
最近在寫一本Xilinx的FPGA方面的書,現將HLS部分內容在這裡分享給大家,希望大家喜歡,也歡迎批評指正。[原創www.cnblogs.com/helesheng] 在可編程邏輯器件被用於電子系統設計的前期,由於所含的邏輯資源較少,絕大部分情況下,它們被用於實現數據的傳輸和介面電路。工程師們習慣 ...
最近在寫一本Xilinx的FPGA方面的書,現將HLS部分內容在這裡分享給大家,希望大家喜歡,也歡迎批評指正。[原創www.cnblogs.com/helesheng]
在可編程邏輯器件被用於電子系統設計的前期,由於所含的邏輯資源較少,絕大部分情況下,它們被用於實現數據的傳輸和介面電路。工程師們習慣於使用寄存器傳輸級(RTL)的描述方式來開發可編程邏輯器件,以提高對邏輯資源的利用率。但正如我們在前面的章節中看到的,使用Verilog HDL這樣的硬體描述語言進行RTL級的開發是一件非常費時、費力的事。
另一方面,隨著摩爾定理的不斷發展,集成在可編程邏輯器件中的邏輯資源呈指數級的快速增長,對於開發者而言節約器件中的邏輯資源的重要性不斷降低。與此同時,隨著深度學習演算法和軟體無線電(SDR)技術的成熟,可編程器件中需要由硬體實現的演算法越來越複雜。再使用硬體描述語言低效率的實現這些複雜的演算法,越來越無法滿足時長對產品上市的時間要求。
提升可編程邏輯器件開發速度的方法無非有二:1、使開發工具能夠自動處理儘可能多的細節,降低項目開發時間(提升抽象的層級)。2、同一段代碼經過簡單地修改就能夠適用不同器件和優化要求,從而被儘可能多的項目使用(設計的重用)。而Vivado High Level Synthesis(高層次綜合器,簡稱HLS)正式Xilinx在上述思路指導下設計的一種開發工具,它通過直接使用C、C++或System C等高級語言進行硬體開發,能夠大幅度提升演算法開發的抽象層次和設計重用率的高效開發工具。
8.1 高層次綜合器(HLS)的概念與特點
1. 為什麼需要高層次綜合器
FPGA開發工具發展的一個總趨勢是提高描述數字系統的抽象層級,從而隱藏更多的底層技術細節,以達到提高複雜演算法開發的效率和不同器件之間設計重用的目的。在本書前述的硬體描述語言Verilog HDL能夠實現的抽象,由低到高包括:結構級的抽象、寄存器傳輸級抽象和行為級的抽象。其中結構級的抽象直接描述查找表和寄存器的連接和配置;寄存器傳輸級的抽象只描述寄存器與寄存器之間的可以被解釋和執行的操作,隱藏了具體的連接和配置方法,而將這部分細節留給硬體描述語言自動補齊;Verilog HDL能夠實現的最高級別的抽象稱為“行為級”,在這個級別上,硬體描述語言的綜合器可以直接針對設計者所需要的電路行為和演算法產生所需的電路,從而隱藏了大部分的電路細節。
而所謂“高層次綜合器”完全擺脫了電路水平的硬體描述,開發者只需要通過C、C++和System C等傳統意義上的電腦高級語言來描述演算法本身,而不必過分關註硬體電路及其在FPGA內部的實現方式。從FPGA開發工具角度來理解,高層次綜合器非上平行於硬體描述語言(HDL)的上述抽象層級(結構級、寄存器傳輸級和行為級)的獨立描述層級。因為,高層次綜合器的作用是將高級語言描述的演算法和行為綜合成寄存器傳輸級描述的硬體描述語言,再由Vivado以調用IP的形式,調用這些寄存器傳輸級的硬體描述語言,並將其進一步綜合成FPGA可以直接使用的網路表。因此,高層次綜合器的“綜合”與硬體描述語言的“綜合”的內涵並不相同,高層次綜合器(HLS)也不能獨立於Vivado單獨使用。下圖所示的是高層次綜合器(HLS)的綜合和硬體描述語言(HDL)的綜合之間的關係,理解這幅圖,有利於讀者理解高層次綜合器開發和優化流程。
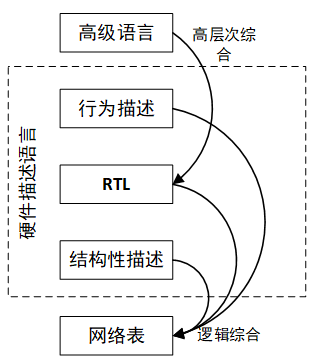
圖8.1 .1 高層次綜合器(HLS)的綜合和硬體描述語言(HDL)的綜合之間的關係
總體而言,高層次綜合器由於使用了更高層級的描述抽象,將更多的電路查找表和寄存器的連接、配置,以及信號傳輸的細節甩給了開發工具來自動完成,符合FPGA開發工具發展的趨勢。雖然在這個過程中可能由於開發工具無法深刻理解具體應用的需求,從而導致FPGA資源的部分浪費,但帶來的優勢也非常明顯:
其一,開發者無需關註細節的實現,導致開發效率成倍增加;開發者能夠將精力放在對系統而言更加重要的演算法開發上。
其二,用高級語言開發的演算法代碼,最大程度的做到了與具體器件“脫鉤”,是的同一段代碼經過簡單的移植後就能夠適用於使用不同器件的工程,提升了代碼的重用率。
其三,在不同的項目中使用同一種演算法時,可能會由於不同項目對演算法執行時間和邏輯資源的要求不同,造成代碼重覆開發的問題。而高層次綜合器HLS能夠通過簡單的配置,實現對同一段代碼優化策略的重配置,進一步提升了代碼的重用率。
2. 高層次綜合器產生的電路模塊
如圖8.1.1所示,高層次綜合器是一種能夠將傳統的高級語言描述的演算法,轉換為在可編程邏輯器件上實現的硬體描述語言的高效率開發工具。但一旦仔細推敲,細心的讀者就會發現,傳統的C/C++這類高級語言是建立在執行程式的CPU“逐條”取指執行的圖靈機框架下的;而實現在可編程器件上的硬體電路卻是相對固定,且需要實實在在介面硬體來完成演算法數據的輸入和結果輸出的。因此高層次綜合器的功能必然包括產生以下兩部分電路:演算法功能性電路,以及介面(也稱為“頂層連接”)電路兩個部分。圖8.1.2所示的是一個典型的高層次綜合器完成的硬體設計,其中包含了演算法綜合(Algorithm Synthesis)產生的功能性電路,以及介面綜合(Interface Synthesis)產生的輸入輸出電路。而這兩部分也是設計者使用高層次綜合器開發時,需要根據要求著重設計和斟酌的。
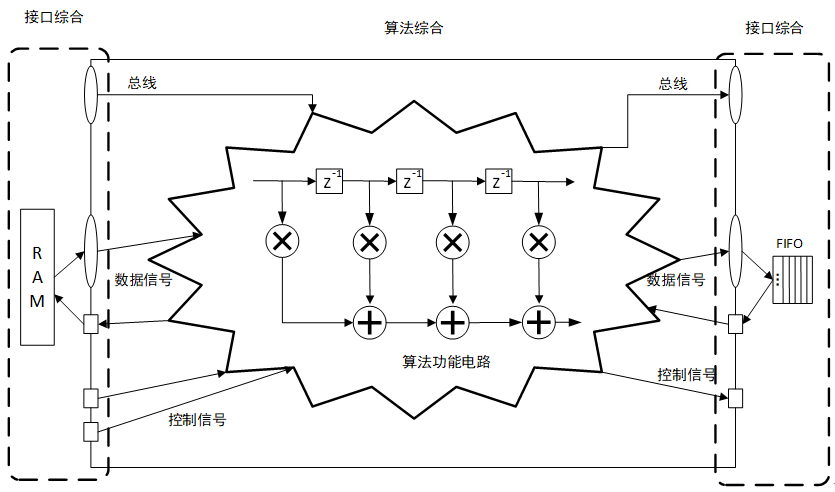
圖8.1.2 高層次綜合器產生的典型電路
3. 使用高層次綜合器的開發流程
使用高層次綜合器進行開發的流程模型如下圖所示。
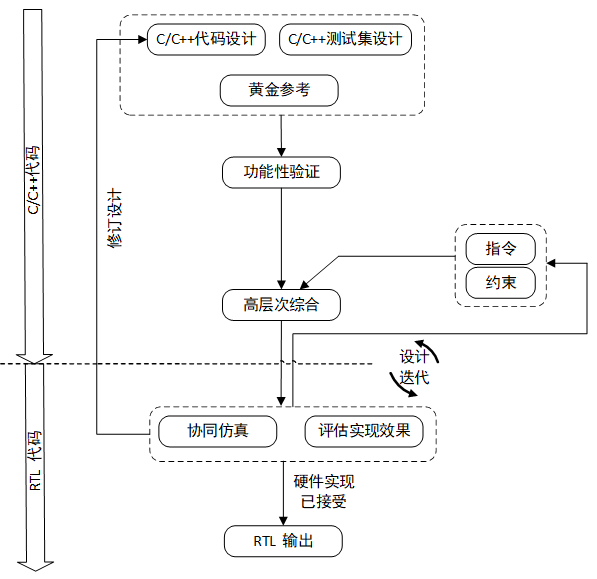
圖8.1.3 高層次綜合器開發流程示意圖
1)開發者需要給高層次綜合器的,首先是一個能夠實現所需演算法功能的C/C++函數;其次是一個用於測試和驗證該函數的標準輸入和輸出數據和調用該函數的代碼。也就是上圖中的“黃金參考”和“C測試集”(在很多設計中黃金參考被以數據的形式寫入到C測試集的C/C++代碼中)。
2)有了黃金測試和C測試集後,高層次綜合器就可以進行功能性驗證了。而通過功能性測試的演算法函數代碼就可以進入到高層次綜合器的“本質工作”高層次綜合階段了。此時開發者可以通過圖形化視窗或指令的方式配置圖8.1.3所示的“演算法綜合”和“介面綜合”的硬體細節。高層次綜合完成後,將產生以硬體描述語言的RTL模型,包括HDL文件和所需的各種日誌、輸出文件,測試集、腳本等設計文件。
3)高層次綜合器產生的RTL模型不一定與演算法的預期設計完全相同,這就需要對RTL模型進行協同模擬。此時需要再次用C測試集,對RTL模型進行模擬,並比較模擬輸出和黃金參考的差異。另外,在上圖中的C/RTL協同模擬的同時,還可以對硬體實現所需的資源的數量、執行的延遲、最高工作時鐘頻率等進行“實現的評估”。若實現無法達到設計要求,這可以通過約束和指令來優化RTL模型。而這個優化過程,必然是一個設計反覆迭代的過程。
4)高層次綜合器最終產生的RTL輸出可以是RTL文件(VHDL 或 Verilog 代碼),也可以是打包好的IP包,以便被其他設計工具方便的調用。
4. 高層次綜合器的核心工作
在上述過程中,高層次綜合器完成的最重要,也是最複雜的是第2)步——由高級語言綜合產生RTL描述模型的部分。這個步驟又可以細分為:提取數據通路和控制通路、調度和綁定、優化三個階段。其中,“提取數據通路和控制通路”是指分析高級語言代碼,解釋所需的功能。將其分解為“數據通路”部分電路和“控制”部分電路,用以對數據流進行處理、運算,以及控制、協調數據流的計算過程。“調度和綁定”則將電路要完成的運算和控制工作分配到不同的時鐘節拍和邏輯資源來完成。“優化”則是指通過圖8.1.3中的約束和指令來限制高層次綜合器的調度和綁定,從而實現反覆迭代、改進綜合結果的過程。
1)設計延遲和設計吞吐量
設計延遲和吞吐量是衡量高層次綜合器產生RTL模型最重要的兩個指標參數,在介紹高層次綜合器的工作之前先將要介紹這兩個概念。
設計延遲(Latency)是指不考慮器件資源性能限制條件下,實現演算法所需要的時鐘節拍數。


1 void foo(a,b,c,d,*x,*y){ 2 …… 3 func_A(a, b, t1); 4 func_B(a, b, t2); 5 func_C(c, t1, &x); 6 func_D(d, t2, &y); 7 }代碼8.1
使用高層次綜合器實現代碼8.1所示的演算法,如不進行任何優化,將得到如圖8.1.4所示的電路工作時序圖,其設計延遲就是10個時鐘周期。
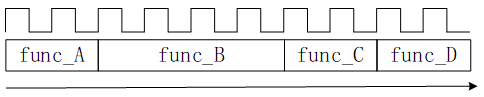
圖8.1.4 設計延遲舉例
設計吞吐量(Throughput)是指不考慮器件資源性能限制條件下,兩筆新輸入(或輸出)之間的周期數,圖8.1.4中吞吐量也可能是10個時鐘周期。
閱讀至此讀者一定充滿了疑惑,既然設計延遲和設計吞吐量含義相同,為什麼要用兩個不同名字?其實我們圖8.1.4中在討論“吞吐量”的含義時,並未考慮電路“併發”的情況——硬體電路和高級語言實現演算法不一樣,可編程器件上不同部分的硬體電路可以同時執行多步運算,不像CPU執行高級語言語句只能一次逐條執行。這樣當可編程器件中的一部分電路執行圖8.1.4的func_B時,原來執行func_A的電路就可以再次取一筆新的數據執行,從而提高整個電路的吞吐量。如圖8.1.5所示,電路的吞吐量就提高為4個周期。
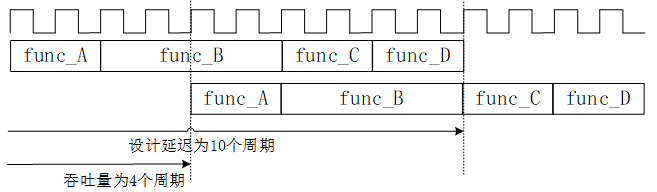
圖8.1.5 設計吞吐量舉例
2)調度和綁定
下麵以一段具體的C語言代碼來說明高層次綜合器可以如何通過“調度”將不同的數據操作映射到不同的時鐘節拍中的。代碼如下所示,其中變數t1、t2、t3和out之間存在依賴關係,只有依次計算得到上一個變數的值,才能得到下一個變數的值。
void foo{ …… t1 = a * b; t2 = c + t1; t3 = d * t2; out = t3 – e; }代碼8.2
如果設計要求不太關心上述演算法所耗費的時間(設計延遲),則可以採用如圖8.1.6所示的調度策略。即第一個時鐘節拍實現a×b,第二個時鐘節拍實現實現c+t1,第三個時鐘節拍實現實現d×t2,第四個時鐘節拍實現實現t3–e。總共花費4個時鐘的時間,每個節拍對應的計算結果都採用觸發器鎖存輸出,該調度方法對於所使用器件邏輯資源延遲的要求也最低。
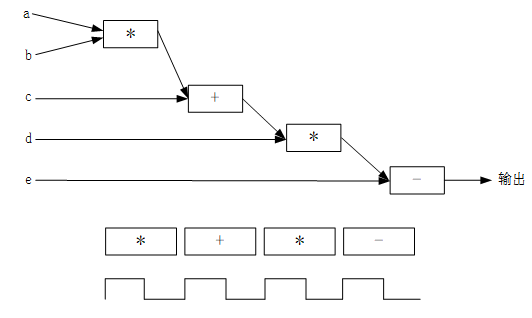
圖8.1.6 調度策略一示意圖
若設計需要演算法消耗較少的時間以實現更高的吞吐量,則可以通過去掉某些鎖存觸發器的方法,將更多的運算合併到單個時鐘節拍中來完成。當然,這樣做的代價是所消耗的器件資源能夠在更短的時間內完成更多的組合邏輯運算。圖8.1.7所示的是將a×b、c+t1、d×t2運算合併到一個時鐘節拍中完成,從而將總耗時降低到2個時鐘節拍的調度策略。

圖8.1.7 調度策略二示意圖
“綁定”是指把調度中涉及的運算“指派”給具體的邏輯資源來實現,即實現資源的映射,綁定策略可以大致分為共用和非共用兩種。顧名思義,共用策略指多個運算共用同一個可編程硬體資源。當然共用的前提是不同運算不能再同一個時鐘節拍中使用該資源。如圖8.1.7所示的調度策略中,兩個乘法運算都被分配到第一個時鐘節拍中完成,這兩個時鐘節拍所使用的乘法器資源就是不可以共用的。
調度和綁定是一個相互關聯的過程,它們共同建立在技術庫的基礎上,又受到用戶指令的限制,實現合理的調度和綁定註定是一個反覆試錯和優化的過程。
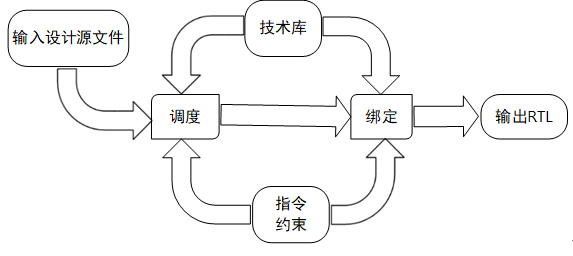
圖8.1.8 調度和綁定過程示意圖
3)改善設計延遲和吞吐量
高層次綜合器的核心工作,無非就是通過調度和綁定在滿足設計占用資源/面積、時鐘頻率和功耗總體要求的前提下,獲得最佳的延遲和吞吐量。而改善設計延遲和吞吐量的思路無非如下。
其一,利用數據之間的關聯性,改善設計延遲。
再考慮代碼8.1所示的演算法,如果是在傳統的CPU上執行這些代碼,則只能如圖8.1.4所示的時序依次執行func_A、func_B、func_C、func_D,設計延遲為10個時鐘周期。但考慮各個函數模塊之間的依賴關係是:只有完成func_A才能得到t1,才能執行func_C;只有完成func_B才能得到t2,以執行func_D。而func_A/func_C與func_B/func_D之間並沒有制約關係,如圖8.1.9所示。
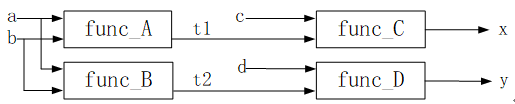
圖8.1.9 數據依賴關係的調整
則開發者可以通過相關約束和命令優化調度和綁定方式,將設計的數據通路調整為圖8.1.10所示的兩條,整體設計延遲降低為6個。
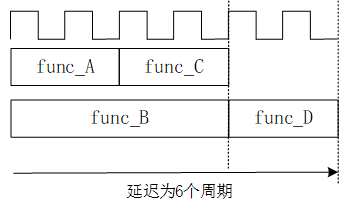
圖8.1.10 設計延遲優化示意圖
其二,在數據依賴關係允許的條件下,調整被綁定硬體資源的工作時序,最大程度的提高各個模塊的並行度。使完成不同功能的硬體資源像“流水線”上的工人一樣有序的持續工作,輪流對被處理的數據流中的具體數據分別進行“加工處理”,從而改善數據吞吐量。同樣以上面的C語言偽代碼為例,不考慮圖8.1.10所示的延遲優化(四個函數順序執行)。其中func_A、func_B、func_C和func_D相當於流水線中完成特定功能的“工人”,而不斷進入的數據則相當於需要加工的“工件”。假設func_A、func_B、func_C和func_D所需的延遲分別為2、4、2、2個時鐘周期,則可通過調度將重覆執行的數據通路並行化,如圖8.1.11所示。每個數據通路並行化後的延遲,為四個函數中執行時間最長的4個時鐘周期。這樣當大量數據依次通過數據通路後,電路的整體延遲雖然仍為10個時鐘周期,但吞吐量縮減為3個時鐘周期。

圖8.1.11 設計吞吐量優化示意圖


