
摘要:讓我們看一個示例,展示在記憶體消耗方面,採用流的編程思路帶來的巨大優越性。 本文分享自華為雲社區《使用 Node.js Stream API 減少伺服器端記憶體消耗的一個具體例子》,作者:Jerry Wang 。 HTTP 響應對象(上面代碼中的 res)也是一個可寫流。這意味著如果我們有一個表示 ...
摘要:讓我們看一個示例,展示在記憶體消耗方面,採用流的編程思路帶來的巨大優越性。
本文分享自華為雲社區《使用 Node.js Stream API 減少伺服器端記憶體消耗的一個具體例子》,作者:Jerry Wang 。
HTTP 響應對象(上面代碼中的 res)也是一個可寫流。這意味著如果我們有一個表示 big.file 內容的可讀流,我們可以將這兩個相互連接起來,併在不消耗約 400 MB 記憶體的情況下獲得幾乎相同的結果。 Node 的 fs 模塊可以使用 createReadStream 方法為我們提供任何文件的可讀流。 我們可以將其通過管道傳遞給響應對象。
讓我們看一個示例,展示在記憶體消耗方面,採用流的編程思路帶來的巨大優越性。
我們先創建一個大文件:
const fs = require('fs'); const file = fs.createWriteStream('./big.file'); for(let i=0; i<= 1e6; i++) { file.write('this is a big file.\n'); } file.end();
fs 模塊可用於使用流介面讀取和寫入文件。 在上面的示例中,我們通過一個迴圈寫入 100 萬行的可寫流,向該 big.file 寫入數據。
運行上面的代碼會生成一個大約 400 MB 的文件。
這是一個簡單的 Node Web 伺服器,旨在專門為 big.file 提供服務:
const fs = require('fs'); const server = require('http').createServer(); server.on('request', (req, res) => { fs.readFile('./big.file', (err, data) => { if (err) throw err; res.end(data); }); }); server.listen(8000);
啟動該伺服器,其消耗的初始記憶體為 8 MB 左右。
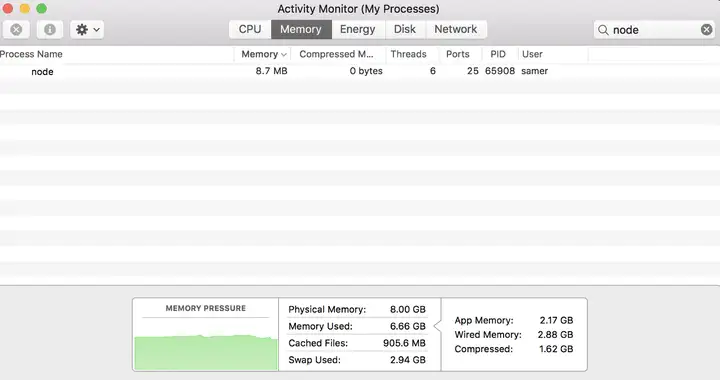
使用瀏覽器訪問伺服器之後,記憶體消耗躍升至 434.8 MB。
我們基本上將整個 big.file 內容放在記憶體中,然後再將其寫入響應對象。 這是非常低效的。
HTTP 響應對象(上面代碼中的 res)也是一個可寫流。 這意味著如果我們有一個表示 big.file 內容的可讀流,我們可以將這兩個相互連接起來,併在不消耗約 400 MB 記憶體的情況下獲得幾乎相同的結果。
Node 的 fs 模塊可以使用 createReadStream 方法為我們提供任何文件的可讀流。 我們可以將其通過管道傳遞給響應對象:
const fs = require('fs'); const server = require('http').createServer(); server.on('request', (req, res) => { const src = fs.createReadStream('./big.file'); src.pipe(res); }); server.listen(8000);
我們現在訪問上述重新實現過的伺服器,發現記憶體消耗量大大降低了。
這是因為,當客戶端請求該大文件時,我們一次將其流式傳輸一個塊,這意味著我們根本不會將其整個的龐大文件內容緩衝在記憶體中。 記憶體使用量增加了大約 25 MB,僅此而已。
我們可以把測試場景設計得更極端一些:用 500 萬行而不是 100 萬行重新生成 big.file,這將使文件超過 2 GB,這實際上大於 Node.js 中的預設緩衝區限制。
如果嘗試使用 fs.readFile 提供該文件,則預設情況下會出現 out of memory 的錯誤。
但是使用 fs.createReadStream,將 2 GB 的數據流式傳輸到請求者完全沒有問題,而且最重要的是,進程記憶體使用情況大致相同。

