本篇主要介紹Java NIO的基本原理和主要組件 Netty是由JBOSS提供的Java開源網路應用程式框架,其底層是基於Java提供的NIO能力實現的。因此為了掌握Netty的底層原理,需要首先瞭解Java NIO的原理。 NIO簡介 電腦主要由CPU、記憶體、外存、IO設備等硬體組成,電腦執行 ...
本篇主要介紹Java NIO的基本原理和主要組件
Netty是由JBOSS提供的Java開源網路應用程式框架,其底層是基於Java提供的NIO能力實現的。因此為了掌握Netty的底層原理,需要首先瞭解Java NIO的原理。
NIO簡介
電腦主要由CPU、記憶體、外存、IO設備等硬體組成,電腦執行計算的過程就是CPU從記憶體中獲取數據,進行計算,然後再將計算結果寫入記憶體中。但由於記憶體非常昂貴且下電後數據會丟失,電腦需要使用外存來持久化存儲大規模的數據,外存提供了大量的存儲空間,代價是其存取速度遠小於記憶體。除了讀取外存數據,電腦還可以從網路設備獲取網路中的數據,受網路傳輸速度的限制,電腦獲取網路數據的速度也遠小於其讀取記憶體的速度。
對於存取這些低速IO設備,操作系統(如Linux)提供了5種不同的IO模型。對於Java來說,其最先提供的就是基於最簡單的阻塞式IO模型實現的BIO(Blocking IO)庫。當調用BIO庫讀取硬碟中的數據時,用戶進程會一直被阻塞在讀數據的介面上,直到數據被操作系統從硬碟中獲取出來並返回給用戶,這時用戶進程才能繼續向下執行。由於讀取硬碟速度相比CPU計算速度慢很多,進程就會一直被卡在讀取數據這裡,用戶體驗就是進程沒有響應。即使CPU處於空閑狀態,也無法使用CPU進行其他工作。這就浪費了大量的資源,同時也給用戶造成了不好的體驗。
除了最傳統的阻塞式IO,操作系統還提供了其他幾種改進的IO模型,總體思想都是儘可能減少用戶進程阻塞在IO上的時間,在進行慢速設備IO時,進程無需等待,可以繼續處理其他指令,當數據獲取完成時操作系統再通知用戶進程可以進行後續的數據處理操作。因此Java在1.4版本後就推出了一套新的IO介面NIO(New IO),這套IO介面基於多路復用IO模型,提供了非阻塞的IO能力,因此NIO中的N也可以理解為Non-blocking。這套NIO介面實現了只用一個線程來輪詢等待所有應用進程的IO就緒狀態,當某個應用進程的IO狀態就緒時,再通知對應進程進行數據讀寫的操作。這就避免了每個應用進程在IO時被阻塞,為開發高性能和高併發的應用提供了關鍵能力。
NIO的3個核心組件
- Channel
- Buffer
- Selector
Channel(通道)
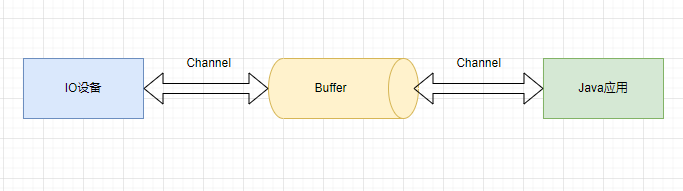
Channel 是 NIO 的核心概念,它表示一個打開的連接,是數據讀寫的雙向通道,這個連接可以連接到 I/O 設備(例如:磁碟文件,Socket)或者一個支持 I/O 訪問的應用程式,Java NIO 使用緩衝區和通道來進行數據傳輸。
Channel的主要實現類有:
- FileChannel(讀寫文件)
- DatagramChannel(UDP編程)
- SocketChannel(TCP編程)
- ServerSocketChannel(TCP編程)
FileChannel
FileChannel只能工作在阻塞模式下,不能配合Selector
FileChannel不能直接打開,必須通過FileInputStream,FileOutputStream或RandomAccessFile來獲取,它們都有getChannel()方法
- 通過
FileInputStream獲取的channel只能讀 - 通過
FileOutputStream獲取的channel只能寫 - 通過
RandomAccessFile是否能讀寫根據構造時的讀寫模式決定
transferTo方法
效率相比使用流式方式拷貝數據高很多,底層使用了操作系統提供的零拷貝特性。
一次最多傳輸2g的數據
Buffer(緩衝區)
Buffer是NIO的另一個核心概念,NIO庫操作數據都是通過緩衝區處理的,在數據讀寫的過程都要先經過緩衝區,然後再從緩衝區中按照塊來處理數據。
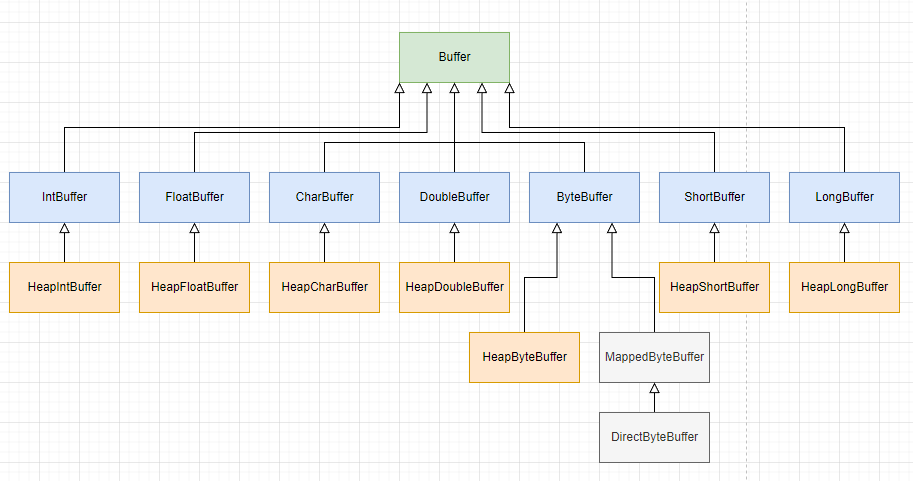
從類圖中可以看到,7 種數據類型對應著 7 種子類,這些名字是 Heap 開頭子類,數據是存放在 JVM 堆中的。
MappedByteBuffer
MappedByteBuffer存放在堆外直接記憶體中,可以與文件進行映射。
通過java.nio包和MappedByteBuffer允許Java程式直接從記憶體中讀取文件內容,通過將整個或部分文件映射到記憶體,由操作系統來處理載入請求和寫入文件,應用只需要和記憶體打交道,這使得IO操作非常快。
Mmap記憶體映射和普通標準IO操作的本質區別在於它並不需要將文件中的數據先拷貝至OS的內核IO緩衝區,而是可以直接將用戶進程私有地址空間中的一塊區域與文件對象建立映射關係,這樣程式就好像可以直接從記憶體中完成對文件讀/寫操作一樣。
ByteBuffer的正確使用方式
- 向buffer中寫入數據,例如
channel.read(buf) - 調用
flip()切換成讀模式 - 從buffer中讀取數據,例如
buffer.get() - 調用
clear()或compact()切換為寫模式 - 重覆1-4
點擊查看代碼
@Slf4j
public class TestByteBuffer {
public static void main(String[] args) {
try (FileInputStream fileInputStream = new FileInputStream("data.txt");
FileChannel channel = fileInputStream.getChannel()) {
ByteBuffer buffer = ByteBuffer.allocate(10);
while (true) {
int len = channel.read(buffer);
if (len < 0) {
break;
}
log.info("讀到的字元數:{}", len);
buffer.flip();
while (buffer.hasRemaining()) {
byte b = buffer.get();
log.info("讀到的字元:{}", (char) b);
}
buffer.clear();
}
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
Java規定內碼使用UTF-16編碼,一個字元占用2個位元組,也就是Java中的char類型在記憶體中是使用UTF-16的編碼形式存儲的。而我們代碼中讀取的文件data.txt使用的是UTF-8編碼格式,因此對於其中的英文字元和數字,一個字元只占用一個位元組。因此代碼中我們可以每次讀取一個位元組,然後再把它轉換成Java內部的char。
Buffer的結構
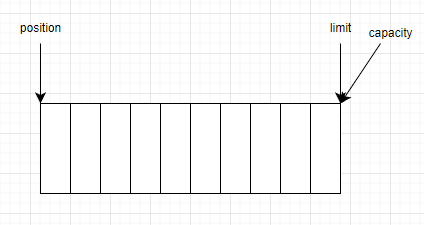
Buffer是由特定基本類型的元素組成的線性有限序列,除了Buffer裡面的內容,其最重要的屬性就是它的capacity,limit和position。
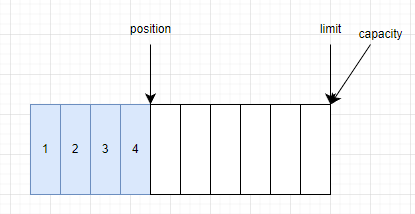
capacity:Buffer中可以儲存的元素數量,Buffer的capacity不能為負值也永遠不會改變。limit:Buffer中第一個不能被讀取或寫入的元素的位置,limit不能為負值也不能大於capacity。position:Buffer中下一個將要被讀取或寫入的元素的位置,position不能為負值也不能大於limit。
三個屬性是如何控制讀寫過程的
- 通過源碼可以看出,調用
ByteBuffer.allocate(10)的時候,我們初始化了一個HeapByteBuffer對象,並將其capacity和limit均設置為10,position被設置為0。
點擊查看代碼
// ByteBuffer.java
public static ByteBuffer allocate(int capacity) {
if (capacity < 0)
throw new IllegalArgumentException();
return new HeapByteBuffer(capacity, capacity);
}
// HeapByteBuffer.java,調用的HeapByteBuffer中的構造方法
HeapByteBuffer(int cap, int lim) { // package-private
super(-1, 0, lim, cap, new byte[cap], 0);
}
- 當調用
channel.read(buf)向Buffer中寫入數據時,根據源碼分析,其最終會調入ByteBuffer的put()方法中,HeapByteBuffer對其的實現如下,nextPutIndex()方法檢查當前position是否大於等於limit,如果小於limit,則將原position返回,並將原position加1。
點擊查看代碼
// HeapByteBuffer.java
public ByteBuffer put(byte x) {
hb[ix(nextPutIndex())] = x;
return this;
}
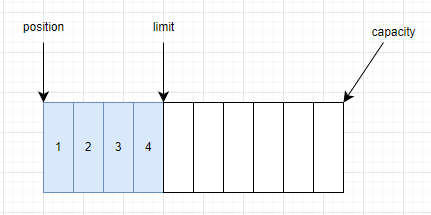
- 當寫入完成後,我們調用
flip()方法,所謂將Buffer切換為讀模式,其實源碼中就是將position和limit的位置重新賦值。如此操作後,position就是我們讀取數據的起點,limit就是我們讀取數據的終點。
點擊查看代碼
// Buffer.java
public final Buffer flip() {
limit = position;
position = 0;
mark = -1;
return this;
}
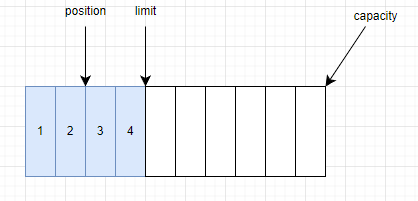
- 切換讀模式後,就可以調用
buffer.get()方法來獲取一個位元組,通過源碼可以看出,nextGetIndex()方法檢查當前position是否大於等於limit,如果小於limit,則將原位置返回,並將原位置加1。
點擊查看代碼
// HeapByteBuffer.java
public byte get() {
return hb[ix(nextGetIndex())];
}
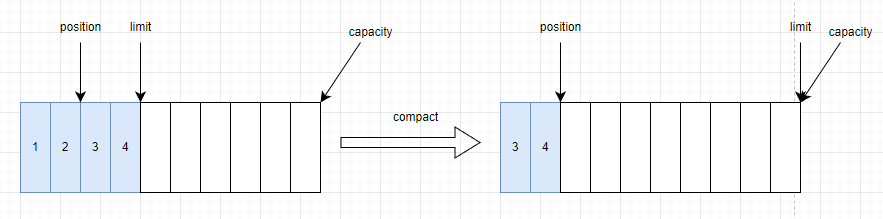
-
當讀取所有數據後,可以調用
buffer.clear()方法或buffer.compact()方法將Buffer切換為寫模式。clear(): 直接將Buffer重置為初始狀態,忽略還沒有讀完的數據。compact():將還沒讀完的數據複製到緩衝區頭部,然後從沒讀完的數據後可以開始寫入新的數據
點擊查看代碼
// Buffer.java
public final Buffer clear() {
position = 0;
limit = capacity;
mark = -1;
return this;
}
// HeapByteBuffer.java
public ByteBuffer compact() {
System.arraycopy(hb, ix(position()), hb, ix(0), remaining()); // 將還沒讀完的數據拷貝到數組頭部
position(remaining()); // 將position重置為剩餘待讀數據之後
limit(capacity()); // 將limit重置為capacity
discardMark();
return this;
}
mark和reset
mark是Buffer中的另一個屬性,它的主要用途是記錄一個position的位置,後續調用reset()方法後會將position重置到mark的位置。mark可以不被定義,但如果設置了mark的值,則它不能為負值且不能大於position的值。
粘包和半包
比如我們想要發送三行數據
Hello world.\n
It is my life.\n
I love you.\n
為了提高發送效率,通常我們會將這三行字元串合併到一個Buffer中進行發送。另一端在接收到消息時,由於協議並不理解消息的內容,因此用戶在讀取數據時,有可能讀取出來如下兩個包。
Hello world.\nIt is my life.\nI Lo
ve you.\n
這裡第一個包出現了原來的兩條數據在一個包中的情況,這就叫做粘包。第一行最後的數據將原來的一條數據截斷了,這就叫做半包。
我們可以通過如下方式處理粘包和半包的問題。
點擊查看代碼
public class TestStickyAndHalfPackage {
public static void main(String[] args) {
ByteBuffer p1 = ByteBuffer.allocate(64);
p1.put("Hello world.\nIt is my life.\nI lo".getBytes());
split(p1);
p1.put("ve you.\n".getBytes());
split(p1);
}
private static void split(ByteBuffer buffer) {
buffer.flip();
for (int i = 0; i < buffer.limit(); ++i) {
if (buffer.get(i) == '\n') {
int len = i + 1 - buffer.position();
ByteBuffer line = ByteBuffer.allocate(len);
for (int j = 0; j < len; ++j) {
line.put(buffer.get());
}
line.flip();
System.out.print(StandardCharsets.UTF_8.decode(line));
}
}
buffer.compact(); // 將沒有讀完的數據移動到buffer頭部,這裡是處理半包和粘包的關鍵
}
}
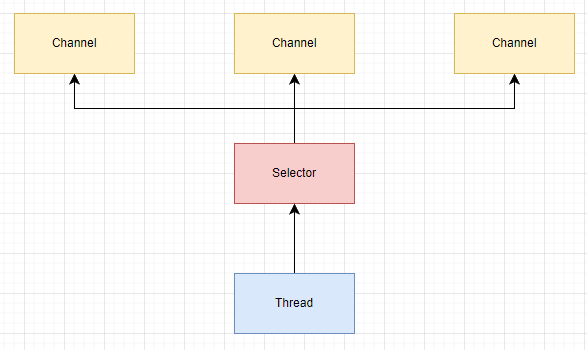
Selector(選擇器)
概念繼承於操作系統IO模型中多路復用IO模型中的selector,其主要作用是,用戶可以把所有讀寫Channel都註冊在某個Selector上,Selector會不斷的輪詢註冊在上面的所有channel,如果某個channel為讀寫等事件做好準備,那麼就處於就緒狀態,通過Selector可以不斷輪詢發現出就緒的channel,進行後續的IO操作。為何要做這種設計呢?
如果每一個Channel都需要一個線程來為其IO過程提供服務,則會占用大量的記憶體,CPU需要在很多線程間進行切換,有太多額外開銷,而且隨著連接數量增加,線程數量會達到上限,無法支持大連接數。
有一種解決方案是使用有固定線程數量的線程池來處理所有連接請求,但線程池中的線程一旦被占用,就要阻塞等待IO完成才能被其他連接使用,如果IO請求花費時間很長,那會導致後續的大量IO請求需要排隊等待。這種情況只適合處理短連接比較多的場景。
針對連接數量非常多,數據流量比較少的場景,多路復用的IO模型就比較適合。如下圖所示,每一個Channel可以把自己註冊到一個獨立運行的Selector線程中,這個Selector線程會輪詢所有Channel的讀寫狀態,當發現一個就緒的Channel時,就可以使用工作線程為這個Channel提供服務。這樣工作線程就不需要阻塞在某一個Channel上,只有真正要進行數據讀寫時才分配給某個Channel,極大提高了線程的利用率。