本文旨在從0到1的講述一下我們團隊在做系統可觀測性過程中所沉澱下來的一整套解決方案,收效甚巨,不敢苟藏,當公之於眾,共建吾輩光明之未來。 ...
作者:京東科技 王亞森
前言
本文旨在從0到1的講述一下我們團隊在做系統可觀測性過程中所沉澱下來的一整套解決方案,收效甚巨,不敢苟藏,當公之於眾,共建吾輩光明之未來。
先講一下我們從中得到的好處:
1,當我所負責系統宕機時我能第一時間得到通知
2,當我寫的業務邏輯進入else或者catch時它會通知我
3,當我新做了一個產品功能上線後,我可以監控用戶的訪問情況
4,我不會再擔心早上沒到公司就收到同事的電話說昨晚上線的應用要回滾
5,發現新做的功能上線後有問題,可以第一時間線上將功能切換至老版本運行
6,不管有沒有發生問題我都可以還原用戶的操作軌跡查找問題
7,老闆說我們好久沒出生產事故了
下麵內容比較乾,建議請提前備好茶水,一起賞用更佳
一、介紹
何為系統可觀測性?
可觀測性是一種系統屬性,如功能性或可測試性。通過收集和分析系統的運行狀態以及系統所承載的業務狀態,用一種可以讓人理解的形式展示出來,以供我們對系統的運行情況做出合理的判斷。
我們要觀測什麼?
通用部分:從硬體運維(cpu, meomery, disk)與 軟體應用可訪問性 與 應用性能幾個方面進行監控。
業務部分:從頁面正常初始化,業務可交互性,交互流程完整性 方面進行監控。
我們以集團內部現有的工具進行說明如何來做,而工具實現的技術手段不在本篇文章職責之內。
二、觀測指標
系統指標
伺服器運行狀態
cpu 占用率
記憶體占用率,
硬碟 使用率
nginx 啟停狀態
應用指標
-
白屏, 因系統錯誤導致的白屏
-
資源載入錯誤
-
請求400,500
-
腳本錯誤,導致阻塞交互
-
首屏渲染時間
-
頁面完全載入耗時
-
介面耗時
業務指標
以信貸產品為例,整個產品的黃金流程分為三部分:授信準入,借款融資,還款。
通用部分
業務異常 (999999)
掊口請求網路超時
介面請求錯誤
未知錯誤(未處理的異常碼)
準入
跳轉實名失敗
補充信息提交失敗 (從用戶點擊提交按鈕開始,未到最終提交成功)
查詢地址列表異常
獲取合同列表失敗
合同預覽失敗
準入開通結果頁面未在60秒內正常跳轉至首頁
資質審核頁面停留時長超過5分鐘
融資
融資申請提交失敗(介面返回正常,但未進入結果頁面)
融資鑒權失敗
還款
還款計劃試算失敗
還款失敗
三、如何觀測
以下所有的觀測工具,皆以京東內部為準,以現有的工具,提供觀測方案
系統指標觀測方法
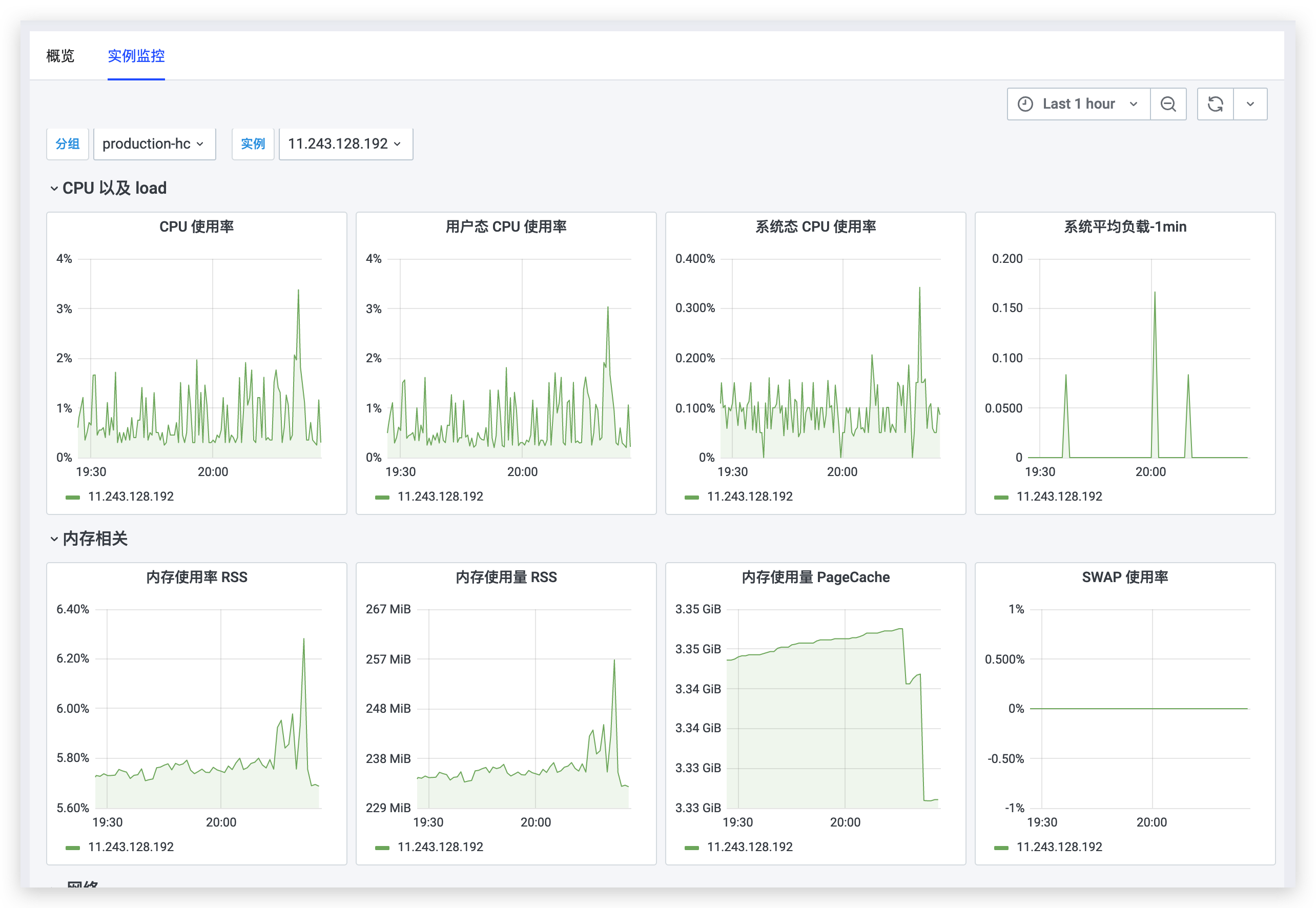
通過jdos 3.0 的智能監控系統 brolly 對系統的 cpu 占用率,記憶體占用率,硬碟使用率 進行監控告警
http://brolly.jdos.jd.com/app/

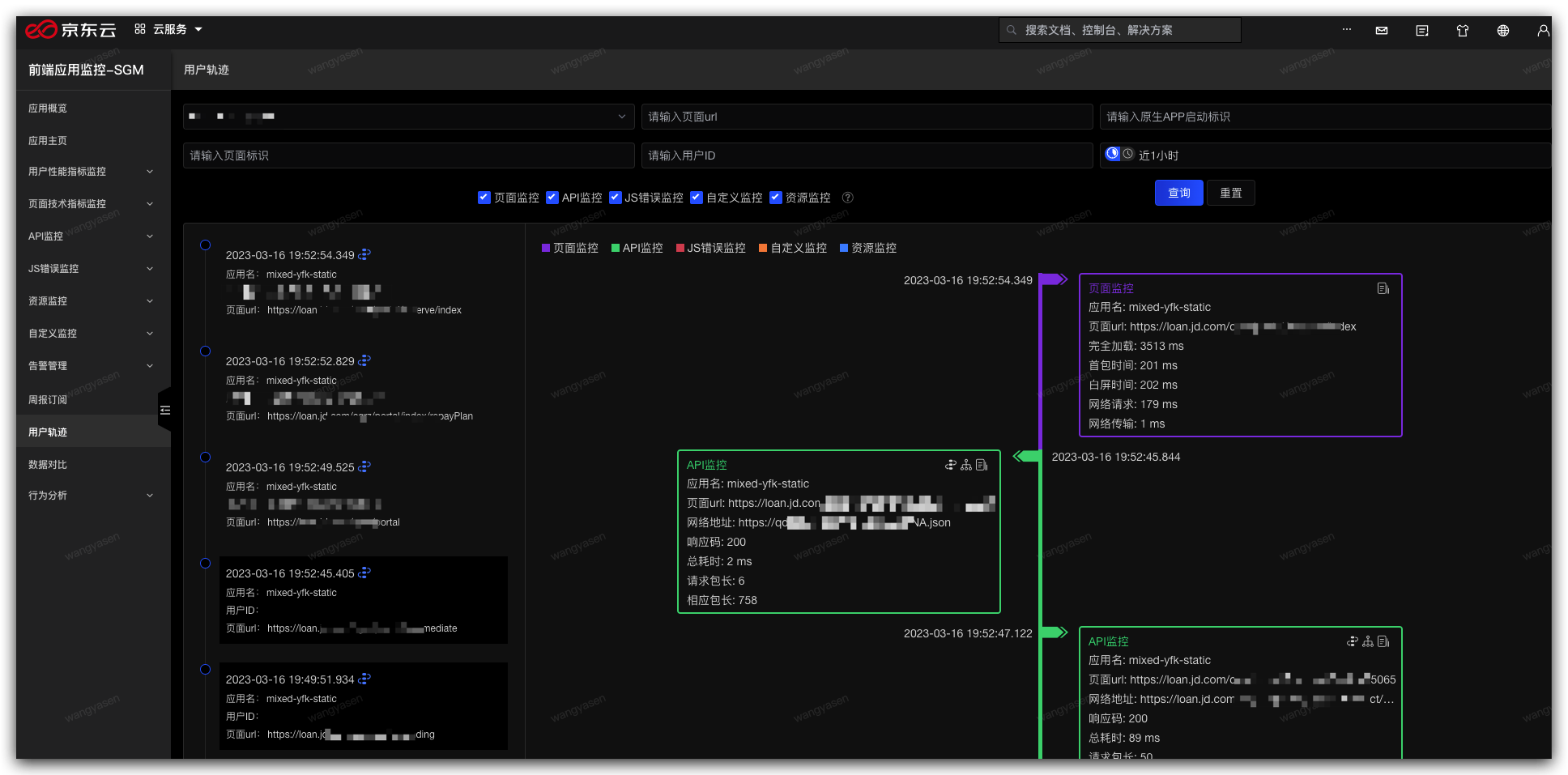
通過jen 對nginx狀態,以及伺服器狀態進行監控告警
應用相關指標觀測方法
前端應用我們選擇科技內部的 sgm 做為應用內場景上報工具,關於sgm的介紹與接入指引參考:sgm接入指引
1,白屏告警
由於sgm中的白屏概念是指訪問頁面開始,到頁面展示第一個字元或圖片內容結果,中間用戶感受到地白屏時間,如果因為發生系統錯誤導致無法展示內容而一直白屏,sgm採集到的白屏時間 為 0,所以sgm無法監測白屏故障。
由於白屏時,頁面 #app 內容為空,此時頁面已經完全載入,所以可能通過監聽頁面 load事件,判斷#app內是否有內容來監控頁面是否白白屏,再配上sgm自定義監控告警,從而達到可以有效監控白白屏故障。
window.addEventListener('load', () => {
if(document.querySelector('#app').children.length < 1){
window.__sgm__.custom({
type: 'error',
code: '系統白屏'
})
}
})
2,資源告警
詳情見:sgm接入指引
3, API 告警
詳情見:sgm接入指引
4, js error 告警
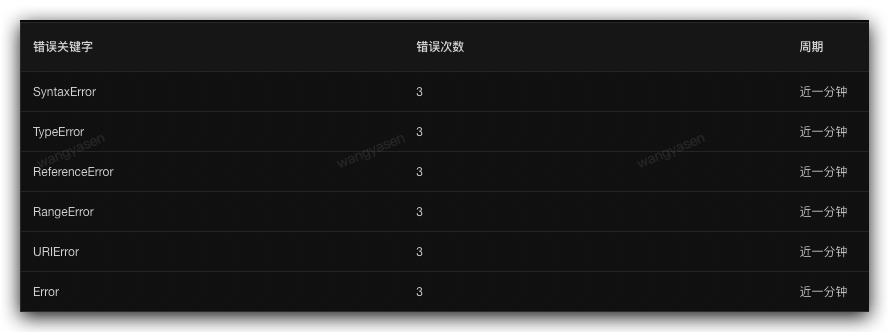
通過sgm-web 對頁面中所有的腳本錯誤的關鍵字進行監控,常見的js錯誤類型為
SyntaxError 語法錯誤
TypeError 類型錯誤
ReferenceError 引用錯誤
RangeError 範圍錯誤
URIError url解析錯誤
InternalError 內部錯誤
5,性能告警
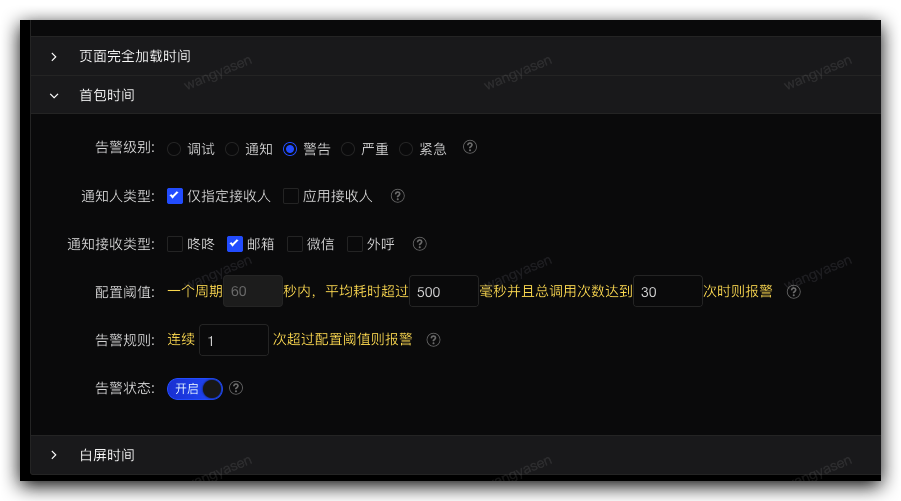
詳情見:sgm接入指引
業務指標觀測方法
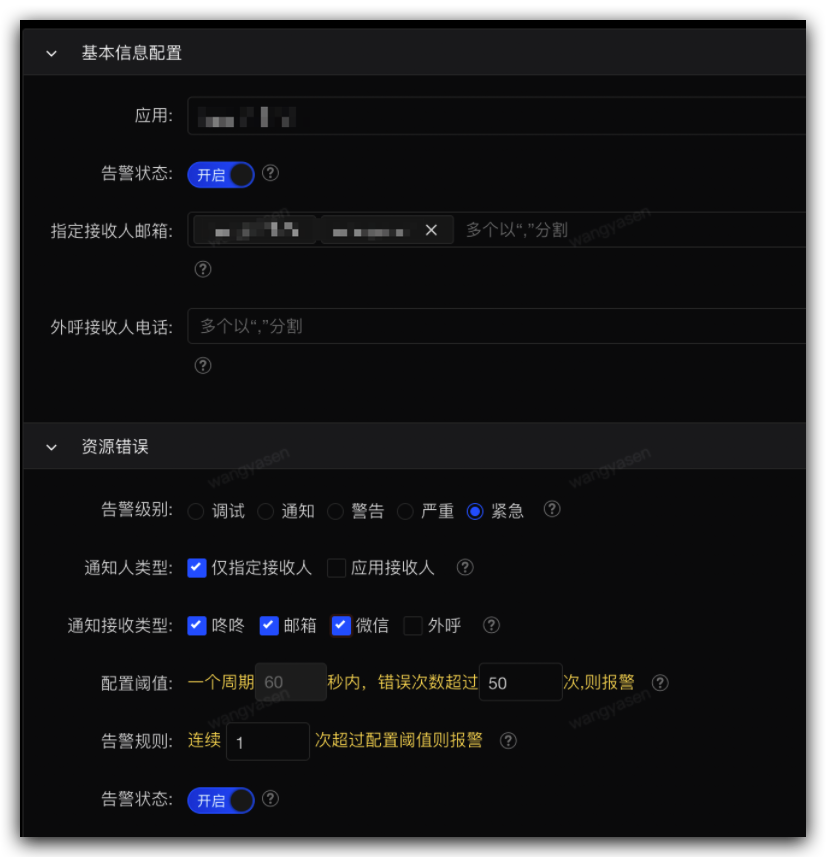
自定義監控告警
自定義告警是監控業務指標的最佳手段,頁面提交失敗,函數進入catch邏輯,等都可以通過自定義監控進行告警設置。
下圖例子中帶Error的編碼,代表進入catch邏輯,需要我們關註,可以通過設置調用量的閾值,來進行告警配置
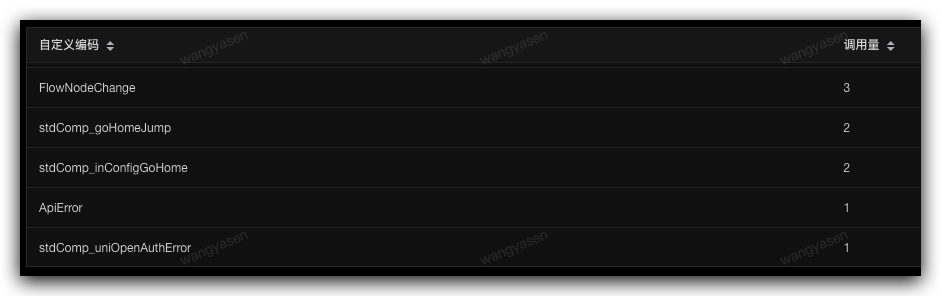
詳情見:sgm接入指引
註意事項
a,埋點上報需包含的信息
userinfo 介面返回的用戶信息,以確保可以拿到用戶標識,查詢相關日誌或者用戶軌跡
當前報錯介面對應的出,入參
自定義上報埋點的上下文信息,以確認出現錯誤的場景
b, 其中頁面路由跳轉失敗的場景可以通過定時器的方法進行上報,在頁面銷毀時清除定時器、
c,sgm上報用戶標識邏輯
四、閾值優化
1,確定點位的有效性
通過本地模擬錯誤進行告警,以確保所有的點位可以正常上報
2,閾值設定的合理性驗證
首先將所有閾值調整至最低,然後查看報警情況
如果有報警,分析報警信息的合理性,如果每次都是需要關註的生產問題,那麼這裡就需要設置為最低的閾值,如果是個例問題或者無須特殊關註的問題,那麼把閾值逐漸調高,至合適的頻率
3,Api監控
前端可以無需特殊關註,可以設置一個20%錯誤率批量報警數值即可
4,資源監控
以頁面靜態資源數為準,包含css, js, img 的總和為監控數值,其中 img 標簽存在動態 src 時,頁面在初次渲染會有一次當前頁面url的資源錯誤上報,可通過 v-if 來避免誤報
5,自定義監控
業務中的自定義錯誤上報 遵循第2條的原則進行逐漸優化
6,應用監控告警閾值配置原則:
由於 sgm 常規計算以 60秒錯誤數(),為一個周期,連續發生多少()周期 ,則觸發告警規則,所以我們需要計算出應用的日均pv,以及對應指標產生的數量級,進行設置合理的閾值。
以 日均 pv 為 10000 的應用 為例,每60s pv 約等於7,每個pv 資源數約為 20, 介面調用數量約為 3,那麼每秒總量是 140次資源請求,21個介面調用 。以 20% 錯誤率上報為標準,來設置對應的閾值。
以上數值可以根據業務線流量視情況而定。
五、報警信息觸達
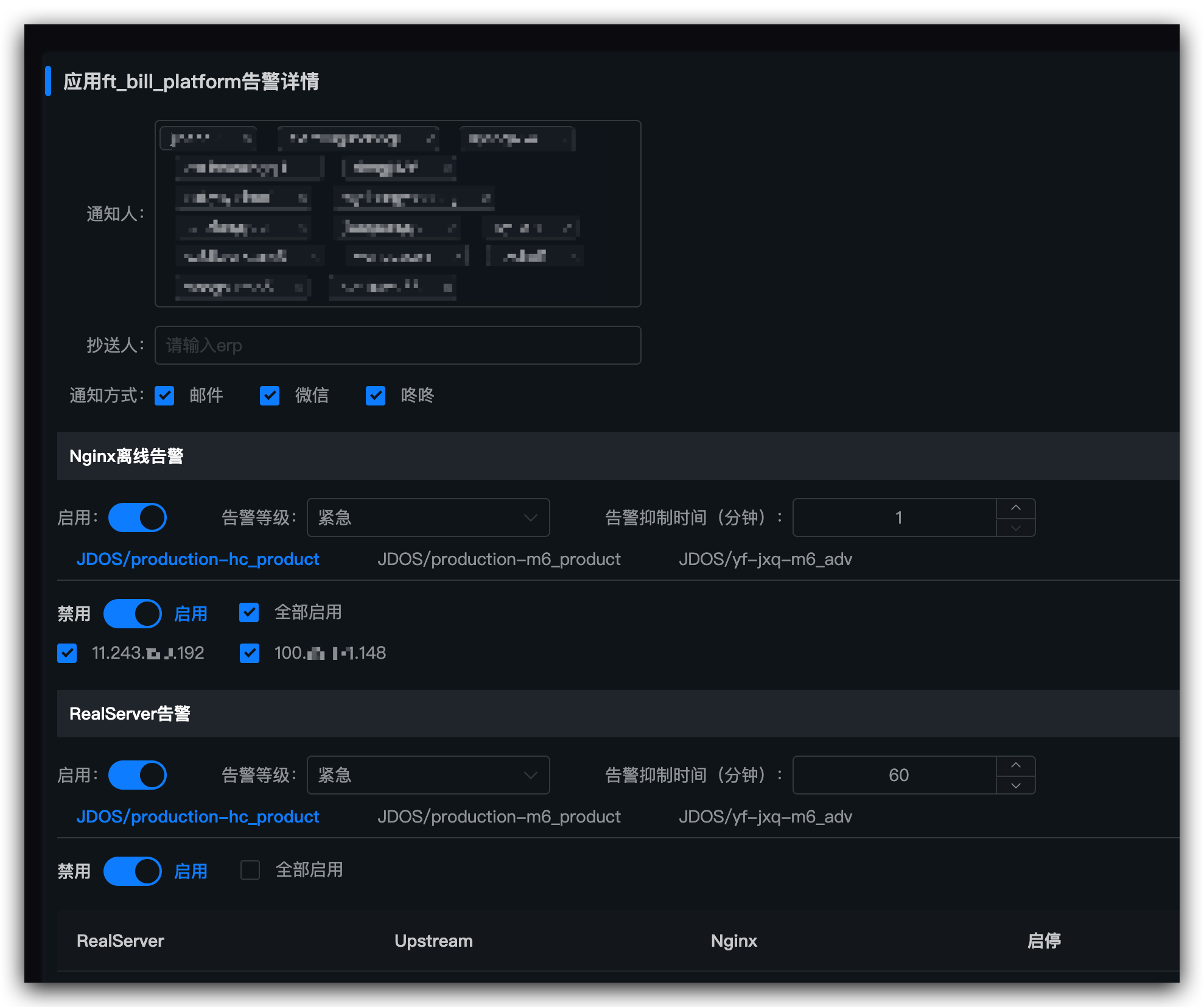
1,郵件(必選)
報警方式中選擇郵件,另外在郵箱中配置報警郵件規則,由於報警郵件可能會有很多包括後端的報警,以及一些非緊急報警郵件,可以通過郵件標題來進行區分。
一般標題中會包含應用名,可以通過篩選應用名來過濾前端應用,另外可以根據標題中的[SGM-WEB]來過濾前端相關的報警信息。
H5_RESOURCE 資源錯誤標題關鍵字
H5_CUSTOM_CODE 自定義監控關鍵字
H5_JS_ERROR 腳本錯誤關鍵字
2,咚咚(必選)
咚咚 報警渠道會比郵件提醒更加及時,被看到的時效性會更高
3,外呼(可選)
時效性最高的報警方法,對於一些關鍵場景,批量錯誤,可以確定是生產問題類的場景需要增加外呼方式,及時觸達信息
六、生產切量監控
可以使用自定義監控來配合系統的切量功能進行監控
假如我要上線一個新的重大功能,需要在生產環境通過切量的方式,逐漸替換老版本的功能,我們如何去監控上線後新老功能
我們需具備兩個功能,一個是切量功能,一個是監控功能
切量是業務系統實現的一個功能,大概流程如下:
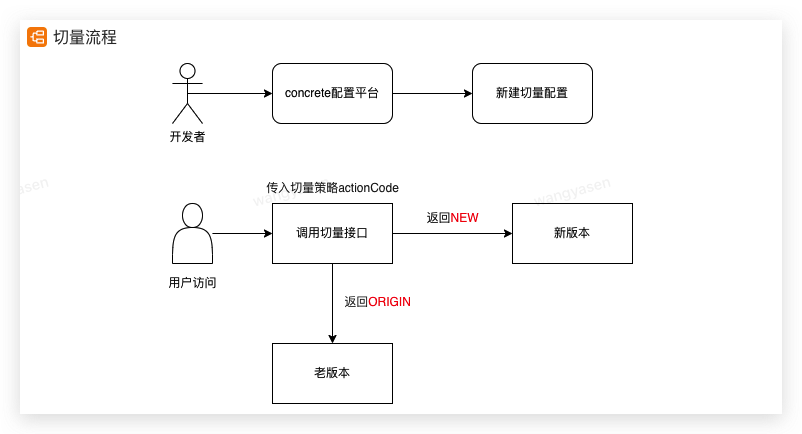
我們分別在新老版本的分支流程里通過自定義埋點來進行監控有多少用戶走到了新流程,有多少老用戶走到了老流程,
然後再通過sgm來查看兩個流程的用戶軌跡來判斷用戶是否在新流程中完成了全部操作,或者是用戶卡在了哪一步,
以此來確定新上線的功能是否有問題,問題出在哪裡
並且可以通過查看監控數據,來確定本次切量是否成功,是否需要及時回滾,或者修複上線,將影響範圍縮小。