
第二章 線程管控 主要內容: 啟動線程,並通過幾種方式為新線程指定運行代碼 等待線程完成和分離線程並運行 唯一識別一個線程 2.1 線程的基本管控 main函數其本聲就是一個線程,在其中又可以啟動別的線程和設置其對應的函數入口。 2.1.1 發起線程 不管線程要執行的任務是複雜還是簡單,其最 ...
第二章 線程管控
主要內容:
- 啟動線程,並通過幾種方式為新線程指定運行代碼
- 等待線程完成和分離線程並運行
- 唯一識別一個線程
2.1 線程的基本管控
main函數其本聲就是一個線程,在其中又可以啟動別的線程和設置其對應的函數入口。
2.1.1 發起線程
不管線程要執行的任務是複雜還是簡單,其最終都要落實到標準庫
std::thread my_thread((background_task()));
下麵我寫了一個驗證程式來驗證作者所說的這一種情況:
class background_task
{
public:
//函數轉化操作符,將類轉為函數對象
void operator()() const
{
cout<<"background_task's function convert"<<endl;
}
};
void func_inside_mythread()
{
cout<<"func_inside_mythread"<<endl;
}
//一個返回background_task對象的函數
background_task do_something()
{
cout<<"do somthing inside background_task"<<endl;
return background_task();
}
//這裡便是引發編譯器歧義的申明,這裡既可以聲明為thread對象的創建也可以是一個參數為返回background_task函數指針的函數
thread my_thread(background_task(*p)());
//如下便是對於上面t1的函數定義
thread my_thread(background_task(*p)())
{
(*p)();
cout<<"I am a function which get function pointer background_task"<<endl;
return thread(func_inside_mythread);
}
int main()
{
thread mt = my_thread(do_something);
mt.join();
return 0;
}
上面的t1就是引發編譯器歧義的地方,也就是作者所舉例說明的情況,下麵來看一下執行結果:
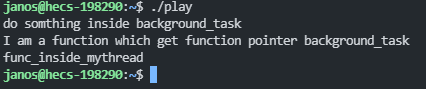
可以發現編譯器把my_thread看作是了一個函數定義,但是實際上這裡我傳入的參數是故意給了一個具名的返回background_tast對象的p函數指針,實際上還可以這麼寫:
int main()
{
//1
thread my_thread(background_task());
//2
background_task f;
thread my_thread(f);
return 0;
}
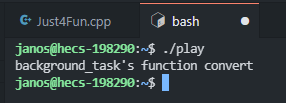
main里的第一句,其實按照語法上來講,這裡的backgroun_task類已經做過了函數類型轉化的操作了,在這裡正常時可以解釋成我定義了一個thread線程對象,他接收可調用對象background_task函數,但是實際上通過vscode自帶的提示器,將滑鼠移動上去以後可以看見它仍然提示這是一個函數聲明:

那如何解決上述問題呢?其實就是書上說的C11以後引入了新式的統一初始化語法,也叫列表初始化,像下麵這樣寫就不存在編譯器把這一行解釋成函數的情況了(或者還可以直接傳入lambda表達式做臨時函數變數也能解決問題):
int main()
{
thread my_thread{background_task()};
my_thread.join();
return 0;
接下來作者說到了線程的分離和匯合,這裡要總結一個概念:如果什麼都不設置,thread對象析構時將自動終止線程程式,如果分離,就算thread對象已經徹底析構了,線程程式還在自己繼續跑著。
這也接下來引發了第二個問題,即如果新線程的函數上持有指向主線程的變數或者數據的指針或引用時,但主線程運行退出後,新線程還沒結束時,這個時候再訪問那些指針的時候就是非法訪問了,書配套代碼如下:
#include <thread>
void do_something(int& i)
{
++i;
}
struct func
{
int& i;
func(int& i_):i(i_){}
void operator()()
{
//for(unsigned j=0;j<1000000;++j)
//這裡為了復現非法訪問的情況改成了無限迴圈
while(1)
{
do_something(i);
}
}
};
void oops()
{
int some_local_state=0;
func my_func(some_local_state);
std::thread my_thread(my_func);
my_thread.detach();
}
int main()
{
oops();
}
這裡要引發的問題就在於,主線程detach以後結束了,自然局部變數得到釋放,但是新增的線程仍然還在跑著,因為傳的是引用類型,所以這個時候再去訪問就是非法訪問了,以下是我的運行結果,估計是Linux內部的什麼機制,主線程一旦退出子線程隨即也退出的場景我沒有復現出來:
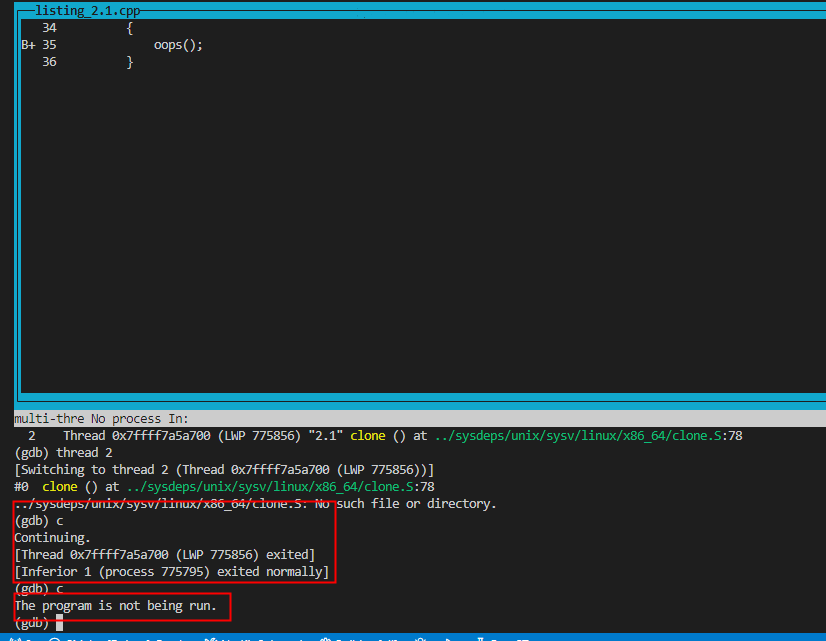
可以看見在gdb中切換到子進程以後輸入c命令讓程式自動運行,主線程775856先退出,隨後子進程立刻也跟著退出了。
解決上述問題的方法作者也給了出來,主要是兩點,一是讓線程函數完全自含(self-contained),另一種是使用thread的join函數,確保子進程在父進程之前退出,也就是匯合線程操作。如果想要更加精細化地控制線程等待,則要到後面講條件變數和future的時候繼續學習,一旦調用了join,則這個線程相關的任何存儲空間都將被立即刪除。
2.1.3 在出現異常的情況下等待
接下來說到了在出現異常狀況下的join等待,主要的問題在於當新線程啟動以後,如果有異常拋出,但是這個時候join在異常的後面,這樣join就得不到執行了略過了,先來看一下代碼清單2.2中不用try-catch的情況:
#include <thread>
#include <iostream>
using namespace std;
void do_something(int& i)
{
++i;
}
struct func
{
int& i;
func(int& i_):i(i_){}
void operator()()
{
for(unsigned j=0;j<1000000;++j)
{
do_something(i);
}
}
};
void do_something_in_current_thread()
{
cout<<"do something error in current thread"<<endl;
}
void f()
{
int some_local_state=0;
func my_func(some_local_state);
std::thread t(my_func);
// try
// {
do_something_in_current_thread();
cout<< 3 / 0 <<endl;
//}
// catch(...)
// {
// t.join();
// throw;
// }
t.join();
}
int main()
{
f();
}
運行結果:通過gdb可以看到出現算術異常時,系統拋出了浮點運算錯誤,此時新線程2因為浮點錯誤直接終止了,但是此時主線程收到了子線程傳過來的SIGFPE信號,也終止了:
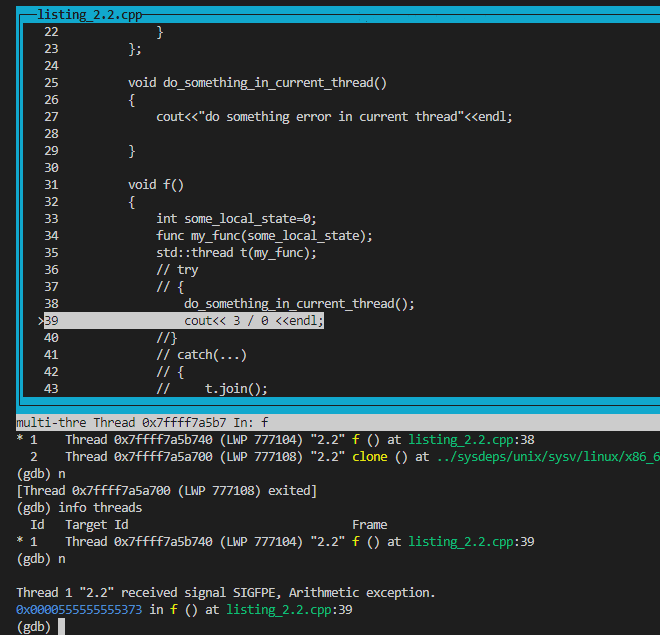
主線程隨後也收到了該信號終止:
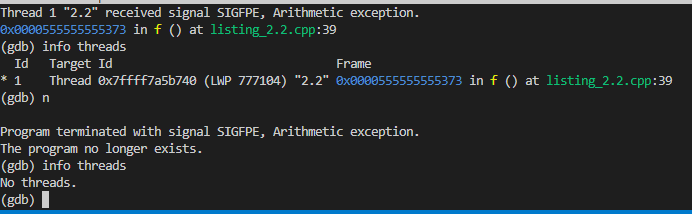
下麵展示成功捕捉到異常然後匯合的場景:
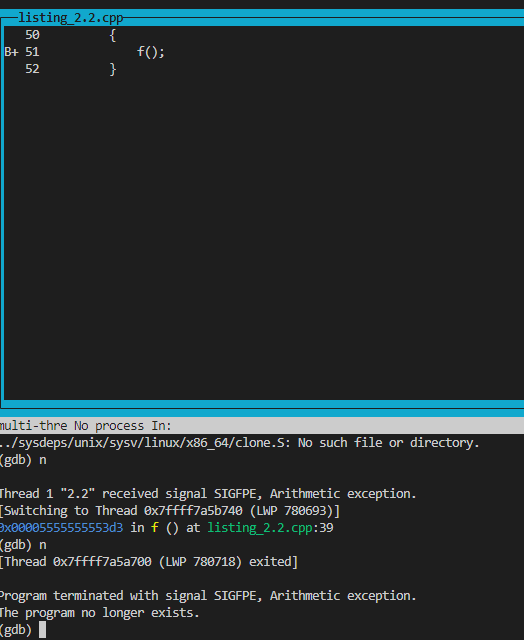
此處新線程在收到SIGFPE時,兩個線程同時終止。上述的使用try-catch捕獲異常的寫法其實稍顯冗餘,更好的是使用標準RALL手法,如下麵配套2.3代碼:
#include <thread>
#include <iostream>
using namespace std;
class thread_guard
{
std::thread& t;
public:
explicit thread_guard(std::thread& t_):
t(t_)
{}
~thread_guard()
{
if(t.joinable())
{
cout<<"Prepare to join"<<endl;
t.join();
}
}
//=delete不允許系統生成自己的預設拷貝和等號運算符重載
thread_guard(thread_guard const&)=delete;
thread_guard& operator=(thread_guard const&)=delete;
};
void do_something(int& i)
{
++i;
}
struct func
{
int& i;
func(int& i_):i(i_){}
void operator()()
{
for(unsigned j=0;j<1000000;++j)
{
do_something(i);
}
}
};
void do_something_in_current_thread()
{}
void f()
{
int some_local_state;
func my_func(some_local_state);
std::thread t(my_func);
thread_guard g(t);
do_something_in_current_thread();
}
int main()
{
f();
}
這裡的要點是,利用析構的順序這個概念,thread_guard對象一定比thread對象t先析構,又用了RALL手法,所以一定可以匯合,不管後面出不出異常,以下是執行結果:
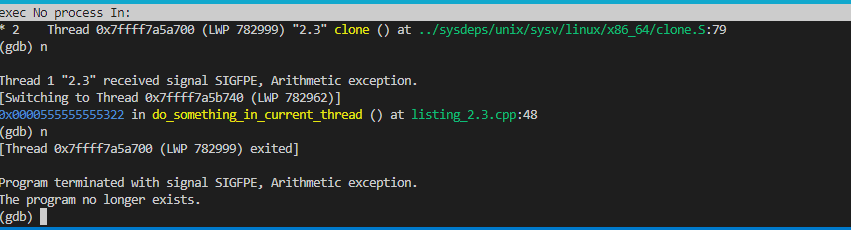
可以看出線上程2出現異常以後,主線程成功調用了join等待到了與2號線程匯合。
2.1.4 在後臺運行線程
這一節主要講了detach的用法以及一個模擬應用場景,提到了守護線程的概念:即和守護進程一樣,被分離出去的線程完全在後臺運行,其幾乎存在於整個應用程式生命周期內。配套代碼2.4給出了文字處理軟體編輯多文件的多線程分離應用場景:
#include <thread>
#include <string>
void open_document_and_display_gui(std::string const& filename)
{}
bool done_editing()
{
return true;
}
enum command_type{
open_new_document
};
struct user_command
{
command_type type;
user_command():
type(open_new_document)
{}
};
user_command get_user_input()
{
return user_command();
}
std::string get_filename_from_user()
{
return "foo.doc";
}
void process_user_input(user_command const& cmd)
{}
void edit_document(std::string const& filename)
{
open_document_and_display_gui(filename);
//while(!done_editing())
for(int i = 0 ;i < 3 ;i++)
{
user_command cmd=get_user_input();
if(cmd.type==open_new_document)
{
std::string const new_name=get_filename_from_user();
std::thread t(edit_document,new_name);
t.detach();
}
else
{
process_user_input(cmd);
}
}
}
int main()
{
edit_document("bar.doc");
}
主要是模擬多線程處理過程,這裡就跳過執行結果了。
2.2 向線程函數傳遞參數
首先總結一個概念:線程的內部是有存儲空間的,任何傳遞給線程的函數參數都會預設先被複製到該處,隨後新線程才能訪問他們,再然後這些副本被當做右值傳給線程上的可調用對象。
上述的概念引出了書中說的第一個錯誤,示例如下:
void f(int i,std::string const& s);
void oops(int some_param)
{
char buffer[1024]; // ⇽--- ①
sprintf(buffer, "%i",some_param);
std::thread t(f,3,buffer); // ⇽--- ②
t.detach();
}
這裡的問題在於,因為thread的構造函數需要原樣複製所提供的值,然後再轉換成可調用對象參數的預期類型,所以有可能oops在這個複製過程中先行崩潰或者退出,導致局部變數buffer被銷毀而引發未定義的行為,所以作者提出的解決辦法是先給他手工轉成string:
std::string(buffer)
然後再傳進去就行了。
另一個場景剛好相反,也就是我們期望參數類型是非const引用,而岸上上述的thread構造概念,整個對象卻被完全複製了一遍,這個是不合理的情況,編譯也過不了,這裡作者沒給出示例代碼,我寫了一段驗證之:
#include <thread>
#include <iostream>
#include <condition_variable>
#include <queue>
#include <mutex>
#include <stdlib.h>
#include <string.h>
using namespace std;
struct widget_id
{
int id;
};
struct widget_data
{
};
void update_data_for_widget(widget_id w, widget_data & data)
{
}
void oops_again(widget_id w)
{
widget_data data;
//正確情況
//thread t(update_data_for_widget,w,ref(data));
//非正確,編譯錯誤
thread t(update_data_for_widget,w,data);
t.join();
}
int main()
{
oops_again(widget_id());
return 0;
}
編譯錯誤顯示如下:
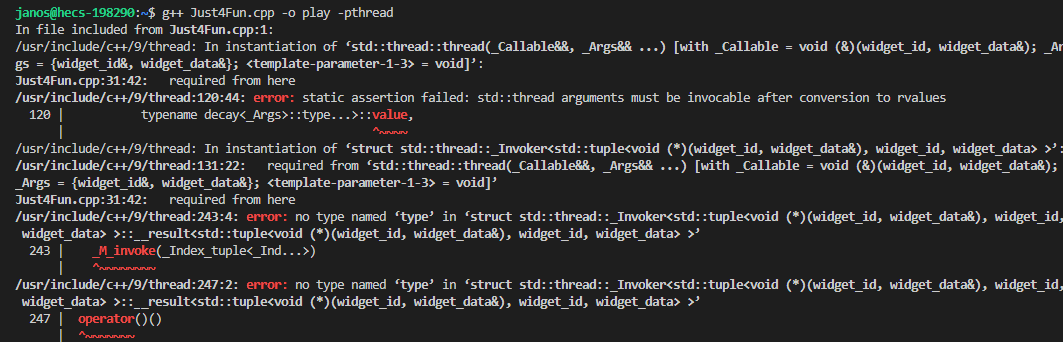
這裡的解決方案是利用標準的std::ref函數做一層包裝,把它強制轉成左值引用傳入,這裡其實內部還有的講(即為什麼ref之後就會忽略thread構造本身需要複製一遍的事實呢?這裡其實是內部用forward實現了完美轉發),引用類型按照原先的類型傳遞到了線程的可調用對象參數列表中。
bind函數和thread構造的參數傳遞機制其實很相似,下一部分作者提到瞭如何將一個類的非靜態成員函數最為thread的調用對象的,其原理譯者在下方1號註釋中做了說明。
2.3 移交線程歸屬權
如果thread對象正在管理一個線程,就不能簡單地向他賦新值,否則新線程會因此被遺棄。這一節主要講的是移動語義和線程歸屬權相互移交的過程,代碼清單2-5展示了從函數內部返回thread對象,清單2-6和之前的2-3很相似,只不過在構造函數用了移動語義直接去構造要接管的thread對象,以及本來要引入C17的joining_thread類,這裡就不做展示和演示了。
清單2.7展示了線程管控自動化切分的簡單實現,用vector管理了一堆線程:
#include <vector>
#include <thread>
#include <algorithm>
#include <functional>
void do_work(unsigned id)
{}
void f()
{
std::vector<std::thread> threads;
for(unsigned i=0;i<20;++i)
{
threads.push_back(std::thread(do_work,i));
}
std::for_each(threads.begin(),threads.end(),
std::mem_fn(&std::thread::join));
}
int main()
{
f();
}
這裡使用了標準的mem_fn,返回一個指向其參數函數的函數指針用於foreach遍歷。
2.4 在運行時選擇線程數量
這章簡單實現了一個並行版本的accumulate,無特別說明,看懂代碼和說明即可。
2.5 識別線程
主要介紹了線程id,如何獲取它(調用thread.get_id),獲取當前線程的方法(this_thread)以及標準庫對其實現了全面的比較運算符支持。


