
大數據時代,各行各業對數據採集的需求日益增多,網路爬蟲的運用也更為廣泛,越來越多的人開始學習網路爬蟲這項技術,K哥爬蟲此前已經推出不少爬蟲進階、逆向相關文章,為實現從易到難全方位覆蓋,特設【0基礎學爬蟲】專欄,幫助小白快速入門爬蟲,本期為自動化工具 Pyppeteer 的使用。 概述 前兩期文章中已 ...

大數據時代,各行各業對數據採集的需求日益增多,網路爬蟲的運用也更為廣泛,越來越多的人開始學習網路爬蟲這項技術,K哥爬蟲此前已經推出不少爬蟲進階、逆向相關文章,為實現從易到難全方位覆蓋,特設【0基礎學爬蟲】專欄,幫助小白快速入門爬蟲,本期為自動化工具 Pyppeteer 的使用。
概述
前兩期文章中已經介紹到了 Selenium 與 Playwright 的使用方法,它們的功能都非常強大。而本期要講的 Pyppeteer 與 Playwright 一致,都可以作為 Selenium 的替代者來使用。且與 Playwright 相比,Pyppeteer 的使用更加簡單。
Pyppeteer 的使用
介紹
在上上期文章中,我們介紹了 Selenium 隱藏特征的方法,其中使用到了 stealth.min.js 文件。在介紹文件的來源時我們提到了 Puppeteer,Puppeteer是一個基於 Node.js 的自動化工具。而這期要將的 Pyppeteer 就是 Puppeteer 的 Python 版。
Pyppeteer 是一個使用 Python 語言封裝的 Google Chrome 瀏覽器的非官方 API。它可以用來進行自動化測試、網站爬蟲和數據抓取等工作。
Pyppeteer 的底層是通過調用 Chrome 瀏覽器的 DevTools Protocol 介面來實現的。DevTools Protocol 是一個基於 WebSocket 協議的遠程調試介面,可以讓開發者控制和檢查 Chrome 瀏覽器的行為。Pyppeteer 利用這個介面實現了對 Chrome 瀏覽器的完全控制,包括載入頁面、模擬用戶操作、獲取頁面內容等等。
Pyppeteer 支持 Python 3.6 及以上版本,並且可以在 Windows、macOS 和 Linux 等操作系統上運行。它提供了簡單易用的 API,可以方便地模擬用戶在瀏覽器上的操作,例如點擊鏈接、填寫表單、觸發事件等等。同時,它也支持對瀏覽器的調試、截屏、PDF 導出等高級功能。
Pyppeteer 的使用方式與其他 Python 庫類似,可以通過 pip 包管理器進行安裝。除了 Pyppeteer 本身外,還需要安裝 asyncio 庫和一個相容的 Chrome 瀏覽器版本。在安裝完成後,可以通過 Python 代碼來控制瀏覽器的行為,實現各種自動化測試或數據抓取的任務。
安裝
Pyppeteer 的安裝與 Playwright 相似。
Pyppeteer 採用了async機制,所以必須使用Python 3.5及以上版本。
首先使用 pip 安裝 Pyppeteer 包:
pip install pyppeteer
安裝完成後可以選擇執行 pyppeteer-install 下載用於 pyppeteer 的 chromium,這一步可以省略,因為第一次運行 Pyppeteer 時會自動檢測是否安裝了 chromium 瀏覽器,如果沒有安裝程式會自動進行安裝配置。
使用
前兩期文章中介紹到了 Selenium 與 Playwright 庫的使用方法,因為自動化庫的使用大同小異,所以這裡只介紹 Pyppeteer 中比較特殊的方法
Pyppeteer 基於非同步實現,所以它支持非同步操作。
啟動
以百度熱搜榜為例:
import asyncio
from pyppeteer import launch
async def main():
browser = await launch(headless=False)
page = await browser.newPage()
await page.goto('https://top.baidu.com/board?tab=realtime')
await browser.close()
asyncio.get_event_loop().run_until_complete(main())
示例代碼中使用 launch 方法創建了一個瀏覽器對象 browser ,設置了 headless=False 來關閉無頭模式,這一行代碼的作用相當於啟動一個瀏覽器,await的作用就是等待瀏覽器啟動完畢。
創建完瀏覽器後,使用到了 newPage 方法,創建了一個 Page 對象,這一步相當於打開了一個新的標簽頁,通過 await 等待標簽頁創建完畢,然後調用 goto 方法打開目標網址,最後使用 close 方法關閉瀏覽器。
launch詳解
launch 方法用於啟動瀏覽器進程並返回瀏覽器實例,它包含了多個參數:
| 參數 | 描述 |
|---|---|
ignoreHTTPSErrors(bool) |
是否忽略HTTPS錯誤。預設為 False |
headless(bool) |
是否開啟無頭模式。預設為True |
executablePath (str) |
可執行文件的路徑,設置該參數可以指定已有的 Chrome 或 Chromium 瀏覽器。 |
slowMo (int | float) |
傳入指定時間(毫秒),用於延緩 Pyppeteer 的一些模擬操作。 |
args (List [str]) |
傳遞給瀏覽器的額外參數。 |
dumpio(bool) |
是否將 Pyppeteer 的輸出信息傳給 process.stdout和process.stderr。預設為False。 |
userDataDir (str) |
用戶數據文件夾。 |
env(dict) |
瀏覽器環境。預設與 Python 進程相同。 |
devtools(bool) |
是否為每個標簽頁打開 DevTools 面板,預設為False,如果該參數為 True,則 headless 會被強制設置為 False。 |
logLevel(int | str) |
日誌級別。預設值與根記錄器相同。 |
autoClose(bool) |
腳本完成時自動關閉瀏覽器進程。預設為True。 |
loop(asyncio.AbstractEventLoop) |
事件迴圈。 |
禁用提示條
與 Selenium 一樣,Pyppeteer 控制瀏覽器時會提示 Chrome 正受到自動測試軟體的控制。可以通過 設置 launch 方法中的 args 參數來關閉提示。
browser = await launch(headless=False, args=['--disable-infobars'])
用戶數據持久化
自動化工具如 Selenium 、Playwright 都有一個特征,就是每一次運行的時候創建的都是一個全新的瀏覽器,它不會記錄用戶之前的行為。如第一次運行時我登錄了某個網站,而第二次運行時再次進入該網站時依舊需要登錄。這是因為自動化工具沒有記錄用戶行為信息。Pyppeteer 中,如果需要記錄用戶的行為信息,可以通過設置 launch 方法中的 userDataDir 方法來實現。
browser = await launch(headless=False, args=['--disable-infobars'], userDataDir='./userdata')
設置了用戶數據文件夾後運行代碼,會生成一個 userdata 文件夾,其中就存儲著用戶上次控制瀏覽器時記錄的一些行為數據。
執行 JS 語句
import asyncio
from pyppeteer import launch
async def main():
browser = await launch(headless=False)
page = await browser.newPage()
await page.goto('https://top.baidu.com/board?tab=realtime')
dimensions = await page.evaluate('''() => {
return {
width: document.documentElement.clientWidth,
height: document.documentElement.clientHeight,
deviceScaleFactor: window.devicePixelRatio,
}
}''')
print(dimensions)
await browser.close()
# {'width': 783, 'height': 583, 'deviceScaleFactor': 1}
通過調用 Page 對象下的 evaluate 方法可以執行一段 JS 語句。
反檢測
Pyppeteer 的反檢測方式與 Selenium 和 Playwright 有些區別,但是思想是一樣的。
首先需要安裝 pyppeteer_stealth 庫,它的作用就是用來隱藏特征。
pip install pyppeteer_stealth
以無頭模式為例:
import asyncio
from pyppeteer import launch
from pyppeteer_stealth import stealth
async def main():
browser = await launch()
page = await browser.newPage()
# 隱藏特征
await stealth(page)
await page.goto('https://bot.sannysoft.com/')
await page.screenshot(path='page.png')
await browser.close()
asyncio.get_event_loop().run_until_complete(main())
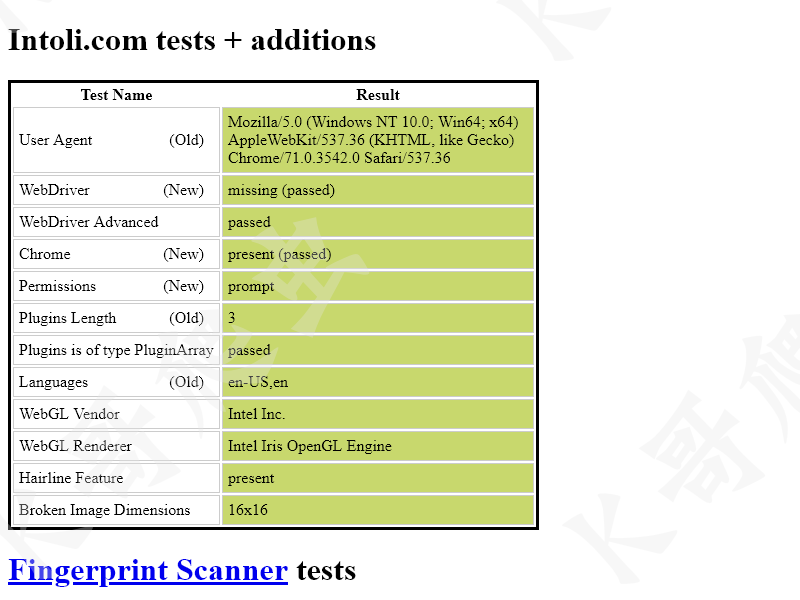
隱藏特征前:

隱藏特征後:
等待
waitForSelector :等待符合條件的節點載入完成
waitForFunction :等待某個 JavaScript 方法執行完畢或返回結果
waitForRequest :等待某個特定的請求發出
waitForResponse :等待某個特定請求對應的響應
waitForNavigation :等待頁面跳轉,如果頁面載入失敗則拋出異常
waitFor :通用等待
waitForXpath :等待符合 Xpath 的節點載入出來
選擇器
Pyppeteer 提供了一些比較有意思的選擇器方法。
J() :返回匹配到的第一個節點,等同於 querySelector 方法。
JJ() :返回匹配到的所有節點,等同於 querySelectorAll 方法。
JJeval() :執行 JS 腳本並返回一個 JSON 對象,等同於 querySelectorAllEval 方法。
Jeval() :執行 JS 腳本並返回執行結果,等同於 querySelectorEval 方法。
Jx() :通過 Xpath 匹配符合條件的內容,等同於 xpath 方法。
import asyncio
from pyppeteer import launch
async def main():
browser = await launch(headless=False)
page = await browser.newPage()
await page.goto('https://top.baidu.com/board?tab=realtime')
# 等待元素載入
await page.waitForXPath('//div[@class="c-single-text-ellipsis"]')
element_j = await page.J('.c-single-text-ellipsis')
element_jj = await page.JJ('.c-single-text-ellipsis')
# 列印元素的文本信息
print(await (await element_j.getProperty('textContent')).jsonValue())
for element in element_jj:
# 列印元素的文本信息
print(await (await element.getProperty('textContent')).jsonValue())
await browser.close()
asyncio.get_event_loop().run_until_complete(main())
"""
運行結果:
青年強則國家強
青年強則國家強
烏代表舉自家國旗挑釁暴揍俄代表
英王加冕禮彩排:黃金鑽石馬車亮眼
平凡崗位上的奮鬥故事
俞敏洪建議24節氣都放假
7人吃自助4小時炫300多個螃蟹
.
.
.
"""
總結
Pyppeteer 類似於輕量級的 Playwright ,它使用起來更加簡單,且 Pyppeteer 與 Playwright 一樣都支持非同步,性能方面也比較強。缺點就是它基於 Chromium 內核,資源消耗比較大,不支持其它瀏覽器,而且 Pyppeteer 的作者近年來都沒對該庫進行維護,導致存在一些 bug。



