
程式代碼到可執行程式編譯鏈接過程 預編譯 以c++/c 語言為例,預編譯階段的工作有以下幾點: 處理所有#define 及條件預編譯指令(如 #if,#ifdef.....),並展開所有巨集定義。 刪除所有註釋("//" ,"/**/")。 處理 "#include",將被包含文件插入該預編譯指令位置 ...
程式代碼到可執行程式編譯鏈接過程
預編譯
以c++/c 語言為例,預編譯階段的工作有以下幾點:
- 處理所有#define 及條件預編譯指令(如 #if,#ifdef.....),並展開所有巨集定義。
- 刪除所有註釋("//" ,"/**/")。
- 處理 "#include",將被包含文件插入該預編譯指令位置。(整過過程遞歸進行,因為被包含文件也可能包含其他文件)
- 添加行號與文件標識。(用於調試時產生的編譯錯誤及報錯等信息)
預編譯過程相當於如下命令:
gcc -E hello.c -o hello.i (-E 表示只進行預編譯)
或者
cpp hello.c > hello.i
編譯
編譯過程可以分為如下步驟:
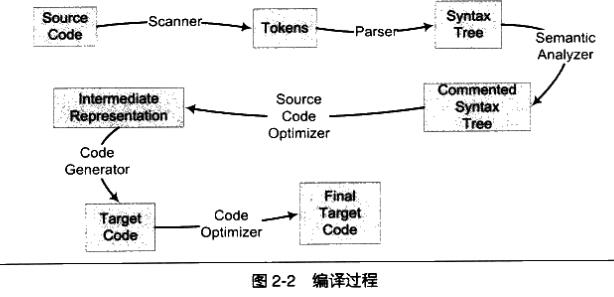
-
掃描
-
詞法分析
運用一種類似於有限狀態機的演算法,將源代碼的字元序列分割為一系列記號(關鍵字、標識符、字面常量、特殊符號等)。【一個名叫lex的程式可以完成這項任務】
-
語法分析
對由掃描器產生的記號進行語法分析,進而產生語法樹。(採用上下文無關的語法分析手段)【同樣一個叫做yacc的工具也可完成這項任務】
-
語義分析
包括靜態語義(如聲明和類型的匹配、類型的轉化等)和動態語義(運行階段才能確定)。
-
源代碼優化【這階段也包括中間代碼(例如llvm 中的 IR)的生成】
由於直接在語法樹上作優化難度較大,源代碼優化器通常將語法樹轉化為中間代碼,再進行優化。
-
目標代碼生成和目標代碼優化
代碼生成器將中間代碼轉化成目標機器代碼。
接著目標代碼優化器對上述目標代碼進行優化。(如選擇合適的定址方式,刪除多餘指令等)
編譯過程相當於如下命令:
gcc -S hello.i -o hello.s (.s 是彙編輸出文件的尾碼)
或者
gcc -S hello.c -o hello.s (預編譯和編譯合併了)
彙編
彙編器將彙編代碼轉變為機器可以執行的指令。(生成可重定位文件 .o)
編譯過程相當於如下命令:
as hello.s -o hello.o
或者
gcc -c hello.s -o hello.o
或者
gcc -c hello.c -hello.o (上面三個過程一步完成)
鏈接
對於一個複雜的軟體,將每個源代碼模塊獨立地翻譯,然後組裝。這個組裝模塊的過程就是鏈接。(主要包括地址和空間分配、符號決議、重定位等步驟)
最基本的靜態鏈接過程:每個模塊的源代碼文件(如.c)文件經過編譯器編譯成可重定位文件(Object File,擴展名為.o或.obj),可重定位文件和庫一起鏈接形成最終可執行文件(.out)。
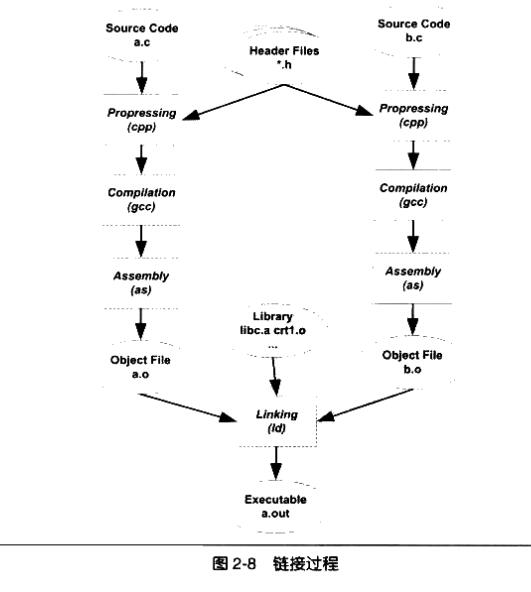
鏈接過程相當於如下命令:
gcc hello.o -o hello.out
以如下代碼為例:
#include<stdio.h>
int main()
{
printf("hello world");
return 0;
}
| 預編譯(hello.i) | 編譯(hello.s) |
|---|---|
 |
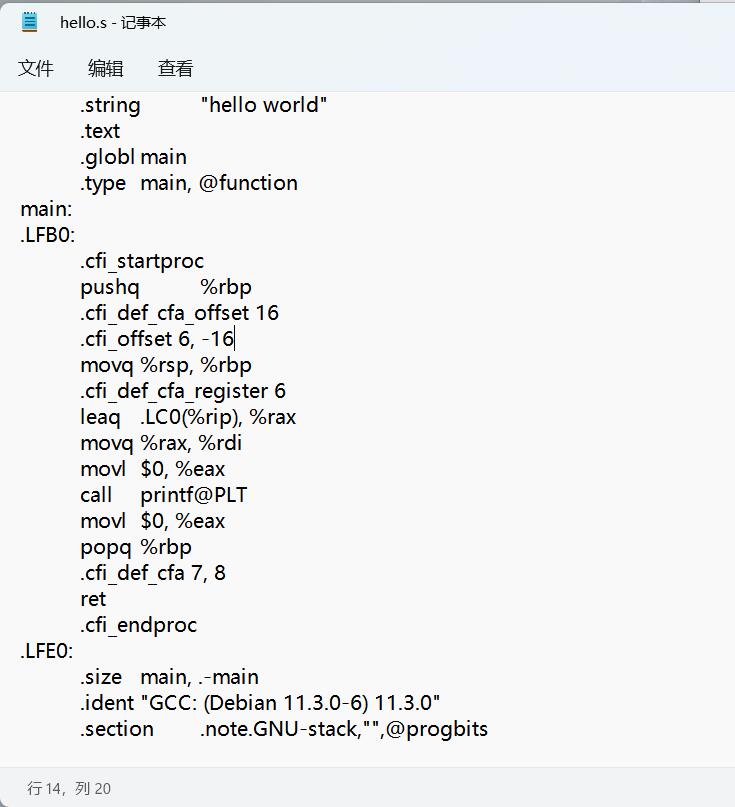 |
| 彙編(hello.o) | 鏈接(hello.out) |
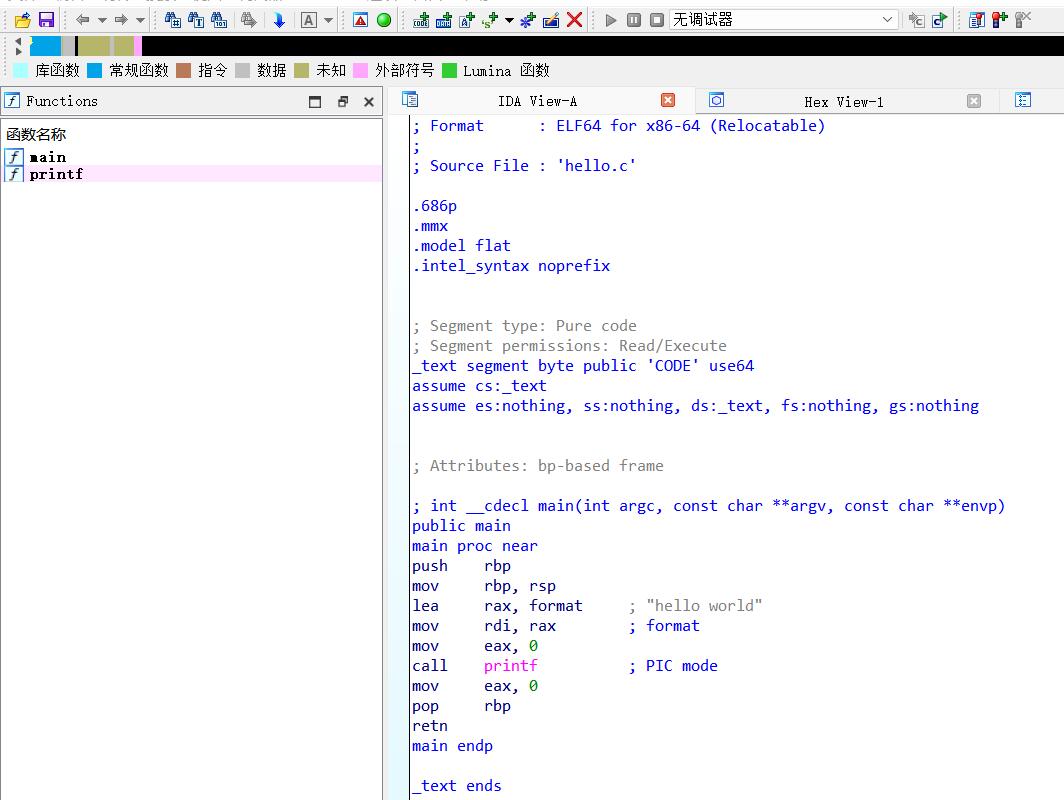 |
 |
可重定位文件 [.o 或 .obj]
可重定位文件的格式
目前PC平臺流行的可執行文件格式(Executable)主要是:
PE(Windows)和 ELF(Linux)。【兩者都發源自 COFF 可執行文件格式】
另外的如ios 是 Mach-O格式,android 是dex格式。
而可重定位文件是源代碼編譯後但未進行鏈接的中間文件。(Windows 下的.obj 和 Linux 下的.o)。
因此,可重定位文件和可執行文件的內容和結構是很相似的。(可以廣義的將二者看作一種類型的文件)
同時動態鏈接庫(Windows 下的.dll 和 Linux 下的.so)和 靜態鏈接庫(Windows 下的.lib 和 Linux 下的.a)文件都可按照可執行文件格式存儲。
【小技巧: Linux 下可使用file命令查看相應的文件格式】
程式的指令和數據分開存放的好處:
- 程式裝載後,數據和指令分別映射到兩個虛存區域。數據區域對進程而言是可讀寫的,指令區域對於進程而言是只讀的。這樣可以防止程式指令被有意或者無意地更改。
- 利於提高程式的局部性。(提高緩存的命中率)
- 當系統中運行著多個該程式副本時,記憶體中只需要保存一份該程式的指令部分。(最重要的原因)


