
作者:你呀不牛 鏈接:https://juejin.cn/post/7114669787870920734 前段時間,同事在代碼中KW掃描的時候出現這樣一條: 上面出現這樣的原因是在使用foreach對HashMap進行遍歷時,同時進行put賦值操作會有問題,異常ConcurrentModifica ...
作者:你呀不牛
鏈接:https://juejin.cn/post/7114669787870920734
前段時間,同事在代碼中KW掃描的時候出現這樣一條:
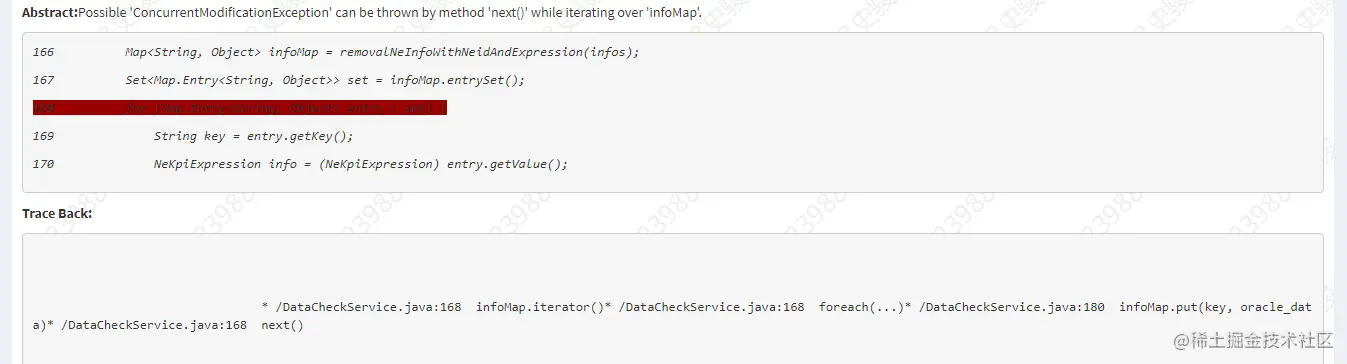
上面出現這樣的原因是在使用foreach對HashMap進行遍歷時,同時進行put賦值操作會有問題,異常ConcurrentModificationException。
於是幫同簡單的看了一下,印象中集合類在進行遍歷時同時進行刪除或者添加操作時需要謹慎,一般使用迭代器進行操作。
於是告訴同事,應該使用迭代器Iterator來對集合元素進行操作。同事問我為什麼?這一下子把我問蒙了?對啊,只是記得這樣用不可以,但是好像自己從來沒有細究過為什麼?
於是今天決定把這個HashMap遍歷操作好好地研究一番,防止採坑!
foreach迴圈?
java foreach 語法是在jdk1.5時加入的新特性,主要是當作for語法的一個增強,那麼它的底層到底是怎麼實現的呢?下麵我們來好好研究一下:
foreach 語法內部,對collection是用iterator迭代器來實現的,對數組是用下標遍歷來實現。Java 5 及以上的編譯器隱藏了基於iteration和數組下標遍歷的內部實現。
(註意,這裡說的是“Java編譯器”或Java語言對其實現做了隱藏,而不是某段Java代碼對其實現做了隱藏,也就是說,我們在任何一段JDK的Java代碼中都找不到這裡被隱藏的實現。這裡的實現,隱藏在了Java 編譯器中,查看一段foreach的Java代碼編譯成的位元組碼,從中揣測它到底是怎麼實現的了)
我們寫一個例子來研究一下:
public class HashMapIteratorDemo {
String[] arr = {"aa", "bb", "cc"};
public void test1() {
for(String str : arr) {
}
}
}
將上面的例子轉為位元組碼反編譯一下(主函數部分):
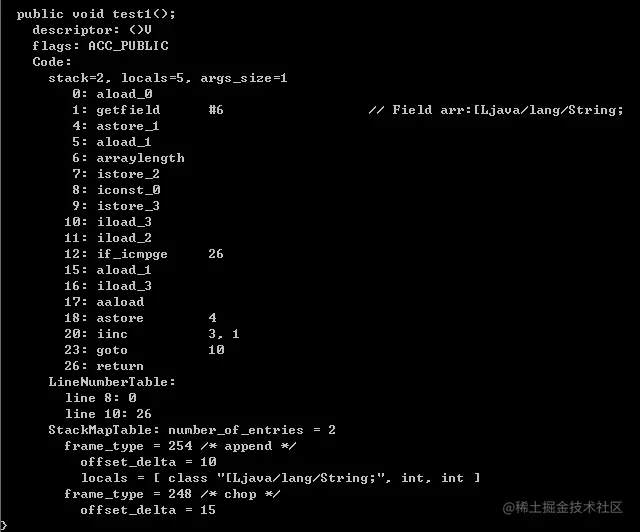
也許我們不能很清楚這些指令到底有什麼作用,但是我們可以對比一下下麵段代碼產生的位元組碼指令:
public class HashMapIteratorDemo2 {
String[] arr = {"aa", "bb", "cc"};
public void test1() {
for(int i = 0; i < arr.length; i++) {
String str = arr[i];
}
}
}

看看兩個位元組碼文件,有木有發現指令幾乎相同,如果還有疑問我們再看看對集合的foreach操作:
通過foreach遍歷集合:
public class HashMapIteratorDemo3 {
List<Integer> list = new ArrayList<>();
public void test1() {
list.add(1);
list.add(2);
list.add(3);
for(Integer var : list) {
}
}
}
通過Iterator遍歷集合:
public class HashMapIteratorDemo4 {
List<Integer> list = new ArrayList<>();
public void test1() {
list.add(1);
list.add(2);
list.add(3);
Iterator<Integer> it = list.iterator();
while(it.hasNext()) {
Integer var = it.next();
}
}
}
將兩個方法的位元組碼對比如下:
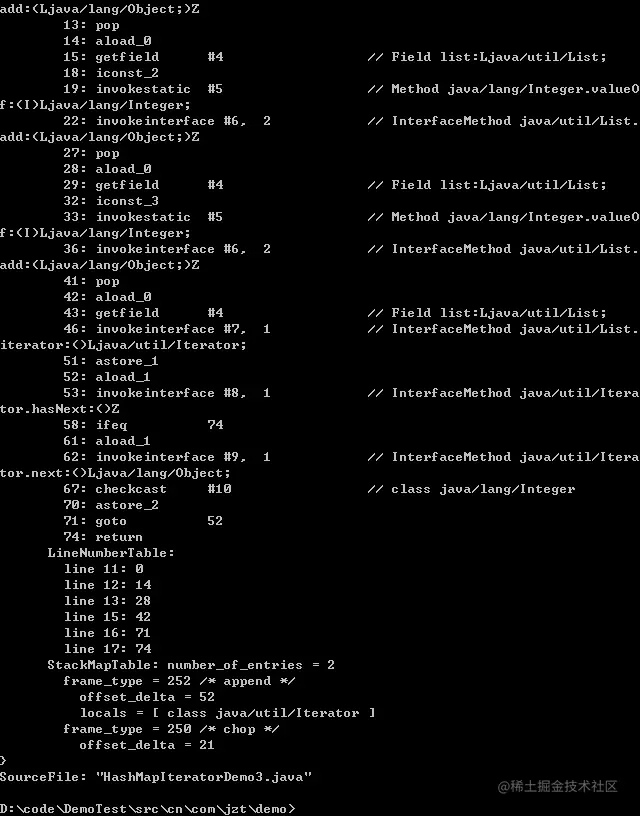
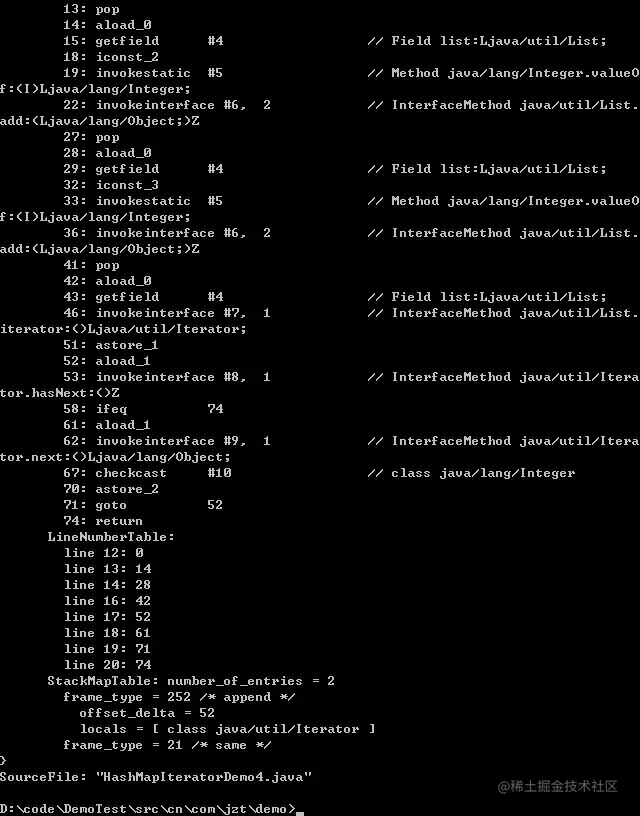
我們發現兩個方法位元組碼指令操作幾乎一模一樣;
這樣我們可以得出以下結論:
對集合來說,由於集合都實現了Iterator迭代器,foreach語法最終被編譯器轉為了對Iterator.next()的調用;
對於數組來說,就是轉化為對數組中的每一個元素的迴圈引用。
HashMap遍歷集合併對集合元素進行remove、put、add
1、現象
根據以上分析,我們知道HashMap底層是實現了Iterator迭代器的 ,那麼理論上我們也是可以使用迭代器進行遍歷的,這倒是不假,例如下麵:
public class HashMapIteratorDemo5 {
public static void main(String[] args) {
Map<Integer, String> map = new HashMap<>();
map.put(1, "aa");
map.put(2, "bb");
map.put(3, "cc");
for(Map.Entry<Integer, String> entry : map.entrySet()){
int k=entry.getKey();
String v=entry.getValue();
System.out.println(k+" = "+v);
}
}
}
輸出:

ok,遍歷沒有問題,那麼操作集合元素remove、put、add呢?
public class HashMapIteratorDemo5 {
public static void main(String[] args) {
Map<Integer, String> map = new HashMap<>();
map.put(1, "aa");
map.put(2, "bb");
map.put(3, "cc");
for(Map.Entry<Integer, String> entry : map.entrySet()){
int k=entry.getKey();
if(k == 1) {
map.put(1, "AA");
}
String v=entry.getValue();
System.out.println(k+" = "+v);
}
}
}
執行結果:

執行沒有問題,put操作也成功了。
但是!但是!但是!問題來了!!!
我們知道HashMap是一個線程不安全的集合類,如果使用foreach遍歷時,進行add,remove操作會java.util.ConcurrentModificationException異常。put操作可能會拋出該異常。(為什麼說可能,這個我們後面解釋)
為什麼會拋出這個異常呢?
我們先去看一下java api文檔對HasMap操作的解釋吧。

翻譯過來大致的意思就是該方法是返回此映射中包含的鍵的集合視圖。集合由映射支持,如果在對集合進行迭代時修改了映射(通過迭代器自己的移除操作除外),則迭代的結果是未定義的。集合支持元素移除,通過Iterator.remove、set.remove、removeAll、retainal和clear操作從映射中移除相應的映射。簡單說,就是通過map.entrySet()這種方式遍歷集合時,不能對集合本身進行remove、add等操作,需要使用迭代器進行操作。
對於put操作,如果這個操作時替換操作如上例中將第一個元素進行修改,就沒有拋出異常,但是如果是使用put添加元素的操作,則肯定會拋出異常了。我們把上面的例子修改一下:
public class HashMapIteratorDemo5 {
public static void main(String[] args) {
Map<Integer, String> map = new HashMap<>();
map.put(1, "aa");
map.put(2, "bb");
map.put(3, "cc");
for(Map.Entry<Integer, String> entry : map.entrySet()){
int k=entry.getKey();
if(k == 1) {
map.put(4, "AA");
}
String v=entry.getValue();
System.out.println(k+" = "+v);
}
}
}
執行出現異常:

這就是驗證了上面說的put操作可能會拋出java.util.ConcurrentModificationException異常。
但是有疑問了,我們上面說過foreach迴圈就是通過迭代器進行的遍歷啊?為什麼到這裡是不可以了呢?
這裡其實很簡單,原因是我們的遍歷操作底層確實是通過迭代器進行的,但是我們的remove等操作是通過直接操作map進行的,如上例子:map.put(4, "AA");//這裡實際還是直接對集合進行的操作,而不是通過迭代器進行操作。所以依然會存在ConcurrentModificationException異常問題。
2、細究底層原理
我們再去看看HashMap的源碼,通過源代碼,我們發現集合在使用Iterator進行遍歷時都會用到這個方法:
final Node<K,V> nextNode() {
Node<K,V>[] t;
Node<K,V> e = next;
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
if (e == null)
throw new NoSuchElementException();
if ((next = (current = e).next) == null && (t = table) != null) {
do {} while (index < t.length && (next = t[index++]) == null);
}
return e;
}
這裡modCount是表示map中的元素被修改了幾次(在移除,新加元素時此值都會自增),而expectedModCount是表示期望的修改次數,在迭代器構造的時候這兩個值是相等,如果在遍歷過程中這兩個值出現了不同步就會拋出ConcurrentModificationException異常。
現在我們來看看集合remove操作:
(1)HashMap本身的remove實現:

public V remove(Object key) {
Node<K,V> e;
return (e = removeNode(hash(key), key, null, false, true)) == null ?
null : e.value;
}
(2)HashMap.KeySet的remove實現
public final boolean remove(Object key) {
return removeNode(hash(key), key, null, false, true) != null;
}
(3)HashMap.EntrySet的remove實現
public final boolean remove(Object o) {
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>) o;
Object key = e.getKey();
Object value = e.getValue();
return removeNode(hash(key), key, value, true, true) != null;
}
return false;
}
(4)HashMap.HashIterator的remove方法實現
public final void remove() {
Node<K,V> p = current;
if (p == null)
throw new IllegalStateException();
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
current = null;
K key = p.key;
removeNode(hash(key), key, null, false, false);
expectedModCount = modCount; //----------------這裡將expectedModCount 與modCount進行同步
}
以上四種方式都通過調用HashMap.removeNode方法來實現刪除key的操作。在removeNode方法內只要移除了key, modCount就會執行一次自增操作,此時modCount就與expectedModCount不一致了;
final Node<K,V> removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
Node<K,V>[] tab; Node<K,V> p; int n, index;
if ((tab = table) != null && (n = tab.length) > 0 &&
...
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
if (node instanceof TreeNode)
((TreeNode<K,V>)node).removeTreeNode(this, tab, movable);
else if (node == p)
tab[index] = node.next;
else
p.next = node.next;
++modCount; //------------------------這裡對modCount進行了自增,可能會導致後面與expectedModCount不一致
--size;
afterNodeRemoval(node);
return node;
}
}
return null;
}
上面三種remove實現中,只有第三種iterator的remove方法在調用完removeNode方法後同步了expectedModCount值與modCount相同,所以在遍歷下個元素調用nextNode方法時,iterator方式不會拋異常。
到這裡是不是有一種恍然大明白的感覺呢!
所以,如果需要對集合遍歷時進行元素操作需要藉助Iterator迭代器進行,如下:
public class HashMapIteratorDemo5 {
public static void main(String[] args) {
Map<Integer, String> map = new HashMap<>();
map.put(1, "aa");
map.put(2, "bb");
map.put(3, "cc");
// for(Map.Entry<Integer, String> entry : map.entrySet()){ // int k=entry.getKey(); // // if(k == 1) {// map.put(1, "AA");// }// String v=entry.getValue(); // System.out.println(k+" = "+v); // }
Iterator<Map.Entry<Integer, String>> it = map.entrySet().iterator();
while(it.hasNext()){
Map.Entry<Integer, String> entry = it.next();
int key=entry.getKey();
if(key == 1){
it.remove();
}
}
}
}


近期熱文推薦:
1.1,000+ 道 Java面試題及答案整理(2022最新版)
4.別再寫滿屏的爆爆爆炸類了,試試裝飾器模式,這才是優雅的方式!!
覺得不錯,別忘了隨手點贊+轉發哦!


