
本文內容整理自 博學谷狂野架構師 運行時數據區都包含什麼 虛擬機的基礎面試題 程式計數器 Java 虛擬機棧 本地方法棧 Java 堆 方法區 程式計數器 程式計數器是線程私有的,並且是JVM中唯一不會溢出的區域,用來保存線程切換時的執行行數 程式計數器(Program Counter Regist ...
本文內容整理自 博學谷狂野架構師
運行時數據區都包含什麼
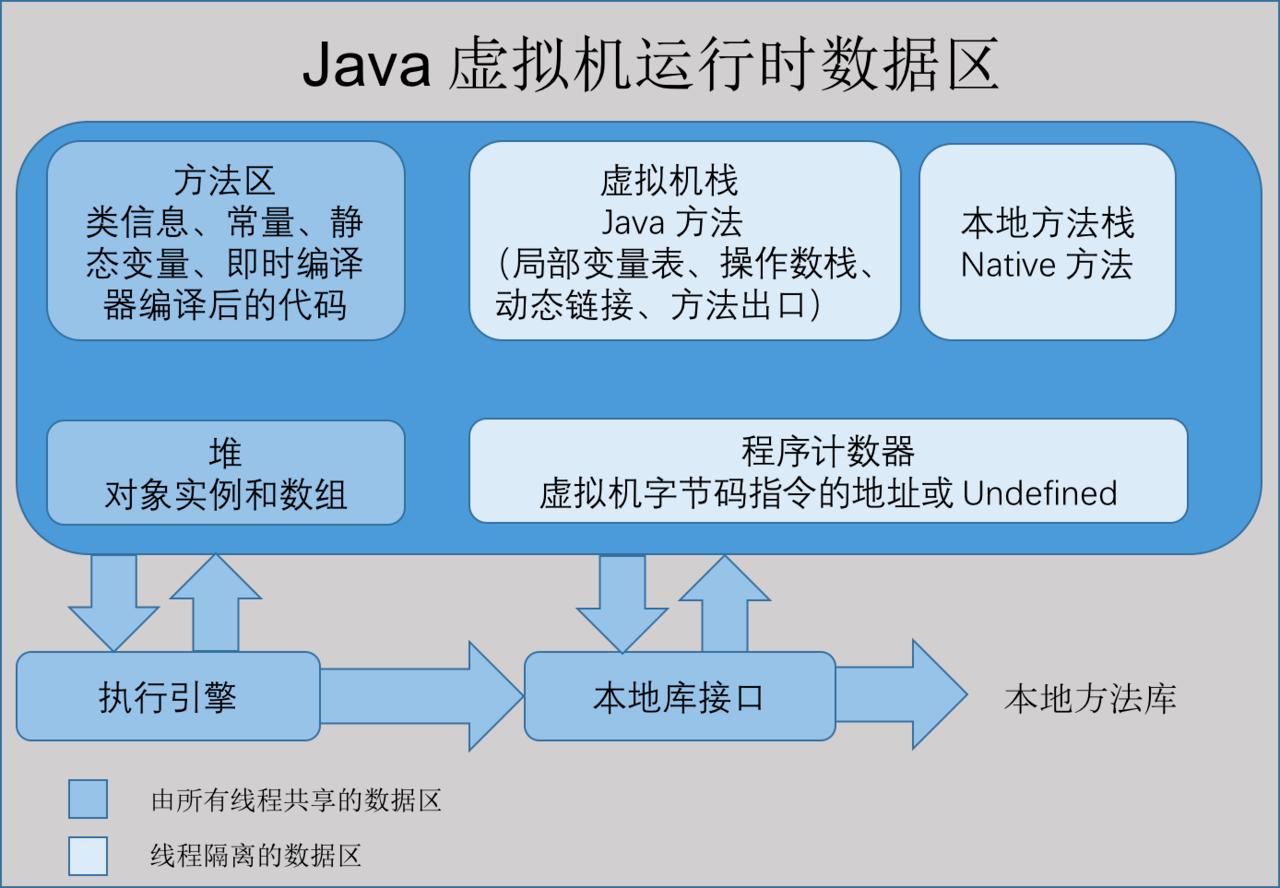
虛擬機的基礎面試題
- 程式計數器
- Java 虛擬機棧
- 本地方法棧
- Java 堆
- 方法區
程式計數器
程式計數器是線程私有的,並且是JVM中唯一不會溢出的區域,用來保存線程切換時的執行行數
程式計數器(Program Counter Register)是一塊較小的記憶體空間,可以看作是當前線程所執行位元組碼的行號指示器。分支、迴圈、跳轉、異常處理、線程恢復等基礎功能都需要依賴這個計數器完成。
由於 Java 虛擬機的多線程是通過線程輪流切換並分配處理器執行時間的方式實現的。為了線程切換後能恢復到正確的執行位置,每條線程都需要一個獨立的程式計數器,各線程之間的計數器互不影響,獨立存儲。
- 如果線程正在執行的是一個 Java 方法,計數器記錄的是正在執行的虛擬機位元組碼指令的地址;
- 如果正在執行的是 Native 方法,這個計數器的值為空。
程式計數器是唯一一個沒有規定任何 OutOfMemoryError 的區域
虛擬機棧
Java 虛擬機棧(Java Virtual Machine Stacks)是線程私有的,生命周期與線程相同。
虛擬機棧描述的是 Java 方法執行的記憶體模型:每個方法被執行的時候都會創建一個棧幀(Stack Frame),存儲
每一個方法被調用到執行完成的過程,就對應著一個棧幀在虛擬機棧中從入棧到出棧的過程
組成部分
- 局部變數表
- 操作數棧
- 動態鏈接
- 方法出口
異常情況
- StackOverflowError:線程請求的棧深度大於虛擬機所允許的深度
- OutOfMemoryError:虛擬機棧擴展到無法申請足夠的記憶體時
本地方法棧
本地方法棧(Native Method Stacks)為虛擬機使用到的 Native 方法服務
Java 堆
Java 堆(Java Heap)是 Java 虛擬機中記憶體最大的一塊。Java 堆在虛擬機啟動時創建,被所有線程共用。
作用:存放對象實例。垃圾收集器主要管理的就是 Java 堆。Java 堆在物理上可以不連續,只要邏輯上連續即可。
包含元素
- 對象
- 數組
- 非靜態變數
有什麼異常
- java.lang.OutOfMemoryError: Java heap space:這種是java堆記憶體不夠,一個原因是真不夠,另一個原因是程式中有死迴圈
- java.lang.OutOfMemoryError: GC overhead limit exceeded:JDK6新增錯誤類型,當GC為釋放很小空間占用大量時間時拋出
方法區
方法區(Method Area)被所有線程共用,用於存儲已被虛擬機載入的類信息、常量、靜態變數、即時編譯器編譯後的代碼等數據。
和 Java 堆一樣,不需要連續的記憶體,可以選擇固定的大小,更可以選擇不實現垃圾收集。
垃圾回收演算法有哪些
常用的垃圾回收演算法有如下四種:標記-清除、複製、標記-整理和分代收集。
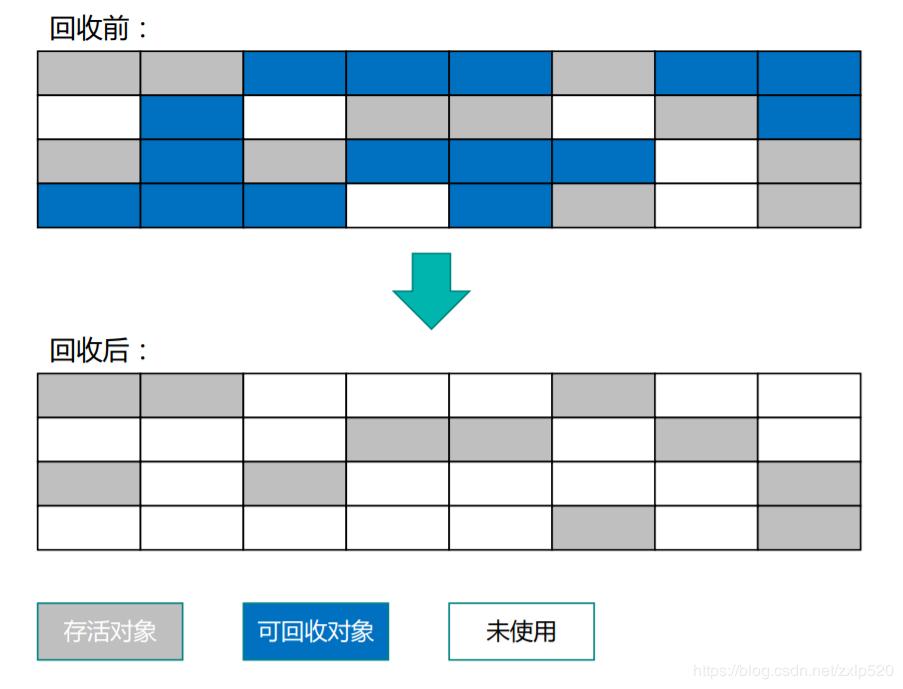
標記-清除演算法
從演算法的名稱上可以看出,這個演算法分為兩部分,標記和清除。首先標記出所有需要被回收的對象,然後在標記完成後統一回收掉所有被標記的對象。
這個演算法簡單,但是有兩個缺點:
- 一是標記和清除的效率不是很高;
- 二是標記和清除後會產生很多的記憶體碎片,導致可用的記憶體空間不連續,當分配大對象的時候,沒有足夠的空間時不得不提前觸發一次垃圾回收。
執行過程如下圖
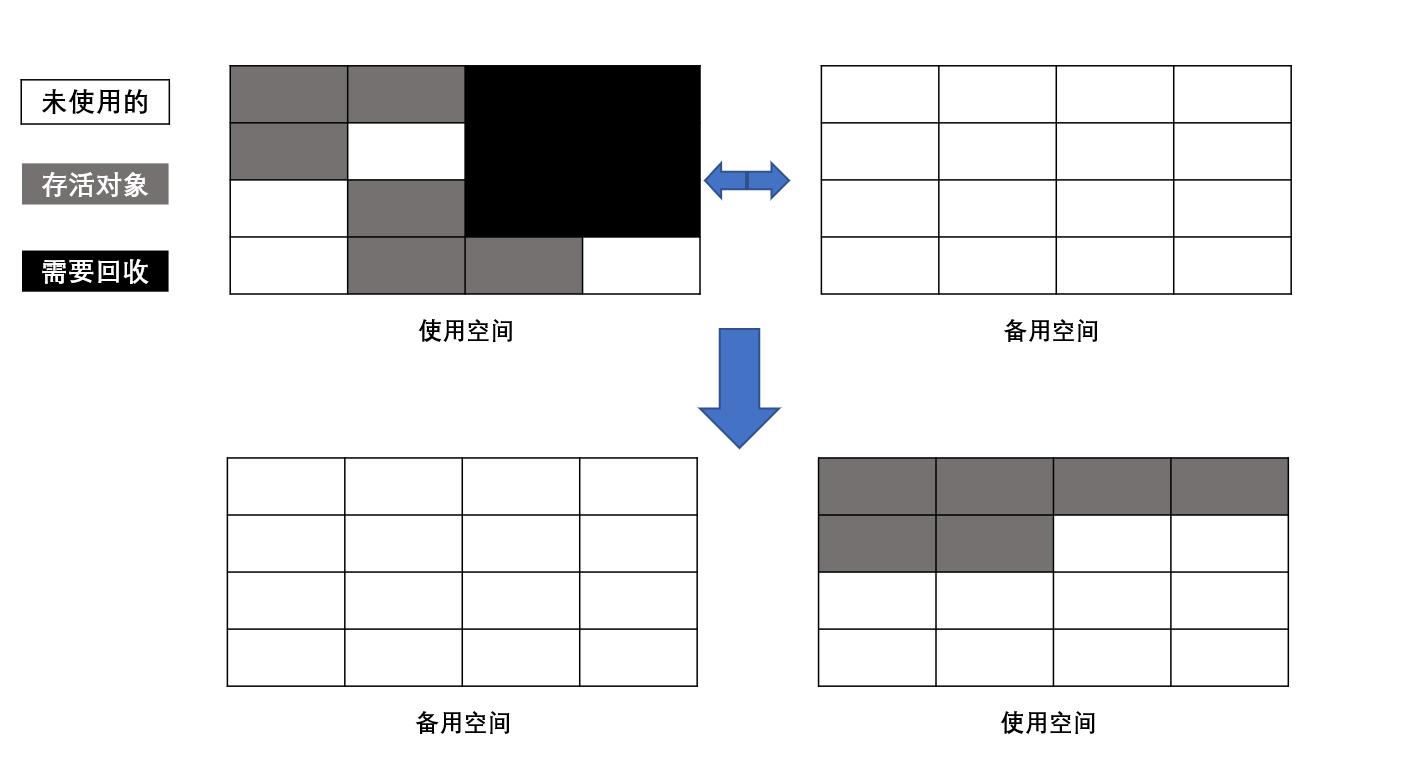
複製演算法
為瞭解決效率問題,一種稱為“複製”(Copying)的收集演算法出現了,他將可用記憶體按容量劃分為大小相等的兩塊,每次只使用其中的一塊。當這塊的記憶體用完了,就將還存活這的對象複製到另外一塊上面,然後再把已使用過的記憶體空間一次清理掉。這樣使得每次都是對整個半區進行記憶體回收,記憶體分配時也就不用考慮記憶體碎片等複雜情況,只要移動堆頂指針,按順序分配記憶體即可,實現簡單,運行高效。只是這種演算法的代價是將記憶體縮小為了原來的一半,未免太高了一點。
優缺點
- 優點:簡單高效
- 缺點:代價是將記憶體縮小為原來的一半,代價高
執行過程如下圖
標記-整理演算法
複製收集演算法在對象存活率較高時就要進行較多的複製操作,效率將會變低。更關鍵的是如果不想浪費50%的空間就要使用額外的空間進行分配擔保(Handle Promotion當空間不夠時,需要依賴其他記憶體),以應對被使用的記憶體中所有對象都100%存活的極端情況
對於“標記-整理”演算法,標記過程仍與“標記-清除”演算法一樣,但是後續步驟不是直接對可回收對象進行清理,而是讓所有的存活對象都向一端移動,然後直接清理掉端邊界以外的記憶體,”標記-整理“演算法示意圖如下:
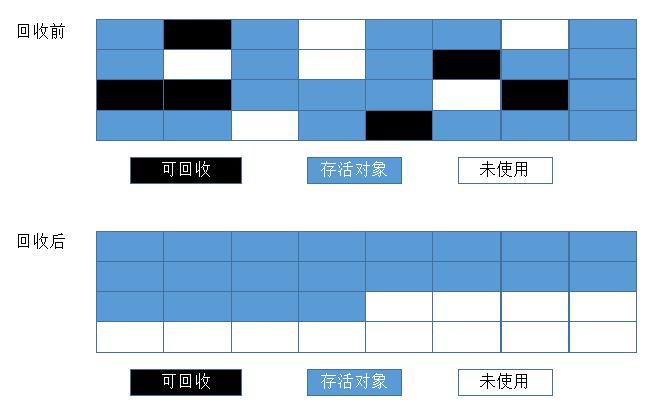
標記-整理演算法解決了複製演算法多複製效率低、空間利用率低的問題,同時也解決了記憶體碎片的問題。
分代收集演算法
根據對象生存周期的不同將記憶體空間劃分為不同的塊,然後對不同的塊使用不同的回收演算法。一般把Java堆分為新生代和老年代,新生代中對象的存活周期短,只有少量存活的對象,所以可以使用複製演算法,而老年代中對象存活時間長,而且對象比較多,所以可以採用標記-清除和標記-整理演算法。
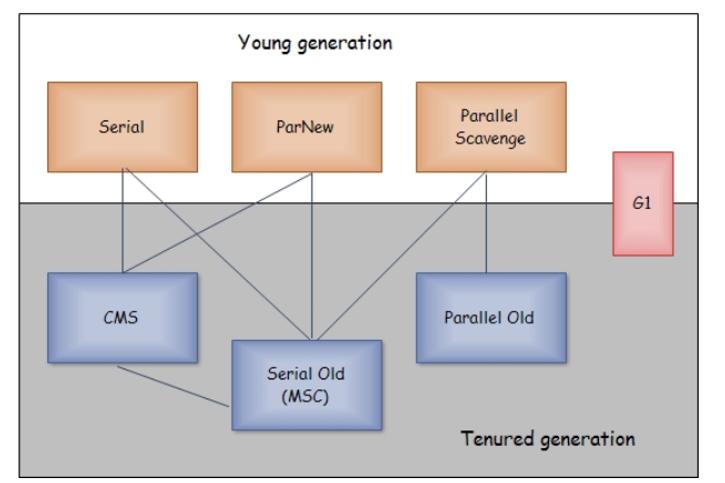
判斷對象是否有效
引用計數演算法
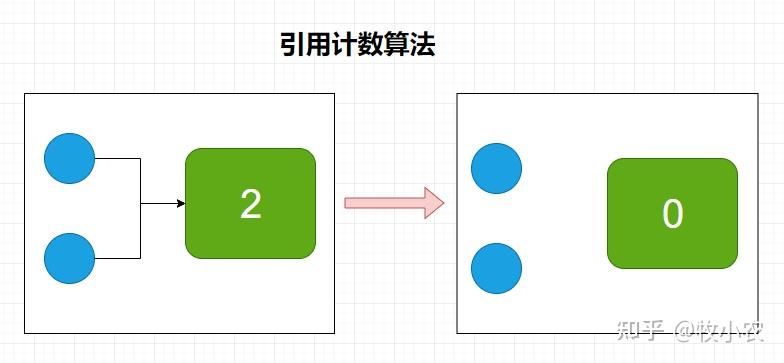
給對象添加一個引用計數器,每當一個地方引用它時,數據器加1;當引用失效時,計數器減1;計數器為0的即可被回收。
- 優點:實現簡單,判斷效率高
- 缺點:很難解決對象之間的相互迴圈引用(objA.instance = objB; objB.instance = objA)的問題,所以java語言並沒有選用引用計數法管理記憶體
根搜索演算法
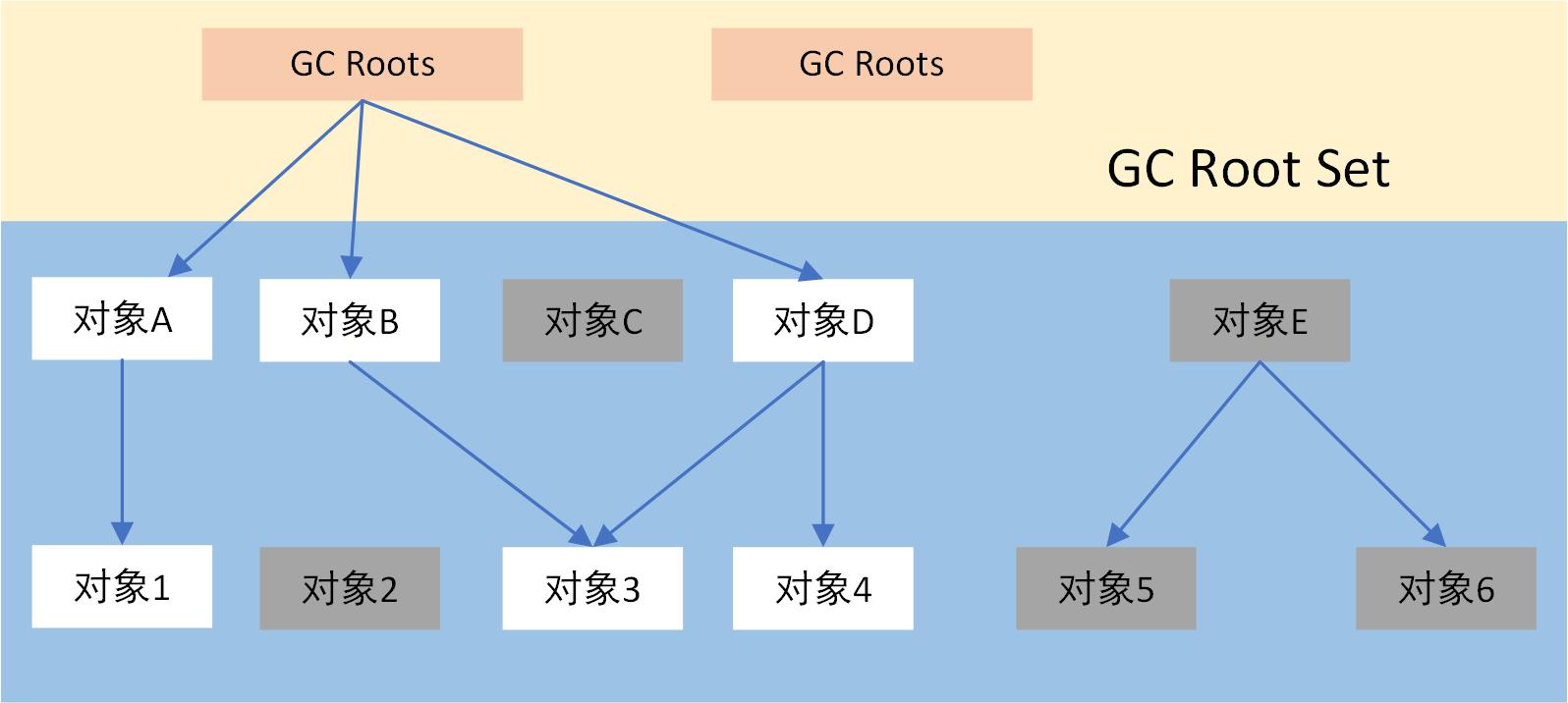
Java和C#都是使用根搜索演算法來判斷對象是否存活。通過一系列的名為“GC Root”的對象作為起始點,從這些節點開始向下搜索,搜索所有走過的路徑稱為引用鏈(Reference Chain),當一個對象到GC Root沒有任何引用鏈相連時(用圖論來說就是GC Root到這個對象不可達時),證明該對象是可以被回收的。
在Java中這些對象可以成為GC Root:
- 虛擬機棧(棧幀中的本地變數表)中的引用對象
- 方法區中的類靜態屬性引用的對象
- 方法區中的常量引用對象
- 本地方法棧中JNI(即Native方法)的引用對象
本文由
傳智教育博學谷狂野架構師教研團隊發佈。如果本文對您有幫助,歡迎
關註和點贊;如果您有任何建議也可留言評論或私信,您的支持是我堅持創作的動力。轉載請註明出處!

