
1、工作應用場景 統計得到每個小時的UV、PV、IP的個數,構建如下表結構: 但是表中數據的存儲格式不利於直接查詢展示,需要進行調整:(以時間分區,去重、聚合等……對結果進行行列轉換) 2、行轉列 (1)多行轉多列 case when函數 功能:用於實現對數據的判斷,根據條件,不同的情況返回不同的結 ...
SQL執行頻率
MySQL 客戶端連接成功後,通過 show [session|global] status 命令可以提供伺服器狀態信
息。通過如下指令,可以查看當前資料庫的INSERT、UPDATE、DELETE、SELECT的訪問頻次:
-- session 是查看當前會話 ;
-- global 是查詢全局數據 ;
SHOW GLOBAL STATUS LIKE 'Com_______';

假如說是以查詢為主,我們又該如何定位針對於那些查詢語句進行優化呢? 此時我們可以藉助於慢查詢日誌。
慢查詢日誌
慢查詢日誌記錄了所有執行時間超過指定參數(long_query_time,單位:秒,預設10秒)的所有
SQL語句的日誌。
MySQL的慢查詢日誌預設沒有開啟,我們可以查看一下系統變數 slow_query_log。

若要開啟慢查詢日誌,需要在mysql配置文件(/etc/my.cnf)中配置如下信息:
#開啟MySql慢日誌查詢開關:
slow_query_log=1
#設置慢日誌的時間為2s,SQL語句執行超過2s,就會視為慢查詢,記錄到慢查詢日誌
long_query_time=2
配置完畢之後,通過以下指令重新啟動MySQL:
systemctl restart mysqld
然後,再次查看開關情況,慢查詢日誌就已經打開了。

執行命令:cat /var/lib/mysql/localhost-slow.log 或者執行tail -f /var/lib/mysql/localhost-slow.log查看慢查詢日誌信息。
執行如下SQL語句 :select count(*) from tb_user;
檢查慢查詢日誌 :最終我們發現,在慢查詢日誌中,只會記錄執行時間超多我們預設時間(2s)的SQL,執行較快的SQL是不會記錄的。
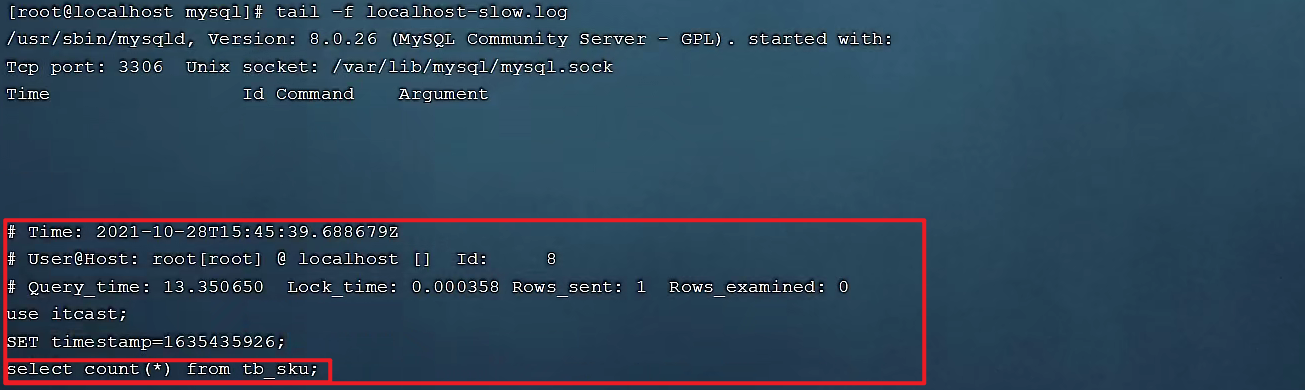
通過慢查詢日誌,就可以定位出執行效率比較低的SQL,從而有針對性的進行優化
profile詳情
show profiles 能夠在做SQL優化時幫助我們瞭解時間都耗費到哪裡去了。通過have_profiling
參數,能夠看到當前MySQL是否支持profile操作:SELECT @@have_profiling ;

可以看到,當前MySQL是支持 profile操作的,但是開關是關閉的。可以通過set語句在
session/global級別開啟profiling:
SET profiling = 1;
開關已經打開了,接下來,我們所執行的SQL語句,都會被MySQL記錄,並記錄執行時間消耗到哪兒去
了。 我們直接執行如下的SQL語句:
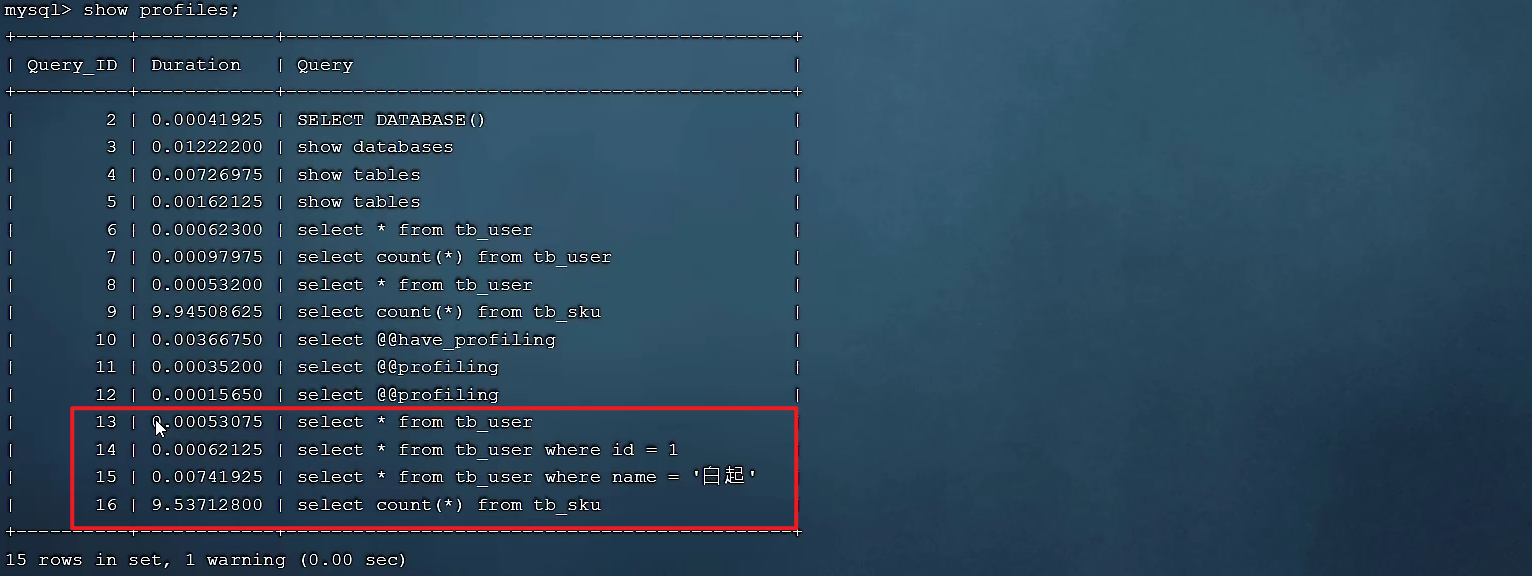
select * from tb_user;
select * from tb_user where id = 1;
select * from tb_user where name = '白起';
select count(*) from tb_sku;
執行一系列的業務SQL的操作,然後通過如下指令查看指令的執行耗時:
-- 查看每一條SQL的耗時基本情況
show profiles;
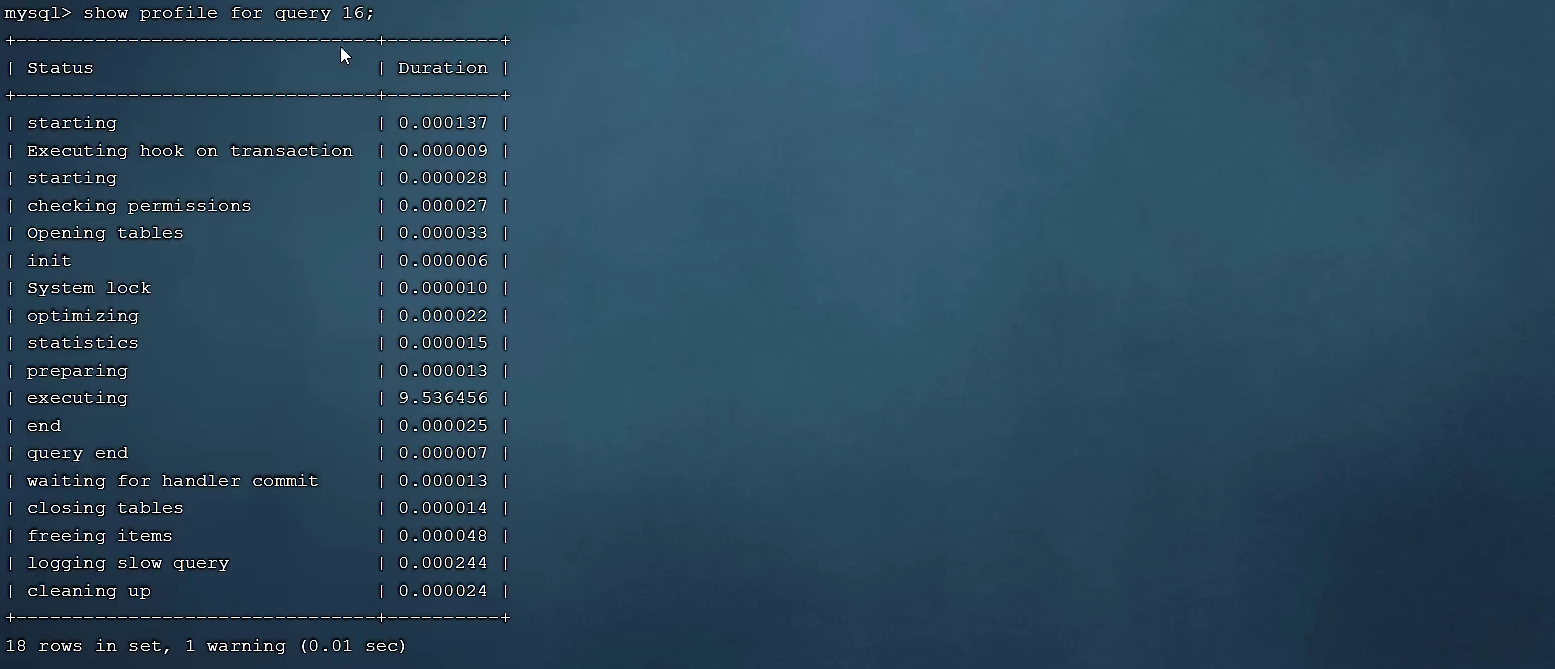
-- 查看指定query_id的SQL語句各個階段的耗時情況
show profile for query query_id;
-- 查看指定query_id的SQL語句CPU的使用情況
show profile cpu for query query_id;
查看每一條SQL的耗時情況:
查看指定SQL各個階段的耗時情況 :
explain
EXPLAIN 或者 DESC命令獲取 MySQL 如何執行 SELECT 語句的信息,包括在 SELECT 語句執行
過程中表如何連接和連接的順序。
語法:
-- 直接在select語句之前加上關鍵字 explain / desc
EXPLAIN SELECT 欄位列表 FROM 表名 WHERE 條件 ;

Explain 執行計劃中各個欄位的含義:
id:select查詢的序列號,表示查詢中執行select子句或者是操作表的順序(id相同,執行順序從上到下;id不同,值越大,越先執行)。
select_type:表示 SELECT 的類型,常見的取值有 SIMPLE(簡單表,即不使用表連接或者子查詢)、PRIMARY(主查詢,即外層的查詢)、
UNION(UNION 中的第二個或者後面的查詢語句)、
SUBQUERY(SELECT/WHERE之後包含了子查詢)等
type:表示連接類型,性能由好到差的連接類型為NULL、system、const、eq_ref、ref、range、 index、all 。
possible_key: 顯示可能應用在這張表上的索引,一個或多個。
key: 實際使用的索引,如果為NULL,則沒有使用索引。
key_len:表示索引中使用的位元組數, 該值為索引欄位最大可能長度,並非實際使用長度,在不損失精確性的前提下, 長度越短越好 。
rows:MySQL認為必須要執行查詢的行數,在innodb引擎的表中,是一個估計值,可能並不總是準確的。
filtered: 表示返回結果的行數占需讀取行數的百分比, filtered 的值越大越好。


