
前言 Pod因記憶體不足消失,可能由2種不同的故障導致,其中對故障2的復現、監控比較繁瑣、耗時、棘手; 故障1:Pod自身記憶體不足 Pod中的運行進程占用空間超出了Pod設置的Limit限制,導致該Pod中進程被Pod內的OS內核Kill掉; 此時Pod的Status為OOMKilled,Pod的OO ...
前言
Pod因記憶體不足消失,可能由2種不同的故障導致,其中對故障2的復現、監控比較繁瑣、耗時、棘手;
故障1:Pod自身記憶體不足
Pod中的運行進程占用空間超出了Pod設置的Limit限制,導致該Pod中進程被Pod內的OS內核Kill掉;
此時Pod的Status為OOMKilled,Pod的OOMKilled狀態可以藉助Promethus進行監控;


apiVersion: v1
kind: Pod
metadata:
name: memory-demo
namespace: mem-example
spec:
containers:
- name: memory-demo-ctr
image: polinux/stress
resources:
limits:
memory: "200Mi"
requests:
memory: "100Mi"
command: ["stress"]
args: ["--vm", "1", "--vm-bytes", "250M", "--vm-hang", "1"]
test-oom.yaml
現象如下
[root@master /]# kubectl delete -f test-oom.yaml pod "memory-demo" deleted [root@master /]# kubectl apply -f test-oom.yaml pod/memory-demo created [root@master /]# kubectl get pod -n mem-example -o wide -w NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES memory-demo 0/1 ContainerCreating 0 4s <none> node1 <none> <none> memory-demo 1/1 Running 0 18s 10.244.166.150 node1 <none> <none> memory-demo 0/1 OOMKilled 0 19s 10.244.166.150 node1 <none> <none>
故障2:Node宿主機記憶體不足
由於Node宿主機記憶體不足,而跑在Node宿主機上的Pod(Pod中運行的進程)占用的記憶體空間太多,被Node宿主機的OS內核OOM killed;
apiVersion: v1
kind: Pod
metadata:
name: memory-demo
namespace: mem-example
spec:
containers:
- name: memory-demo-ctr
image: polinux/stress
resources:
limits:
memory: "3Gi"
requests:
memory: "3Gi"
command: ["stress"]
args: ["--vm", "1", "--vm-bytes", "500M", "--vm-hang", "1"]
test-oom.yaml
在K8s的Node節點上經常有其他進程和Pod爭搶記憶體資源,導致該Node出現OOM現象,最終導致運行在該Node節點上Pod被OS給Kill掉;
採用監控系統和日誌系統對該現象進行監控報警,並通過日誌系統收集的日誌進行佐證;
stress --vm 4 --vm-bytes 730M --vm-keep
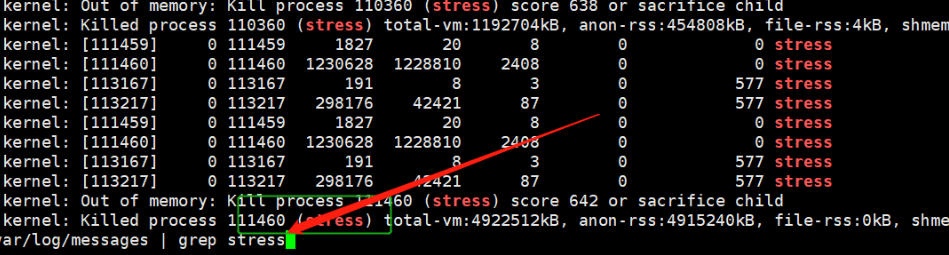
查看K8s node的/var/log/messages日誌,發現Pod中運行的stress進程,由於node宿主機記憶體不足,已經被該node宿主機的OS內核Kill掉了;
一、使用Top命令
我們平時會部署一些應用到Linux伺服器,所以經常需要瞭解伺服器的運行狀態;
Top命令是幫助我們瞭解伺服器當前的CPU、記憶體、進程狀態的實用工具;
在node宿主機使用top命令查看Pod進程的記憶體占用情況;
1.top快速入門
(base) [root@docker /]# top top - 09:57:23 up 137 days, 25 min, 2 users, load average: 0.05, 0.03, 0.05 Tasks: 148 total, 1 running, 147 sleeping, 0 stopped, 0 zombie %Cpu(s): 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st KiB Mem : 32779568 total, 31119584 free, 636676 used, 1023308 buff/cache KiB Swap: 0 total, 0 free, 0 used. 31707740 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 8753 root 20 0 822868 47888 8040 S 0.7 0.1 11:52.10 python3.8 1 root 20 0 191028 4040 2604 S 0.0 0.0 0:46.16 systemd 2 root 20 0 0 0 0 S 0.0 0.0 0:00.26 kthreadd 4 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kworker/0:0H 5 root 20 0 0 0 0 S 0.0 0.0 0:01.76 kworker/u16:0 6 root 20 0 0 0 0 S 0.0 0.0 0:00.01 ksoftirqd/0 7 root rt 0 0 0 0 S 0.0 0.0 0:00.06 migration/0 8 root 20 0 0 0 0 S 0.0 0.0 0:00.00 rcu_bh 9 root 20 0 0 0 0 S 0.0 0.0 3:13.03 rcu_sched 10 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 lru-add-drain 11 root rt 0 0 0 0 S 0.0 0.0 0:46.57 watchdog/0 12 root rt 0 0 0 0 S 0.0 0.0 0:41.06 watchdog/1 13 root rt 0 0 0 0 S 0.0 0.0 0:00.05 migration/1 14 root 20 0 0 0 0 S 0.0 0.0 0:00.02 ksoftirqd/1 16 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kworker/1:0H 17 root rt 0 0 0 0 S 0.0 0.0 0:39.13 watchdog/2 18 root rt 0 0 0 0 S 0.0 0.0 0:00.07 migration/2 19 root 20 0 0 0 0 S 0.0 0.0 0:00.01 ksoftirqd/2 21 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kworker/2:0H 22 root rt 0 0 0 0 S 0.0 0.0 0:40.14 watchdog/3
2.系統狀態概覽
第一行是對當前Linux系統情況的整體概況;
top - 09:57:23 up 137 days, 25 min, 2 users, load average: 0.05, 0.03, 0.05
top:當前處在Top命令模式,系統時間
up:Linux操作系統運行了多久
users:當前活躍用戶
load average:5分鐘、10分鐘、15分鐘之內的CPU負載
2.1.load average
Linux系統中的Load是對當前CPU工作量的度量,簡單的說是進程隊列的長度。
Load Average 就是一個時間段 (1 分鐘、5分鐘、15分鐘) 內CPU的平均 Load 。
2.2.如何衡量cpu load
假設1臺電腦只有1個CPU,所有進程中的運算任務,都必須由這1個CPU來完成。
那麼,我們不妨把這個CPU想象成1座單向通行大橋,橋上只有1根車道,所有車輛都必須從這1根車道上通過。
2.2.1.系統負荷為0
意味著大橋上1輛車也沒有。

2.2.2.系統負荷為0.5
意味著大橋的一半,被車流占用了。

2.2.3.系統負荷為1.0
意味著大橋的全部,被車流占滿了,但是直到此時該大橋還是能順暢通行的,沒有堵車;

2.2.4.系統負荷為1.7
大橋在通車的時候, 不光橋上的車流會影響通車的效率, 後面排隊等著還沒有上橋的車也增加道路的擁堵,;
如果把等待進入大橋的車,也算到負載中去, 那麼Load就會 > 1.0.
例:系統負荷為1.7,意味著車輛太多了,大橋已經被占滿了(100%),後面等待上橋的車輛為大橋上車輛的70%。

2.2.5.系統負荷高會造成什麼影響?
以此類推,系統負荷2.0,意味著等待上橋的車輛與橋面的車輛一樣多;
系統負荷3.0,意味著等待上橋的車輛是橋面車輛的2倍。
總之,當cpu load大於1時,後面的車輛(進程)就必須等待了,系統負荷越大,過橋的時間就越久。
2.3.cpu load和cpu使用率
CPU Load 低 CPU利用率低 :CPU資源良好,系統運行正常
CPU Load 低 CPU利用率高:確定程式是否有問題,少量進程消耗大量COP計算資源
CPU Load 高 CPU利用率低:程式中IO操作比較多,導致系統出現IO瓶頸;
CPU Load 高 CPU利用率高:CPU資源不足
3.進程狀態概覽
Tasks: 148 total, 1 running, 147 sleeping, 0 stopped, 0 zombie
Tasks:當前系統中運行的進程總數
Running:當前系統中處在running 狀態的進程個數
Sleeping:當前系統中處在sleeping狀態的進程個數
Stopped:當前系統中處在Stopped狀態的進程個數
Zombie:當前系統中處在Zombie狀態的進程個數,子進程比父進程先結束,父進程無法獲取到子進程的Exit狀態,該進程稱為僵屍進程。
4.CPU狀態概覽
%Cpu(s): 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
CPU分為用戶態和內核態
us:CPU在用戶態花費的時間 ,應該<60%
sy:CPU在內核態花費的時間,sy+us<80%
id:CPU在空閑狀態花費的時間
wa: 進程執行IO操作占用CPU的時間,<30%,不同功能的伺服器,閾值不一,郵件伺服器的wa很高;
5.記憶體使用概覽
以CentOS-7.6為例
[root@node1 ~]# cat /etc/centos-release CentOS Linux release 7.6.1810 (Core) [root@node1 ~]# cat /proc/version Linux version 3.10.0-957.el7.x86_64 ([email protected]) (gcc version 4.8.5 20150623 (Red Hat 4.8.5-36) (GCC) ) #1 SMP Thu Nov 8 23:39:32 UTC 2018 [root@node1 ~]#
講解Linux的記憶體
KiB Mem : 32779568 total, 31119584 free, 636676 used, 1023308 buff/cache KiB Swap: 0 total, 0 free, 0 used. 31707740 avail Mem
5.1.buff/cache占用記憶體的意義

Linux系統設計哲學之一是一切皆文件,所以該系統對IO性能要求比較高;
buffer:用於存放從記憶體即將輸出到磁碟的數據
cache:用於存放從磁碟讀取到記憶體中,待今後使用的數據
Linux借記憶體空間,造buff/cache,是為了提升Linux系統的IO性能,使Linux用起來更加流暢;
當進程可使用的記憶體空間嚴重不足時,Linux會把借用的buff/cache記憶體空間讓進程占用,雖然記憶體空間還回來了,但此時Linux會變得卡頓起來。
5.2.如何查看進程使用的記憶體空間大小
[root@node1 ~]# free -h total used free shared buff/cache available Mem: 7.1G 2.0G 2.8G 397M 2.3G 4.3G Swap: 0B 0B 0B [root@node1 ~]#
- total:total=used(進程使用的記憶體)+buff/cache(提升Linux系統的IO性能花銷的記憶體)+free(空閑的)
- used:正在運行的進程使用的記憶體(used= total – free – buff/cache)
- free: 未使用的記憶體 (free= total – used – buff/cache)
- shared:多個進程共用的記憶體
- buffers:記憶體保留用於內核操作一個進程隊列請求
- cache:在 RAM 中保存最近使用的文件的頁面緩存的大小
- buff/cache:Buffers + Cache
- available:在不使用Swap分區的前提下,預計有多少記憶體可用於將程式啟動為進程,
available = free + buffer/cache(註:只是大概的計算方法)
6.進程詳細狀態
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 8753 root 20 0 822868 47888 8040 S 0.7 0.1 11:52.10 python3.8
PID:進程編號
USER:執行進程的用戶
PR(Priority):進程優先順序,由OS決定的;(PR越低越優先被CPU調度),越低越優先
NI(Nice):進程的Nice值,用戶可以設置進程的執行優先權,root(-20到19),普通user 0-19
VIRT(Virtual memory usage ):進程需要的虛擬記憶體空間大小
RES(Resident Memory Usage):進程當前實際占用的物理記憶體大小,但不包括swap out
SHR(Shared Memory):除了自身進程的共用記憶體,也包括其他進程的共用記憶體
S(Status):進程狀態D(Dead)R(運行) T(跟蹤/停止)Z(僵屍)
%CPU:當前進程占用CPU時間的百分比
%MEM:當前進程占用記憶體空間的百分比
TIME+:當前進程使用CPU時間的總和
COMMAND:命令行
6.1.虛擬記憶體和物理記憶體的關係
虛擬記憶體和物理記憶體通過Page Table關聯起來。
虛擬記憶體空間中著色的部分,分別被映射到物理記憶體空間對應相同著色的部分。
然而虛擬記憶體空間中的灰色部分,在物理記憶體空間中沒有與之對應的部分,也就是說灰色部分沒有被映射到物理記憶體空間中。
如此設計是本著“按需映射”的指導思想。
因為虛擬記憶體空間很大,虛擬記憶體中很多部分,在1次程式運行過程中根本不需要訪問;
所以也就沒有必要,將虛擬記憶體空間中的這些不需要被訪問的部分映射到物理記憶體空間上。

6.2.虛擬記憶體(Virtual Memory)
VIRT=Swap分區+Resident Memory
虛擬記憶體是1個假象的記憶體空間,在程式運行過程中虛擬記憶體空間中需要被訪問的部分會被映射到物理記憶體空間中。
虛擬記憶體空間大隻能表示1個程式運行過程中可訪問的記憶體空間比較大,不代表占用實際物理記憶體的空間。
6.3.駐留記憶體(Resident Memory)
RES=Code+Data
駐留記憶體,是指那些被映射到虛擬記憶體空間中的物理記憶體。
上圖中,在系統物理記憶體空間中被著色的部分都是駐留記憶體。
比如,A1、A2、A3和A4是進程A的駐留記憶體,B1、B2和B3是進程B的駐留記憶體。
駐留記憶體就是進程實實在在占用的物理記憶體,一般我們所講的進程占用了多少記憶體,其實就是說的占用了多少駐留記憶體而不是多少虛擬記憶體。
因為進程的虛擬記憶體大,並不意味著進程運行過程成所占用的物理記憶體大。
6.4.共用記憶體(Shared Memory)
多個進程之間通過共用記憶體的方式相互通信也會出現了共用記憶體。
7.常用快捷鍵
- shift+e:切換記憶體單位顯示格式 (可重覆按鍵切換)
- z:換是否彩色顯示(可復按鍵換
- m: 切換記憶體使用率顯示格式(可重覆按鍵切換)
- e:切換底部各個進程詳細中單位的顯示模式 (可重覆按鍵切換)
- b:切換高亮選中 (可重覆按鍵切換)
- W:把當前配置保存到文件中,下次啟動top會使用當前的配置
- h:進入幫助菜單(進入菜單後,可按ESC或q退出幫助菜單)
- q:退出 top命令
8.欄位排序
top底部的進程列表信息是可以選擇指定列進行排序的
- 按f進入欄位選擇界面
- 按上下鍵選擇要進行排序的欄位/ space鍵選擇該欄位是否顯示
- 按下s鍵激活這個選擇
- 按q鍵退出排序欄位選擇界面
二、Node宿主機記憶體不足監控方案
cgroups,其名稱源自控制組群(control groups)的簡寫,是Linux內核的一個功能;
用來限制、控制與分離一個進程組的資源(如CPU、記憶體、磁碟輸入輸出等)。
[root@node1 43359]# ps -ef | grep stress root 43359 43338 0 16:09 ? 00:00:00 stress --vm 1 --vm-bytes 150M --vm-hang 1 root 43372 43359 5 16:09 ? 00:01:10 stress --vm 1 --vm-bytes 150M --vm-hang 1 root 62876 26220 0 16:28 pts/2 00:00:00 grep --color=auto stress [root@node1 43359]# docker inspect --format '{{.Config.Hostname}}' $(cat /proc/43359/cgroup|awk -F 'docker-' '{print $2}' |cut -c1-12| head -n 1) memory-demo [root@node1 43359]#


