
本文主要介紹在Node.js應用中, 如何用全鏈路信息存儲技術把全鏈路追蹤數據存儲起來,併進行相應的展示,最終實現基於業界通用 OpenTracing 標準的 Zipkin 的 Node.js 方案。 ...
作者:vivo 互聯網前端團隊- Yang Kun
本文是上篇文章《Node.js 應用全鏈路追蹤技術——全鏈路信息獲取》的後續。閱讀完,再來看本文,效果會更佳哦。
本文主要介紹在Node.js應用中, 如何用全鏈路信息存儲技術把全鏈路追蹤數據存儲起來,併進行相應的展示,最終實現基於業界通用 OpenTracing 標準的 Zipkin 的 Node.js 方案。
一、背景
目前業界主流的做法是使用分散式鏈路跟蹤系統,其理論基礎是來自 Google 的一篇論文 《大規模分散式系統的跟蹤系統》。
論文如下圖所示:
(圖片來源:網路)
在此理論基礎上,誕生了很多優秀的實現,如 zipkin、jaeger 。同時為了保證 API 相容,他們都遵循 OpenTracing 標準。那 OpenTracing 標準是什麼呢?
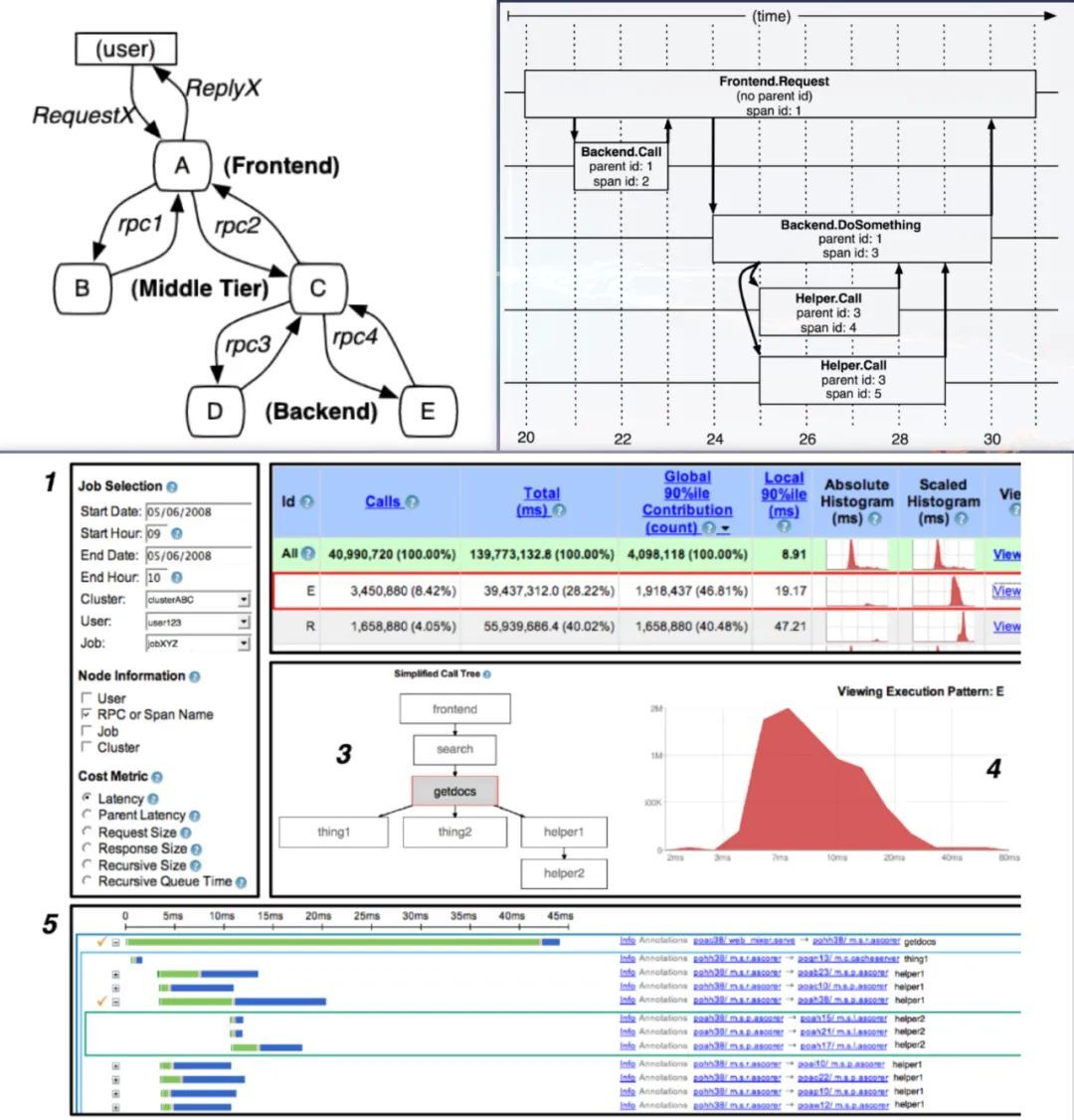
OpenTracing 翻譯為開發分散式追蹤,是一個輕量級的標準化層,它位於應用程式/類庫和鏈路跟蹤系統之間的一層。 這一層可以用下圖表示:
從上圖可以知道, OpenTracing 具有以下優勢:
-
統一了 API ,使開發人員能夠方便的添加追蹤系統的實現。
-
OpenTracing 已進入 CNCF ,正在為全球的分散式鏈路跟蹤系統,提供統一的模型和數據標準。
大白話解釋下:它就像手機的介面標準,當今手機基本都是 typeC 介面,這樣方便各種手機能力的共用。因此,做全鏈路信息存儲,需要按照業界公認的 OpenTracing 標準去實現。
本篇文章將通過已有的優秀實現 —— zipkin ,來給大家闡述 Node.js 應用如何對接分散式鏈路跟蹤系統。
二、zipkin
2.1 zipkin 是什麼?
zipkin 是 Twitter 基於 Google 的分散式追蹤系統論文的開發實現,其遵循 OpenTracing 標準。
zipkin 用於跟蹤分散式服務之間的應用數據鏈路。
2.2 zipkin 架構
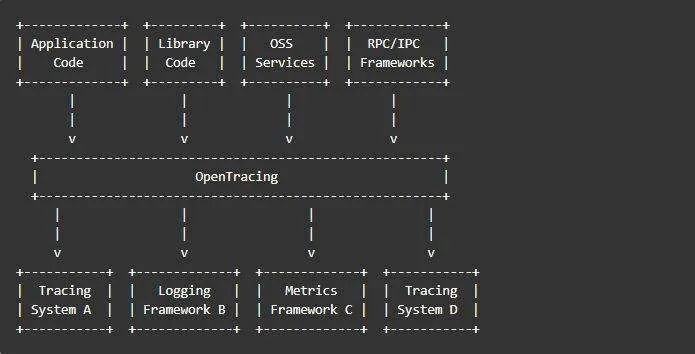
官方文檔上的架構如下圖所示:
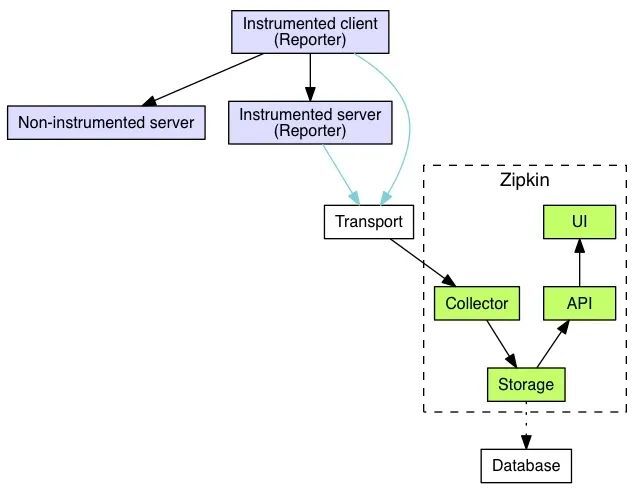
為了更好的理解,我這邊對架構圖進行了簡化,簡化架構圖如下所示:
從上圖可以看到,分為三個部分:
第一部分:全鏈路信息獲取,我們不使用 zipkin 自帶的全鏈路信息獲取,我們使用 zone-context 去獲取全鏈路信息
第二部分:傳輸層, 使用 zipkin 提供的傳輸 api ,將全鏈路信息傳遞給 zipkin
第三部分: zipkin 核心功能,各個模塊介紹如下:
-
collector 就是信息收集器,作為一個守護進程,它會時刻等待客戶端傳遞過來的追蹤數據,對這些數據進行驗證、存儲以及創建查詢需要的索引。
-
storage 是存儲組件。zipkin 預設直接將數據存在記憶體中,此外支持使用 ElasticSearch 和 MySQL 。
-
search 是一個查詢進程,它提供了簡單的 JSON API 來供外部調用查詢。
-
web UI 是 zipkin 的服務端展示平臺,主要調用 search 提供的介面,用圖表將鏈路信息清晰地展示給開發人員。
至此, zipkin 的整體架構就介紹完了,下麵我們來進行 zipkin 的環境搭建。
2.3 zipkin 環境搭建
採用 docker 搭建, 這裡我們使用 docker 中的 docker-compose 來快速搭建 zipkin 環境。
docker-compose.yml 文件內容如下:
version: '3.8'
services:
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:7.5.0
container_name: elasticsearch
restart: always
ports:
- 9200:9200
healthcheck:
test: ["CMD-SHELL", "curl --silent --fail localhost:9200/_cluster/health || exit 1"]
interval: 30s
timeout: 10s
retries: 3
start_period: 40s
environment:
- discovery.type=single-node
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
- TZ=Asia/Shanghai
ulimits:
memlock:
soft: -1
hard: -1
zipkin:
image: openzipkin/zipkin:2.21
container_name: zipkin
depends_on:
- elasticsearch
links:
- elasticsearch
restart: always
ports:
- 9411:9411
environment:
- TZ=Asia/Shanghai
- STORAGE_TYPE=elasticsearch
- ES_HOSTS=elasticsearch:9200
在上面文件所在的目錄下執行 docker-compose up -d 即可完成本地搭建。
搭建完成後,在瀏覽器中打開地址 http://localhost:9411 ,會看到如下圖所示頁面:
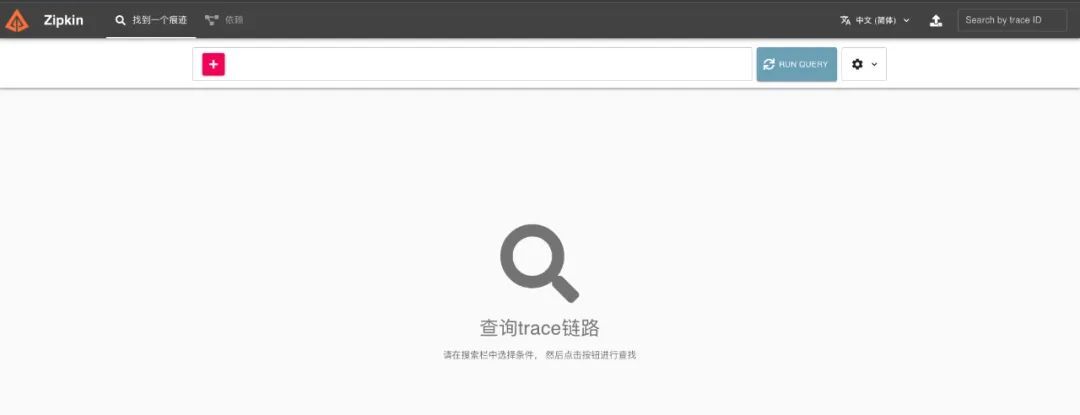
接著打開地址 http://localhost:9200 ,會看到如下圖所示頁面:
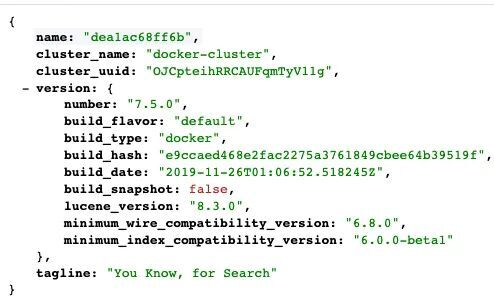
至此, zipkin 的本地環境就搭建好啦。 下麵我就將介紹 Node.js 應用如何對接 zipkin。
三、Node.js 接入 zipkin
3.1 搞定全鏈路信息獲取
這個我在 《Node.js 應用全鏈路追蹤技術——全鏈路信息獲取》 文章中,已經詳細闡述了,如何去獲取全鏈路信息。
3.2 搞定傳輸層
因為 zipkin 是基於 OpenTracing 標準實現的。因此我們只要搞定了 zipkin 的傳輸層,也就搞定了其他主流分散式追蹤系統。
這裡我們用到了 zipkin 官方提供的兩個 npm 包,分別是:
-
zipkin
-
zipkin-transport-http
zipkin 包是官方對支持 Node.js 的核心包。 zipkin-transport-http 包的作用是將數據通過 HTTP 非同步發送到 zipkin 。
下麵我們將詳細介紹在傳輸層,如何將將數據發送到 zipkin 。
3.3 傳輸層基礎封裝
核心代碼實現和相關註釋如下:
const {
BatchRecorder,
Tracer,
// ExplicitContext,
jsonEncoder: { JSON_V1, JSON_V2 },
} = require('zipkin')
const { HttpLogger } = require('zipkin-transport-http')
// const ctxImpl = new ExplicitContext();
// 配置對象
const options = {
serviceName: 'zipkin-node-service',
targetServer: '127.0.0.1:9411',
targetApi: '/api/v2/spans',
jsonEncoder: 'v2'
}
// http 方式傳輸
async function recorder ({ targetServer, targetApi, jsonEncoder }) => new BatchRecorder({
logger: new HttpLogger({
endpoint: `${targetServer}${targetApi}`,
jsonEncoder: (jsonEncoder === 'v2' || jsonEncoder === 'V2') ? JSON_V2 : JSON_V1,
})
})
// 基礎記錄
const baseRecorder = await recorder({
targetServer: options.targetServer
targetApi: options.targetApi
jsonEncoder: options.jsonEncoder
})
至此,傳輸層的基礎封裝就完成了,我們抽離了 baseRecorder 出來,下麵將會把全鏈路信息接入到傳輸層中。
3.4 接入全鏈路信息
這裡說下官方提供的接入 SDK ,代碼如下:
const { Tracer } = require('zipkin')
const ctxImpl = new ExplicitContext()
const tracer = new Tracer({ ctxImpl, recorder: baseRecorder })
// 還要處理請求頭、手動層層傳遞等事情
上面的方式缺點比較明顯,需要額外去傳遞一些東西,這裡我們使用上篇文章提到的 Zone-Context , 代碼如下:
const zoneContextImpl = new ZoneContext()
const tracer = new Tracer({ zoneContextImpl, recorder: baseRecorder })
// 僅此而已,不再做額外處理
對比兩者,明顯發現, Zone-Context 的實現方式更加的隱式,對代碼入侵更小。這也是單獨花一篇文章介紹 Zone-Context 技術原理的價值體現。
自此,我們完成了傳輸層的適配, Node.js 應用接入 zipkin 的核心步驟基本完成。
3.5 搞定 zipkin 收集、存儲、展示
這部分中的收集、展示功能, zipkin 官方自帶完整實現,無需進行二次開發。存儲這塊,提供了 MySQL 、 Elasticsearch 等接入方式。可以根據實際情況去做相應的接入。本文采用 docker-compose 集成了 ElasticSearch 。
四、總結
自此,我們已經完成基於業界通用 OpenTracing 標準實現的 zipkin 的 Node.js 方案。希望大家看完這兩篇文章,對 Node.js 全鏈路追蹤,有一個整體而清晰的認識。
參考資料:
分享 vivo 互聯網技術乾貨與沙龍活動,推薦最新行業動態與熱門會議。
