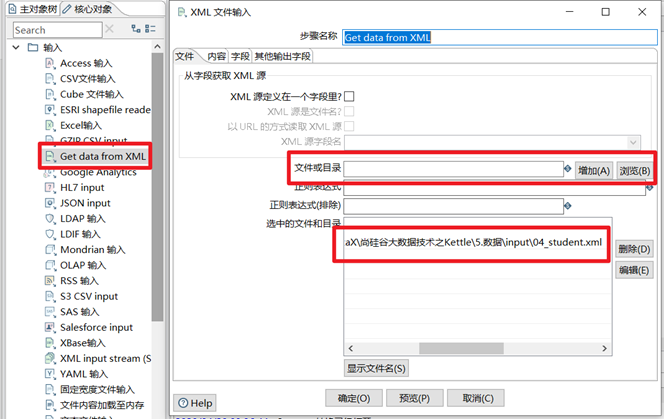
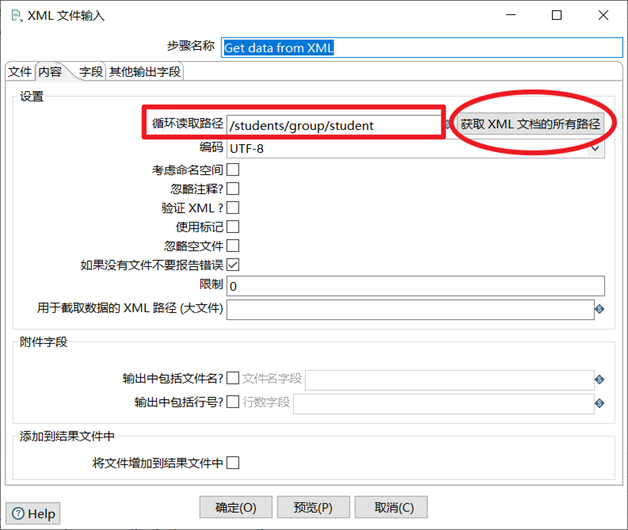
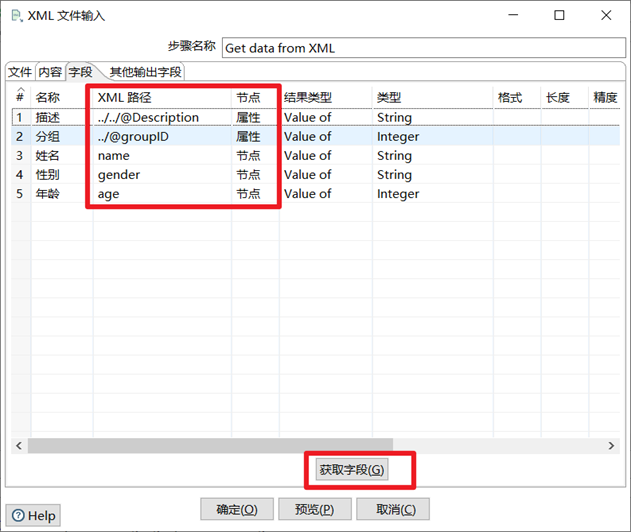
本章節任務:熟悉XML輸入控制項,將XML文件的學生數據寫到excel文件中
3.1.5 JSON輸入
1)JSON簡介
JSON(JavaScript Object Notation, JS 對象簡譜) 是一種輕量級的數據交換格式。JSON對象本質上就是一個JS對象,但是這個對象比較特殊,它可以直接轉換為字元串,在不同語言中進行傳遞,通過工具又可以轉換為其他語言中的對象。
JSON核心概念:數組、對象、屬性。
數組:[ ]
對象:{ }
屬性:key:value
2)JSON Path
JSONPath類似於XPath在xml文檔中的定位,JsonPath表達式通常是用來路徑檢索或設置Json的。其表達式可以接受“dot–notation”(點記法)和“bracket–notation”(括弧記法)格式
點記法:$.store.book[0].title
括弧記法:$[‘store’][‘book’][0][‘title’]
3) JSON輸入控制項
瞭解JSON格式和JSON Path以後,我們要學習使用JSON輸入控制項,JSON控制項也是企業里做ETL常用的控制項之一。
- 瀏覽獲取JSON文件,將json文件獲取到kettle中
- 根據JSON Path點記法,獲取到需要的欄位,並且設置合適格式
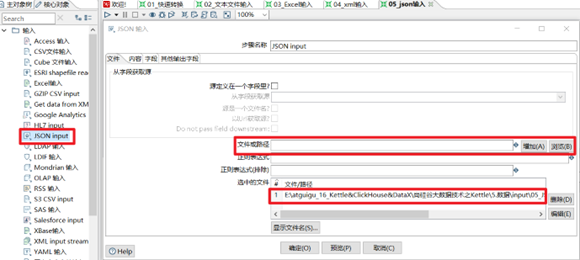
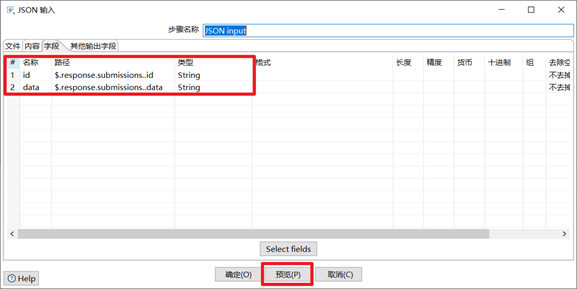
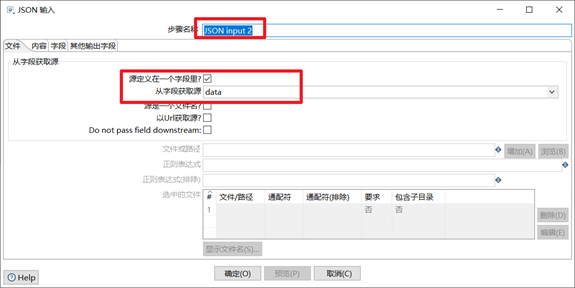
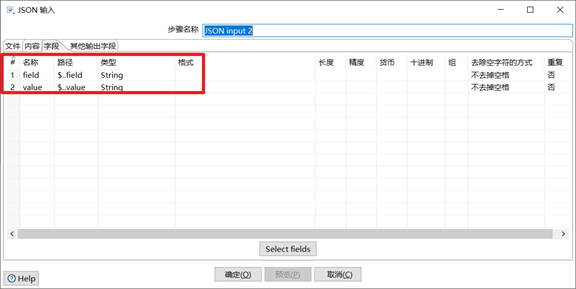
本章節任務:獲取到JSON文件裡面的id,field,value欄位,寫到excel文件中
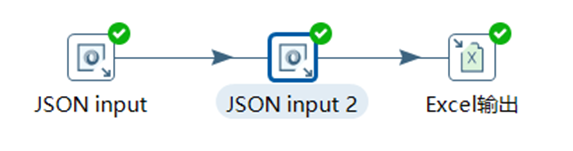
3.1.6 表輸入
1)創建資料庫連接
表輸入可以說是kettle中用到最多的一種輸入控制項,因為企業中大部分的數據都會存在資料庫中。kettle可以連接市面上常見的各種資料庫,比如Oracle,Mysql,SqlServer等。但是在連接各個資料庫之前,我們需要先配置好對應的資料庫驅動,本教程以mysql為例,給大家講解kettle連接mysql資料庫的過程。
首先我們要將對應版本的mysql連接驅動放到kettle安裝目錄下麵的lib文件夾下,然後重啟kettle的客戶端Spoon
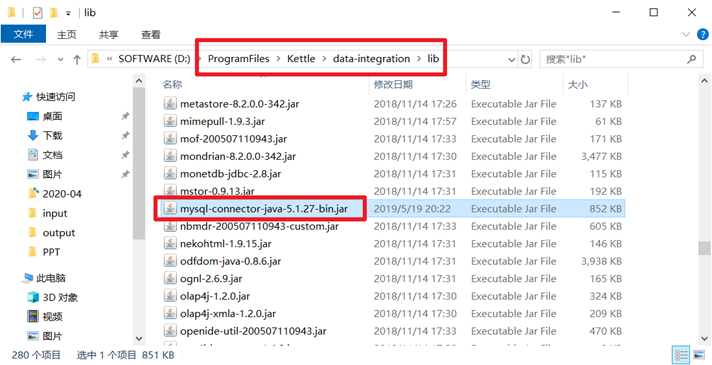
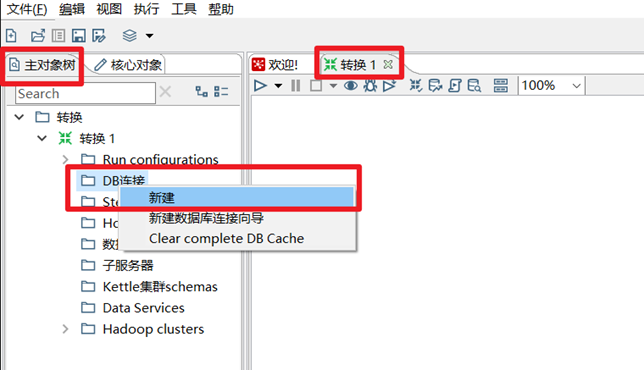
重啟Spoon客戶端以後,我們就可以創建對應的資料庫連接了,在轉換視圖的主對象樹目錄下,有個DB連接,右鍵然後選擇新建,在打開資料庫連接框里,填寫正確的資料庫信息,然後測試,測試無誤後,可以保存此資料庫連接。

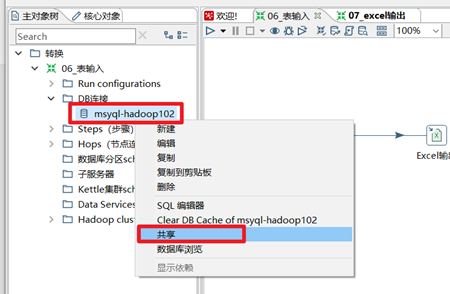
資料庫連接預設只對本轉換有效,換一個轉換以後,這個連接就沒法用了,還需要新建資料庫連接,所以我們需要將建好的這個資料庫連接進行共用下,共用以後,其他的轉換也能用我們提前建好的這個資料庫連接了。
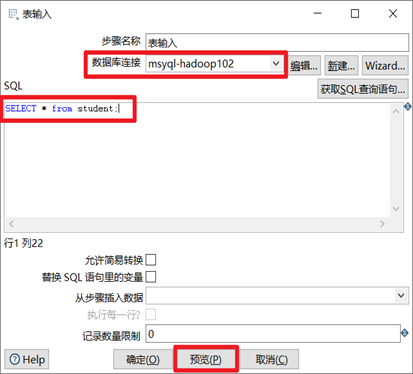
2)表輸入
創建好資料庫連接以後,我們就可以使用表輸入控制項了,雙擊表輸入控制項,選擇剛剛創建的資料庫連接,然後在SQL框里輸入合適的查詢語句,然後點擊預覽按鈕,看能否預覽到我們期望的數據。
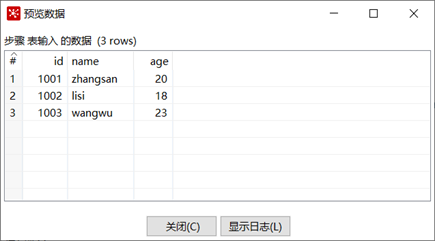
本章節任務:根據自己的集群環境,創建資料庫連接,然後使用表輸入控制項將student表的數據寫到excel中。
3.2 Kettle輸出控制項
輸出是轉換裡面的第二個分類,輸出控制項也是轉換中的第二大控制項,用來存儲數據。輸出是ETL裡面的L(Load),主要做數據載入的工作。
由於Kettle中自帶的輸出控制項比較多,本文只挑出開發中經常使用的幾個輸出控制項來進行講解,詳情如下圖。
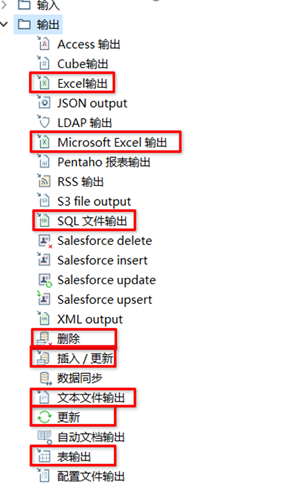
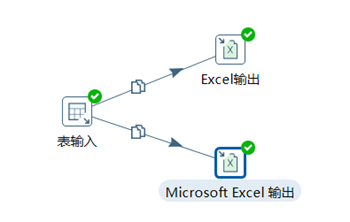
3.2.1 Excel輸出
Kettle中自帶了兩個Excel輸出,一個Excel輸出,另一個是Microsoft Excel輸出。
Excel輸出只能輸出xls文件(適合Excel2003),Microsoft Excel輸出可以輸出xls和xlsx文件(適合Excel2007及以後)
Excel輸出大家已經很熟悉了,本章不再贅述,接下來給大家講下Microsoft Excel輸出。
1) 選擇合適的擴展名
2) 點擊瀏覽,補全輸出文件的路徑已經文件名
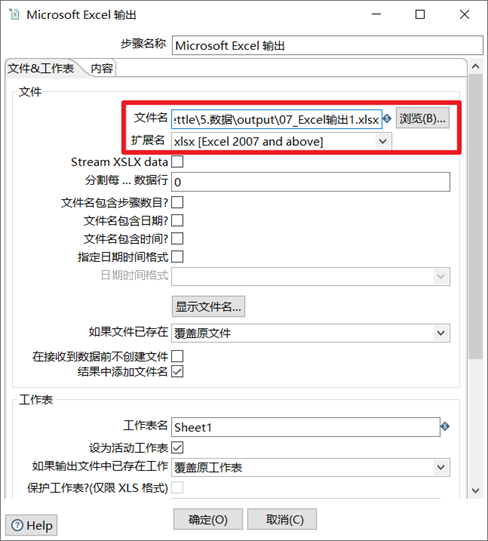
本章任務:使用表輸入控制項,將student表的數據,以複製的方式輸出到xls和xlsx文件中
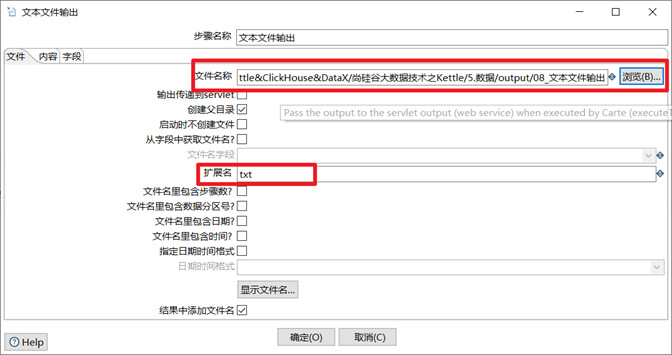
3.2.2 文本文件輸出
文本文件輸出控制項,顧名思義,這是一個能將數據輸出成文本的控制項,比較簡單,在企業裡面也比較常用。
1. 設置對應的目錄和文件名
2. 設置合適的擴展名,比如txt,csv等
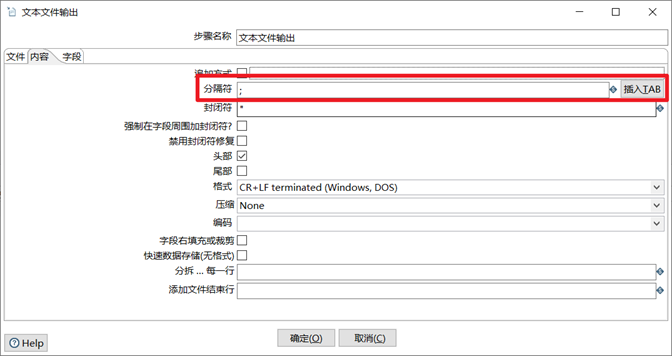
3. 在內容框里設置合適的分隔符,比如分號,逗號,TAB等
4. 在欄位框里獲取欄位,並且給每個欄位設置合適的格式

本章節任務:將student表的數據複製兩份,導出成txt和csv文件
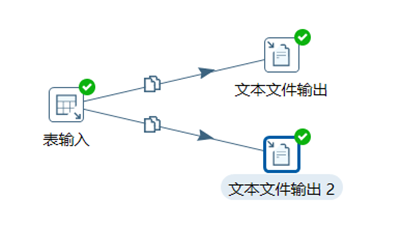
3.2.3 SQL文件輸出
SQL文件輸出一般跟表輸入做連接,然後將資料庫表的表結構和數據以sql文件的形式導出,然後做資料庫備份的這麼一個工作。
1. 選擇合適的資料庫連接
2. 選擇目標表
3. 勾選增加創建表語句和每個語句另起一行
4. 填寫輸出文件的路徑和文件名
5. 擴展名預設為sql,這個不需要更改
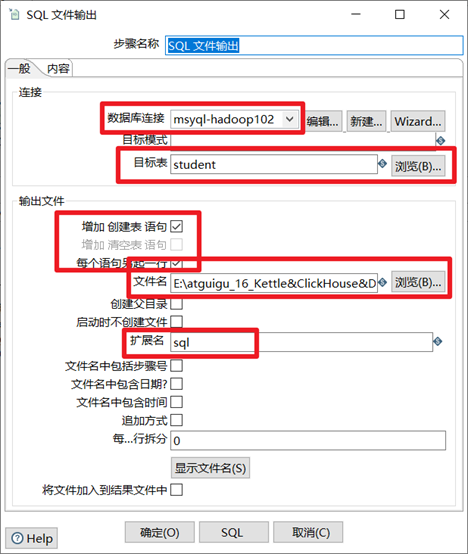
本章節任務:將student表的表結構和數據利用kettle導出成sql文件備份
3.2.4 表輸出
表輸出控制項可以將kettle數據行中的數據直接寫入到資料庫中的表中,企業里做ETL工作會經常用到此控制項。
1. 選擇合適的資料庫連接
2. 選擇目標表,目標表可以提前在資料庫中手動創建好,也可以輸入一個資料庫不存在的表,然後點擊下麵的SQL按鈕,利用kettle現場創建
3. 如果目標表的表結構和輸入的數據結構不一致,還可以自己指定資料庫欄位
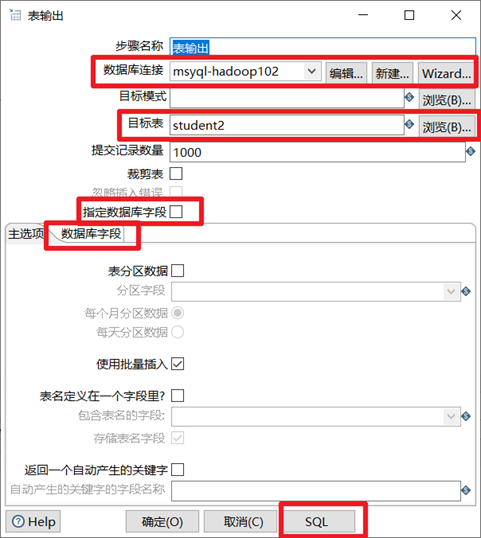
本章節任務:熟悉表輸出控制項,然後將student表的數據導入到student2表中,要求利用kettle現場創建student2表
3.2.5 更新&插入/更新
更新和插入/更新,這兩個控制項是kettle提供的將資料庫已經存在的記錄與數據流裡面的記錄進行對比的控制項。企業級ETL經常會用到這兩個控制項來進行資料庫更新的操作
兩者區別:
更新是將資料庫表中的數據和數據流中的數據做對比,如果不同就更新,如果數據流中的數據比資料庫表中的數據多,那麼就報錯。
插入/更新的功能和更新一樣,只不過優化了數據不存在就插入的功能,因此企業里更多的也是使用插入/更新。
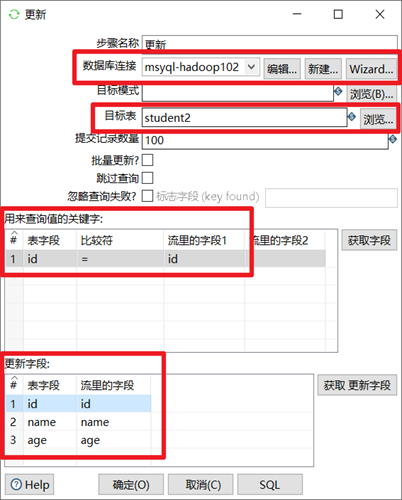
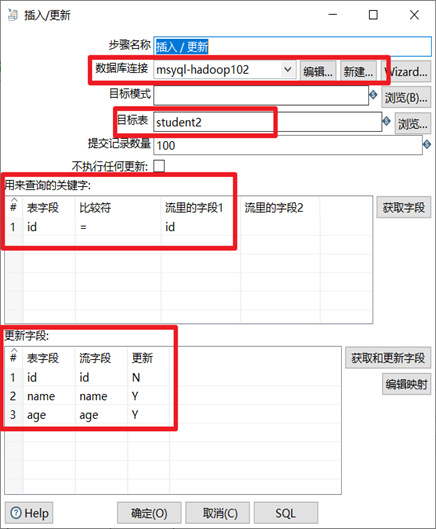
1. 選擇正確的資料庫連接
2. 選擇目標表
3. 輸入兩個表來進行比較的欄位,一般來說都是用主鍵來進行比較
4. 輸入要更新的欄位
本章節任務:手動修改下student表的數據(修改和新增),然後用修改後的數據和student2來進行對比,分別嘗試更新和插入/更新控制項的區別
3.2.6 刪除
刪除控制項可以刪除資料庫表中指定條件的數據,企業里一般用此控制項做資料庫表數據刪除或者跟另外一個表數據做對比,然後進行去重的操作。
1. 選擇資料庫連接
2. 選擇目標表
3. 設置數據流跟目標表要刪除數據的對應欄位
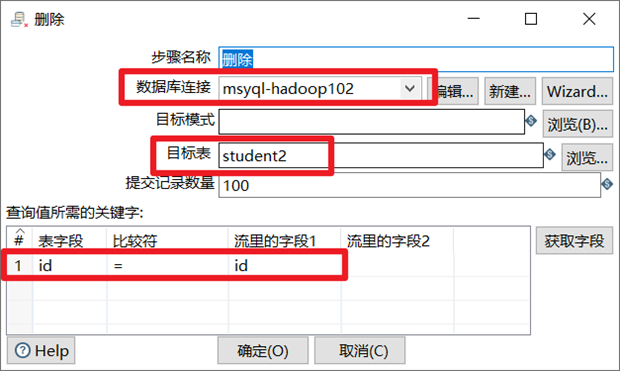
本章節任務:刪除student2表格中student表裡面已有的數據(按照student表對student2表數據進行去重)
3.3 Kettle轉換控制項
轉換控制項是轉換裡面的第四個分類,轉換控制項也是轉換中的第三大控制項,用來轉換數據。轉換是ETL裡面的T(Transform),主要做數據轉換,數據清洗的工作。ETL整個過程中,Transform的工作量最大,耗費的時間也比較久,大概可以占到整個ETL的三分之二。
由於Kettle中自帶的轉換控制項比較多,本文只挑出開發中經常使用的幾個轉換控制項來進行講解,詳情如下圖。

3.3.1 Concat fields
轉換控制項Concat fields,顧名思義,就是將多個欄位連接起來形成一個新的欄位。
本章節任務:將staff表的firstname和lastname拼接起來,形成name欄位,然後再將數據插入到新表emp中
提示:如果涉及到中文亂碼問題,請參考資料:Mysql中文亂碼問題.docx
3.3.2 值映射
值映射就是把欄位的一個值映射成其他的值。在數據質量規範上使用非常多,比如很多系統對應性別sex欄位的定義不同。所以我們需要利用此控制項,將同一個欄位的不同的值,映射轉換成我們需要的值。
1. 選擇映射的欄位
2. 還可以自定義映射完以後的新欄位名
3. 可以設置不匹配時的預設值
4. 設置映射的值
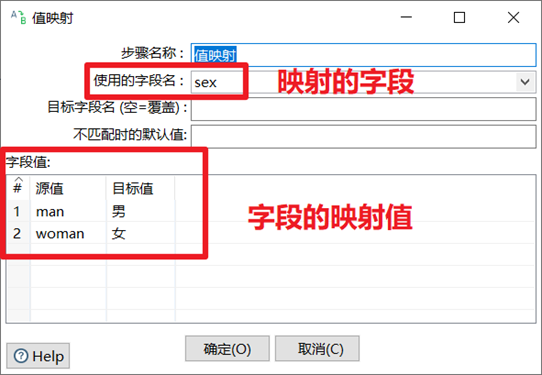
本章節任務:將staff表的sex欄位,映射成男or女,然後再插入到emp表中
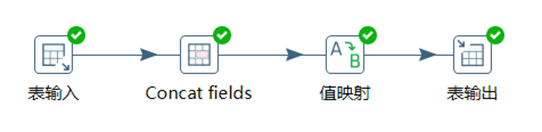
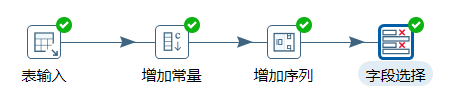
3.3.3 增加常量&增加序列
增加常量就是在本身的數據流裡面添加一列數據,該列的數據都是相同的值。
增加序列是給數據流添加一個序列欄位,可以自定義該序列欄位的遞增步長。
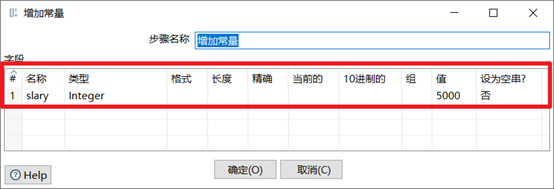
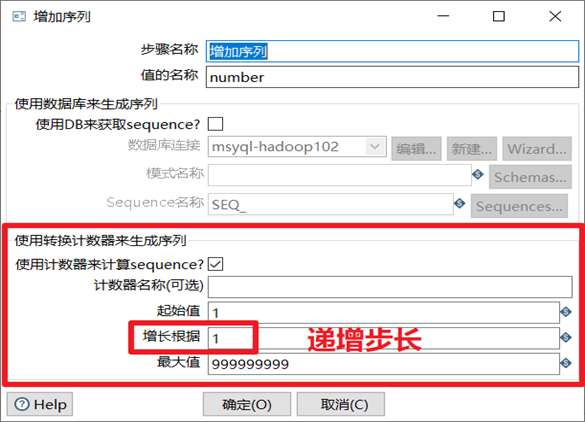
本章節任務:給表staff的數據加一列固定值slary和一個遞增的number序列,在控制台預覽下數據即可,不用輸出。
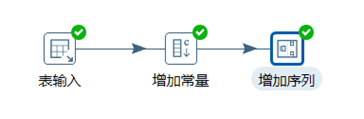
3.3.4 欄位選擇
欄位選擇是從數據流中選擇欄位、改變名稱、修改數據類型。
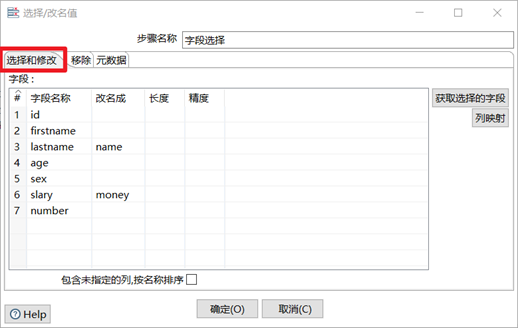
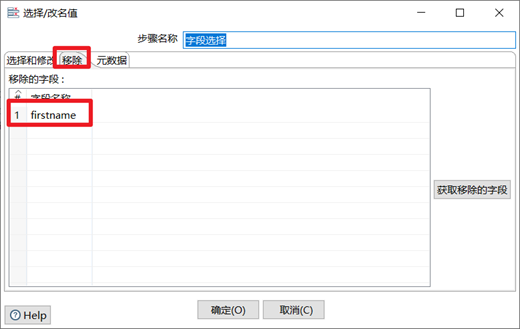
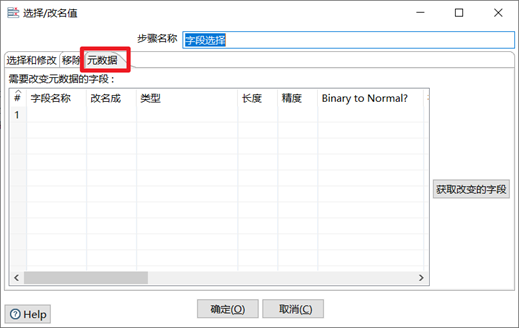
本章節任務:在上一章節的轉換之後,添加欄位選擇控制項,移除掉firstname欄位,並且將lastname重命名為name,將slary重命名為money,然後再次預覽數據,查看數據的變化
3.3.5 計算器
計算器是一個函數集合來創建新的欄位,還可以設置欄位是否移除(臨時欄位)。我們可以通過計算器裡面的多個計算函數對已有欄位進行計算,得出新欄位。
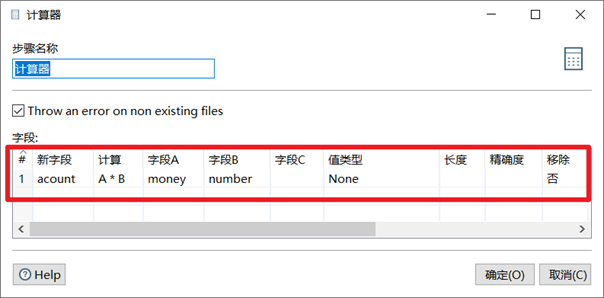
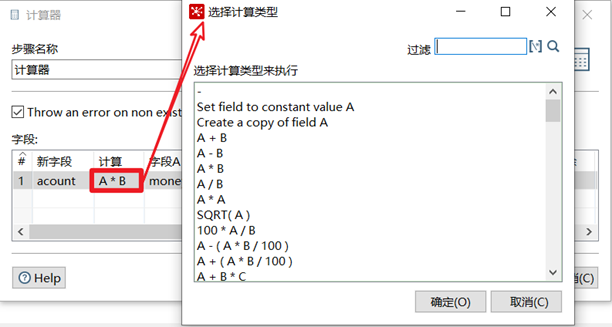
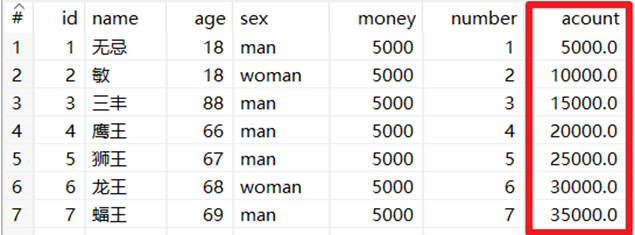
本章節任務:在上一節的任務基礎之上,添加計算器控制項對money和number欄位進行相乘,得出新欄位acount,然後預覽數據。
3.3.6 字元串剪切&替換&操作
轉換控制項中有三個關於字元串的控制項,分別是剪切字元串,字元串操作,字元串替換
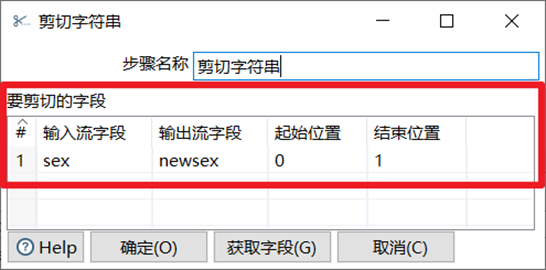
剪切字元串是指定輸入流欄位裁剪的位置剪切出新的欄位。
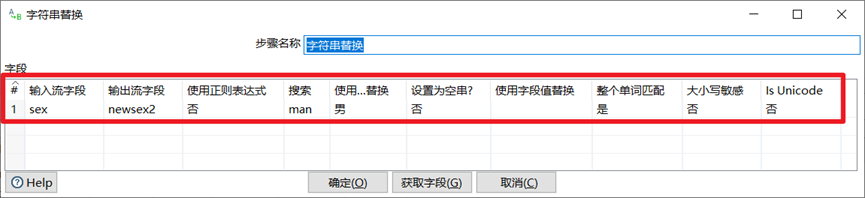
字元串替換是指定搜索內容和替換內容,如果輸入流的欄位匹配上搜索內容就進行替換生成新欄位。
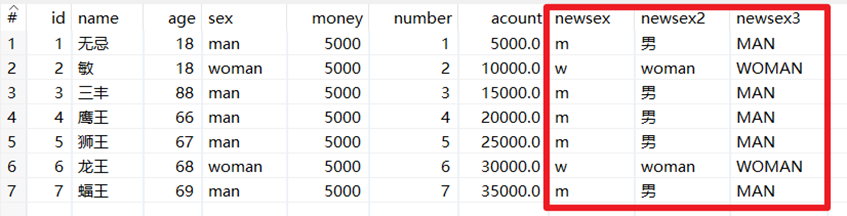
字元串操作是去除字元串兩端的空格和大小寫切換,並生成新的欄位。

本章節任務:在上一節任務之後,添加剪切字元串,字元串替換,字元串操作三個控制項,利用這三個控制項分別對sex欄位進行剪切,替換,操作(去空格,轉大小寫)

3.3.7 排序記錄&去除重覆記錄
去除重覆記錄是去除數據流裡面相同的數據行。但是此控制項使用之前要求必須先對數據進行排序,對數據排序用的控制項是排序記錄,排序記錄控制項可以按照指定欄位的升序或者降序對數據流進行排序。因此排序記錄+去除重覆記錄控制項常常配合組隊使用。
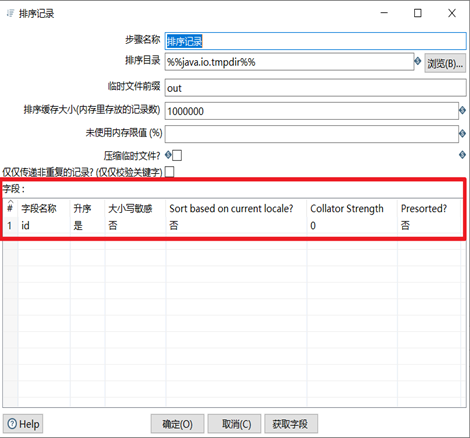
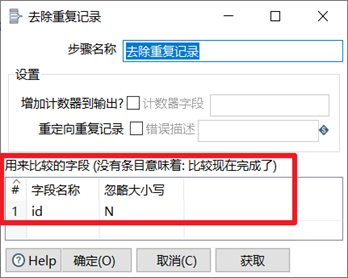
本章節任務:利用excel輸入控制項讀取input目錄下的06_去除重覆記錄.xlsx,然後對裡面重覆的數據進行按照id排序並去重
3.3.8 唯一行(哈希值)
唯一行(哈希值)就是刪除數據流重覆的行。此控制項的效果和(排序記錄+去除重覆記錄)的效果是一樣的,但是實現的原理不同。排序記錄+去除重覆記錄對比的是每兩行之間的數據,而唯一行(哈希值)是給每一行的數據建立哈希值,通過哈希值來比較數據是否重覆,因此唯一行(哈希值)去重效率比較高,也更建議大家使用。
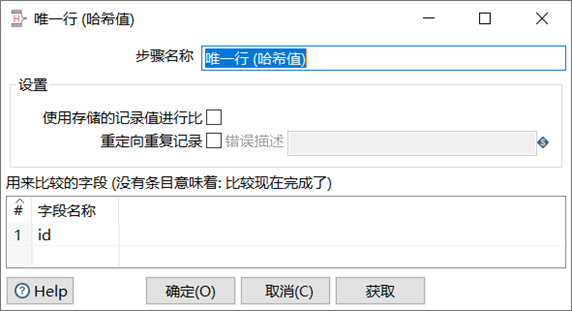
本章節任務:利用唯一行(哈希值)控制項對06_去除重覆記錄.xlsx去重,並且查看最後輸出的數據跟上個任務有何區別
3.3.9 拆分欄位
拆分欄位是把欄位按照分隔符拆分成兩個或多個欄位。需要註意的是,欄位拆分以後,原欄位就會從數據流中消失。
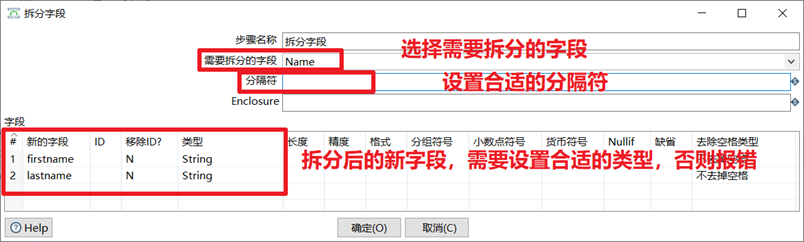
本章節任務:將07_拆分欄位.xlsx裡面的NBA球星的姓名,拆分成姓跟名。
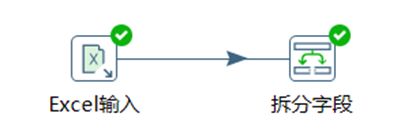
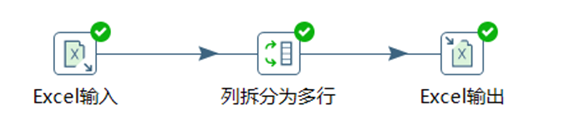
3.3.10 列拆分為多行
列拆分為多行就是把指定欄位按指定分隔符進行拆分為多行,然後其他欄位直接複製。具體效果如下圖:

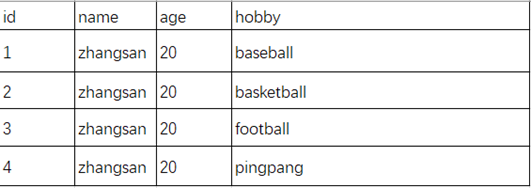
1. 選擇要拆分的欄位
2. 設置合適的分割符
3. 設置分割以後的新欄位名
4. 選擇是否輸出新數據的排列行號,行號是否重置
本章節任務:對08_列拆分為多行.xlsx的數據按照hobby欄位進行拆分為多行,然後將新數據輸出到excel文件中,查看數據。
3.3.11 行扁平化
行扁平化就是把同一組的多行數據合併成為一行,可以理解為列拆分為多行的逆向操作。但是需要註意的是行扁平化控制項使用有兩個條件:
- 使用之前需要對數據進行排序
- 每個分組的數據條數要保證一致,否則數據會有錯亂
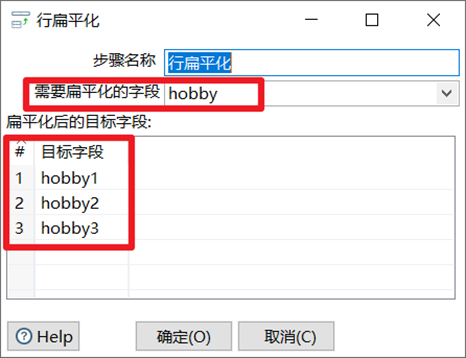
1. 選擇扁平化的欄位
2. 填寫目標欄位,欄位個數跟每個分組的數據一致
本章節任務:將09_行扁平化.xlsx的數據按照hobby欄位進行扁平化

3.3.12 列轉行
列轉行,顧名思義多列轉一行,就是如果數據一列有相同的值,按照指定的欄位,將其中一列的欄位內容變成不同的列,然後把多行數據轉換為一行數據的過程。具體效果如下圖:
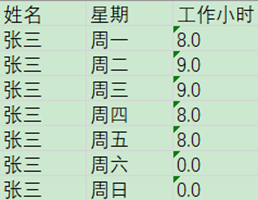

註意:列轉行之前數據流必須按照分組欄位進行排序,否則數據會錯亂!
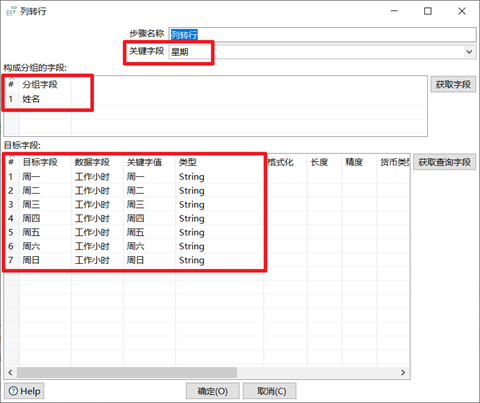
1. 關鍵欄位:從數據內容變成列名的欄位
2. 分組欄位:列轉行,轉變以後的分組欄位
3. 目標欄位:增加的列的列名欄位
4. 數據欄位:目標欄位的數據欄位
5. 關鍵字值:數據欄位查詢時的關鍵字,也可以理解為key
6. 類型:要給目標欄位設置合適的類型,否則會報錯
本章節任務:將input目錄下的10_列轉行.xlsx的數據進行列轉行,熟悉列轉行控制項的使用
3.3.13 行轉列
行轉列,一行轉多列,就是把數據欄位的欄位名轉換為一列,把數據行變為數據列。我們也可以簡單理解為行轉列控制項是列轉行控制項的逆向操作。具體如下圖:

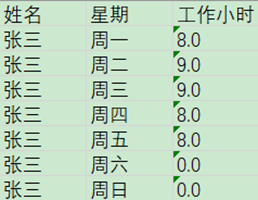
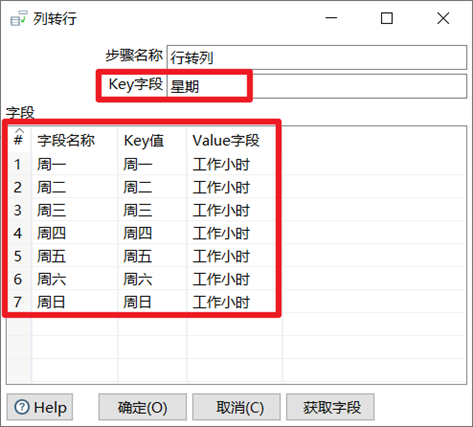
1. Key欄位:行轉列,生成的列名欄位名
2. 欄位名稱:原本數據流中的欄位名
3. Key值:Key欄位的值,這個是自己自定義的,一般都跟前面的欄位名稱一樣
4. Value欄位:對應的Key值的數據列的列名
本章節任務:將input目錄下的11_行轉列.xlsx用excel控制項輸入,然後行轉列,熟悉行轉列控制項的使用。
3.4 Kettle應用控制項
應用是轉換控制項裡面的第五個分類,這個分類下是Kettle給我們自帶的一些工具類
3.4.1 替換NULL值
替換NULL值,顧名思義就是將數據裡面的null值替換成其他的值,此控制項比較簡單,但是在企業裡面也會經常用到。
1. 可以選擇替換數據流中所有欄位的null值
2. 也可以選擇欄位,在下麵的欄位框裡面,根據不同的欄位,將null值替換成不同的值
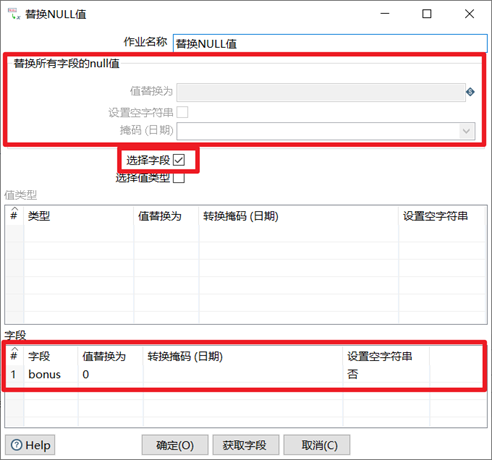
本章節任務:替換excel數據12_替換NULL值.xlsx的bonus列的null值為0
3.4.2 寫日誌
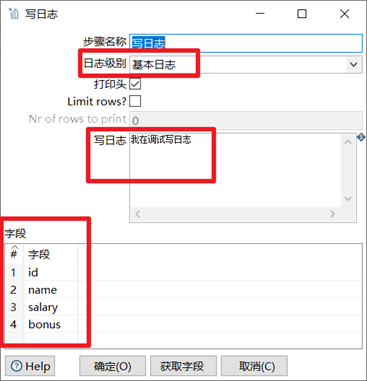
寫日誌控制項主要是調試的時候使用,此控制項可以將數據流的每行數據列印到控制台,方便我們調試整個程式。
1. 選擇日誌級別
2. 可以輸入自定義輸出的語句
3. 選擇要輸出列印的欄位
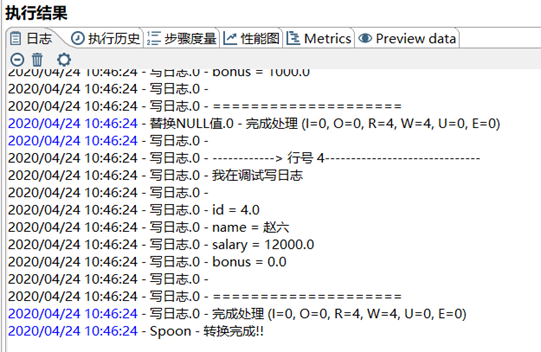
本章節任務:在上個任務的基礎之上,添加寫日誌控制項,在控制台輸出查看數據。
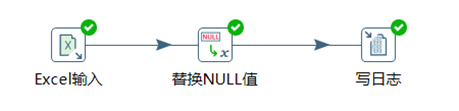
3.5 Kettle流程式控制件
流程是轉換裡面的第六個分類,流程分類下的控制項主要用來控制數據流程和數據流向。
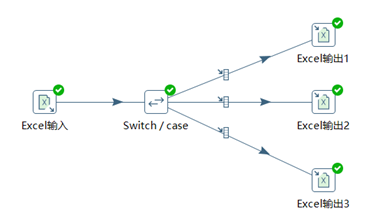
3.5.1 Switch/case
Switch/case控制項,最典型的數據分類控制項,可以利用某一個欄位的數據的不同的值,讓數據流從一路到多路。
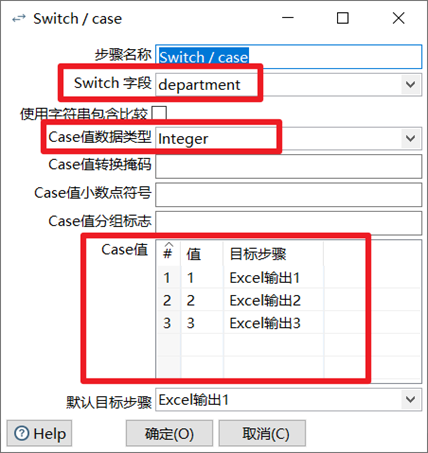
1. 選擇需要判斷的欄位
2. 選擇判斷欄位的值的類型
3. 填寫分類數據的判斷條件和目標步驟
本章節任務:將excel:13_Switch-Case.xlsx的數據按照部門欄位進行分類,將同一個部門的數據輸出到一個excel中
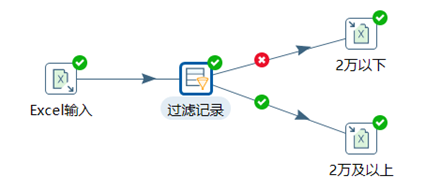
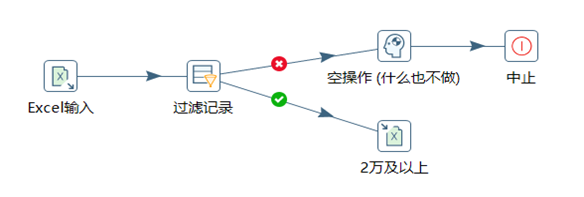
3.5.2 過濾記錄
和Switch/case做對比的話,過濾記錄相當於if-else,可以自定義輸入一個判斷條件,然後將數據流中的數據一路分為兩路。
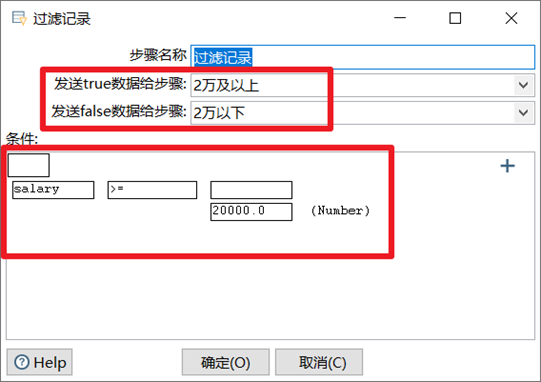
- 在下麵先填寫數據的判斷條件
- 然後再上面選擇下判斷條件為true或者false的輸出步驟
本章節任務:將excel:13_Switch-Case.xlsx的數據按照工資欄位進行判斷,將工資在20000及以上的數據輸出到一個excel中,將工資小於20000的輸出到另外一個excel中。
3.5.3 空操作
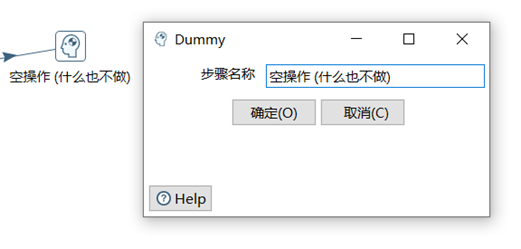
空操作,顧名思義就是什麼也不做,此控制項一般作為數據流的終點。
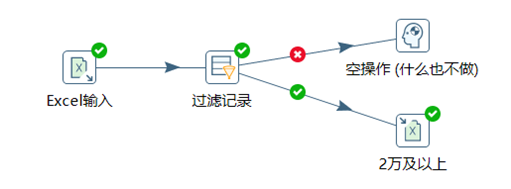
本章節任務:修改上節的轉換任務,將工資大於等於20000的數據輸出,小於20000的數據直接丟棄,熟悉空操作控制項的使用。
3.5.3 中止
中止是數據流的終點,如果有數據流到此控制項處,整個轉換程式將中止,並且在控制台輸出報錯信息。此控制項一般用來校驗數據,或者調試程式。
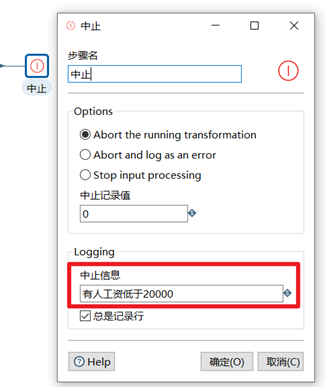
本章節任務:使用中止控制項判斷上節任務中是否有人的工資低於20000,如果發現有人的工資低於20000的話,中止程式,併在控制台輸出信息。
3.6 Kettle查詢控制項
查詢是轉換裡面的第九個分類,查詢控制項是用來查詢數據源裡面的數據,併合併到主數據流中。
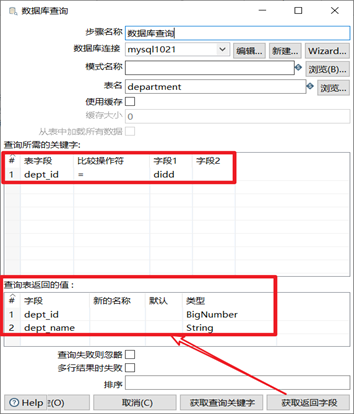
3.6.1 資料庫查詢
資料庫查詢就是從資料庫裡面查詢出數據,然後跟數據流中的數據進行左連接的一個過程。左連接的意思是數據流中原本的數據全部有,但是資料庫查詢控制項查詢出來的數據不一定全部會列出,只能按照輸入的匹配條件來進行關聯。
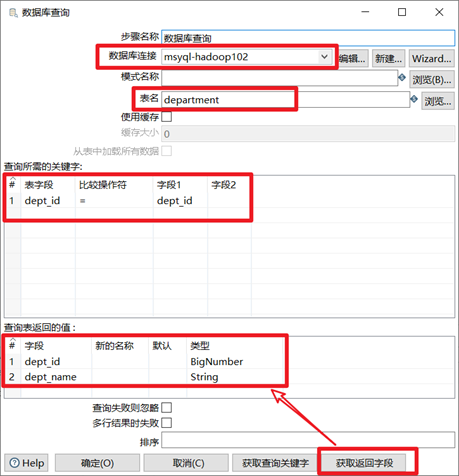
- 選擇合適的資料庫鏈接
- 輸入要去資料庫裡面查詢的表名
- 輸入兩個表進行左連接的連接條件
- 獲取返回欄位,得到查詢表返回的值
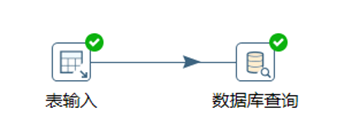
本章節任務:利用表輸入控制項獲取到staff表的數據,然後利用資料庫查詢控制項查詢到department表的數據,然後對兩個表按照dept_id欄位進行左連接,並預覽數據
3.6.2 流查詢
流查詢控制項就是查詢兩條數據流中的數據,然後按照指定的欄位做等值匹配。註意:流查詢在查詢前把數據都載入到記憶體中,並且只能進行等值查詢。
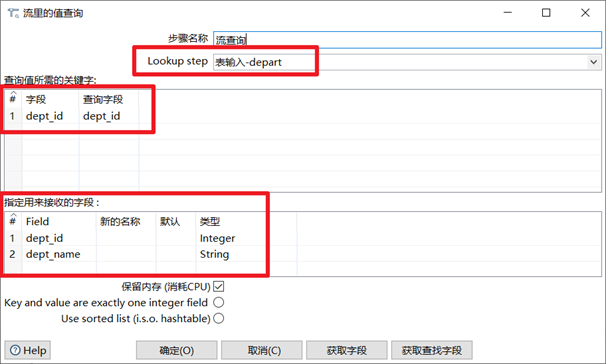
- 輸入查詢的數據流
- 輸入兩個流進行匹配的欄位(等值匹配)
- 輸入查詢出的欄位
本章節任務:用流查詢控制項,將staff和department的數據按照dept_id欄位進行關聯起來
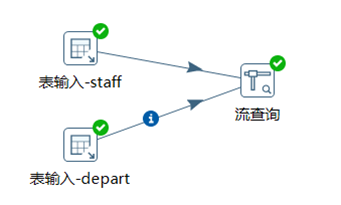
3.7 Kettle連接控制項
連接是轉換裡面的第十個分類,連接分類下的控制項一般都是將多個數據集通過關鍵字進行連接起來,形成一個數據集的過程。
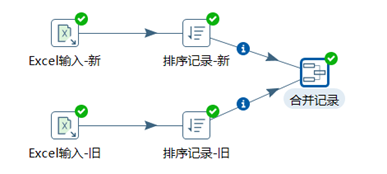
3.7.1 合併記錄
合併記錄是用於將兩個不同來源的數據合併,這兩個來源的數據分別為舊數據和新數據,該步驟將舊數據和新數據按照指定的關鍵字匹配、比較、合併。註意舊數據和新數據需要事先按照關鍵欄位排序,並且舊數據和新數據要有相同的欄位名稱。
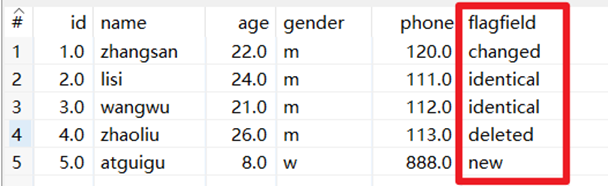
合併後的數據將包括舊數據來源和新數據來源里的所有數據,對於變化的數據,使用新數據代替舊數據,同時在結果里用一個標示欄位,來指定新舊數據的比較結果。
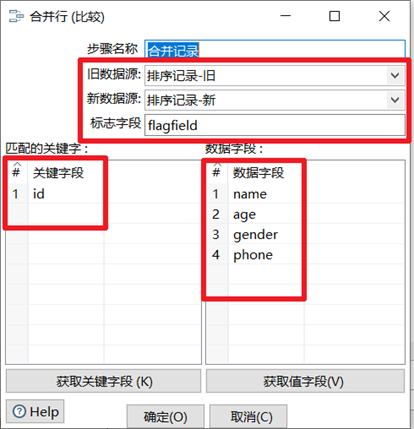
- 舊數據源:選擇舊數據來源的步驟
- 新數據源:選擇新數據來源的步驟
- 標誌欄位:設置標誌欄位的名稱,標誌欄位用於保存比較的結果,比較結果有下列幾種
① “identical” – 舊數據和新數據一樣
② “changed” – 數據發生了變化;
③ “new” – 新數據中有而舊數據中沒有的記錄
④ “deleted” –舊數據中有而新數據中沒有的記錄 - 關鍵欄位:用於定位判斷兩個數據源中的同一條記錄的欄位。
- 比較欄位:對於兩個數據源中的同一條記錄,指定需要比較的欄位
本章節任務:利用合併記錄控制項比較合併記錄-新舊excel的數據,並預覽數據,查看標誌欄位的內容
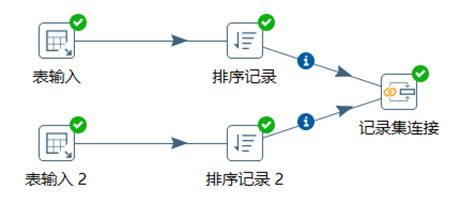
3.7.2 記錄集連接
記錄集連接可以對兩個步驟中的數據流進行左連接,右連接,內連接,外連接。此控制項功能比較強大,企業做ETL開發會經常用到此控制項,但是需要註意在進行記錄集連接之前,需要對記錄集的數據進行排序,並且排序的欄位還一定要選兩個表關聯的欄位,否則數據錯亂,出現null值。
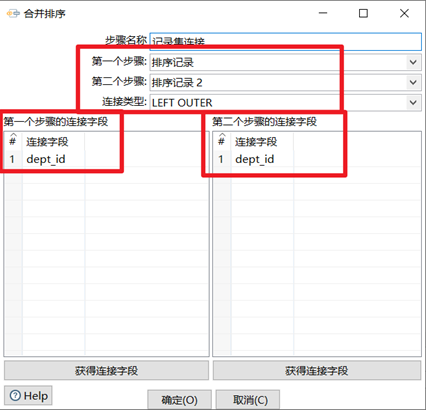
- 選擇需要連接的兩個數據流的步驟
- 選擇連接類型,一共有四個:INNER,LEFT OUTER,RIGHT OUTER,FULL OUTER
- 從兩個數據流步驟裡面選出連接欄位
本章節任務:使用記錄集連接控制項對資料庫表satff和department按照部門id分別進行內連接,左連接,右連接,外連接,查看數據的不同
註意:兩個表進行排序記錄的時候,排序的欄位一定要選擇部門id,否則數據會不正確
3.8 Kettle統計控制項
統計是轉換裡面的第十三個分類,統計控制項可以提供數據的採樣和統計功能。
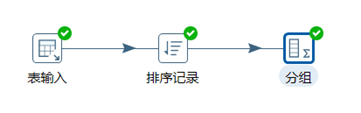
3.8.1 分組
分組控制項的功能類似於GROUP BY,可以按照指定的一個或者幾個欄位進行分組,然後其餘欄位可以按照聚合函數進行合併計算。註意,在進行分組之前,數據最好先進行排序。
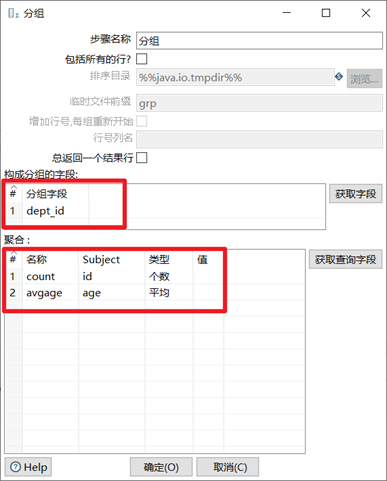
- 選擇分組欄位
- 給其餘欄位選擇合適的聚合函數進行計算
本章節任務:給表staff的數據按照部門進行分組,求出各部門人數以及各部門員工的平均年齡。
3.9 Kettle映射控制項
映射是轉換裡面的第十八個分類,映射可以用來定義子轉換,方便代碼封裝和重用。
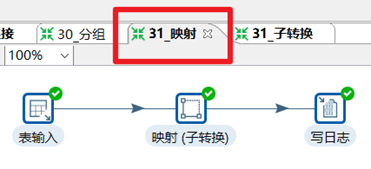
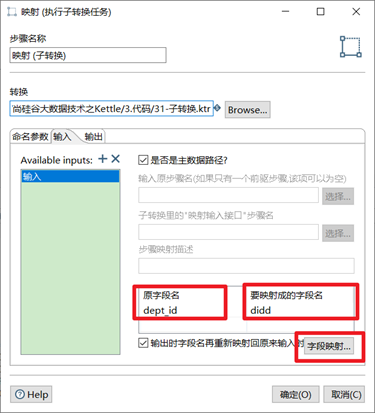
3.9.1 映射
映射(子轉換)是用來配置子轉換,對子轉換進行調用的一個步驟。
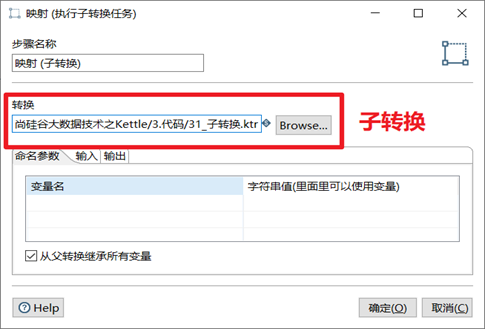
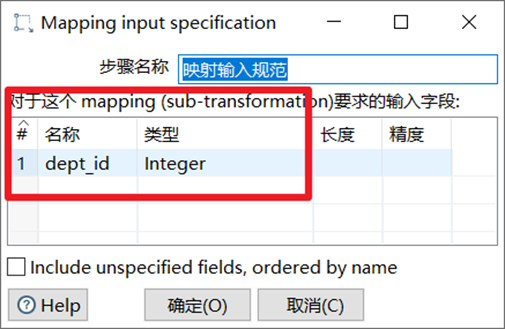
映射輸入規範是輸入欄位,由調用的轉換輸入。
映射輸出規範是向調用的轉換輸出所有列,不做任何處理。
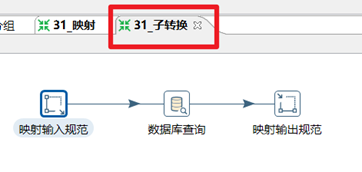
本章節任務:封裝一個子轉換能夠通過dept_id求出dept_name,然後使用另外一個轉換調用此子轉換,求出資料庫staff表id=3的員工的姓名,年齡,部門id,部門姓名,並輸出到控制台。
3.10 Kettle腳本控制項
腳本是轉換的第七個分類,腳本就是直接通過寫程式代碼完成一些複雜的操作。
3.10.1 執行SQL腳本
執行sql腳本控制項就是連接到資料庫裡面,然後執行自己寫的一些sql語句
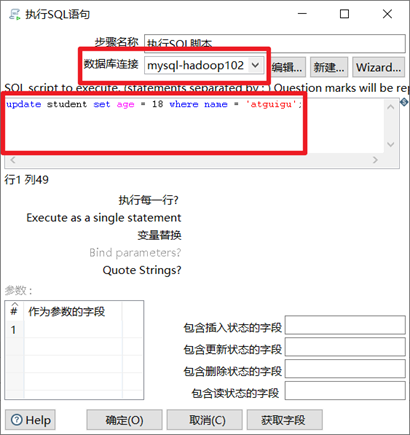
- 選擇合適的資料庫連接
- 填入要執行的sql語句
本章節任務:利用執行sql腳本控制項將student表數據的atguigu的年齡更新為18。
第4章 Kettle作業
4.1 作業簡介
大多數ETL項目都需要完成各種各樣的維護工作。例如,如何傳送文件;驗證資料庫表是否存在等等。而這些操作都是按照一定順序完成。因為轉換以並行方式執行,就需要一個可以串列執行的作業來處理這些操作。
一個作業包含一個或者多個作業項,這些作業項以某種順序來執行。作業執行順序由作業項之間的跳(job hop)和每個作業項的執行結果來決定。
4.1.1 作業項
作業項是作業的基本構成部分。如同轉換的步驟,作業項也可以使用圖標的方式圖形化展示。但是,作業項和轉換步驟有下麵幾點不同:
- 轉換步驟與步驟之間是數據流,作業項之間是步驟流。
- 轉換啟動以後,所有步驟一起並行啟動等待數據行的輸入,而作業項是嚴格按照執行順序啟動,一個作業項執行完以後,再執行下一個作業項。
- 在作業項之間可以傳遞一個結果對象(result object)。這個結果對象裡面包含了數據行,它們不是以數據流的方式來傳遞的。而是等待一個作業項執行完了,再傳遞個下一個作業項。
- 因為作業順序執行作業項,所以必須定義一個起點。有一個叫“開始”的作業項就定義了這個點。一個作業只能定一個開始作業項。
4.1.2 作業跳
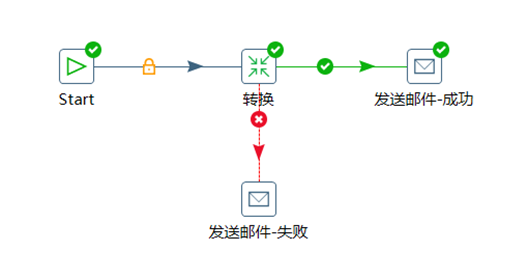
作業的跳是作業項之間的連接線,他定義了作業的執行路徑。作業里每個作業項的不同運行結果決定了做作業的不同執行路徑。作業跳一共分為下麵三種情況:
①無條件執行:不論上一個作業項執行成功還是失敗,下一個作業項都會執行。這是一種藍色的連接線,上面有一個鎖的圖標。

②當運行結果為真時執行:當上一個作業項的執行結果為真時,執行下一個作業項。通常在需要無錯誤執行的情況下使用。這是一種綠色的連接線,上面有一個對鉤號的圖標。

③當運行結果為假時執行:當上一個作業項的執行結果為假或者沒有成功執行是,執行下一個作業項。這是一種紅色的連接線,上面有一個紅色的停止圖標。

在圖標上單擊就可以對跳進行設置。
4.2 作業初體驗
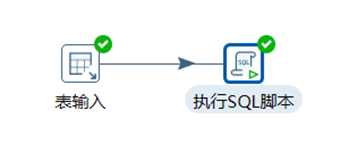
作業案例:將3.10.1章節的轉換嵌入作業中執行,執行成功或者失敗都發送郵件提醒
1) 點擊左上角的文件,新建一個作業
2) 按照下圖設置作業項和作業跳
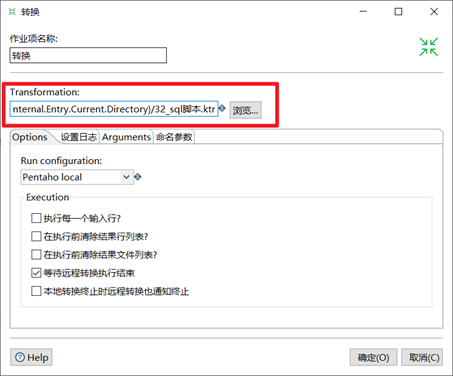
3) 轉換作業項設置,選擇要嵌入的轉換文件
4) 發送郵件作業項設置,
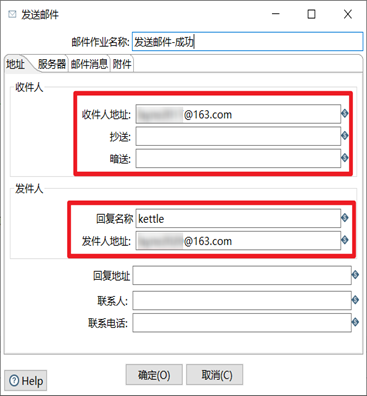
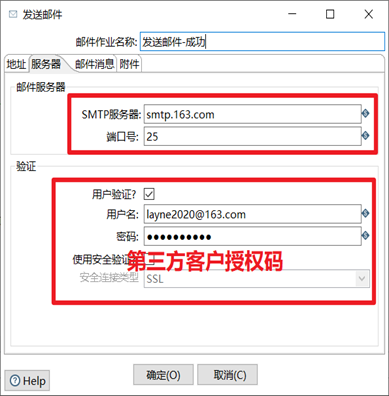
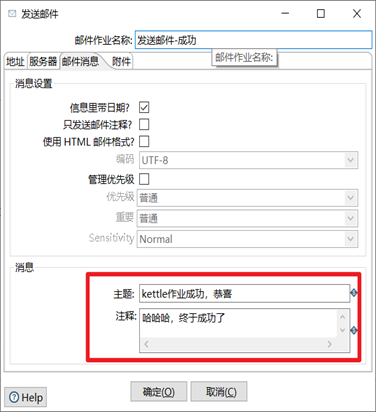
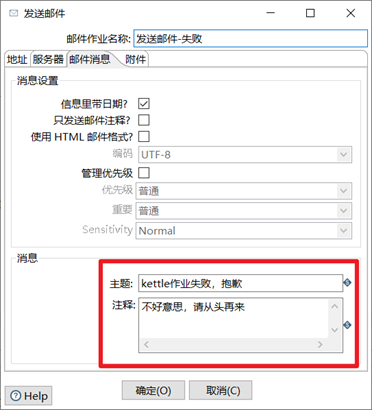
5) 分別嘗試作業執行成功和失敗,查看kettle發送的郵件信息
第5章 Kettle使用案例
5.1 轉換案例
案例一:把stu1的數據按id同步到stu2,stu2有相同id則更新數據
(1)在mysql中創建兩張表
mysql> create database kettle;
mysql> use kettle;
mysql> create table stu1(id int,name varchar(20),age int);
mysql> create table stu2(id int,name varchar(20));
(2)往兩張表中插入一些數據
mysql> insert into stu1 values(1001,'zhangsan',20),(1002,'lisi',18), (1003,'wangwu',23);
mysql> insert into stu2 values(1001,'wukong');
(3)在kettle中新建轉換
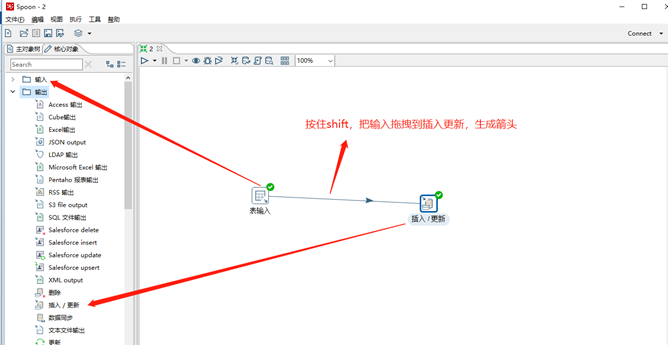
(4)分別在輸入和輸出中拉出表輸入和插入/更新
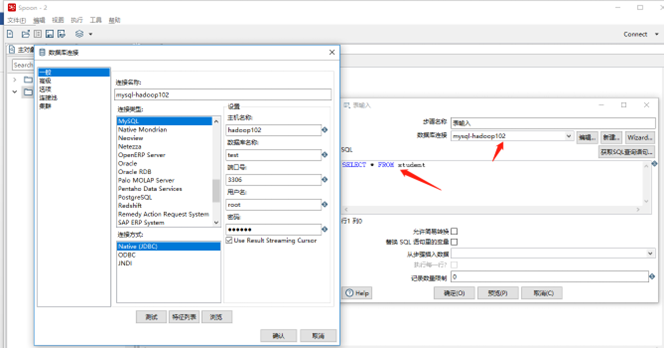
(5)雙擊表輸入對象,填寫相關配置,測試是否成功
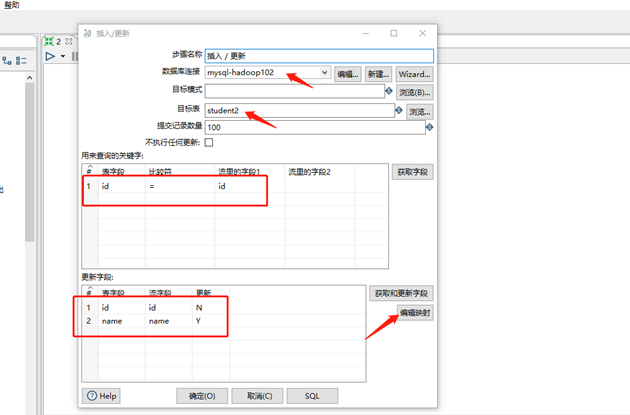
(6)雙擊 更新/插入對象,填寫相關配置
(7)保存轉換,啟動運行,去mysql表查看結果
註意:如果需要連接mysql資料庫,需要先將mysql的連接驅動包複製到kettle的根目錄下的lib目錄中,否則會報錯找不到驅動。

5.2 作業案例
案例二:使用作業執行上述轉換,並且額外在表stu2中添加一條數據,整個作業運行成功的話發郵件提醒
(1)新建一個作業
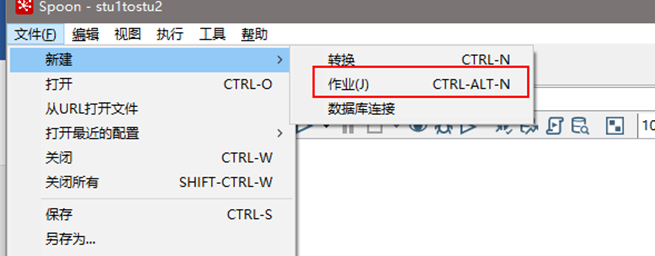
(2) 按圖示拉取組件
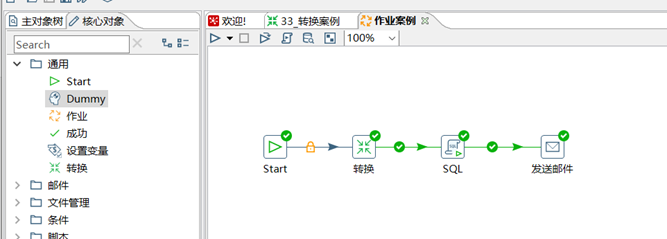
(3)雙擊Start編輯Start
(4)雙擊轉換,選擇案例1保存的文件
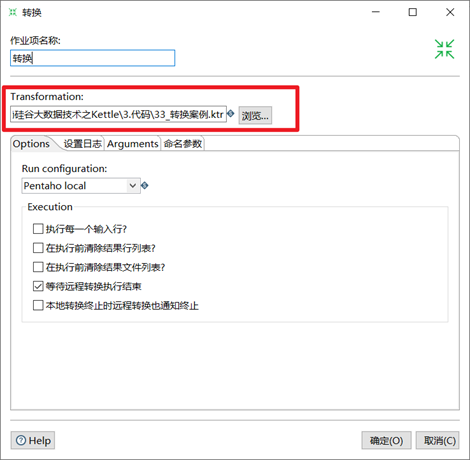
(5)雙擊SQL,編輯SQL語句
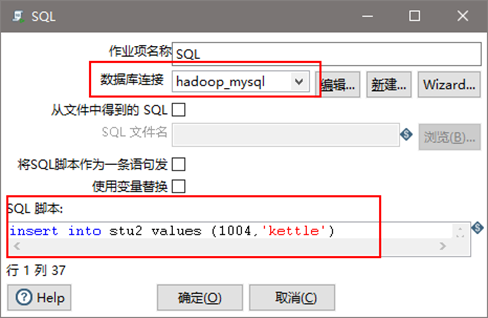
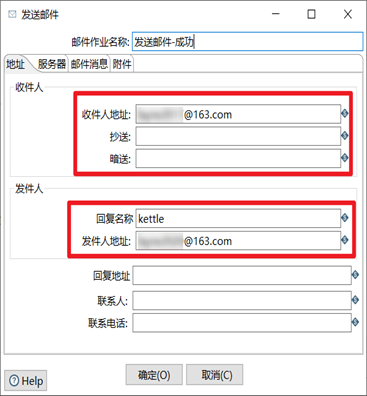
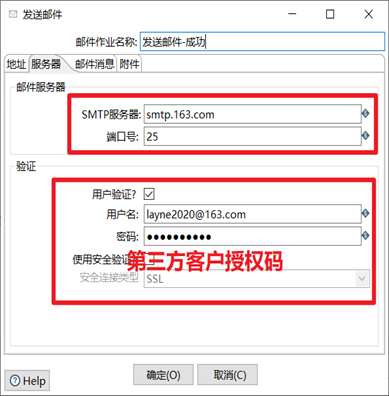
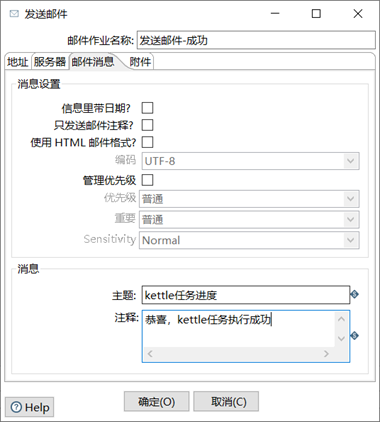
(6)雙擊發送郵件,編輯發送郵件的設置信息
(7)保存作業並執行,然後去mysql查看結果和郵件信息
5.3 Hive-HDFS案例
案例三:將hive表的數據輸出到hdfs
(1)因為涉及到hive和hbase的讀寫,需要先修改相關配置文件。
修改kettle安裝目錄下的data-integration\plugins\pentaho-big-data-plugin下的plugin.properties,設置active.hadoop.configuration=hdp26,並將如下配置文件拷貝到data-integration\plugins\pentaho-big-data-plugin\hadoop-configurations\hdp26下
(2)啟動hdfs,yarn,zookeeper,hbase集群的所有進程,啟動hiveserver2服務
[atguigu@hadoop102 ~]$ hadoop.sh start //自己寫的hadoop啟動腳本
[atguigu@hadoop102 ~]$ zk.sh start //自己寫的zookeeper啟動腳本
[atguigu@hadoop102 ~]$ /opt/module/hbase-1.3.1/bin/start-hbase.sh
[atguigu@hadoop102 ~]$ /opt/module/hive/bin/hiveserver2
(3)進入beeline,查看10000埠開啟情況
[atguigu@hadoop102 ~]$ /opt/module/hive/bin/beeline
Beeline version 1.2.1 by Apache Hive
beeline> !connect jdbc:hive2://hadoop102:10000(回車)
Connecting to jdbc:hive2://hadoop102:10000
Enter username for jdbc:hive2://hadoop102:10000: atguigu(輸入atguigu)
Enter password for jdbc:hive2://hadoop102:10000:(直接回車)
Connected to: Apache Hive (version 1.2.1)
Driver: Hive JDBC (version 1.2.1)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://hadoop102:10000>(到了這裡說明成功開啟10000埠)
(4)創建兩張表dept和emp
CREATE TABLE dept(deptno int, dname string,loc string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t';
CREATE TABLE emp(
empno int,
ename string,
job string,
mgr int,
h


