
使用python爬蟲爬取鏈家濰坊市二手房項目 需求分析 需要將濰坊市各縣市區頁面所展示的二手房信息按要求爬取下來,同時保存到本地。 流程設計 明確目標網站URL( https://wf.lianjia.com/ ) 確定爬取二手房哪些具體信息(欄位名) python爬蟲關鍵實現:requests庫和 ...
使用python爬蟲爬取鏈家濰坊市二手房項目
需求分析
需要將濰坊市各縣市區頁面所展示的二手房信息按要求爬取下來,同時保存到本地。
流程設計
- 明確目標網站URL( https://wf.lianjia.com/ )
- 確定爬取二手房哪些具體信息(欄位名)
- python爬蟲關鍵實現:requests庫和lxml庫
- 將爬取的數據存儲到CSV或資料庫中
實現過程
項目目錄

1、在資料庫中創建數據表
我電腦上使用的是MySQL8.0,圖形化工具用的是Navicat.
資料庫欄位對應
id-編號、title-標題、total_price-房屋總價、unit_price-房屋單價、
square-面積、size-戶型、floor-樓層、direction-朝向、type-樓型、
district-地區、nearby-附近區域、community-小區、elevator-電梯有無、
elevatorNum-梯戶比例、ownership-房屋性質
該圖顯示的是欄位名、數據類型、長度等信息。

2、自定義數據存儲函數
這部分代碼放到Spider_wf.py文件中
通過write_csv函數將數據存入CSV文件,通過write_db函數將數據存入資料庫
點擊查看代碼
import csv
import pymysql
#寫入CSV
def write_csv(example_1):
csvfile = open('二手房數據.csv', mode='a', encoding='utf-8', newline='')
fieldnames = ['title', 'total_price', 'unit_price', 'square', 'size', 'floor','direction','type',
'BuildTime','district','nearby', 'community', 'decoration', 'elevator','elevatorNum','ownership']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writerow(example_1)
#寫入資料庫
def write_db(example_2):
conn = pymysql.connect(host='127.0.0.1',port= 3306,user='changziru',
password='ru123321',database='secondhouse_wf',charset='utf8mb4'
)
cursor =conn.cursor()
title = example_2.get('title', '')
total_price = example_2.get('total_price', '0')
unit_price = example_2.get('unit_price', '')
square = example_2.get('square', '')
size = example_2.get('size', '')
floor = example_2.get('floor', '')
direction = example_2.get('direction', '')
type = example_2.get('type', '')
BuildTime = example_2.get('BuildTime','')
district = example_2.get('district', '')
nearby = example_2.get('nearby', '')
community = example_2.get('community', '')
decoration = example_2.get('decoration', '')
elevator = example_2.get('elevator', '')
elevatorNum = example_2.get('elevatorNum', '')
ownership = example_2.get('ownership', '')
cursor.execute('insert into wf (title, total_price, unit_price, square, size, floor,direction,type,BuildTime,district,nearby, community, decoration, elevator,elevatorNum,ownership)'
'values (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)',
[title, total_price, unit_price, square, size, floor,direction,type,
BuildTime,district,nearby, community, decoration, elevator,elevatorNum,ownership])
conn.commit()#傳入資料庫
conn.close()#關閉資料庫
3、爬蟲程式實現
這部分代碼放到lianjia_house.py文件,調用項目Spider_wf.py文件中的write_csv和write_db函數
點擊查看代碼
#爬取鏈家二手房詳情頁信息
import time
from random import randint
import requests
from lxml import etree
from secondhouse_spider.Spider_wf import write_csv,write_db
#模擬瀏覽器操作
USER_AGENTS = [
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506)",
"Mozilla/4.0 (compatible; MSIE 7.0; AOL 9.5; AOLBuild 4337.35; Windows NT 5.1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)",
"Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)",
"Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0",
"Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5",
"Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.8) Gecko Fedora/1.9.0.8-1.fc10 Kazehakase/0.5.6",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; fr) Presto/2.9.168 Version/11.52",
]
#隨機USER_AGENTS
random_agent = USER_AGENTS[randint(0, len(USER_AGENTS) - 1)]
headers = {'User-Agent': random_agent,}
class SpiderFunc:
def __init__(self):
self.count = 0
def spider(self ,list):
for sh in list:
response = requests.get(url=sh, params={'param':'1'},headers={'Connection':'close'}).text
tree = etree.HTML(response)
li_list = tree.xpath('//ul[@class="sellListContent"]/li[@class="clear LOGVIEWDATA LOGCLICKDATA"]')
for li in li_list:
# 獲取每套房子詳情頁的URL
detail_url = li.xpath('.//div[@class="title"]/a/@href')[0]
try:
# 向每個詳情頁發送請求
detail_response = requests.get(url=detail_url, headers={'Connection': 'close'}).text
except Exception as e:
sleeptime = randint(15,30)
time.sleep(sleeptime)#隨機時間延遲
print(repr(e))#列印異常信息
continue
else:
detail_tree = etree.HTML(detail_response)
item = {}
title_list = detail_tree.xpath('//div[@class="title"]/h1/text()')
item['title'] = title_list[0] if title_list else None # 1簡介
total_price_list = detail_tree.xpath('//span[@class="total"]/text()')
item['total_price'] = total_price_list[0] if total_price_list else None # 2總價
unit_price_list = detail_tree.xpath('//span[@class="unitPriceValue"]/text()')
item['unit_price'] = unit_price_list[0] if unit_price_list else None # 3單價
square_list = detail_tree.xpath('//div[@class="area"]/div[@class="mainInfo"]/text()')
item['square'] = square_list[0] if square_list else None # 4面積
size_list = detail_tree.xpath('//div[@class="base"]/div[@class="content"]/ul/li[1]/text()')
item['size'] = size_list[0] if size_list else None # 5戶型
floor_list = detail_tree.xpath('//div[@class="base"]/div[@class="content"]/ul/li[2]/text()')
item['floor'] = floor_list[0] if floor_list else None#6樓層
direction_list = detail_tree.xpath('//div[@class="type"]/div[@class="mainInfo"]/text()')
item['direction'] = direction_list[0] if direction_list else None # 7朝向
type_list = detail_tree.xpath('//div[@class="area"]/div[@class="subInfo"]/text()')
item['type'] = type_list[0] if type_list else None # 8樓型
BuildTime_list = detail_tree.xpath('//div[@class="transaction"]/div[@class="content"]/ul/li[5]/span[2]/text()')
item['BuildTime'] = BuildTime_list[0] if BuildTime_list else None # 9房屋年限
district_list = detail_tree.xpath('//div[@class="areaName"]/span[@class="info"]/a[1]/text()')
item['district'] = district_list[0] if district_list else None # 10地區
nearby_list = detail_tree.xpath('//div[@class="areaName"]/span[@class="info"]/a[2]/text()')
item['nearby'] = nearby_list[0] if nearby_list else None # 11區域
community_list = detail_tree.xpath('//div[@class="communityName"]/a[1]/text()')
item['community'] = community_list[0] if community_list else None # 12小區
decoration_list = detail_tree.xpath('//div[@class="base"]/div[@class="content"]/ul/li[9]/text()')
item['decoration'] = decoration_list[0] if decoration_list else None # 13裝修
elevator_list = detail_tree.xpath('//div[@class="base"]/div[@class="content"]/ul/li[11]/text()')
item['elevator'] = elevator_list[0] if elevator_list else None # 14電梯
elevatorNum_list = detail_tree.xpath('//div[@class="base"]/div[@class="content"]/ul/li[10]/text()')
item['elevatorNum'] = elevatorNum_list[0] if elevatorNum_list else None # 15梯戶比例
ownership_list = detail_tree.xpath('//div[@class="transaction"]/div[@class="content"]/ul/li[2]/span[2]/text()')
item['ownership'] = ownership_list[0] if ownership_list else None # 16交易權屬
self.count += 1
print(self.count,title_list)
# 將爬取到的數據存入CSV文件
write_csv(item)
# 將爬取到的數據存取到MySQL資料庫中
write_db(item)
#迴圈目標網站
count =0
for page in range(1,101):
if page <=40:
url_qingzhoushi = 'https://wf.lianjia.com/ershoufang/qingzhoushi/pg' + str(page) # 青州市40
url_hantingqu = 'https://wf.lianjia.com/ershoufang/hantingqu/pg' + str(page) # 寒亭區 76
url_fangzi = 'https://wf.lianjia.com/ershoufang/fangziqu/pg' + str(page) # 坊子區
url_kuiwenqu = 'https://wf.lianjia.com/ershoufang/kuiwenqu/pg' + str(page) # 奎文區
url_gaoxin = 'https://wf.lianjia.com/ershoufang/gaoxinjishuchanyekaifaqu/pg' + str(page) # 高新區
url_jingji = 'https://wf.lianjia.com/ershoufang/jingjijishukaifaqu2/pg' + str(page) # 經濟技術85
url_shouguangshi = 'https://wf.lianjia.com/ershoufang/shouguangshi/pg' + str(page) # 壽光市 95
url_weichengqu = 'https://wf.lianjia.com/ershoufang/weichengqu/pg' + str(page) # 濰城區
list_wf = [url_qingzhoushi, url_hantingqu,url_jingji, url_shouguangshi, url_weichengqu, url_fangzi, url_kuiwenqu, url_gaoxin]
SpiderFunc().spider(list_wf)
elif page <=76:
url_hantingqu = 'https://wf.lianjia.com/ershoufang/hantingqu/pg' + str(page) # 寒亭區 76
url_fangzi = 'https://wf.lianjia.com/ershoufang/fangziqu/pg' + str(page) # 坊子區
url_kuiwenqu = 'https://wf.lianjia.com/ershoufang/kuiwenqu/pg' + str(page) # 奎文區
url_gaoxin = 'https://wf.lianjia.com/ershoufang/gaoxinjishuchanyekaifaqu/pg' + str(page) # 高新區
url_jingji = 'https://wf.lianjia.com/ershoufang/jingjijishukaifaqu2/pg' + str(page) # 經濟技術85
url_shouguangshi = 'https://wf.lianjia.com/ershoufang/shouguangshi/pg' + str(page) # 壽光市 95
url_weichengqu = 'https://wf.lianjia.com/ershoufang/weichengqu/pg' + str(page) # 濰城區
list_wf = [url_hantingqu,url_jingji, url_shouguangshi, url_weichengqu, url_fangzi, url_kuiwenqu, url_gaoxin]
SpiderFunc().spider(list_wf)
elif page<=85:
url_fangzi = 'https://wf.lianjia.com/ershoufang/fangziqu/pg' + str(page) # 坊子區
url_kuiwenqu = 'https://wf.lianjia.com/ershoufang/kuiwenqu/pg' + str(page) # 奎文區
url_gaoxin = 'https://wf.lianjia.com/ershoufang/gaoxinjishuchanyekaifaqu/pg' + str(page) # 高新區
url_jingji = 'https://wf.lianjia.com/ershoufang/jingjijishukaifaqu2/pg' + str(page) # 經濟技術85
url_shouguangshi = 'https://wf.lianjia.com/ershoufang/shouguangshi/pg' + str(page) # 壽光市 95
url_weichengqu = 'https://wf.lianjia.com/ershoufang/weichengqu/pg' + str(page) # 濰城區
list_wf = [url_jingji, url_shouguangshi, url_weichengqu, url_fangzi, url_kuiwenqu, url_gaoxin]
SpiderFunc().spider(list_wf)
elif page <=95:
url_shouguangshi = 'https://wf.lianjia.com/ershoufang/shouguangshi/pg' + str(page) # 壽光市 95
url_weichengqu = 'https://wf.lianjia.com/ershoufang/weichengqu/pg' + str(page) # 濰城區
url_fangzi = 'https://wf.lianjia.com/ershoufang/fangziqu/pg' + str(page) # 坊子區
url_kuiwenqu = 'https://wf.lianjia.com/ershoufang/kuiwenqu/pg' + str(page) # 奎文區
url_gaoxin = 'https://wf.lianjia.com/ershoufang/gaoxinjishuchanyekaifaqu/pg' + str(page) # 高新區
list_wf = [url_shouguangshi, url_weichengqu, url_fangzi, url_kuiwenqu, url_gaoxin]
SpiderFunc().spider(list_wf)
else:
url_weichengqu = 'https://wf.lianjia.com/ershoufang/weichengqu/pg' + str(page) # 濰城區
url_fangzi = 'https://wf.lianjia.com/ershoufang/fangziqu/pg' + str(page) # 坊子區
url_kuiwenqu = 'https://wf.lianjia.com/ershoufang/kuiwenqu/pg' + str(page) # 奎文區
url_gaoxin = 'https://wf.lianjia.com/ershoufang/gaoxinjishuchanyekaifaqu/pg' + str(page) # 高新區
list_wf = [url_weichengqu, url_fangzi,url_kuiwenqu, url_gaoxin]
SpiderFunc().spider(list_wf)
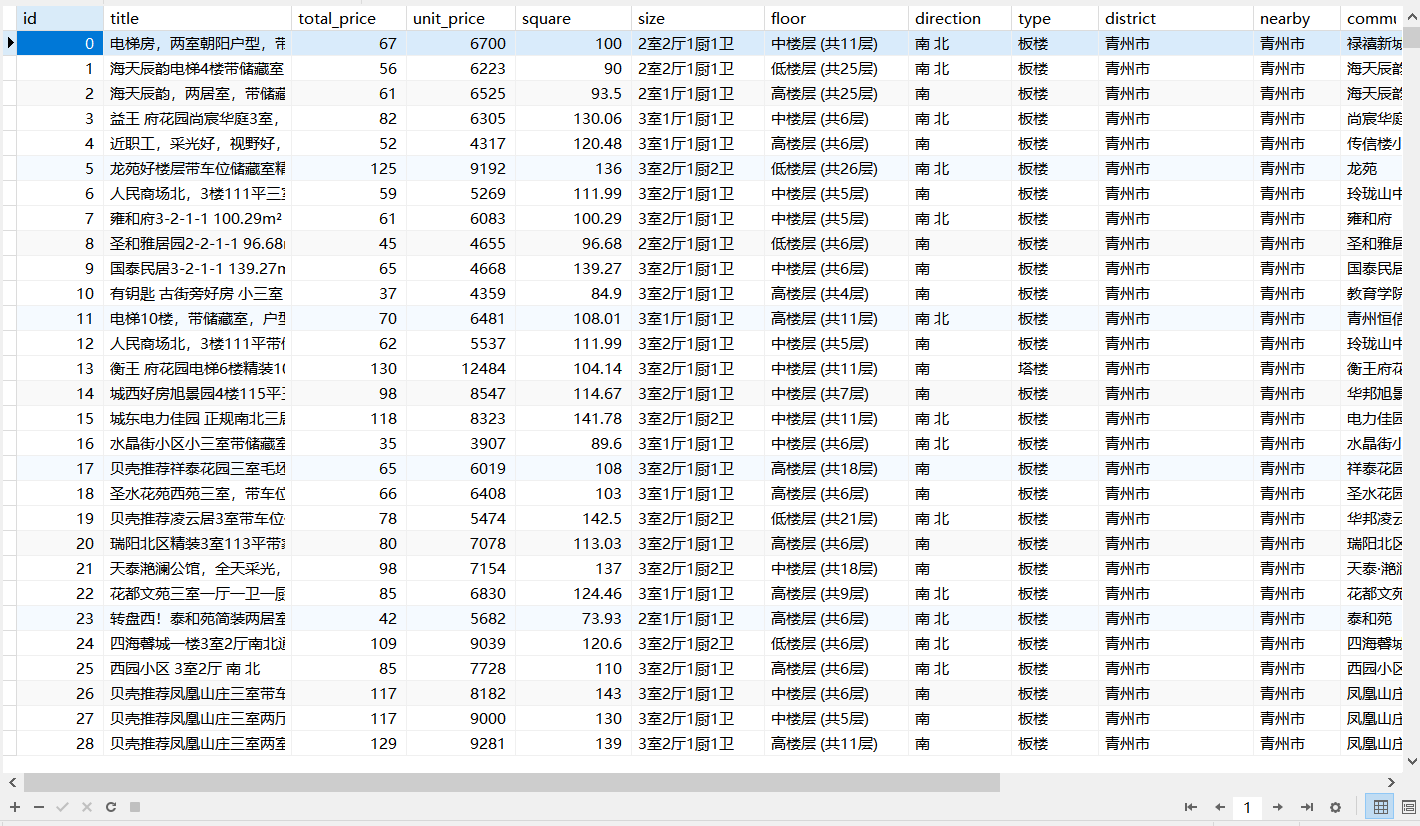
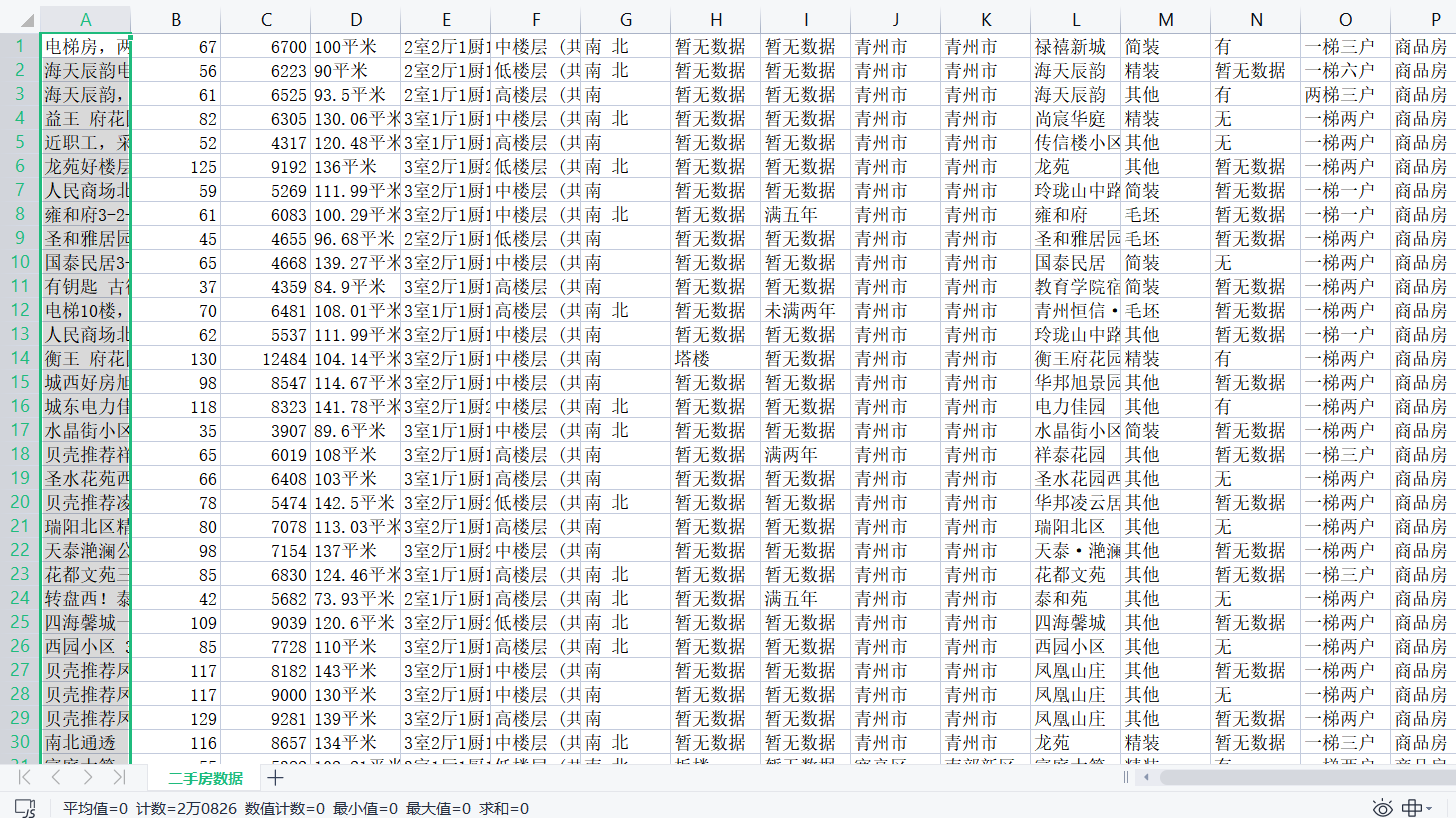
4、效果展示
總共獲取到20826條數據,
我資料庫因為要做數據分析,因而作了預處理,獲得18031條
本文來自博客園,作者:阿儒さん,轉載請註明原文鏈接:https://www.cnblogs.com/changziru/p/17229751.html


