
摘要:保證線程安全是 Java 併發編程必須要解決的重要問題,本文和大家聊聊Java中的併發原子類,看它如何確保多線程的數據一致性。 本文分享自華為雲社區《學了這麼久的高併發編程,連Java中的併發原子類都不知道?這也太Low了吧》,作者:冰 河。 今天我們一起來聊聊Java中的併發原子類。在 ja ...
摘要:保證線程安全是 Java 併發編程必須要解決的重要問題,本文和大家聊聊Java中的併發原子類,看它如何確保多線程的數據一致性。
本文分享自華為雲社區《學了這麼久的高併發編程,連Java中的併發原子類都不知道?這也太Low了吧》,作者:冰 河。
今天我們一起來聊聊Java中的併發原子類。在 java.util.concurrent.atomic包下有很多支持併發的原子類,某種程度上,我們可以將其分成:基本數據類型的原子類、對象引用類型的原子類、數組類型的原子類、對象屬性類型的原子類和累加器類型的原子類 五大類。
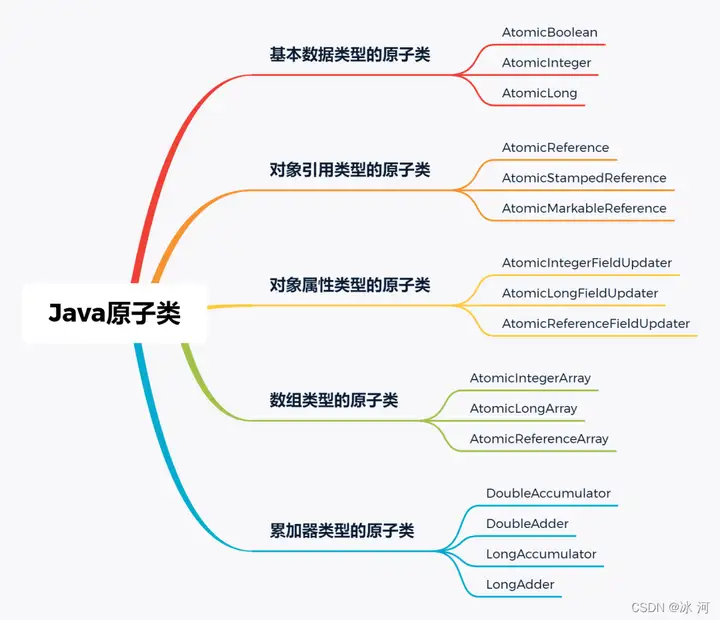
接下來,我們就一起來看看這些併發原子類吧。
基本數據類型的原子類
基本數據類型的原子類包含:AtomicBoolean、AtomicInteger和AtomicLong。
打開這些原子類的源碼,我們可以發現,這些原子類在使用上還是非常簡單的,主要提供瞭如下這些比較常用的方法。
- 原子化加1或減1操作
//原子化的i++ getAndIncrement() //原子化的i-- getAndDecrement() //原子化的++i incrementAndGet() //原子化的--i decrementAndGet()
- 原子化增加指定的值
//當前值+=delta,返回+=前的值 getAndAdd(delta) //當前值+=delta,返回+=後的值 addAndGet(delta)
- CAS操作
//CAS操作,返回原子化操作的結果是否成功 compareAndSet(expect, update)
- 接收函數計算結果
//結果數據可通過傳入func函數來計算 getAndUpdate(func) updateAndGet(func) getAndAccumulate(x,func) accumulateAndGet(x,func)
對象引用類型的原子類
對象引用類型的原子類包含:AtomicReference、AtomicStampedReference和AtomicMarkableReference。
利用這些對象引用類型的原子類,可以實現對象引用更新的原子化。AtomicReference提供的原子化更新操作與基本數據類型的原子類提供的更新操作差不多,只不過AtomicReference提供的原子化操作常用於更新對象信息。這裡不再贅述。
需要特別註意的是:使用對象引用類型的原子類,要重點關註ABA問題。
關於ABA問題,文章的最後部分會說明。
好在AtomicStampedReference和AtomicMarkableReference這兩個原子類解決了ABA問題。
AtomicStampedReference類中的compareAndSet的方法簽名如下所示。
boolean compareAndSet(V expectedReference, V newReference, int expectedStamp, int newStamp)
可以看到,AtomicStampedReference類解決ABA問題的方案與樂觀鎖的機制比較相似,實現的CAS方法增加了版本號。只有expectedReference的值與記憶體中的引用值相等,並且expectedStamp版本號與記憶體中的版本號相同時,才會將記憶體中的引用值更新為newReference,同時將記憶體中的版本號更新為newStamp。
AtomicMarkableReference類中的compareAndSet的方法簽名如下所示。
boolean compareAndSet(V expectedReference, V newReference, boolean expectedMark, boolean newMark)
可以看到,AtomicMarkableReference解決ABA問題的方案就更簡單了,在compareAndSet方法中,新增了boolean類型的校驗值。這些理解起來也比較簡單,這裡,我也不再贅述了。
對象屬性類型的原子類
對象屬性類型的原子類包含:AtomicIntegerFieldUpdater、AtomicLongFieldUpdater和AtomicReferenceFieldUpdater。
利用對象屬性類型的原子類可以原子化的更新對象的屬性。值得一提的是,這三個類的對象都是通過反射的方式生成的,如下是三個類的newUpdater()方法。
//AtomicIntegerFieldUpdater的newUpdater方法 public static <U> AtomicIntegerFieldUpdater<U> newUpdater(Class<U> tclass, String fieldName) //AtomicLongFieldUpdater的newUpdater方法 public static <U> AtomicLongFieldUpdater<U> newUpdater(Class<U> tclass, String fieldName) //AtomicReferenceFieldUpdater的newUpdater方法 public static <U,W> AtomicReferenceFieldUpdater<U,W> newUpdater(Class<U> tclass, Class<W> vclass, String fieldName)
這裡,我們不難看出,在AtomicIntegerFieldUpdater、AtomicLongFieldUpdater和AtomicReferenceFieldUpdater三個類的newUpdater()方法中,只有傳遞的Class信息,並沒有傳遞對象的引用信息。如果要更新對象的屬性,則一定要使用對象的引用,那對象的引用是在哪裡傳遞的呢?
其實,對象的引用是在真正調用原子操作的方法時傳入的。這裡,我們就以compareAndSet()方法為例,如下所示。
//AtomicIntegerFieldUpdater的compareAndSet()方法 compareAndSet(T obj, int expect, int update) //AtomicLongFieldUpdater的compareAndSet()方法 compareAndSet(T obj, long expect, long update) //AtomicReferenceFieldUpdater的compareAndSet()方法 compareAndSet(T obj, V expect, V update)
可以看到,原子化的操作方法僅僅是多了一個對象的引用,使用起來也非常簡單,這裡,我就不再贅述了。
另外,需要註意的是:使用AtomicIntegerFieldUpdater、AtomicLongFieldUpdater和AtomicReferenceFieldUpdater更新對象的屬性時,對象屬性必須是volatile類型的,只有這樣才能保證可見性;如果對象屬性不是volatile類型的,newUpdater()方法會拋出IllegalArgumentException這個運行時異常。
數組類型的原子類
數組類型的原子類包含:AtomicIntegerArray、AtomicLongArray和AtomicReferenceArray。
利用數組類型的原子類可以原子化的更新數組裡面的每一個元素,使用起來也非常簡單,數組類型的原子類提供的原子化方法僅僅是在基本數據類型的原子類和對象引用類型的原子類提供的原子化方法的基礎上增加了一個數組的索引參數。
例如,我們以compareAndSet()方法為例,如下所示。
//AtomicIntegerArray的compareAndSet()方法 compareAndSet(int i, int expect, int update) //AtomicLongArray的compareAndSet()方法 compareAndSet(int i, long expect, long update) //AtomicReferenceArray的compareAndSet()方法 compareAndSet(int i, E expect, E update)
可以看到,原子化的操作方法僅僅是對多了一個數組的下標,使用起來也非常簡單,這裡,我就不再贅述了。
累加器類型的原子類
累加器類型的原子類包含:DoubleAccumulator、DoubleAdder、LongAccumulator和LongAdder。
累加器類型的原子類就比較簡單了:僅僅支持值的累加操作,不支持compareAndSet()方法。對於值的累加操作,比基本數據類型的原子類速度更快,性能更好。
使用原子類實現count+1
在併發編程領域,一個經典的問題就是count+1問題。也就是在高併發環境下,如何保證count+1的正確性。一種方案就是在臨界區加鎖來保護共用變數count,但是這種方式太消耗性能了。
如果使用Java提供的原子類來解決高併發環境下count+的問題,則性能會大幅度提升。
簡單的示例代碼如下所示。
public class IncrementCountTest{ private AtomicLong count = new AtomicLong(0); public void incrementCountByNumber(int number){ for(int i = 0; i < number; i++){ count.getAndIncrement(); } } }
可以看到,原子類實現count+1問題,既沒有使用synchronized鎖,也沒有使用Lock鎖。
從本質上講,它使用的是無鎖或者是樂觀鎖方案解決的count+問題,說的具體一點就是CAS操作。
CAS原理
CAS操作包括三個操作數:需要讀寫的記憶體位置(V)、預期原值(A)、新值(B)。如果記憶體位置與預期原值的A相匹配,那麼將記憶體位置的值更新為新值B。
如果記憶體位置與預期原值的值不匹配,那麼處理器不會做任何操作。
無論哪種情況,它都會在 CAS 指令之前返回該位置的值。(在 CAS 的一些特殊情況下將僅返回 CAS 是否成功,而不提取當前值。)
簡單點理解就是:位置 V 應該包含值 A;如果包含該值,則將 B 放到這個位置;否則,不要更改該位置,只返回位置V現在的值。這其實和樂觀鎖的衝突檢測+數據更新的原理是一樣的。
ABA問題
因為CAS需要在操作值的時候檢查下值有沒有發生變化,如果沒有發生變化則更新,但是如果一個值原來是A,變成了B,又變成了A,那麼使用CAS進行檢查時會發現它的值沒有發生變化,但是實際上卻變化了。
ABA問題的解決思路就是使用版本號。在變數前面追加上版本號,每次變數更新的時候把版本號加1,那麼A-B-A 就會變成1A-2B-3A。
從Java1.5開始JDK的atomic包里提供的AtomicStampedReference類和AtomicMarkableReference類能夠解決CAS的ABA問題。
關於AtomicStampedReference類和AtomicMarkableReference類前文有描述,這裡不再贅述。


