
一、什麼是繼承 繼承是一種新建類的方式,新建的類稱為子類,被繼承的類稱為父類 繼承的特性是:子類會遺傳父類的屬性 繼承是類與類之間的關係 二、為什麼用繼承 使用繼承可以減少代碼的冗餘 三、對象的繼承 Python中支持一個類同時繼承多個父類 class Parent1: pass class Par ...
任務目標:
對於電信運營商來說,用戶流失有很多偶然因素,不過通過對用戶屬性和行為的數字化描述,我們或許也能夠在這些數據中,挖掘導致用戶流失的“蛛絲馬跡”,並且更重要的一點,如果能夠實時接入這些數據,或許還能夠進一步藉助模型來對未來用戶流失的風險進行預測,從而及時制定輓留策略,來防止用戶真實流失情況發生。
機器學習建模目標:
在此背景下,實際的演算法建模目標有兩個,其一是對流失用戶進行預測,其二則是找出影響用戶流失的重要因數,來輔助運營人員來進行營銷策略調整或制定用戶輓留措施。
綜合上述兩個目標我們不難發現,我們要求模型不僅要擁有一定的預測能力,並且能夠輸出相應的特征重要性排名,並且最好能夠具備一定的可解釋性,也就是能夠較為明顯的闡述特征變化是如何影響標簽取值變化的。據此要求,我們首先可以考慮邏輯回歸模型。邏輯回歸的線性方程能夠提供非常好的結果可解釋性,同時我們也可以通過邏輯回歸中的正則化項也可以用於評估特征重要性。
- Stage 1.業務背景解讀與數據探索
在拿到數據(接受任務)的第一時間,需要對數據(也就是對應業務)的基本背景進行解讀。由於任何數據都誕生於某業務場景下,同時也是根據某些規則來進行的採集或者計算得出,因此如果可以,我們應當儘量去瞭解數據誕生的基本環境和對應的業務邏輯,儘可能準確的解讀每個欄位的含義,而只有在無法獲取真實業務背景時,才會考慮退而求其次通過數據情況去倒推業務情況。
當然,在進行了數據業務背景解讀後,接下來就需要對拿到的數據進行基本的數據探索。一般來說,數據探索包括數據分佈檢驗、數據正確性校驗、數據質量檢驗、訓練集/測試集規律一致性檢驗等。當然,這裡可能涉及到的操作較多,也並非所有的操作都必須在一次建模過程中全部完成。但作為教學案例,我們將在後續的內容中詳細介紹每個環節的相關操作及目的。 - Stage 2.數據預處理與特征工程
在瞭解了建模業務背景和基本數據情況後,接下來我們就需要進行實際建模前的“數據準備”工作了,也就是數據預處理(數據清洗)與特征工程。其中,數據清洗主要聚焦於數據集數據質量提升,包括缺失值、異常值、重覆值處理,以及數據欄位類型調整等;而特征工程部分則更傾向於調整特征基本結構,來使數據集本身規律更容易被模型識別,如特征衍生、特殊類型欄位處理(包括時序欄位、文本欄位等)等。
當然,很多時候我們並不刻意區分數據清洗與特征工程之間的區別,很多時候數據清洗的工作也可以看成是特征工程的一部分。同時,也有很多時候我們也不會一定要求在不同階段執行不同操作,例如如果在數據探索時發現缺失值比例較小,則可以直接對其進行均值/眾數填補,而不用等到特征工程階段統一處理,再例如很多特征工程的方法需要結合實際建模效果來判別,所以有的時候特征衍生也會和建模過程交替進行。 - Stage 3.演算法建模與模型調優
在經過一系列準備工作後,就將進入到最終建模環節了,建模過程既包括演算法訓練也包括參數調優。當然,很多時候建模工作不會一蹴而就,需要反覆嘗試各種模型、各種調參方法、以及模型融合方法。此外,很多時候我們也需要根據最終模型輸出結果來進行數據預處理和特征工程相關方法調整。
數據解讀與預處理:
獲取數據:
在數據集主頁,下載csv,放到主目錄下:
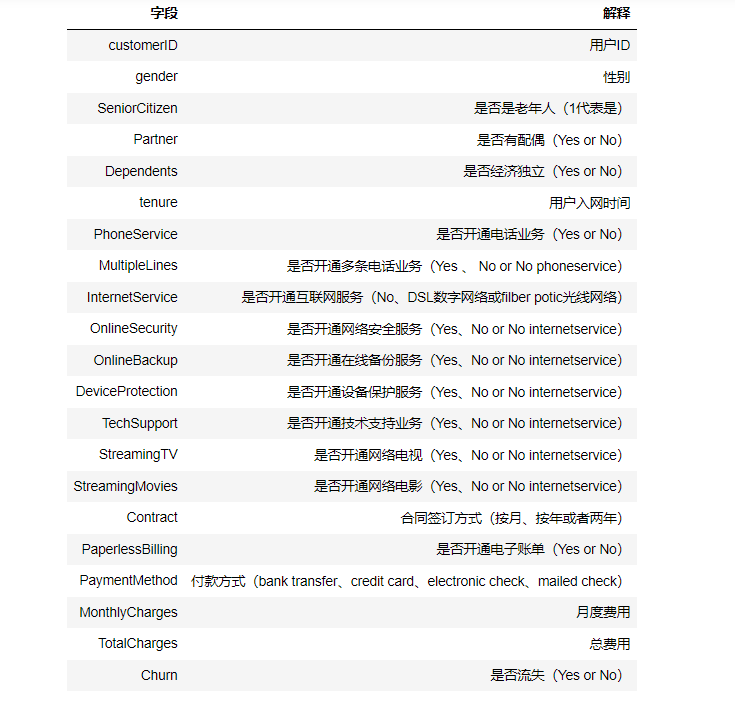
| customerID | gender | SeniorCitizen | Partner | Dependents | tenure | PhoneService | MultipleLines | InternetService | OnlineSecurity | ... | DeviceProtection | TechSupport | StreamingTV | StreamingMovies | Contract | PaperlessBilling | PaymentMethod | MonthlyCharges | TotalCharges | Churn | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 7590-VHVEG | Female | 0 | Yes | No | 1 | No | No phone service | DSL | No | ... | No | No | No | No | Month-to-month | Yes | Electronic check | 29.85 | 29.85 | No |
| 1 | 5575-GNVDE | Male | 0 | No | No | 34 | Yes | No | DSL | Yes | ... | Yes | No | No | No | One year | No | Mailed check | 56.95 | 1889.5 | No |
| 2 | 3668-QPYBK | Male | 0 | No | No | 2 | Yes | No | DSL | Yes | ... | No | No | No | No | Month-to-month | Yes | Mailed check | 53.85 | 108.15 | Yes |
| 3 | 7795-CFOCW | Male | 0 | No | No | 45 | No | No phone service | DSL | Yes | ... | Yes | Yes | No | No | One year | No | Bank transfer (automatic) | 42.30 | 1840.75 | No |
| 4 | 9237-HQITU | Female | 0 | No | No | 2 | Yes | No | Fiber optic | No | ... | No | No | No | No | Month-to-month | Yes | Electronic check | 70.70 | 151.65 | Yes |
5 rows × 21 columns
1.由於數據集沒有提供數據字典,但是可以通過欄位名字知道其意義。
得到數據以後,我們首先檢查數據的完整性。目前來看,我們得到的數據沒有預設值(沒有None和Nan),但並不排除可能存在用別的值表示缺失值的情況,稍後我們將對其進行進一步分析。
欄位類型探索:
接下來,我們應該圍繞數據集的欄位類型進行一些調整:(以方便後來我們的使用)
- 時序欄位處理
大多數欄位都屬於離散型欄位,並且object類型居多。由於建模分析中,無法直接使用object類型對象,所以進行類型轉化。通常來說,我們會將欄位劃分為連續型欄位和離散型欄位,並且根據離散欄位的具體含義來進一步區分是名義型變數還是有序變數。不過在劃分連續/離散欄位之前,我們發現數據集中存在一個入網時間欄位,看起來像是時序欄位。但是!時間標註的時序欄位即不數據連續型欄位或離散型欄位(儘管可以將其看成是離散欄位,但這樣做會損失一些信息),因此我們需要重點關註入網時間欄位是否是時間標註的欄位:
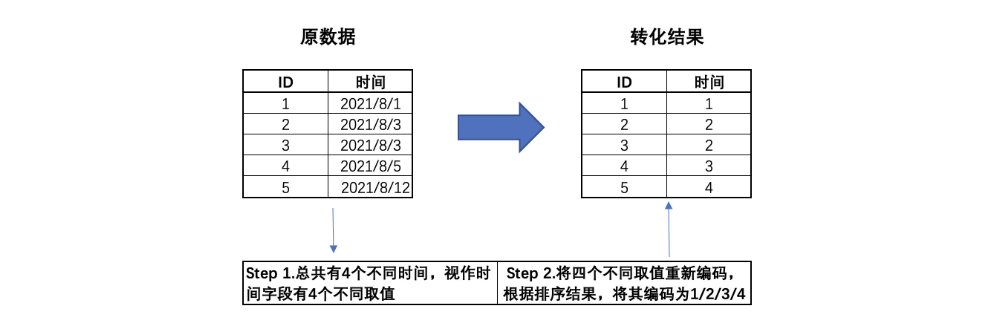
在第三季度中,這些用戶的行為發生在某73天內,因此入網時間欄位有73個取值。不過由於該欄位是經過字典排序後的結果,因此已經損失了原始信息,即每位用戶實際的入網時間。而在實際的分析過程中,我們可以轉化後的入網時間欄位看成是離散變數,當然也可以將其視作連續變數來進行分析,具體選擇需要依據模型來決定。此處我們先將其視作離散變數,後續根據情況來進行調整。
- 連續/離散型變數標註
們需要對不同類型欄位進行轉化。並且在此過程中,我們需要檢驗是否存在採用別的值來表示缺失值的情況。就像此前所說我們通過isnull只能檢驗出None(Python原生對象)和np.Nan(numpy/pandas在讀取數據文件時文件內部缺失對象的讀取後表示形式)對象。但此外我們還需要註意數據集中是否包含採用某符號表示缺失值的情況,例如某些時候可能使用空格(其本質也是一種字元)來代替空格:
此時在進行檢驗時,空格的數據並不會被識別為缺失值(空格本身也是一種值)。
但根據實際情況來看,空格可能確實是代表著數據採集時數據是缺失的,因此我們仍然需要將其識別然後標記為缺失值,此時可以通過比較數據集各列的取值水平是否和既定的一致來進行檢查。例如,對於上述df數據集來說,特征A和B預設情況只有Y和N兩種取值,而B列由於通過空格表示了缺失值,因此用nunique查看數據集的話,B列將出現3種取值:


