
大數據時代,各行各業對數據採集的需求日益增多,網路爬蟲的運用也更為廣泛,越來越多的人開始學習網路爬蟲這項技術,K哥爬蟲此前已經推出不少爬蟲進階、逆向相關文章,為實現從易到難全方位覆蓋,特設【0基礎學爬蟲】專欄,幫助小白快速入門爬蟲,本期為 HTTP 協議的基本原理介紹。 電腦網路模型 電腦網路是 ...

大數據時代,各行各業對數據採集的需求日益增多,網路爬蟲的運用也更為廣泛,越來越多的人開始學習網路爬蟲這項技術,K哥爬蟲此前已經推出不少爬蟲進階、逆向相關文章,為實現從易到難全方位覆蓋,特設【0基礎學爬蟲】專欄,幫助小白快速入門爬蟲,本期為 HTTP 協議的基本原理介紹。
電腦網路模型
電腦網路是指由通信線路互相連接的許多自主工作的電腦構成的集合體,各個部件之間以何種規則進行通信,就是網路模型研究的問題,除了標準的 OSI 七層模型以外,常見的網路層次劃分還有 TCP/IP 四層協議以及 TCP/IP 五層協議,它們之間的對應關係如下圖所示:
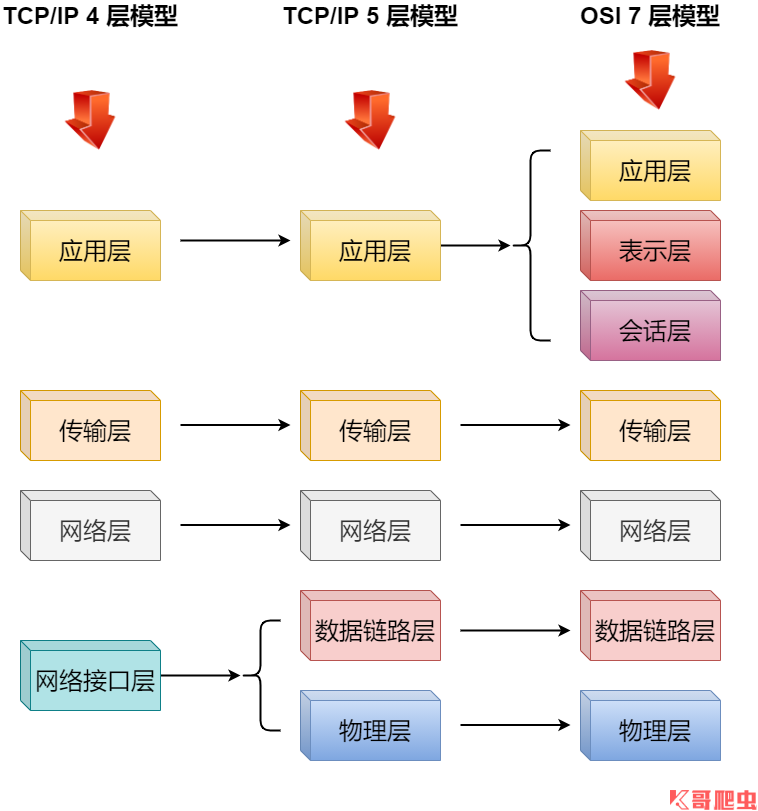
- **物理層(Physical):**負責傳輸比特流的硬體部分,包括各種傳輸介質(如銅線、光纖、無線通道)和傳輸設備(如集線器、交換機、路由器),基於電器特性發送高低電壓(電信號)傳輸比特流(Bits),高電壓對應數字 1,低電壓對應數字 0,定義物理設備標準,如網線的介面類型、光纖的介面類型、各種傳輸介質的傳輸速率等;
- **數據鏈路層(Data Link):**負責在物理層的傳輸介質上傳送數據幀,併在源主機和目的主機之間建立邏輯鏈路,定義了電信號的分組方式,規定電信號多少位一組,每組代表什麼,這一層還提供了對傳輸數據的檢測和傳輸數據錯誤的糾正以確保數據的可靠傳輸,例如:Wi-Fi(IEEE 802.11)、ethernet(乙太網)、FDDI(Fiber Distributed Data Interface,光纖分散式數據介面)等;
- **網路層(Network):**負責在多個主機之間傳送數據包,併為分組交換提供路由選擇功能,基本數據單位為 IP 數據報,主要協議:IP協議(Internet Protocol,網際網路互聯協議)、 ICMP(Internet Control Message Protocol,網際網路控制報文協議)、IGMP(Internet Group Management Protocol,Internet 組管理協議)、ARP(Address Resolution Protocol,地址解析協議)等;
- **傳輸層(Transport):**負責在源主機和目的主機之間的端到端的數據傳輸,併為上層協議提供可靠的數據傳輸服務,主要協議:TCP 協議(Transmission Control Protocol,傳輸控制協議)、UDP 協議(User Datagram Protocol,用戶數據報協議);
- **會話層(Session):**負責封裝調用 TCP,會話層建立和管理應用程式之間的通信,封裝了調用 TCP 去打包,然後調用 IP 協議去找路由等操作;
- **表示層(presentation):**負責解決不同系統之間的通信語法問題(數據格式化,代碼轉換,數據加密);
- **應用層(Application):**負責向用戶提供網路服務,包括文件傳輸、電子郵件、遠程登錄等,主要協議:FTP(文件傳送協議)、Telnet(遠程登錄協議)、DNS(功能變數名稱解析協議)、SMTP(郵件傳送協議),POP3協議(郵局協議),HTTP協議(Hyper Text Transfer Protocol)。
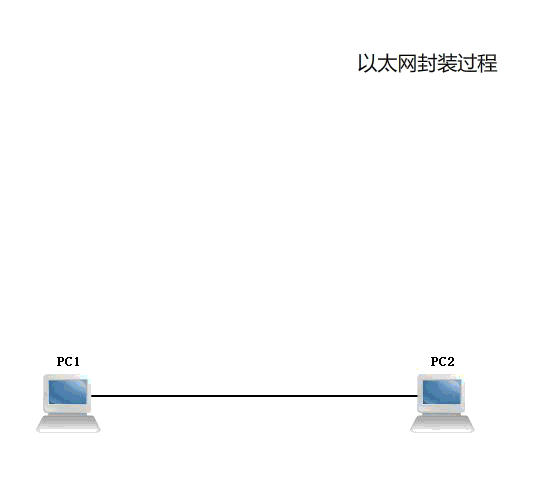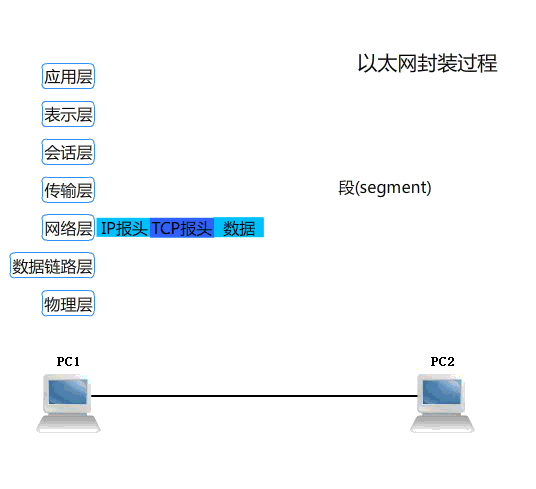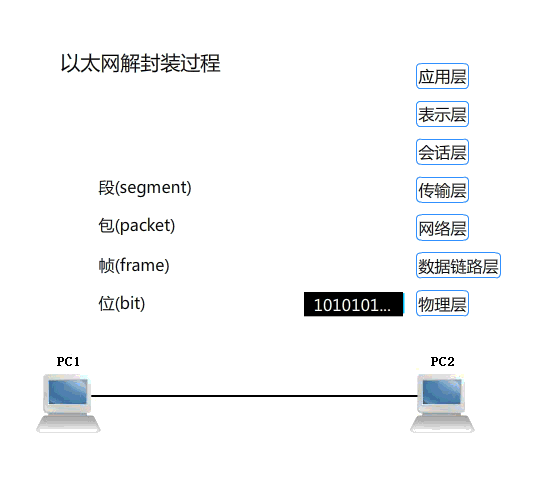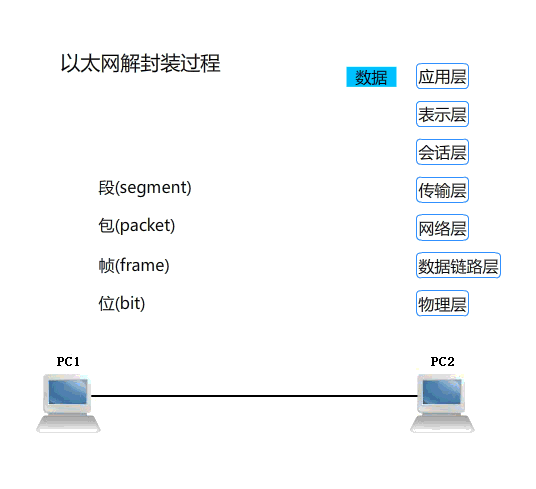
HTTP 發展史
HTTP 協議和 HTTPS 協議
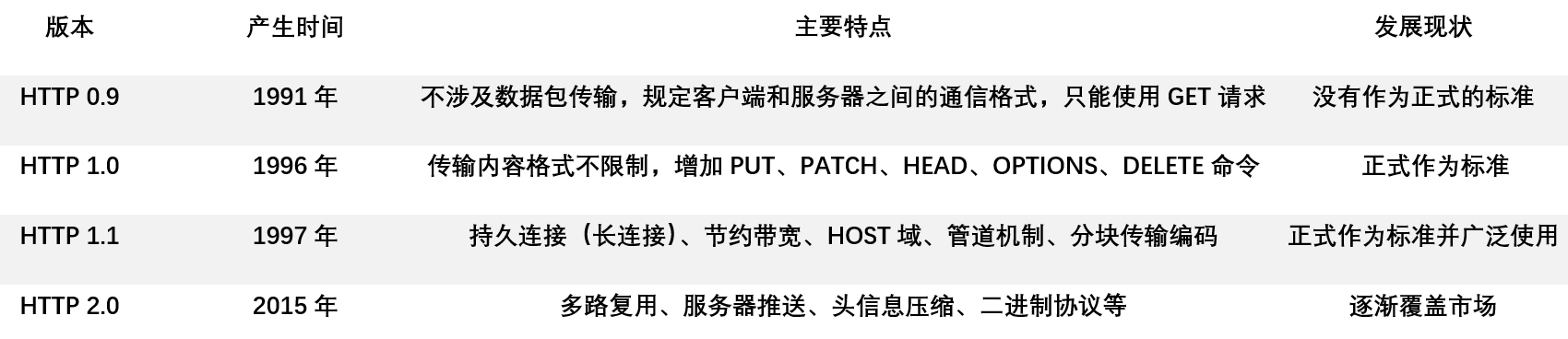
HTTP(Hypertext Transfer Protocol)中文名為超文本傳輸協議,其作用是把超文本數據從網路傳輸到本地瀏覽器,能夠高效而準確地傳輸超文本文檔。HTTP 是由萬維網協會(World Wide Web Consortium)和 Internet 工作小組 IETF(Interner Engineering Task Force)合作制定的規範,目前被廣泛使用的是 HTTP 1.1 版本,如今也有不少網站支持 HTTP 2.0 版本。
HTTP 協議的特點:
- 應用層協議,由請求和響應構成,是一個標準的客戶端伺服器模型;
- 無狀態的協議,對客戶端沒有狀態存儲,對事物處理沒有“記憶”能力,比如訪問一個網站需要反覆進行登錄操作;
- 通常承載於 TCP 協議之上;
- 由請求和響應構成,是一個標準的客戶端伺服器模型(B/S);
- 永遠都是客戶端發起請求,伺服器回送響應;
- 通信使用明文、請求和響應不會對通信方進行確認、無法保護數據的完整性;
- 雙向協議,例如在上網衝浪時,瀏覽器是請求方 A,百度網站就是應答方 B,雙方約定用 HTTP 協議來通信,於是瀏覽器把請求數據發送給網站,網站再把一些數據返回給瀏覽器,最後由瀏覽器渲染在屏幕,就可以看到圖片、視頻了。

HTTPS(Hypertext Transfer Protocol over Secure Socket Layer)是一種通過電腦網路進行安全通信的傳輸協議,經由 HTTP 進行通信,利用 SSL/TLS 建立全通道,加密數據包,HTTPS 使用的主要目的是提供對網站伺服器的身份認證,同時保護交換數據的隱私與完整性,相當於 HTTP 協議的安全版。
HTTPS 協議的特點:
- **內容加密:**建立了一個信息安全通道,保證數據傳輸的安全性;
- **身份驗證:**確認網站的真實性,凡是使用 HTTPS 協議的網站,都可以通過單機瀏覽器地址欄的鎖頭標誌來查看網站認證之後的真實信息,此外還可以通過 CA 機構頒發的安全簽章來查詢;
- **保護數據完整性:**防止傳輸的內容被中間人冒充或者篡改。
時勢發展:
- 蘋果公司強制所有 iOS APP 在2017年1月1日前全部改為使用 HTTPS 加密,否則 APP 無法在應用商店上架;
- 谷歌從2017年1月推出的 Chrome 56 開始,對未進行 HTTPS 加密的網址亮出風險提示,即在地址欄的顯著位置提示用戶”此網頁不安全“;
- 騰訊微信小程式的官方需求文檔要求後臺使用 HTTPS 請求進行網路通信,不滿足條件的功能變數名稱和協議無法正常請求。
HTTP 和 HTTPS 的區別主要如下:
- HTTPS 協議需要到 CA 申請證書,一般免費證書較少,因而需要一定費用;
- HTTP 是超文本傳輸協議,信息是明文傳輸,HTTPS 則是具有安全性的 SSL 加密傳輸協議;
- HTTP 和 HTTPS 使用的是完全不同的連接方式,用的埠也不一樣,前者是80,後者是443;
- HTTP 的連接很簡單,是無狀態的;HTTPS 協議是由 SSL+HTTP 協議構建的可進行加密傳輸、身份認證的網路協議,比 HTTP 協議安全。
上述 HTTPS 看起來是加強版的 HTTP,可圈可點,但並不是完美無缺的:
- HTTPS 協議的加密範圍也比較有限,在黑客攻擊、拒絕服務攻擊、伺服器劫持等方面幾乎起不到什麼作用;
- SSL 證書的信用鏈體系並不安全,特別是在某些國家可以控制 CA 根證書的情況下,中間人攻擊一樣可行;
- SSL 證書需要購買申請,功能越強大的證書費用越高;
- SSL 證書通常需要綁定 IP,不能在同一 IP 上綁定多個功能變數名稱,IPv4 資源不可能支撐這個消耗(SSL 有擴展可以部分解決這個問題,但是比較麻煩,而且要求瀏覽器、操作系統支持);
- 根據 ACM CoNEXT 數據顯示,使用HTTPS協議會使頁面的載入時間延長近50%,增加10%到20%的耗電;
- HTTPS 連接緩存不如 HTTP 高效,流量成本高;
- HTTPS 連接伺服器端資源占用高很多,支持訪客多的網站需要投入更大的成本;
- HTTPS 協議握手階段比較費時,對網站的響應速度有影響,影響用戶體驗,比較好的方式是採用分而治之,比如首頁用 HTTP,用戶信息相關頁用 HTTPS。
HTTP 請求過程
HTTP 由請求和響應構成,是一個標準的客戶端伺服器模型(B/S),HTTP 協議永遠都是客戶端發起請求,伺服器回送響應,HTTP 是一個無狀態的協議,無狀態是指客戶機(Web 瀏覽器)和伺服器之間不需要建立持久的連接,這意味著當一個客戶端向伺服器端發出請求,然後伺服器返迴響應(response),連接就被關閉了,在伺服器端不保留連接的有關信息,HTTP 遵循請求(Request)/應答(Response)模型,客戶機(瀏覽器)向伺服器發送請求,伺服器處理請求並返回適當的應答,所有 HTTP 連接都被構造成一套請求和應答。
HTTP 請求/響應的步驟:
- 客戶端連接到 Web 伺服器:一個 HTTP 客戶端,通常是瀏覽器,與 Web 伺服器的 HTTP 埠(預設為80)建立一個 TCP 套接字連接;
- 發送 HTTP 請求:通過 TCP 套接字,客戶端向 Web 伺服器發送一個文本的請求報文,一個請求報文由請求行、請求頭部、空行和請求數據四部分組成;
- 伺服器接受請求並返回 HTTP 響應:Web 伺服器解析請求,定位請求資源,伺服器將資源複本寫到 TCP 套接字,由客戶端讀取。一個響應由狀態行、響應頭部、空行和響應數據四部分組成;
- 釋放連接 TCP 連接:若 connection 模式為 close,則伺服器主動關閉 TCP 連接,客戶端被動關閉連接,釋放 TCP 連接;若 connection 模式為 keepalive,則該連接會保持一段時間,在該時間內可以繼續接收請求;
- 客戶端瀏覽器解析 HTML 內容:客戶端瀏覽器首先解析狀態行,查看表明請求是否成功的狀態代碼,然後解析每一個響應頭,響應頭告知以下為若幹位元組的 HTML 文檔和文檔的字元集,客戶端瀏覽器讀取響應數據 HTML,根據 HTML 的語法對其進行格式化,併在瀏覽器視窗中顯示。
步驟簡述:
- 瀏覽器向 DNS 伺服器請求解析該 URL 中的功能變數名稱所對應的 IP 地址;
- 解析出 IP 地址後,根據該 IP 地址和預設埠 80,和伺服器建立 TCP 連接;
- 瀏覽器發出讀取文件(URL 中功能變數名稱後面部分對應的文件)的 HTTP 請求,該請求報文作為 TCP 三次握手的第三個報文的數據發送給伺服器;
- 伺服器對瀏覽器請求作出響應,並把對應的 HTML 文本發送給瀏覽器;
- 釋放 TCP 連接;
- 瀏覽器將該 HTML 文本並顯示內容。
HTTP 請求/響應模型:
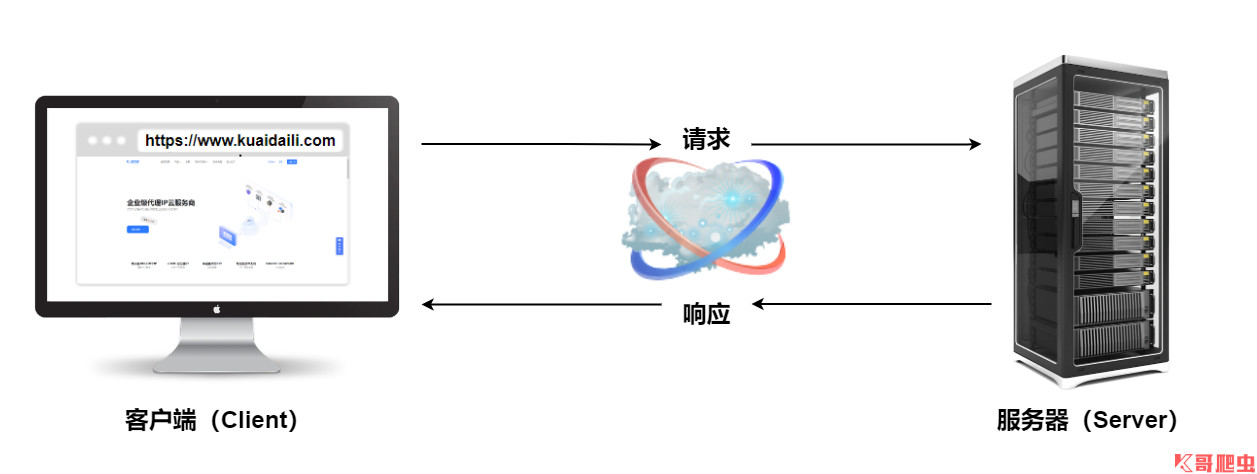
通俗點講就是在瀏覽器地址欄輸入一個 URL,按下回車之後便可觀察到對應的頁面內容,實際上,這個過程是瀏覽器先向網站所在的伺服器發送一個請求,網站伺服器接收到請求後對其進行處理和解析,然後返回對應的響應,接著傳回瀏覽器,由於響應里包含頁面的源代碼等內容,所以瀏覽器在對其進行解析,便將網頁呈現出來。
HTTP 請求方法
HTTP/1.1 協議中共定義了八種方法(有時也叫“動作”),來表明 Request-URL 指定的資源不同的操作方式,HTTP1.0 定義了三種請求方法:GET,POST 和 HEAD 方法,HTTP1.1 新增的五種請求方法:OPTIONS,PUT,DELETE,TRACE 和 CONNECT 方法:
- OPTIONS:返回伺服器針對特定資源所支持的 HTTP 請求方法,也可以利用向 web 伺服器發送 ‘*’ 的請求來測試伺服器的功能性;
- HEAD:向伺服器索與 GET 請求相一致的響應,只不過響應體將不會被返回,這一方法可以再不必傳輸整個響應內容的情況下,就可以獲取包含在響應報頭中的元信息;
- GET:向特定的資源發出請求,並返回實體主體;
- POST:向指定資源提交數據進行處理請求(例如提交表單或者上傳文件),數據被包含在請求體中,POST 請求可能會導致新的資源的建立和/或已有資源的修改;
- PUT:向指定資源位置上傳其最新內容;
- DELETE:請求伺服器刪除 Request-URL 所標識的資源;
- TRACE:回顯伺服器收到的請求,主要用於測試或診斷;
- CONNECT:把伺服器仿作跳板,讓伺服器代替客戶端訪問其他網頁。
最為常見的請求方法是 GET 和 POST,在瀏覽器地址欄輸入一個 URL,按下回車,即發起了一個 GET 請求,請求的參數會直接包含到 URL 里;POST 請求大多在提交表單時發起,例如登錄,輸入用戶名和密碼,點擊登錄即發起一個 POST 請求,其數據通常以表單的形式傳輸,而不會體現在 URL 中,GET 和 POST 請求方法區別如下:

GET 請求中的參數包含在 URL 里,數據可以在 URL 中看到;而 POST 請求的 URL 不會包含這些數據,數據都是通過表單形式傳輸的,會包含在函數體中;
GET 請求提交的數據最多只有 1024 位元組,POST 方式則沒有限制;
GET 請求是不安全的,因為在傳輸過程中,參數數據直接暴露在 URL 上,所以不能用來傳遞敏感信息;
GET 請求參數會完整的保留在瀏覽器的歷史記錄中,POST 請求的參數不會保留;
GET 請求在瀏覽器回退的時候是無害的,POST 請求會再次提交數據;
GET 請求在瀏覽器中可以被主動 cache(緩存),而 POST 請求不會,可以手動設置;
GET 請求產生的 URL 地址是可以被 bookmark(添加書簽)的,POST 請求不可以;
GET 請求只允許 ASCII 碼,POST 請求沒有限制,允許二進位數據;
GET 請求的執行效率比 POST 請求好;
對於 GET 請求,瀏覽器會把 http header 和 data 一起發送出去,伺服器響應200,請求成功;
對於POST請求,瀏覽器先發送 header,伺服器會響應100(已經收到請求的第一部分,正在等待其餘部分),瀏覽器再次發送 data,伺服器返回200,請求成功;
簡而言之:GET 產生一個 TCP 數據包,POST 產生兩個 TCP 數據包,不過並不是所有瀏覽器都會在 POST 中發送兩次包,Firefox(火狐)就只發送一次;
HTTP 請求頭
HTTP 請求頭(HTTP Request Header)提供了關於請求,響應或者其他的發送實體的信息,HTTP 的頭信息包括通用頭、請求頭、響應頭和實體頭四個部分:
- 通用頭標:即可用於請求,也可用於響應,是作為一個整體而不是特定資源與事務相關聯;
- 請求頭標:允許客戶端傳遞關於自身的信息和希望的響應形式;
- 響應頭標:伺服器和於傳遞自身信息的響應;
- 實體頭標:定義被傳送資源的信息,即可用於請求,也可用於響應。
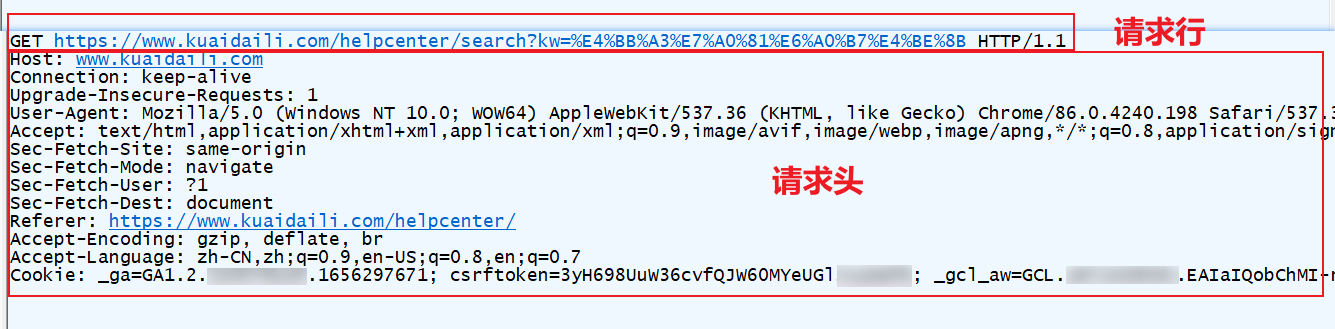
每個頭域由一個功能變數名稱,冒號(:)和域值三部分組成,常用的 HTTP 請求頭如下:
Accept:請求報頭域,用於指定客戶端可接受那些類型的信息;
Accept: application/json瀏覽器可以接受伺服器回發的類型為 application/json;Accept: */*代表瀏覽器可以處理所有類型,(一般瀏覽器發給伺服器都是發這個);Accept-Encoding:用於指定客戶端可接受的內容編碼,通常指定壓縮方法,是否支持壓縮,支持什麼壓縮方法(gzip,deflate);
Accept-Language:用於指定客戶端可接受的語言類型(zh-cn,zh;q=0.5:支持的語言分別是簡體中文和中文,優先支持簡體中文);
Content-type:也叫互聯網媒體類型(Internet Media Type)或者 MIME 類型,在 HTTP 協議消息頭中用來表示具體請求中的媒體類型信息(text/html:HTML 格式、image/gif:GIF 圖片、application/json:JSON 類型、application/x-www-form-urlencoded:表單數據、multipart/form-data:表單文件上傳等);
Host:請求報頭域主要用於指定被請求資源的 Internet 主機和埠號,其內容為請求 URL 的原始伺服器或網關的位置,從 HTTP1.1 版本開始,請求必須包含此內容;
Referer:用於標識請求是從哪個頁面發過來的,伺服器可以拿到這一信息並做相應的處理,如做來源統計、防盜鏈處理等;
User-Agent:簡稱 UA,這是一個特殊的字元串頭,可以使伺服器識別客戶端使用的操作系統及版本、瀏覽器及版本等信息;
Connection:表示是否需要持久連接(HTTP 1.1預設進行持久連接);
Date:請求發送的日期和時間;
Expect:請求的特定的伺服器行為;
Warning:關於消息實體的警告信息;
Max-Forwards:限制信息通過代理和網關傳送的時間;
Cookie:主要功能更是維持當前訪問會話,用來存儲一些用戶信息以便讓伺服器辨別用戶身份的(大多數需要登錄的網站上面會比較常見),比如 Cookie 會存儲一些用戶的用戶名和密碼,當用戶登錄後就會在客戶端產生一個 Cookie 來存儲相關信息,這樣瀏覽器通過讀取 Cookie 的信息去伺服器上驗證並通過後會判定你是合法用戶,從而允許查看相應網頁;
HTTP 響應頭
HTTP 響應頭(HTTP Responses Header)中包含了伺服器對請求的應答信息,HTTP響應也由四個部分組成,分別是:狀態行、消息報頭、空行和響應正文:
- 狀態行:由 HTTP 協議版本號, 狀態碼, 狀態消息 三部分組成;
- 消息報頭:用來說明客戶端要使用的一些附加信息;
- 空行:消息報頭後面的空行是必須的;
- 響應正文:伺服器返回給客戶端的文本信息。
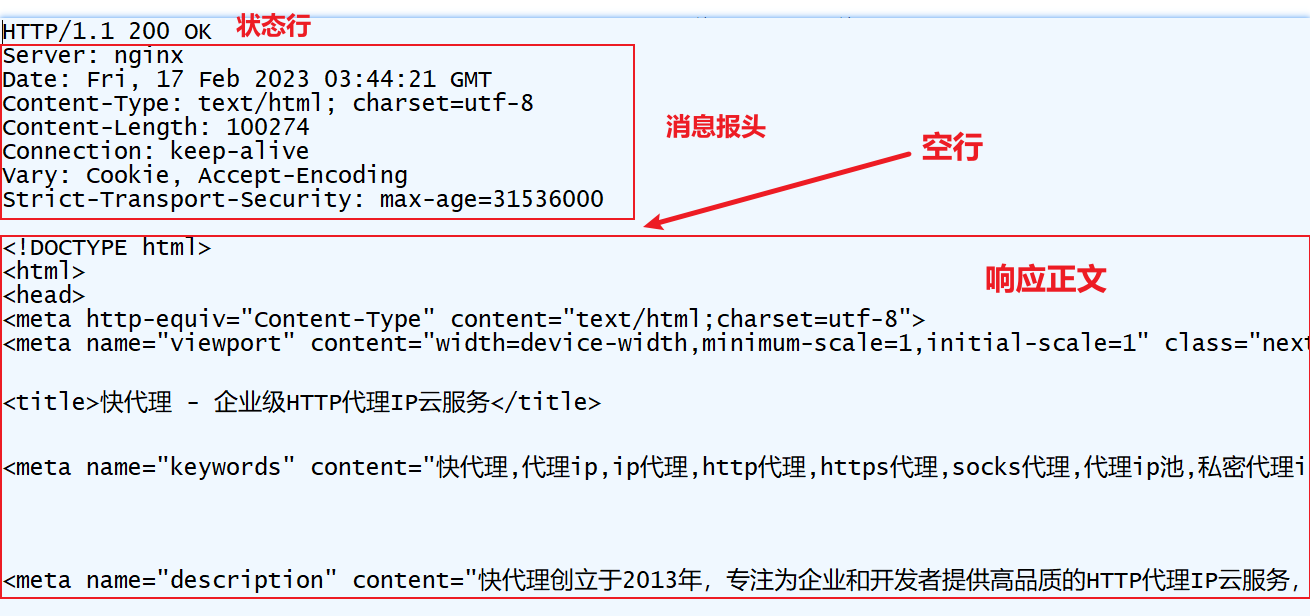
常用的 HTTP 響應頭如下:
- Accept-Ranges:表明伺服器是否支持指定範圍請求及哪種類型的分段請求;
- Allow:對某網路資源的有效的請求行為,不允許則返回405;
- Cache-Control:告訴所有的緩存機制是否可以緩存及哪種類型;
- Content-Language:響應體的語言;
- Content-Length:響應體的長度;
- Content-Location:請求資源可替代的備用的另一地址;
- Content-Range:在整個返回體中本部分的位元組位置;
- Content-Type:返回內容的 MIME 類型;
- Date:原始伺服器消息發出的時間;
- Expires:響應過期的日期和時間,可以讓代理伺服器或瀏覽器將載入的內容更新到緩存中,當再次訪問相同的內容時,就可以直接從緩存中載入,達到降低伺服器負載、縮短載入時間的目的;
- Location:用來重定向接收方到非請求 URL 的位置來完成請求或標識新的資源;
- Proxy-Authenticate:它指出認證方案和可應用到代理的該 URL 上的參數;
- refresh:應用於重定向或一個新的資源被創造,在5秒之後重定向(由網景提出,被大部分瀏覽器支持);
- Server:包含伺服器的信息,例如名稱、版本號等;
- Set-Cookie:設置 Http Cookie,響應頭中的 Set-Cookie 用於告訴瀏覽器需要將此內容放在 Cookie 中,下次請求時將 Cookie 攜帶上;
- Warning:警告實體可能存在的問題;
- WWW-Authenticate:表明客戶端請求實體應該使用的授權方案。
HTTP 響應狀態碼

**1xx:**該狀態碼表示臨時響應並需要請求者繼續執行操作
- 100(繼續):請求者應當繼續提出請求。伺服器已收到請求的第一部分,正在等待剩餘部分;
- 101(切換協議):請求者要求伺服器切換協議,伺服器也已確認切換協議;
**2xx:**該狀態碼表示成功
- 200(成功):伺服器已成功處理請求。一般這表示伺服器正常處理了請求,並且正常返回了相應的頁面;
- 201(已創建):請求成功並且伺服器成功創建新資源;
- 202(已接受):伺服器已接收請求,但仍未處理;
- 203(非授權信息):伺服器成功處理請求,但是返回的信息可能來自另外一來源;
- 204(無內容):伺服器成功處理請求,但是沒有返回任何內容;
- 205(重置內容):伺服器成功處理請求,但沒有返回任何內容;
- 206(部分內容):伺服器成功處理了部分GET請求;
**3xx:**該狀態碼表示要完成請求,需要進一步操作,通常這些狀態碼用來重定向
- 300(多鐘選擇):針對請求,伺服器可以執行多種操作。伺服器可以根據請求者的(user-agent)選擇一項操作,或者提供操作列表供請求者選擇;
- 301(永久移動):請求的網頁已永久移動到新的位置。伺服器返回該狀態碼時,會自動將請求者轉到新位置;
- 302(臨時移動):伺服器目前從不同位置的網頁響應請求,但請求者應繼續使用原有位置進行後續的請求;
- 303(查看其它位置):請求者應當對不同的位置使用單獨的 GET 請求來檢索響應時,伺服器返回此狀態碼;
- 304(未修改):自從上次請求後,請求的網頁未修改過,伺服器返回此狀態碼時,不會返回網頁內容;
- 305(使用代理):請求者只能使用代理訪問請求的網頁;
- 307(臨時重定向):伺服器目前從不同位置的網頁響應請求,但請求者應繼續使用原有位置來進行後續請求;
**4xx:**表示請求可能出錯,妨礙了伺服器的處理
- 400(錯誤請求):表示客戶端請求的語法錯誤,伺服器無法理解;
- 401(未授權):請求要求身份驗證。一般需要登錄的網站,伺服器可能會返回此狀態碼;
- 402:保留;
- 403(禁止):伺服器理解請求客戶端的請求,拒絕請求;
- 404(未找到):伺服器無法根據客戶端請求找到資源;
- 405(方法禁用):禁用請求中指定的方法;
- 406(不接受):無法使用請求的內容特性響應請求的網頁;
- 407(需要代理授權):此狀態碼與401類似,但指定請求者應當授權使用代理;
- 408(請求超時):伺服器等候請求時超時;
- 409(衝突):伺服器在完成請求是發生衝突。伺服器必須在響應中包含有關衝突的信息;
- 410(已刪除):請求的資源已永久刪除;
- 411(需要有效長度):伺服器不接受不含有效內容長度標頭欄位的請求;
- 412(未滿足前提條件):伺服器未滿足請求者在請求中設置的其中一個前提條件;
- 413(請求實體過大):相應實體過大。伺服器拒絕處理當前請求,請求超過伺服器所能處理和允許處理的最大值;
- 414(請求的url過長):請求的url過長,伺服器無法處理;
- 415(不支持的媒體類型):請求的格式不受請求頁面的支持;
- 416(請求範圍不符合要求):如果頁面無法提供請求的範圍,伺服器則會返回此狀態碼;
- 417(未滿足期望值):在請求頭 Expect 指定的預期內容無法被伺服器滿足;
- 422(不可處理的實體):請求格式正確,但由於含有語義錯誤,無法響應;
**5xx:**表示伺服器在嘗試處理請求時發生內部錯誤,這些錯誤可能是伺服器本身的錯誤,並不是請求出錯,當然也有可能是請求者的故意為之,使伺服器本身出現錯誤
- 500(伺服器內部錯誤):伺服器遇到一個未預料到的狀況,導致無法完成對請求的處理;
- 501(尚未實施):伺服器不具備完成請求的功能;
- 502(錯誤網關):伺服器作為網關或者代理,從上游伺服器收到無效響應;
- 503(服務不可用):伺服器目前無法使用;
- 504(網關超時):伺服器作為網關或代理,但未及時收到上游伺服器的響應;
- 505(HTTP版本不受支持):伺服器不支持請求中所用的 HTTP 版本。



