
作者:變速風聲 鏈接:https://juejin.cn/post/7104090532015505416 前言 在開發中遇到一個業務訴求,需要在千萬量級的底池數據中篩選出不超過 10W 的數據,並根據配置的權重規則進行排序、打散(如同一個類目下的商品數據不能連續出現 3 次)。 下麵對該業務訴求的 ...
作者:變速風聲
鏈接:https://juejin.cn/post/7104090532015505416
前言
在開發中遇到一個業務訴求,需要在千萬量級的底池數據中篩選出不超過 10W 的數據,並根據配置的權重規則進行排序、打散(如同一個類目下的商品數據不能連續出現 3 次)。
下麵對該業務訴求的實現,設計思路和方案優化進行介紹,對「千萬量級數據中查詢 10W 量級的數據」設計瞭如下方案
- 多線程 + CK 翻頁方案
- ES
scroll scan深翻頁方案 - ES + Hbase 組合方案
- RediSearch + RedisJSON 組合方案
初版設計方案
整體方案設計為:
- 先根據配置的「篩選規則」,從底池表中篩選出「目標數據」
- 在根據配置的「排序規則」,對「目標數據」進行排序,得到「結果數據」
技術方案如下:
- 每天運行導數任務,把現有的千萬量級的底池數據(
Hive表)導入到 Clickhouse 中,後續使用 CK 表進行數據篩選。 - 將業務配置的篩選規則和排序規則,構建為一個「篩選 + 排序」對象
SelectionQueryCondition。 - 從 CK 底池表取「目標數據」時,開啟多線程,進行分頁篩選,將獲取到的「目標數據」存放到
result列表中。
//分頁大小 預設 5000
int pageSize = this.getPageSize();
//頁碼數
int pageCnt = totalNum / this.getPageSize() + 1;
List<Map<String, Object>> result = Lists.newArrayList();
List<Future<List<Map<String, Object>>>> futureList = new ArrayList<>(pageCnt);
//開啟多線程調用
for (int i = 1; i <= pageCnt; i++) {
//將業務配置的篩選規則和排序規則 構建為 SelectionQueryCondition 對象
SelectionQueryCondition selectionQueryCondition = buildSelectionQueryCondition(selectionQueryRuleData);
selectionQueryCondition.setPageSize(pageSize);
selectionQueryCondition.setPage(i);
futureList.add(selectionQueryEventPool.submit(new QuerySelectionDataThread(selectionQueryCondition)));
}
for (Future<List<Map<String, Object>>> future : futureList) {
//RPC 調用
List<Map<String, Object>> queryRes = future.get(20, TimeUnit.SECONDS);
if (CollectionUtils.isNotEmpty(queryRes)) {
// 將目標數據存放在 result 中
result.addAll(queryRes);
}
}
對目標數據 result 進行排序,得到最終的「結果數據」。
推薦一個開源免費的 Spring Boot 最全教程:
CK分頁查詢
在「初版設計方案」章節的第 3 步提到了「從 CK 底池表取目標數據時,開啟多線程,進行分頁篩選」。此處對 CK 分頁查詢進行介紹。
封裝了 queryPoolSkuList 方法,負責從 CK 表中獲得目標數據。該方法內部調用了 sqlSession.selectList 方法。
public List<Map<String, Object>> queryPoolSkuList( Map<String, Object> params ) {
List<Map<String, Object>> resultMaps = new ArrayList<>();
QueryCondition queryCondition = parseQueryCondition(params);
List<Map<String, Object>> mapList = lianNuDao.queryPoolSkuList(getCkDt(),queryCondition);
if (CollectionUtils.isNotEmpty(mapList)) {
for (Map<String,Object> data : mapList) {
resultMaps.add(camelKey(data));
}
}
return resultMaps;
}
// lianNuDao.queryPoolSkuList
@Autowired
@Qualifier("ckSqlNewSession")
private SqlSession sqlSession;
public List<Map<String, Object>> queryPoolSkuList( String dt, QueryCondition queryCondition ) {
queryCondition.setDt(dt);
queryCondition.checkMultiQueryItems();
return sqlSession.selectList("LianNu.queryPoolSkuList",queryCondition);
}
sqlSession.selectList 方法中調用了和 CK 交互的 queryPoolSkuList 查詢方法,部分代碼如下。
<select id="queryPoolSkuList" parameterType="com.jd.bigai.domain.liannu.QueryCondition" resultType="java.util.Map">
select sku_pool_id,i
tem_sku_id,
skuPoolName,
price,
...
...
businessType
from liannu_sku_pool_indicator_all
where
dt=#{dt}
and
<foreach collection="queryItems" separator=" and " item="queryItem" open=" " close=" " >
<choose>
<when test="queryItem.type == 'equal'">
${queryItem.field} = #{queryItem.value}
</when>
...
...
</choose>
</foreach>
<if test="orderBy == null">
group by sku_pool_id,item_sku_id
</if>
<if test="orderBy != null">
group by sku_pool_id,item_sku_id,${orderBy} order by ${orderBy} ${orderAd}
</if>
<if test="limitEnd != 0">
limit #{limitStart},#{limitEnd}
</if>
</select>
可以看到,在 CK 分頁查詢時,是通過 limit #{limitStart},#{limitEnd} 實現的分頁。
limit 分頁方案,在「深翻頁」時會存在性能問題。初版方案上線後,在 1000W 量級的底池數據中篩選 10W 的數據,最壞耗時會達到 10s~18s 左右。
使用ES Scroll Scan 優化深翻頁
對於 CK 深翻頁時候的性能問題,進行了優化,使用 Elasticsearch 的 scroll scan 翻頁方案進行優化。
ES的翻頁方案
ES 翻頁,有下麵幾種方案
from+size翻頁scroll翻頁scroll scan翻頁search after翻頁
| 翻頁方式 | 性能 | 優點 | 缺點 | 場景 |
|---|---|---|---|---|
from + size |
低 | 靈活性好,實現簡單 | 深度分頁問題 | 數據量比較小,能容忍深度分頁問題 |
scroll |
中 | 解決了深度分頁問題 | 需要維護一個 scrollId(快照版本),無法反應數據的實時性;可排序,但無法跳頁查詢 |
查詢海量數據 |
scroll scan |
中 | 基於 scroll 方案,進一步提升了海量數據查詢的性能 |
無法排序,其餘缺點同 scroll |
查詢海量數據 |
search after |
高 | 性能最好,不存在深度分頁問題,能夠反映數據的實時變更 | 實現複雜,需要有一個全局唯一的欄位。連續分頁的實現會比較複雜,因為每一次查詢都需要上次查詢的結果 | 不適用於大幅度跳頁查詢,適用於海量數據的分頁 |
對上述幾種翻頁方案,查詢不同數目的數據,耗時數據如下表。
| ES 翻頁方式 | 1-10 | 49000-49010 | 99000-99010 |
|---|---|---|---|
| from + size | 8ms | 30ms | 117ms |
| scroll | 7ms | 66ms | 36ms |
| search_after | 5ms | 8ms | 7ms |
耗時數據
此處,分別使用 Elasticsearch 的 scroll scan 翻頁方案、初版中的 CK 翻頁方案進行數據查詢,對比其耗時數據。
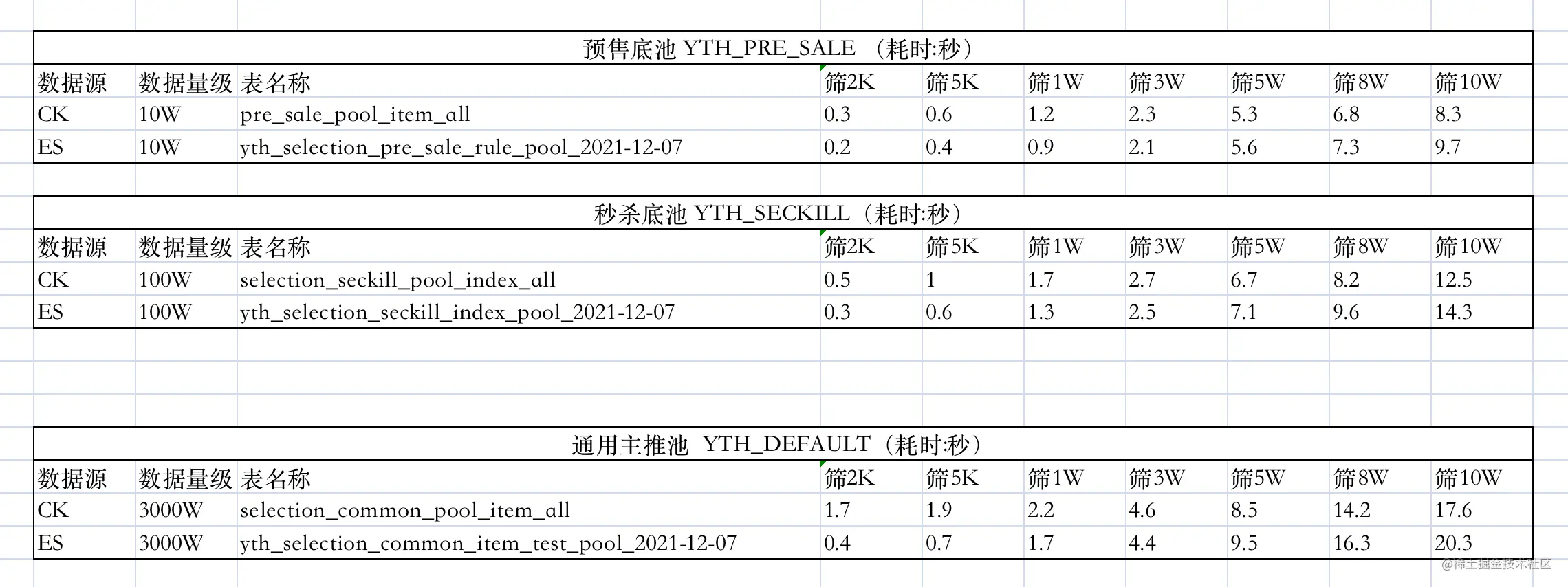
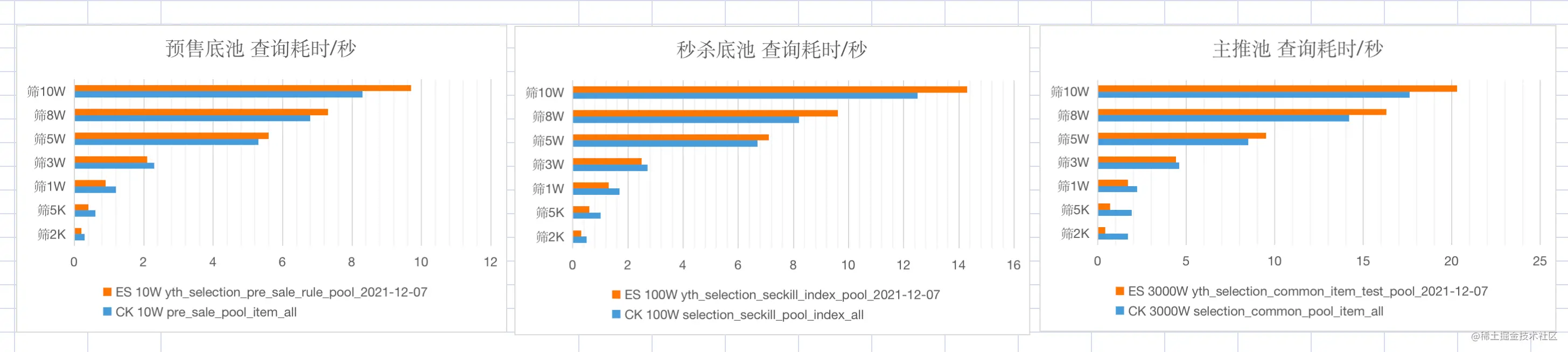
如上測試數據,可以發現,以十萬,百萬,千萬量級的底池為例
- 底池量級越大,查詢相同的數據量,耗時越大
- 查詢結果 3W 以下時,ES 性能優;查詢結果 5W 以上時,CK 多線程性能優
ES+Hbase組合查詢方案
在「使用 ES Scroll Scan 優化深翻頁」中,使用 Elasticsearch 的 scroll scan 翻頁方案對深翻頁問題進行了優化,但在實現時為單線程調用,所以最終測試耗時數據並不是特別理想,和 CK 翻頁方案性能差不多。
在調研階段發現,從底池中取出 10W 的目標數據時,一個商品包含多個欄位的信息(CK 表中一行記錄有 150 個欄位信息),如價格、會員價、學生價、庫存、好評率等。對於一行記錄,當減少獲取欄位的個數時,查詢耗時會有明顯下降。如對 sku1的商品,從之前獲取價格、會員價、學生價、親友價、庫存等 100 個欄位信息,縮減到只獲取價格、庫存這兩個欄位信息。
如下圖所示,使用 ES 查詢方案,對查詢同樣條數的場景(從千萬級底池中篩選出 7W+ 條數據),獲取的每條記錄的欄位個數從 32 縮減到 17,再縮減到 1個(其實是兩個欄位,一個是商品唯一標識 sku_id,另一個是 ES 對每條文檔記錄的 doc_id)時,查詢的耗時會從 9.3s 下降到 4.2s,再下降到 2.4s。
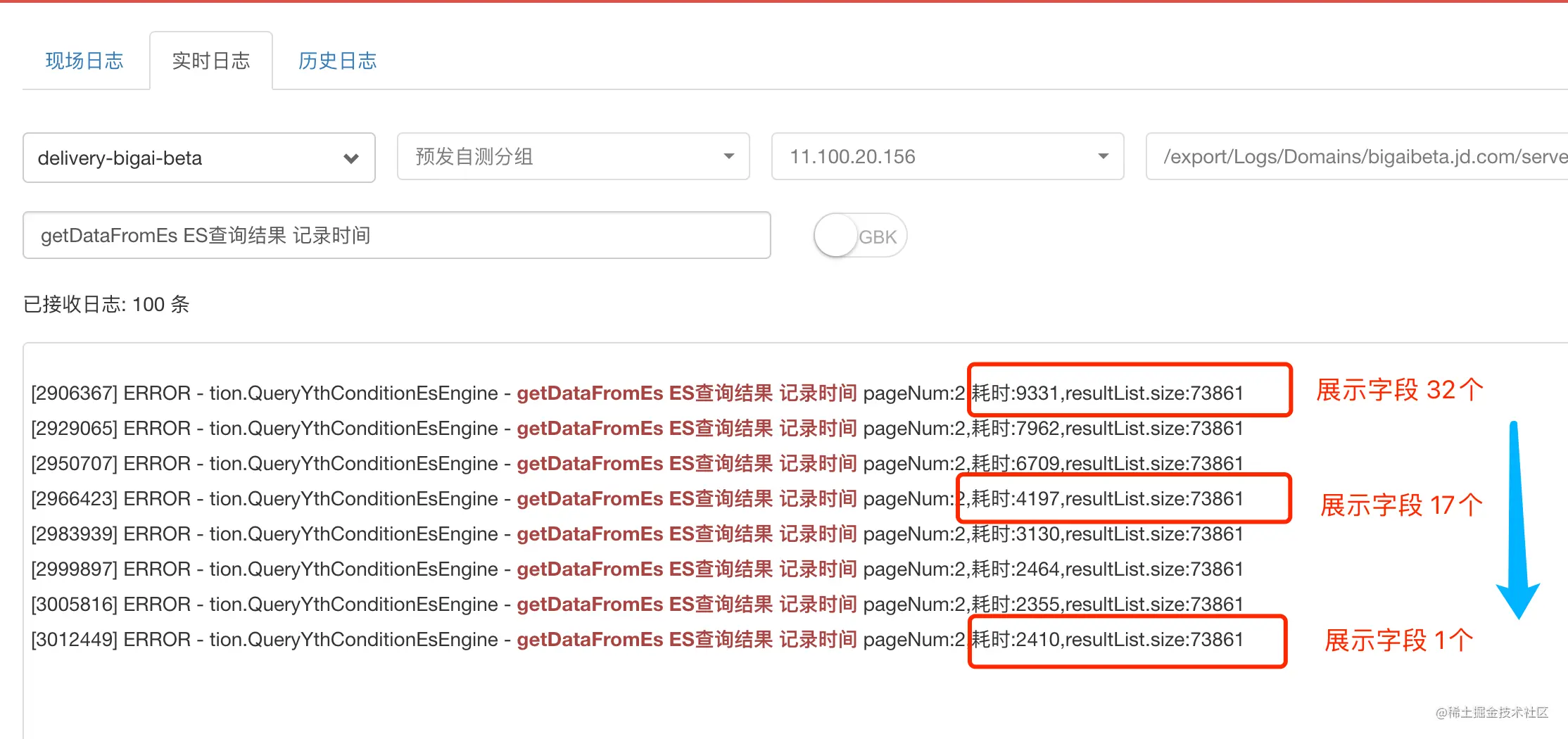
從中可以得出如下結論
- 一次 ES 查詢中,若查詢欄位和信息較多,
fetch階段的耗時,遠大於query階段的耗時。 - 一次 ES 查詢中,若查詢欄位和信息較多,通過減少不必要的查詢欄位,可以顯著縮短查詢耗時。
下麵對結論中涉及的 query 和 fetch 查詢階段進行補充說明。
ES查詢的兩個階段:query和fetch
在 ES 中,搜索一般包括兩個階段,query 和 fetch 階段
query 階段
- 根據查詢條件,確定要取哪些文檔(
doc),篩選出文檔 ID(doc_id)
fetch 階段
- 根據
query階段返回的文檔 ID(doc_id),取出具體的文檔(doc)
ES的filesystem cache
- ES 會將磁碟中的數據自動緩存到
filesystem cache,在記憶體中查找,提升了速度 - 若
filesystem cache無法容納索引數據文件,則會基於磁碟查找,此時查詢速度會明顯變慢 - 若數量兩過大,基於「ES 查詢的的 query 和 fetch 兩個階段」,可使用 ES + HBase 架構,保證 ES 的數據量小於
filesystem cache,保證查詢速度
組合使用Hbase
在上文調研的基礎上,發現「減少不必要的查詢展示欄位」可以明顯縮短查詢耗時。沿著這個優化思路,參照參考鏈接 ref-1,設計了一種新的查詢方案
- ES 僅用於條件篩選,ES 的查詢結果僅包含記錄的唯一標識
sku_id(其實還包含 ES 為每條文檔記錄的doc_id) - Hbase 是列存儲資料庫,每列數據有一個
rowKey。利用rowKey篩選一條記錄時,複雜度為O(1)。(類似於從HashMap中根據key取value) - 根據 ES 查詢返回的唯一標識
sku_id,作為 Hbase 查詢中的rowKey,在O(1)複雜度下獲取其他信息欄位,如價格,庫存等。
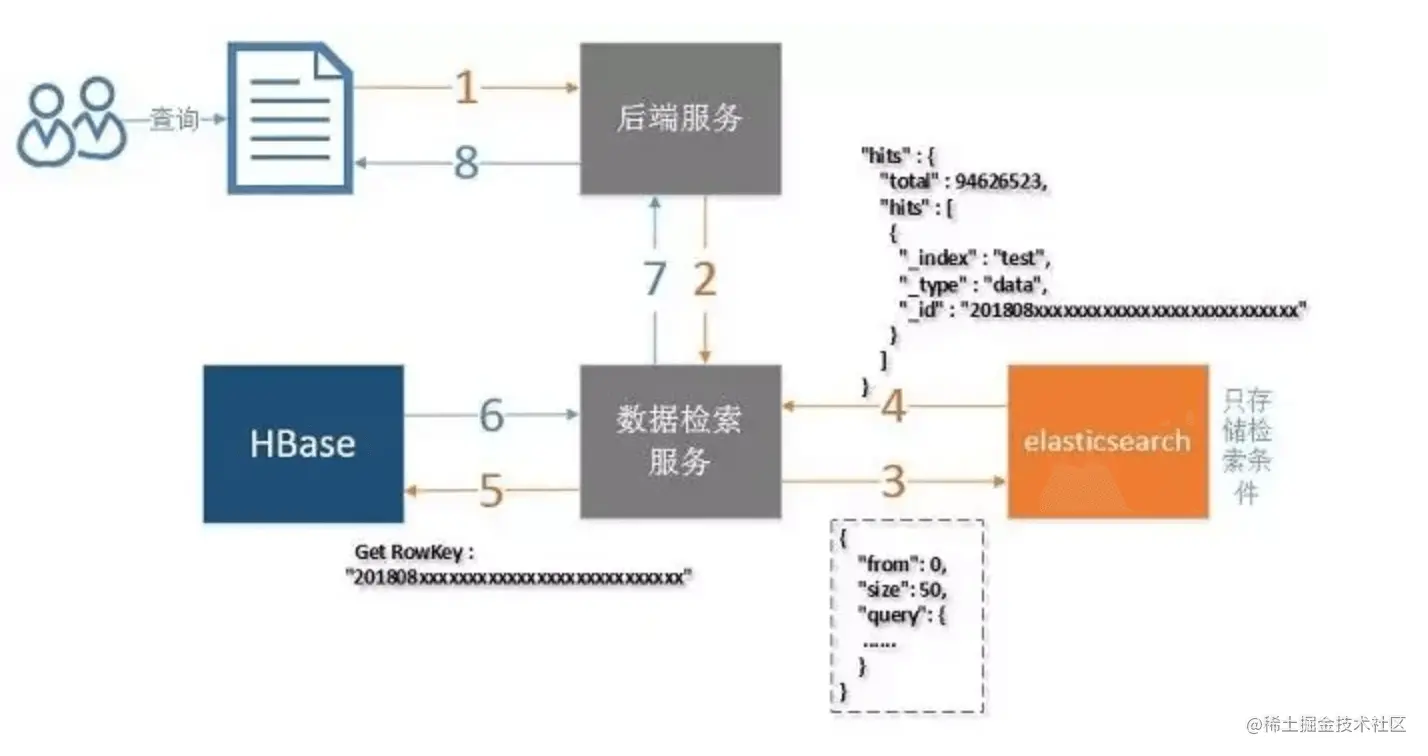
使用 ES + Hbase 組合查詢方案,線上上進行了小規模的灰度測試。在 1000W 量級的底池數據中篩選 10W 的數據,對比 CK 翻頁方案,最壞耗時從 10~18s 優化到了 3~6s 左右。
也應該看到,使用 ES + Hbase 組合查詢方案,會增加系統複雜度,同時數據也需要同時存儲到 ES 和 Hbase。
RediSearch+RedisJSON優化方案
RediSearch 是基於 Redis 構建的分散式全文搜索和聚合引擎,能以極快的速度在 Redis 數據集上執行複雜的搜索查詢。RedisJSON 是一個 Redis 模塊,在 Redis 中提供 JSON 支持。RedisJSON 可以和 RediSearch 無縫配合,實現索引和查詢 JSON 文檔。
根據一些參考資料,RediSearch + RedisJSON 可以實現極高的性能,可謂碾壓其他 NoSQL 方案。在後續版本迭代中,可考慮使用該方案來進一步優化。
下麵給出 RediSearch + RedisJSON 的部分性能數據。
RediSearch 性能數據
在同等伺服器配置下索引了 560 萬個文檔 (5.3GB),RediSearch 構建索引的時間為 221 秒,而 Elasticsearch 為 349 秒。RediSearch 比 ES 快了 58%。
數據建立索引後,使用 32 個客戶端對兩個單詞進行檢索,RediSearch 的吞吐量達到 12.5K ops/sec,ES 的吞吐量為 3.1K ops/sec,RediSearch 比ES 要快 4 倍。同時,RediSearch 的延遲為 8ms,而 ES 為 10ms,RediSearch 延遲稍微低些。
| 對比 | Redisearch | Elasticsearch |
|---|---|---|
| 搜索引擎 | 專用引擎 | 基於 Lucene 引擎 |
| 編程語言 | C 語言 | Java |
| 存儲方案 | 記憶體 | 磁碟 |
| 協議 | Redis 序列化協議 | HTTP |
| 集群 | 企業版支持 | 支持 |
| 性能 | 簡單查詢高於 ES | 複雜查詢時高於 RediSearch |
RedisJSON 性能數據
根據官網的性能測試報告,RedisJson + RedisSearch 可謂碾壓其他 NoSQL
- 對於隔離寫入(isolated writes),RedisJSON 比 MongoDB 快 5.4 倍,比 ES 快 200 倍以上
- 對於隔離讀取(isolated reads),RedisJSON 比 MongoDB 快 12.7 倍,比 ES 快 500 倍以上
在混合工作負載場景中,實時更新不會影響 RedisJSON 的搜索和讀取性能,而 ES 會受到影響。
- RedisJSON 支持的操作數/秒比 MongoDB 高約 50 倍,比 ES 高 7 倍/秒。
- RedisJSON 的延遲比 MongoDB 低約 90 倍,比 ES 低 23.7 倍。
此外,RedisJSON 的讀取、寫入和負載搜索延遲,在更高的百分位數中遠比 ES 和 MongoDB 穩定。當增加寫入比率時,RedisJSON 還能處理越來越高的整體吞吐量。而當寫入比率增加時,ES 會降低它可以處理的整體吞吐量。
總結
本文從一個業務訴求觸發,對「千萬量級數據中查詢 10W 量級的數據」介紹了不同的設計方案。對於「在 1000W 量級的底池數據中篩選 10W 的數據」的場景,不同方案的耗時如下
- 多線程 + CK 翻頁方案,最壞耗時為 10s~18s
- 單線程 + ES
scroll scan深翻頁方案,相比 CK 方案,並未見到明顯優化 - ES + Hbase 組合方案,最壞耗時優化到了 3s~6s
- RediSearch + RedisJSON 組合方案,後續會實測該方案的耗時
參考資料:
- https://juejin.cn/post/7103848212154286087
- https://www.infoq.cn/article/wymrl5h80sfawg8u7ede
- https://juejin.cn/post/7042476201574662175
近期熱文推薦:
1.1,000+ 道 Java面試題及答案整理(2022最新版)
4.別再寫滿屏的爆爆爆炸類了,試試裝飾器模式,這才是優雅的方式!!
覺得不錯,別忘了隨手點贊+轉發哦!

