
0. ray 簡介 ray是開源分散式計算框架,為並行處理提供計算層,用於擴展AI與Python應用程式,是ML工作負載統一工具包 Ray AI Runtime ML應用程式庫集 Ray Core 通用分散式計算庫 Task -- Ray允許任意Python函數在單獨的Python worker上運 ...
0. ray 簡介
ray是開源分散式計算框架,為並行處理提供計算層,用於擴展AI與Python應用程式,是ML工作負載統一工具包
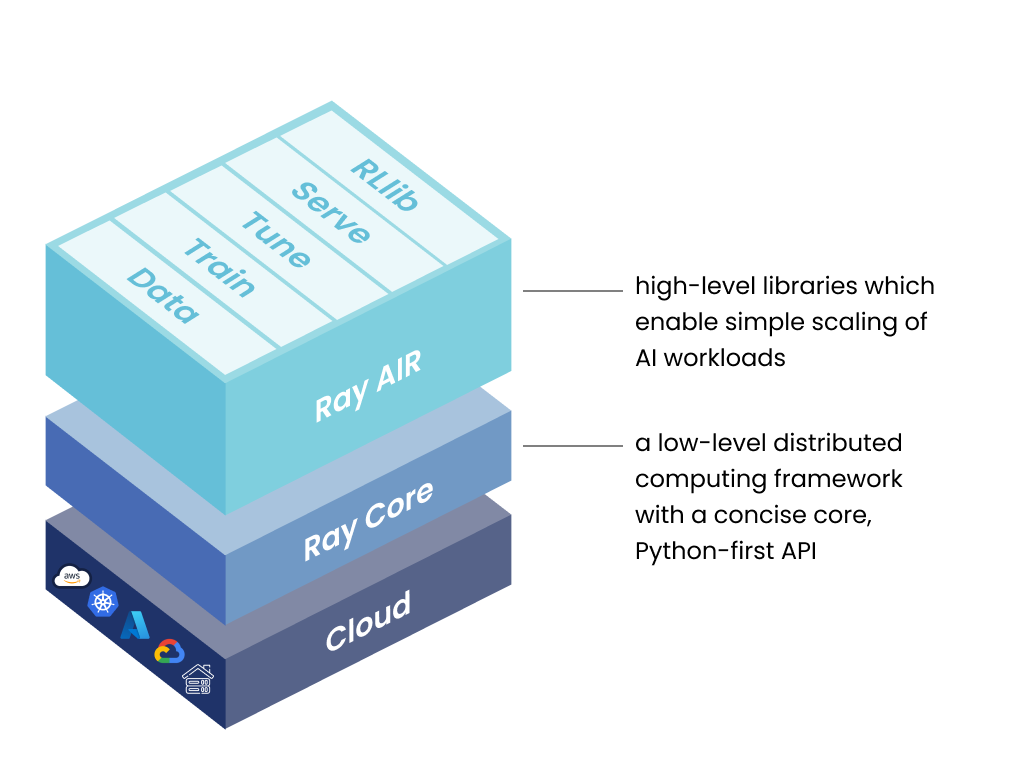
- Ray AI Runtime
ML應用程式庫集
- Ray Core
通用分散式計算庫
- Task -- Ray允許任意Python函數在單獨的Python worker上運行,這些非同步Python函數稱為任務
- Actor -- 從函數擴展到類,是一個有狀態的工作者,當一個Actor被創建,一個新的worker被創建,並且actor的方法被安排到那個特定的worker上,並且可以訪問和修改那個worker的狀態
- Object -- Task與Actor在對象上創建與計算,被稱為遠程對象,被存儲在ray的分散式共用記憶體對象存儲上,通過對象引用來引用遠程對象。集群中每個節點都有一個對象存儲,遠程對象存儲在何處(一個或多個節點上)與遠程對象引用的持有者無關
- Placement Groups -- 允許用戶跨多個節點原子性的保留資源組,以供後續Task與Actor使用
- Environment Dependencies -- 當Ray在遠程機器上執行Task或Actor時,它們的依賴環境項(Python包、本地文件、環境變數)必須可供代碼運行。解決環境依賴的方式有兩種,一種是在集群啟動前準備好對集群的依賴,另一種是在ray的運行時環境動態安裝
- Ray cluster
一組連接到公共 Ray 頭節點的工作節點,通過 kubeRay operator管理運行在k8s上的ray集群
- 關聯鏈接
- Ray Doc: https://docs.ray.io/en/latest/ray-overview/index.html
- Ray Github: https://ray-project.github.io/kuberay/deploy/helm-cluster/
- Python raycluster 管理API: https://github.com/ray-project/kuberay/tree/master/clients/python-client
- Ray Job Python SDK Doc: https://docs.ray.io/en/latest/cluster/running-applications/job-submission/jobs-package-ref.html#ray-job-submission-sdk-ref
1. ray 集群管理
ray版本:2.3.0
- Kind 創建測試k8s集群
1主3從集群
# 配置文件 -- 一主兩從(預設單主),文件名:k8s-3nodes.yaml
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
nodes:
- role: control-plane
- role: worker
- role: worker
創建k8s集群
kind create cluster --config k8s-3nodes.yaml
- KubeRay 部署ray集群
# helm方式安裝
# 添加Charts倉庫
helm repo add kuberay https://ray-project.github.io/kuberay-helm/
# 安裝default名稱空間
# 安裝 kubeRay operator
# 下載離線的chart包: helm pull kuberay/kuberay-operator --version 0.5.0
# 本地安裝: helm install kuberay-operator
helm install kuberay-operator kuberay/kuberay-operator --version 0.5.0
# 創建ray示例集群,若通過sdk管理則跳過
# 下載離線的ray集群自定義資源:helm pull kuberay/ray-cluster --version 0.5.0
helm install raycluster kuberay/ray-cluster --version 0.5.0
# 獲取ray集群對應的CR
kubectl get raycluster
# 查詢pod的狀態
kubectl get pods
# 轉發svc 8265埠到本地8265埠
kubectl port-forward --address 0.0.0.0 svc/raycluster-kuberay-head-svc 8265:8265
# 登錄ray head節點,並執行一個job
kubectl exec -it ${RAYCLUSTER_HEAD_POD} -- bash
python -c "import ray; ray.init(); print(ray.cluster_resources())" # (in Ray head Pod)
# 刪除ray集群
helm uninstall raycluster
# 刪除kubeRay
helm uninstall kuberay-operator
# 查詢helm管理的資源
helm ls --all-namespaces
- Ray 集群管理
前置要求:
- 安裝 KubeRay
- 安裝 k8s sdk: pip install kubernetes
- 將python_client拷貝到PYTHONPATH路徑下或者直接安裝python_client, 該庫路徑為:https://github.com/ray-project/kuberay/tree/master/clients/python-client/python_client
from python_client import kuberay_cluster_api
from python_client.utils import kuberay_cluster_utils, kuberay_cluster_builder
def main():
# ray集群管理的api 獲取集群列表、創建集群、更新集群、刪除集群
kuberay_api = kuberay_cluster_api.RayClusterApi()
# CR 構建器,構建ray集群對應的字典格式的CR
cr_builder = kuberay_cluster_builder.ClusterBuilder()
# CR資源對象操作工具,更新cr資源
cluster_utils = kuberay_cluster_utils.ClusterUtils()
# 構建集群的CR,是一個字典對象,可以修改、刪除、添加額外的屬性
# 可以指定包含特定環境依賴的人ray鏡像
cluster = (
cr_builder.build_meta(name="new-cluster1", labels={"demo-cluster": "yes"}) # 輸入ray群名稱、名稱空間、資源標簽、ray版本信息
.build_head(cpu_requests="0", memory_requests="0") # ray集群head信息: ray鏡像名稱、對應service類型、cpu memory的requests與limits、ray head啟動參數
.build_worker(group_name="workers", cpu_requests="0", memory_requests="0") # ray集群worker信息: worker組名稱、 ray鏡像名稱、ray啟動命令、cpu memory的requests與limits、預設副本個數、最大與最小副本個數
.get_cluster()
)
# 檢查CR是否構建成功
if not cr_builder.succeeded:
print("error building the cluster, aborting...")
return
# 創建ray集群
kuberay_api.create_ray_cluster(body=cluster)
# 更新ray集群CR中的worker副本集合
cluster_to_patch, succeeded = cluster_utils.update_worker_group_replicas(
cluster, group_name="workers", max_replicas=4, min_replicas=1, replicas=2
)
if succeeded:
# 更新ray集群
kuberay_api.patch_ray_cluster(
name=cluster_to_patch["metadata"]["name"], ray_patch=cluster_to_patch
)
# 在原來的集群的CR中的工作組添加新的工作組
cluster_to_patch, succeeded = cluster_utils.duplicate_worker_group(
cluster, group_name="workers", new_group_name="duplicate-workers"
)
if succeeded:
kuberay_api.patch_ray_cluster(
name=cluster_to_patch["metadata"]["name"], ray_patch=cluster_to_patch
)
# 列出所有創建的集群
kube_ray_list = kuberay_api.list_ray_clusters(k8s_namespace="default", label_selector='demo-cluster=yes')
if "items" in kube_ray_list:
for cluster in kube_ray_list["items"]:
print(cluster["metadata"]["name"], cluster["metadata"]["namespace"])
# 刪除集群
if "items" in kube_ray_list:
for cluster in kube_ray_list["items"]:
print("deleting raycluster = {}".format(cluster["metadata"]["name"]))
# 通過指定名稱刪除ray集群
kuberay_api.delete_ray_cluster(
name=cluster["metadata"]["name"],
k8s_namespace=cluster["metadata"]["namespace"],
)
if __name__ == "__main__":
main()
2. ray Job 管理
前置: pip install -U "ray[default]"
- 創建一個job任務
# 文件名稱: test_job.py
# python 標準庫
import json
import ray
import sys
# 已經在ray節點安裝的庫
import redis
# 通過job提交時傳遞的模塊依賴 runtime_env 配置 py_modules,通過 py_nodules傳遞過來就可以直接在job中導入
from test_module import test_1
import stk12
# 創建一個連接redeis對象,通過redis作為中轉向job傳遞輸入並獲取job的輸出
redis_cli = redis.Redis(host='192.168.6.205', port=6379, decode_responses=True)
# 通過redis獲取傳入過來的參數
input_params_value = None
if len(sys.argv) > 1:
input_params_key = sys.argv[1]
input_params_value = json.loads(redis_cli.get(input_params_key))
# 執行遠程任務
@ray.remote
def hello_world(value):
return [v + 100 for v in value]
ray.init()
# 輸出傳遞過來的參數
print("input_params_value:", input_params_value, type(input_params_key))
# 執行遠程函數
result = ray.get(hello_world.remote(input_params_value))
# 獲取輸出key
output_key = input_params_key.split(":")[0] + ":output"
# 將輸出結果放入redis
redis_cli.set(output_key, json.dumps(result))
# 測試傳遞過來的Python依賴庫是否能正常導入
print(test_1.test_1())
print(stk12.__dir__())
- 創建測試自定義模塊
# 模塊路徑: test_module/test_1.py
def test_1():
return "test_1"
- 創建一個job提交對象
import json
from ray.job_submission import JobSubmissionClient, JobStatus
import time
import uuid
import redis
# 上傳un到ray集群供job使用的模塊
import test_module
from agi import stk12
# 創建一個連接redeis對象
redis_cli = redis.Redis(host='192.168.6.205', port=6379, decode_responses=True)
# 創建一個client,指定遠程ray集群的head地址
client = JobSubmissionClient("http://127.0.0.1:8265")
# 創建任務的ID
id = uuid.uuid4().hex
input_params_key = f"{id}:input"
input_params_value = [1, 2, 3, 4, 5]
# 將輸入參數存入redis,供遠程函數job使用
redis_cli.set(input_params_key, json.dumps(input_params_value))
# 提交一個ray job 是一個獨立的ray應用程式
job_id = client.submit_job(
# 執行該job的入口腳本
entrypoint=f"python test_job.py {input_params_key}",
# 將本地文件上傳到ray集群
runtime_env={
"working_dir": "./",
"py_modules": [test_module, stk12],
"env_vars": {"testenv": "test-1"}
},
# 自定義任務ID
submission_id=f"{id}"
)
# 輸出job ID
print("job_id:", job_id)
def wait_until_status(job_id, status_to_wait_for, timeout_seconds=5):
"""輪詢獲取Job的狀態,當完成時獲取任務的的日誌輸出"""
start = time.time()
while time.time() - start <= timeout_seconds:
# 獲取任務的狀態
status = client.get_job_status(job_id)
print(f"status: {status}")
# 檢查任務的狀態
if status in status_to_wait_for:
break
time.sleep(1)
wait_until_status(job_id, {JobStatus.SUCCEEDED, JobStatus.STOPPED, JobStatus.FAILED})
# 輸出job日誌
logs = client.get_job_logs(job_id)
print(logs)
# 輸出從job中獲取的任務
output_key = job_id + ":output"
output_value = redis_cli.get(output_key)
print("output:", output_value)
- job 管理
from ray.job_submission import JobSubmissionClient, JobDetails, JobInfo, JobType, JobStatus
# 創建一個job提交客戶端,如果管理多個ray集群的Job則切換或者創建多個連接ray head節點的客戶端
job_cli = JobSubmissionClient("http://127.0.0.1:8265")
# Job信息,對應Job中submission_id屬性
job_id = "b9ad6ff9ada445a29fb54307f1394594"
job_info = job_cli.get_job_info(job_id)
# 獲取提交的所有job
jobs = job_cli.list_jobs()
for job in jobs:
# 獲取job的狀態
job_status = job_cli.get_job_status(job.submission_id)
print(f"job_id: {job.submission_id}, job_status: {job_status}")
# 輸出job的json格式詳情
print("job:", job.json())
# 停止Job
job_cli.stop_job(job_id)
# 刪除 job
# job_cli.delete_job(job_id)
# 提交 Job
# job_cli.submit_job()
# 獲取版本信息
print("version:", job_cli.get_version())
3. 產品場景
- 將周期、耗時任務非同步化
鏡像文件打包下載、文件同步、運維腳本、數據導出與同步、鏡像同步、服務啟停、TATC衛星項目中演算法任務的執行、批量同類型任務的計算(如衛星項目中衛星軌跡的計算)、備份任務
- k8s中每個租戶可以創建與刪除自己的ray集群實例,線上IDE中將計算型任務交給ray來執行,不消耗IED所在環境的計算資源


