
大數據時代,各行各業對數據採集的需求日益增多,網路爬蟲的運用也更為廣泛,越來越多的人開始學習網路爬蟲這項技術,K哥爬蟲此前已經推出不少爬蟲進階、逆向相關文章,為實現從易到難全方位覆蓋,特設【0基礎學爬蟲】專欄,幫助小白快速入門爬蟲,本期為自動化工具 playwright 的使用。 概述 上期文章中講 ...

大數據時代,各行各業對數據採集的需求日益增多,網路爬蟲的運用也更為廣泛,越來越多的人開始學習網路爬蟲這項技術,K哥爬蟲此前已經推出不少爬蟲進階、逆向相關文章,為實現從易到難全方位覆蓋,特設【0基礎學爬蟲】專欄,幫助小白快速入門爬蟲,本期為自動化工具 playwright 的使用。
概述
上期文章中講到了自動化工具 Selenium 的基本使用方法,也介紹了 Selenium 的優缺點。Selenium的功能非常強大,支持所有現代瀏覽器。但是 Selenium 使用起來十分不方便,我們需要提前安裝好瀏覽器,然後下載對應版本的驅動文件,當瀏覽器更新後驅動文件也得隨之更新。如果想要大規模且長期的採集數據,那麼部署 Selenium 時環境配置會是一個大問題。因此本期我們將介紹一款更加好用的自動化工具 Playwright 。
Playwright 的使用
介紹
Playwright是一個用於自動化Web瀏覽器測試和Web數據抓取的開源庫。它由Microsoft開發,支持Chrome、Firefox、Safari、Edge和WebKit瀏覽器。Playwright的一個主要特點是它能夠在所有主要的操作系統(包括Windows、Linux和macOS)上運行,並且它提供了一些強大的功能,如跨瀏覽器測試、支持無頭瀏覽器、並行執行測試、元素截圖和模擬輸入等。它主要有以下優勢:
- 相容多個瀏覽器,而且所有瀏覽器都使用相同的API。
- 速度快、穩定性高,即使在大型、複雜的Web應用程式中也可以運行。
- 支持無頭瀏覽器,因此可以在沒有可見界面的情況下運行測試,從而提高測試效率。
- 提供了豐富的 API,以便於執行各種操作,如截圖、模擬輸入、攔截網路請求等。
安裝
使用 Playwright 需要 Python版本在3.7以上。
安裝 Playwright 可以直接使用 pip 工具:
pip install playwright
安裝完成後需要進行初始化操作,安裝所需的瀏覽器。
playwright install
執行上述指令時,Playwright 會自動安裝多個瀏覽器(Chromium、Firefox 和 WebKit)並配置驅動,所以速度較慢。
使用
Playwright 支持同步與非同步兩種模式,這裡分開來進行講解。
同步
使用 Playwright 時可以選擇啟動安裝的三種瀏覽器(Chromium、Firefox 和 WebKit)中的一種。
from playwright.sync_api import sync_playwright
# 調用sync_playwright方法,返回瀏覽器上下文管理器
with sync_playwright() as p:
# 創建谷歌瀏覽器示例,playwright預設啟動無頭模式,設置headless=False,即關閉無頭模式
browser = p.chromium.launch(headless=False)
# 新建選項卡
page = browser.new_page()
# 跳轉到目標網址
page.goto("http://baidu.com")
# 獲取頁面截圖
page.screenshot(path='example.png')
# 列印頁面的標題,也就是title節點中的文本信息
print(page.title())
# 關閉瀏覽器
browser.close()
# 輸出:百度一下,你就知道
可以看到,Playwright 的使用也比較簡單,語法比較簡潔,而且瀏覽器的啟動速度以及運行速度也很快。
非同步
非同步代碼的編寫方法與同步基本一致,區別在於同步調用的是 sync_playwright,非同步調用的是 async_playwright。最終運行效果與同步一致。
import asyncio
from playwright.async_api import async_playwright
async def main():
async with async_playwright() as p:
browser = await p.chromium.launch(headless=False)
page = await browser.new_page()
await page.goto("http://baidu.com")
# 列印網頁源代碼
print(await page.content())
await browser.close()
asyncio.run(main())
代碼生成
Playwright 提供了代碼生成功能,這個功能可以對我們在瀏覽器上的操作進行錄製並生成代碼,它可以有效提高程式的編寫效率。代碼生成功能需要使用 Playwright 命令行中的 codegen實現,codegen 命令存在如下主要參數:
-o :將生成的腳本保存到指定文件
--target :生成的語言,預設為 Python
--save-trace :記錄會話的跟蹤並將其保存到文件中
-b :要使用的瀏覽器,預設為 chromium
--timeout :設置頁面載入的超時時間
--user-agent :指定UA
--viewport-size :指定瀏覽器視窗大小
我們在命令行執行命令:playwright codegen -o script.py
執行命令後會彈出一個 chromium 瀏覽器與腳本視窗,當我們在瀏覽器上進行操作時,腳本視窗會根據我們的操作生成對應代碼。當我們操作結束後,關閉瀏覽器,在當前目錄下會生成一個 script.py 文件,該文件中就是我們在進行瀏覽器操作時,Playwright 錄製的代碼。我們運行該文件,就會發現它在復現我們之前的操作。
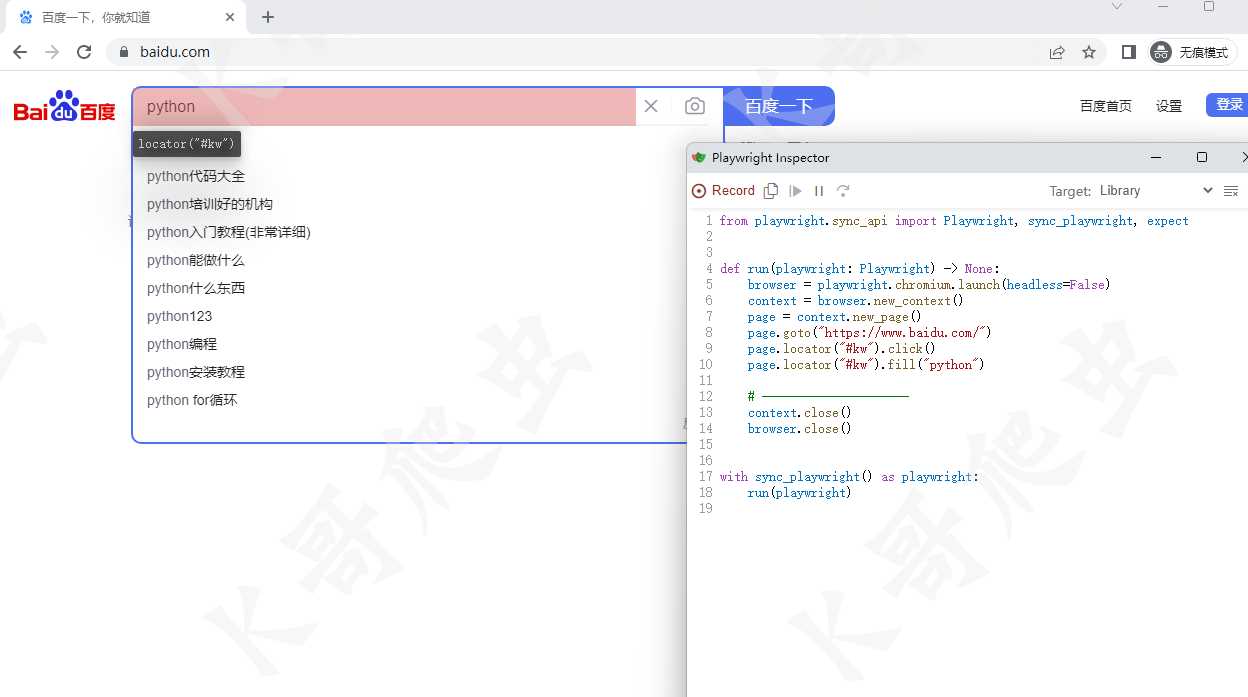
代碼生成功能的實用性其實較為一般,它只能實現比較簡單的操作,當遇到複雜操作時,生成的代碼就容易出現問題。最好的方式是使用代碼生成功能生成部分操作的代碼,然後再手動去修改它生成的代碼。
隔離
上一步中,我們使用代碼生成功能生成了一段代碼,我們會發現這段代碼中使用到了一個 new_context 方法,通過這個方法創建了一個 content ,然後再去進行其它操作。這個 new_content 方法其實是為了創建一個獨立的全新上下文環境,它的目的是為了防止多個測試用例並行時各個用例間不受干擾,當一個測試用例異常時不會影響到另一個。
browser = playwright.chromium.launch()
context = browser.new_context()
page = context.new_page()
定位器
Playwright 提供了多種定位器來幫助開發中定位元素。
page.get_by_role() :通過顯式和隱式可訪問性屬性進行定位。
page.get_by_text() :通過文本內容定位。
page.get_by_label() :通過關聯標簽的文本定位表單控制項。
page.get_by_placeholder() :按占位符定位輸入。
page.get_by_alt_text() :通過替代文本定位元素,通常是圖像。
page.get_by_title() :通過標題屬性定位元素。
page.get_by_test_id() :根據data-testid屬性定位元素(可以配置其他屬性)。
page.locator():拓展選擇器,可以使用 CSS 選擇器進行定位
使用定位器最好的方式就是上文中講到的利用代碼生成功能來生成定位代碼,然後手動去修改,這裡就不做嘗試。
選擇器
Playwright 支持 CSS、Xpath 和一些拓展選擇器,提供了一些比較方便的使用規則。
CSS 選擇器
# 匹配 button 標簽
page.locator('button').click()
# 根據 id 匹配,匹配 id 為 container 的節點
page.locator('#container').click()
# CSS偽類匹配,匹配可見的 button 按鈕
page.locator("button:visible").click()
# :has-text 匹配任意內部包含指定文本的節點
page.locator(':has-text("Playwright")').click()
# 匹配 article 標簽內包含 products 文本的節點
page.locator('article:has-text("products")').click()
# 匹配 article 標簽下包含類名為 promo 的 div 標簽的節點
page.locator("article:has(div.promo)").click()
Xpath
page.locator("xpath=//button").click()
page.locator('xpath=//div[@class="container"]').click()
其它
# 根據文本匹配,匹配文本內容包含 name 的節點
page.locator('text=name').click()
# 匹配文本內容為 name 的節點
page.locator("text='name'").click()
# 正則匹配
page.locator("text=/name\s\w+word").click()
# 匹配第一個 button 按鈕
page.locator("button").locator("nth=0").click()
# 匹配第二個 button 按鈕
page.locator("button").locator("nth=-1").click()
# 匹配 id 為 name 的元素
page.locator('id=name')
等待
當進行 click 、fill 等操作時,Playwright 在採取行動之前會對元素執行一系列可操作性檢測,以確保這些行動能夠按預期進行。
如對元素進行 click 操作之前,Playwright 將確保:
元素附加到 DOM
元素可見
元素是穩定的,因為沒有動畫或完成動畫
元素接收事件,因為沒有被其他元素遮擋
元素已啟用
即使 Playwright 已經做了充分準備,但是也並不完全穩定,在實際項目中依舊容易出現因頁面載入導致事件沒有生效等問題,為了避免這些問題,需要自行設置等待。
# 固定等待1秒
page.wait_for_timeout(1000)
# 等待事件
page.wait_for_event(event)
# 等待載入狀態
page.get_by_role("button").click()
page.wait_for_load_state()
事件
添加/刪除事件
from playwright.sync_api import sync_playwright
def print_request_sent(request):
print("Request sent: " + request.url)
def print_request_finished(request):
print("Request finished: " + request.url)
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
# 添加事件 發起請求時列印URL
page.on("request", print_request_sent)
# 請求完成時列印URL
page.on("requestfinished", print_request_finished)
page.goto("https://baidu.com")
# 刪除事件
page.remove_listener("requestfinished", print_request_finished)
browser.close()
反檢測
在 Selenium 的使用中,我們講到了自動化工具容易被網站檢測,也提供了一些繞過檢測的方案。這裡我們介紹一下 Playwright 的反檢測方案。
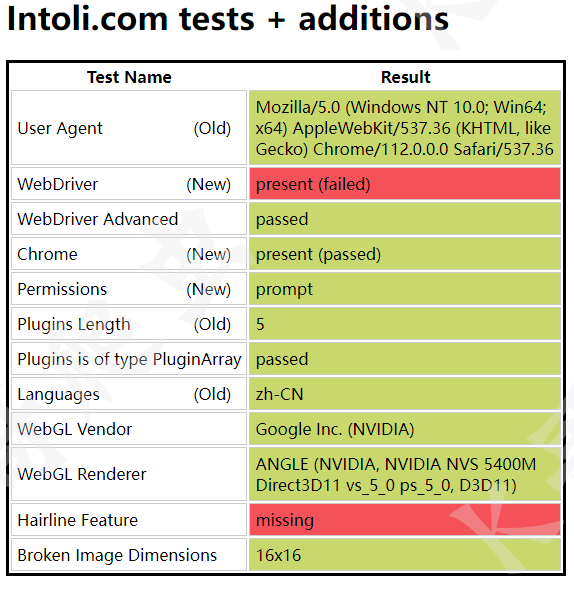
以 https://bot.sannysoft.com/ 為例,我們分別測試正常模式與無頭模式下的檢測結果。
正常模式:
無頭模式:
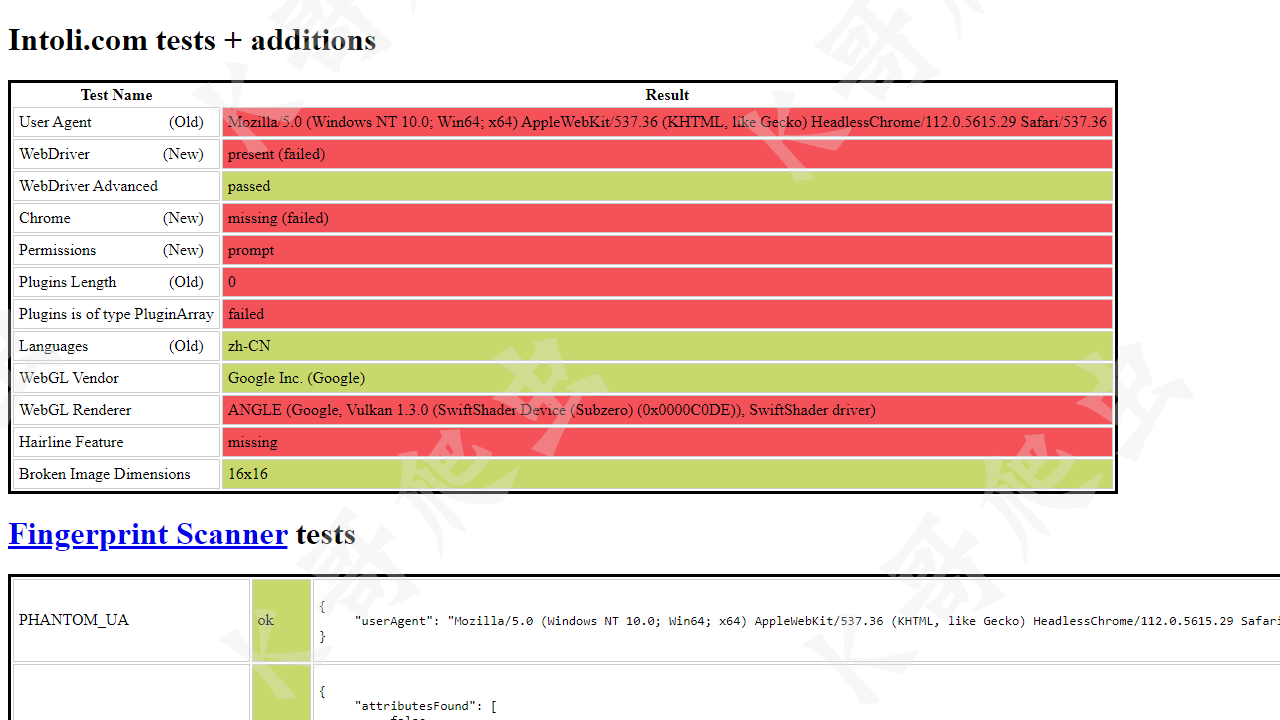
可以看到,正常模式下 WebDriver 一欄報紅,而無頭模式下更是慘不忍睹,基本上所有特征都被檢測到了。這些還只是最基本的檢測機制,自動化工具的弱點就暴露的很明顯了。
與 Selenium 一樣,繞過檢測主要還是針對網站的檢測機制來處理,主要就是在頁面載入之前通過執行 JS 代碼來修改一些瀏覽器特征。以無頭模式為例:
from playwright.sync_api import sync_playwright
with open('./stealth.min.js', 'r') as f:
js = f.read()
with sync_playwright() as p:
browser = p.chromium.launch()
# 添加 UserAgent
page = browser.new_page(
user_agent='Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36'
)
# 執行 JS 代碼
page.add_init_script(js)
page.goto("https://bot.sannysoft.com/")
page.screenshot(path='example.png')
browser.close()
這裡與 Selenium 反檢測方案一樣,執行 stealth.min.js 來隱藏特征( stealth.min.js 的來源與介紹參考上期文章)。最終結果如下圖:
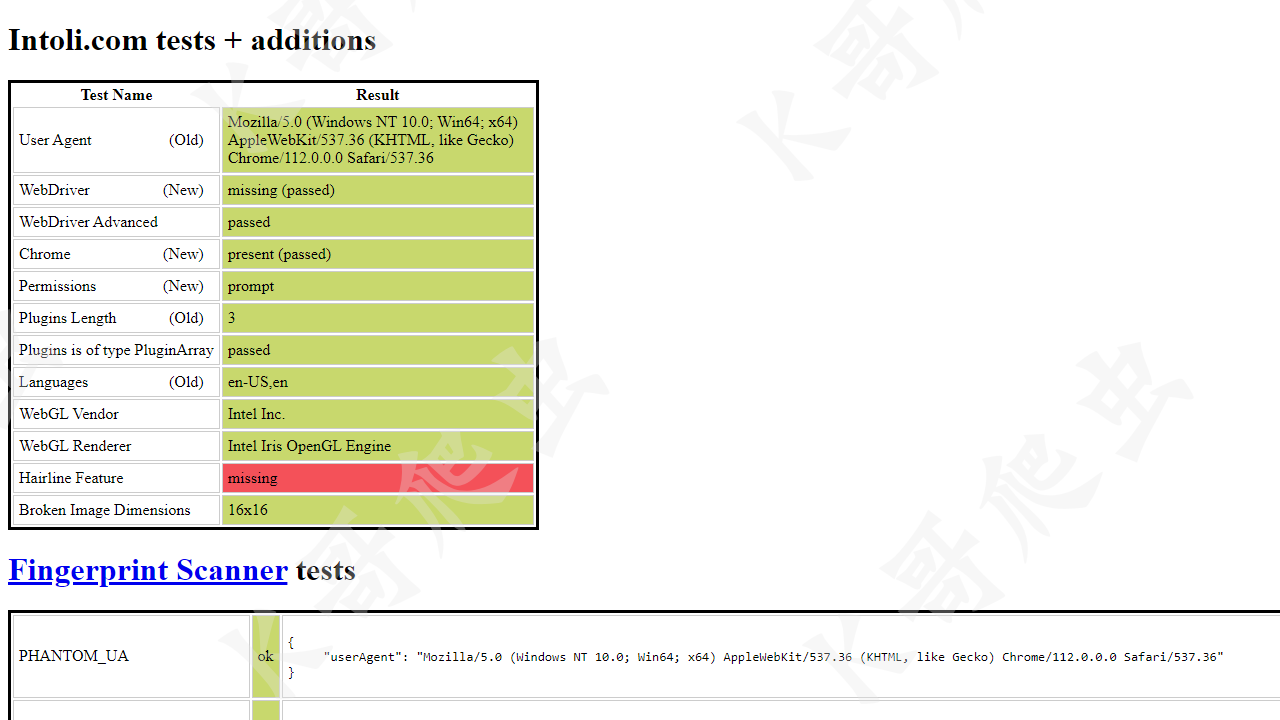
可以看到,與真實瀏覽器訪問基本一致了。
總結
與 Selenium 相比,Playwright 最大的優點就是不需要手動安裝驅動,而且它擁有更好的性能與更多的功能。因此 在爬蟲領域,Playwright 是更好的選擇。


