
Redis 數據結構-雙向鏈表 最是人間留不住,朱顏辭鏡花辭樹。 1、簡介 Redis 之所以快主要得益於它的數據結構、操作記憶體資料庫、單線程和多路 I/O 復用模型,進一步窺探下它常見的五種基本數據的底層數據結構。 Redis 常見數據類型對應的的底層數據結構。 String:簡單動態字元串。 L ...
Redis 數據結構-雙向鏈表
最是人間留不住,朱顏辭鏡花辭樹。
1、簡介
Redis 之所以快主要得益於它的數據結構、操作記憶體資料庫、單線程和多路 I/O 復用模型,進一步窺探下它常見的五種基本數據的底層數據結構。
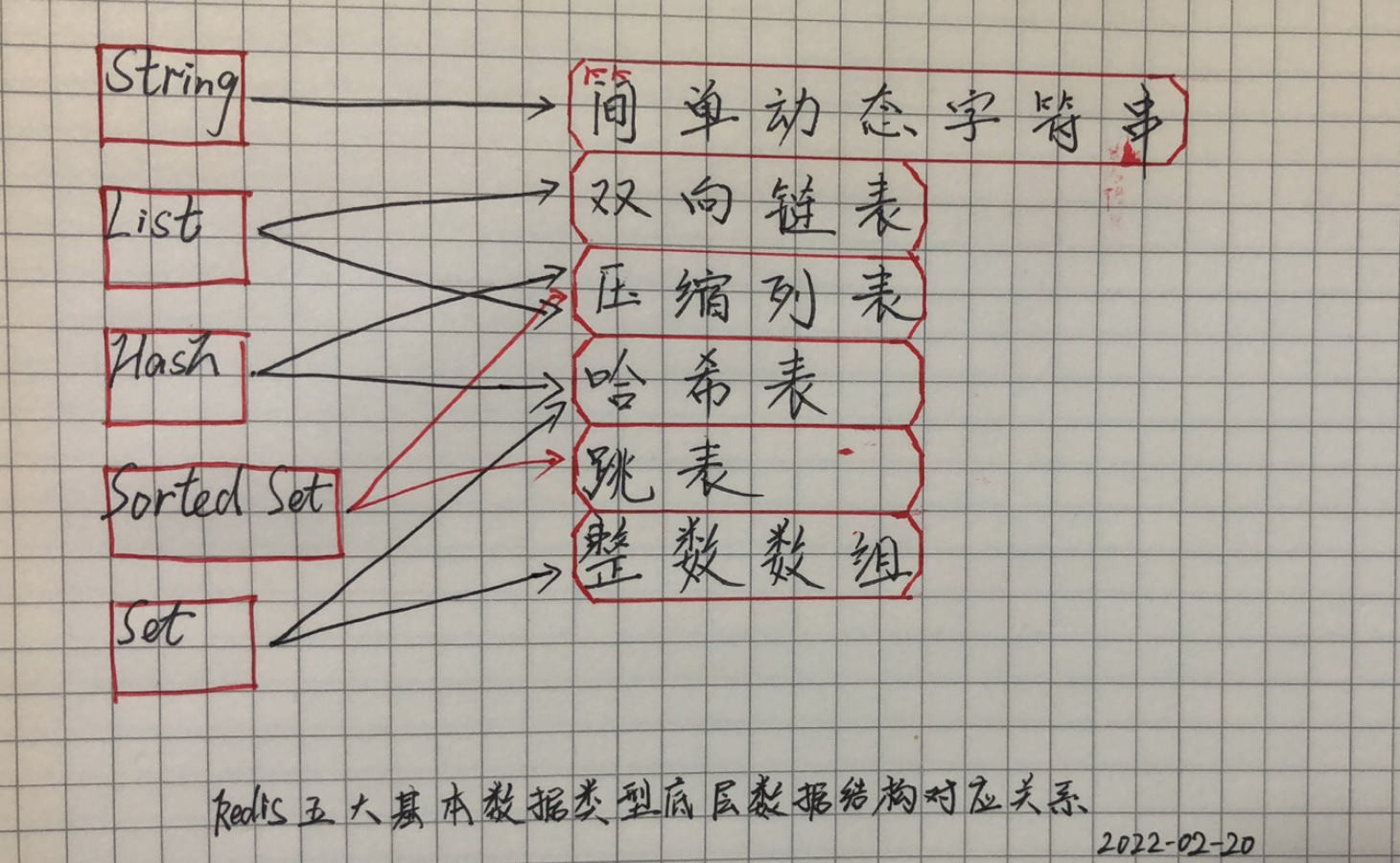
Redis 常見數據類型對應的的底層數據結構。
- String:簡單動態字元串。
- List:雙向鏈表、壓縮列表。
- Hash:壓縮列表、哈希表。
- Sorted Set:壓縮列表、跳錶。
- Set:哈希表、整數數組。
2、雙向鏈表
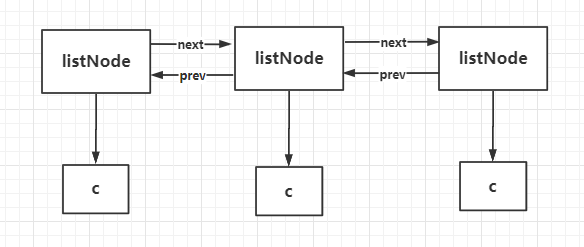
C 語言是沒有內置鏈表這種結構,而當一個列表鍵包含較多的元素,或者列表中包含的元素都是比較長的字元串的時,Redis 就會使用鏈表作為 list 的底層實現,就自己實現了雙向鏈表,相當於Java 語言中的LinkedList,但又不完全是。
單純的鏈表優缺點:
- 雙向鏈表數據結構,支持前後順序遍歷。
- 不需要連續的的記憶體空間,插入和刪除的時間複雜度是 O(1) 級別的,效率較高。
- 比起數組它的缺點就是查詢較慢(時間複雜度O(n))。
常見使用場景
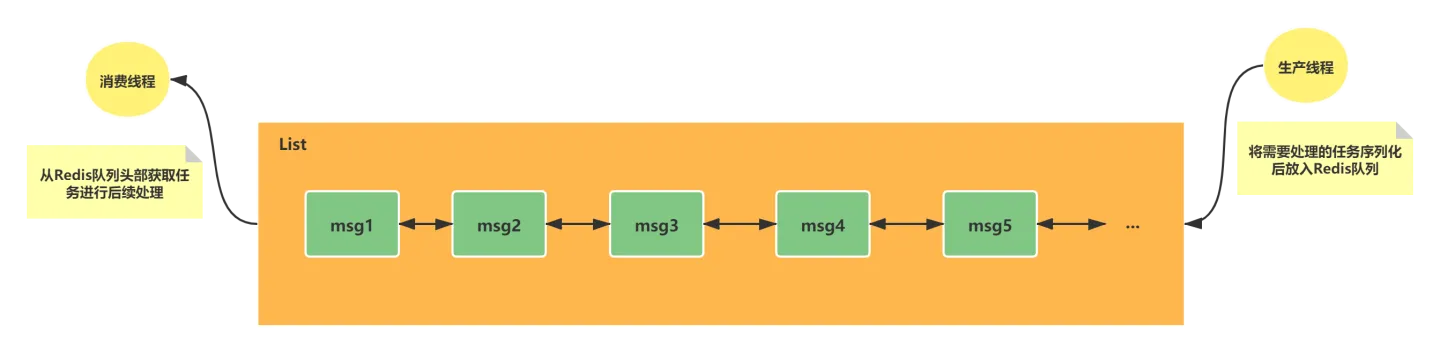
雙向鏈表的特性經常被用於非同步隊列的使用。實際開發中將需要延後處理的任務結構體序列化成字元串,放入Redis 的隊列中,另一個線程從這個列表中獲取數據進行後續的業務邏輯。
鏈表節點結構
從redis/src/adlist.h 源碼文件中查看鏈表節點結構設計。
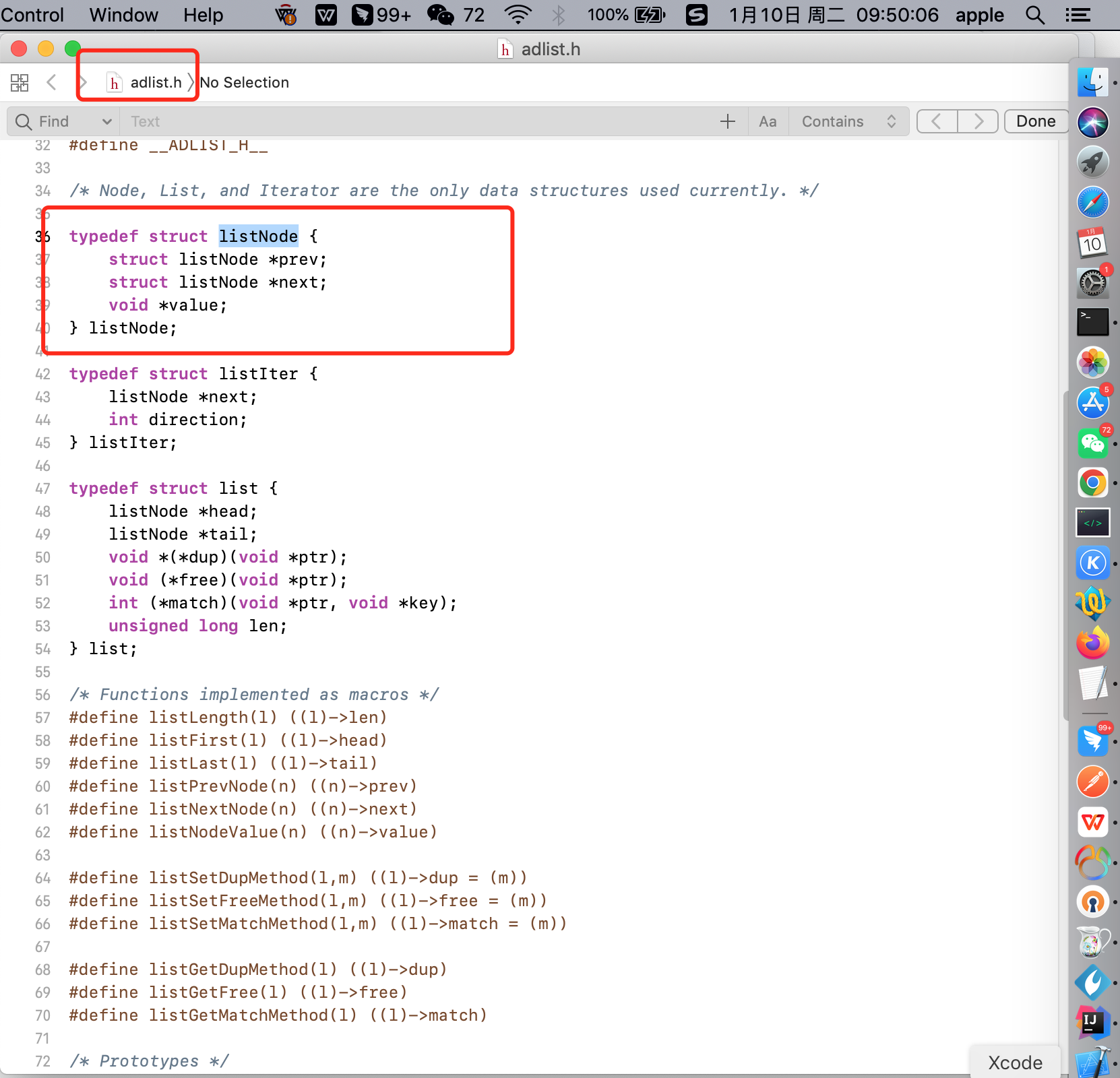
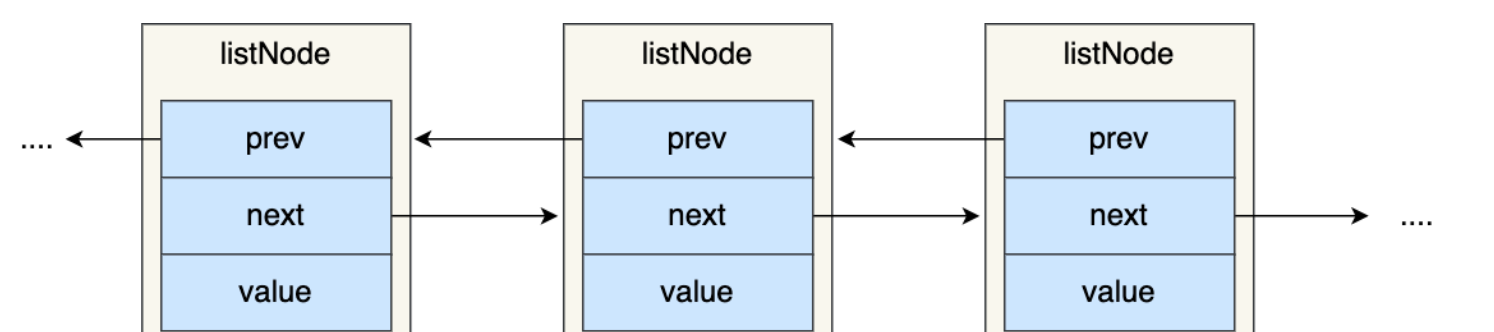
1 typedef struct listNode { 2 struct listNode *prev; // 前置節點,如果是list的頭結點,則prev指向NULL 3 struct listNode *next;// 後置節點,如果是list尾部結點,則next指向NULL 4 void *value; // 記錄該節點的值,能夠存放任何信息(也叫萬能節點) 5 } listNode;
從listNode 結構中看到一個節點由頭指針 prev 、尾指針 next 以及節點的值 value 組成,這種有前置節點和後置節點很明顯就是一個雙向鏈表。
鏈表結構
為了方便操作,Redis 在 listNode 鏈表節點結構體基礎上又封裝了 list 這個數據結構,而且封裝之後,還提供了頭節點、尾節點以及一些自定義的函數。鏈表結構如下:
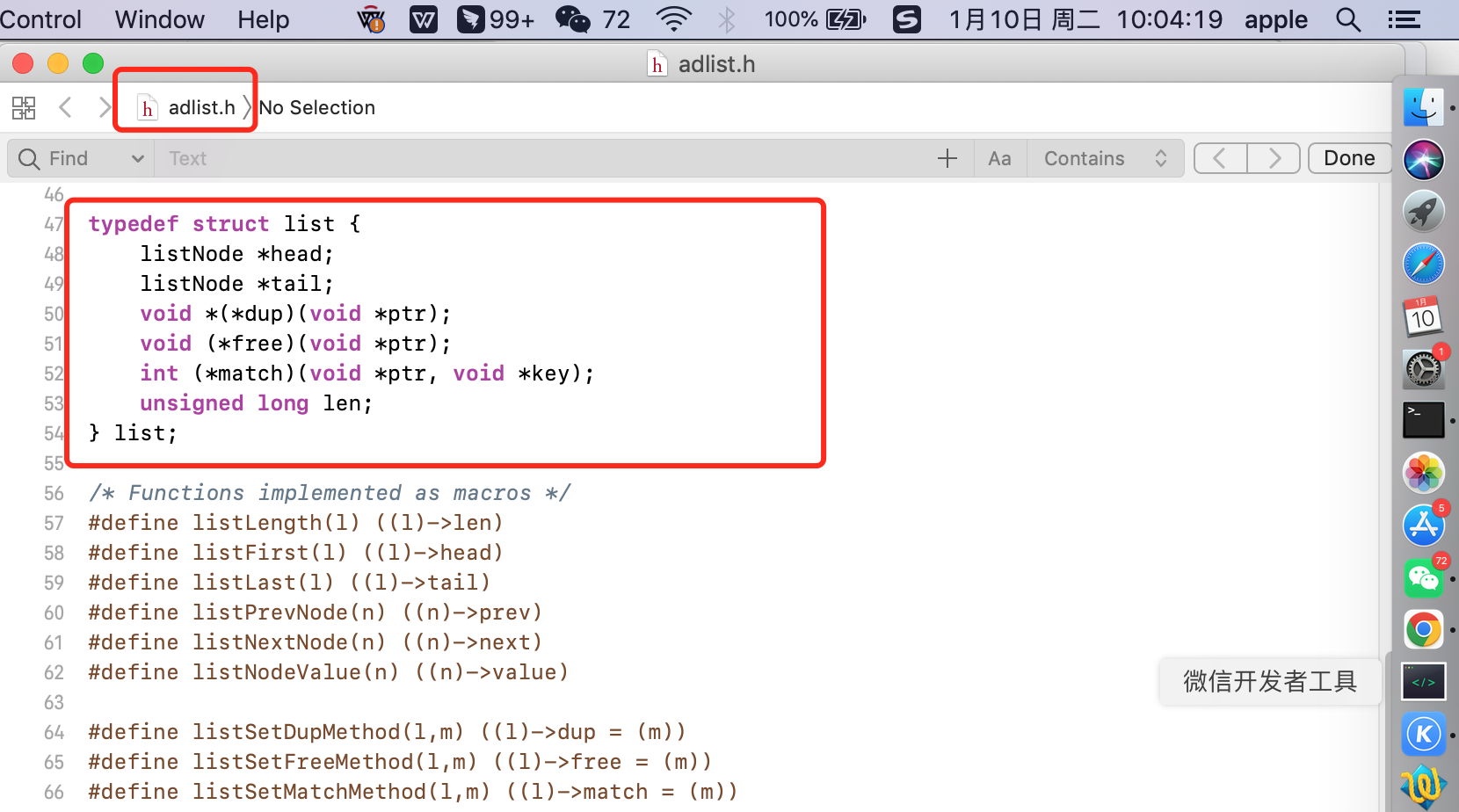
1 typedef struct list { 2 listNode *head; // 鏈表 頭結點 指針 3 listNode *tail; // 鏈表 尾結點 指針 4 unsigned long len; // 鏈表長度計數器 即 節點的個數 5 6 // 三個函數指針 7 void *(*dup)(void *ptr); // 複製函數 複製鏈表節點保存的值 8 void (*free)(void *ptr); // 釋放函數 釋放鏈表節點保存的值 9 int (*match)(void *ptr, void *key); // 匹配函數 查找節點時使用 比較鏈表節點所保存的節點值和另一個輸入的值是否相等 10 } list;
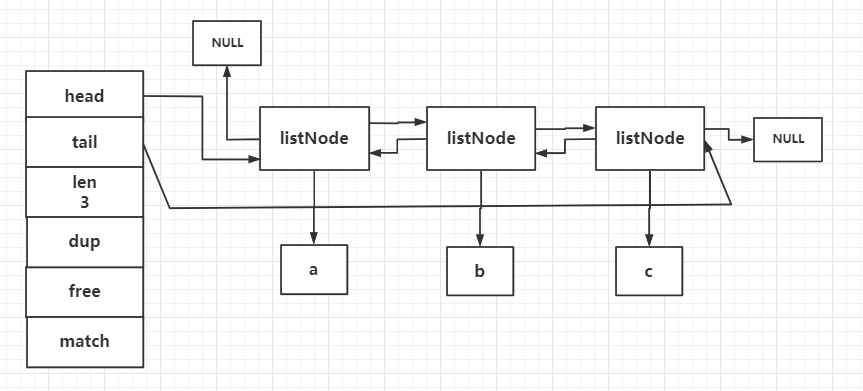
list 結構為鏈表提供了鏈表頭指針 head、鏈表尾節點 tail、鏈表節點數量 len、以及可以自定義實現的 dup、free、match 函數。
- head:鏈表 頭結點 指針,指向了雙向鏈表的最開始的一個節點;
- tail:鏈表 尾結點 指針,指向了雙向鏈表的最後一個節點;
- len:代表了雙向鏈表節點的數量;
- dup:複製函數,用於複製雙向鏈表節點所保存的值;
- free:釋放函數,用於釋放雙向鏈表節點所保存的值;
- match:匹配函數,用於對比雙向鏈表節點所保存的值和另外一個的輸入值是否相等。
相關命令
右進左出(隊列)
隊列在結構上是先進先出(FIFO)的數據結構(比如排隊購票的順序),常見場景如消息排隊、非同步處理等,用於確保元素的訪問順序。
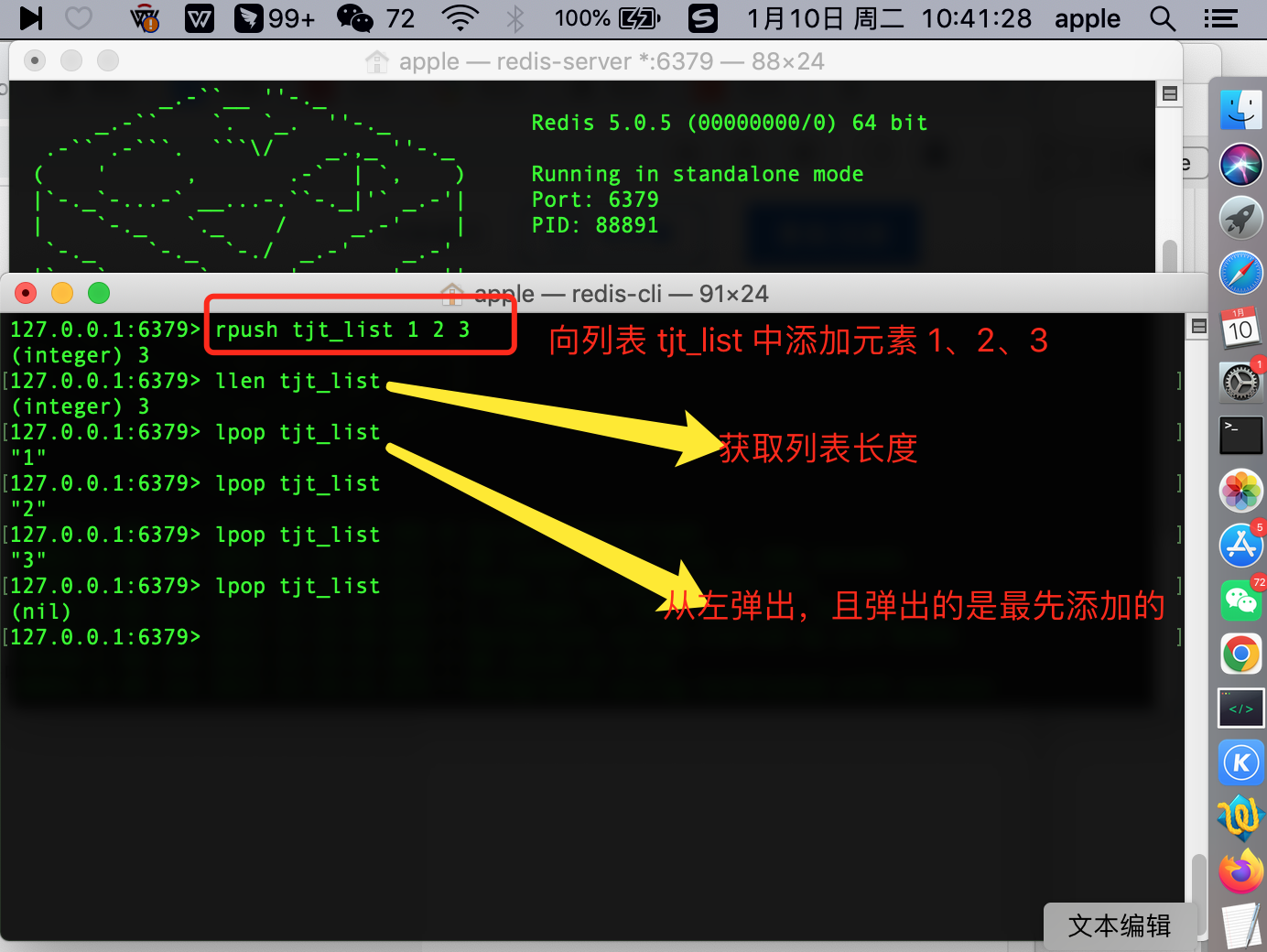
lpush -> 從左邊邊添加元素
127.0.0.1:6379> lpush tjt_list 1 2 3
rpush -> 從右邊添加元素
127.0.0.1:6379> rpush tjt_list 1 2 3
llen -> 獲取列表的長度
127.0.0.1:6379> llen tjt_list
lpop -> 從左邊彈出元素
127.0.0.1:6379> lpop tjt_list
右進右出(棧)
棧在結構上是先進後出(FILO)的數據結構(比如彈夾壓入子彈,子彈被射擊出去的順序就是棧),這種數據結構一般用來處理一些逆序輸出的業務場景。
lpush -> 從左邊邊添加元素
127.0.0.1:6379> lpush tjt_list 1 2 3
rpush -> 從右邊添加元素
127.0.0.1:6379> rpush tjt_list 1 2 3
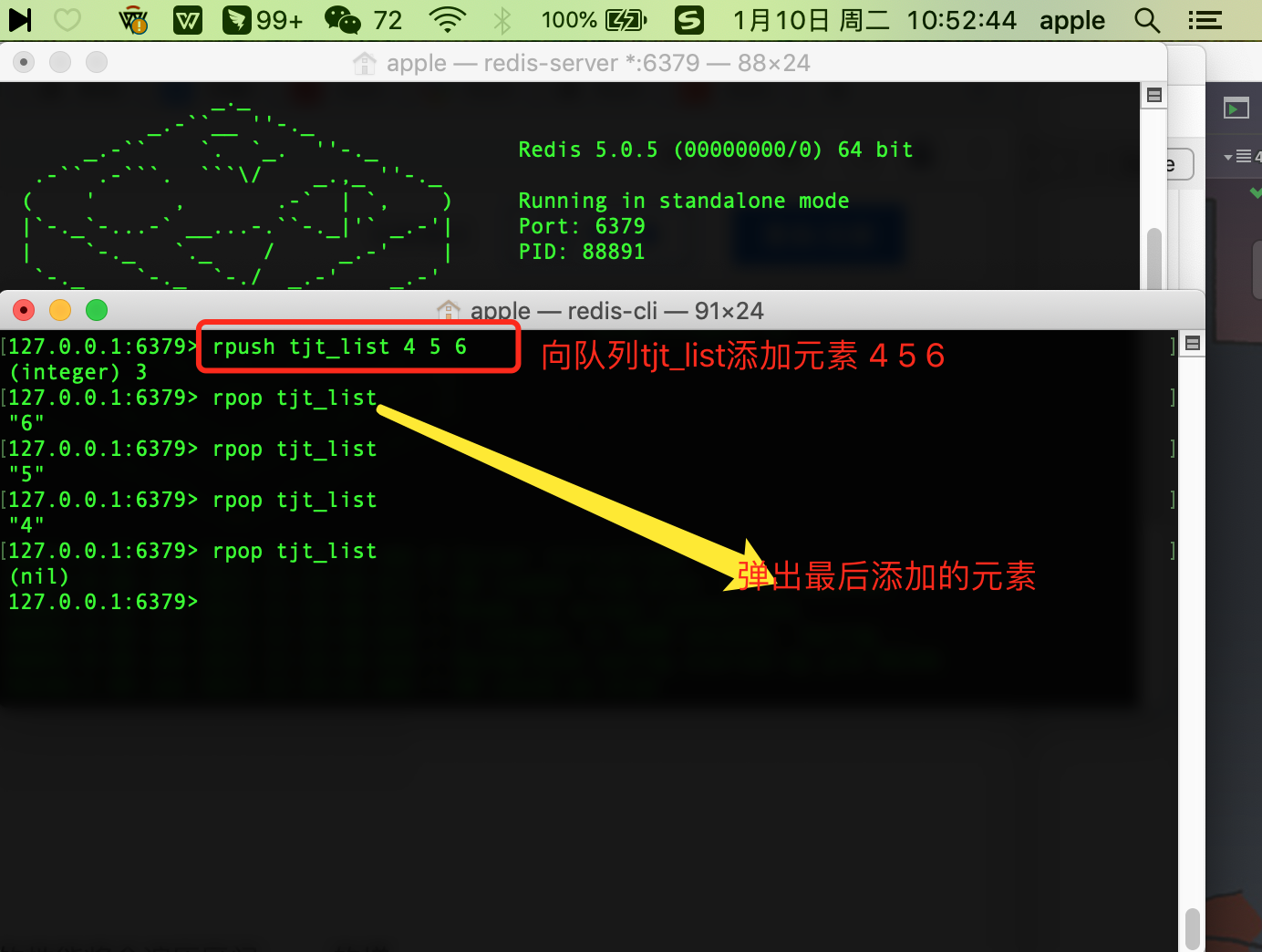
rpop -> 從右邊彈出元素
127.0.0.1:6379> rpop tjt_list
慢操作
由於列表(list)的鏈表數據結構,它的遍歷是慢操作,所以涉及到遍歷的性能將會隨著遍歷區間range 的增大而增大。在Redis 鏈表中,list 的索引運行為負數,-1代表倒數第一個,-2代表倒數第二個,其它同理。
lindex -> 遍歷獲取列表指定索引處的值(下方所有為 0)
127.0.0.1:6379> lindex tjt_list 0 "you"
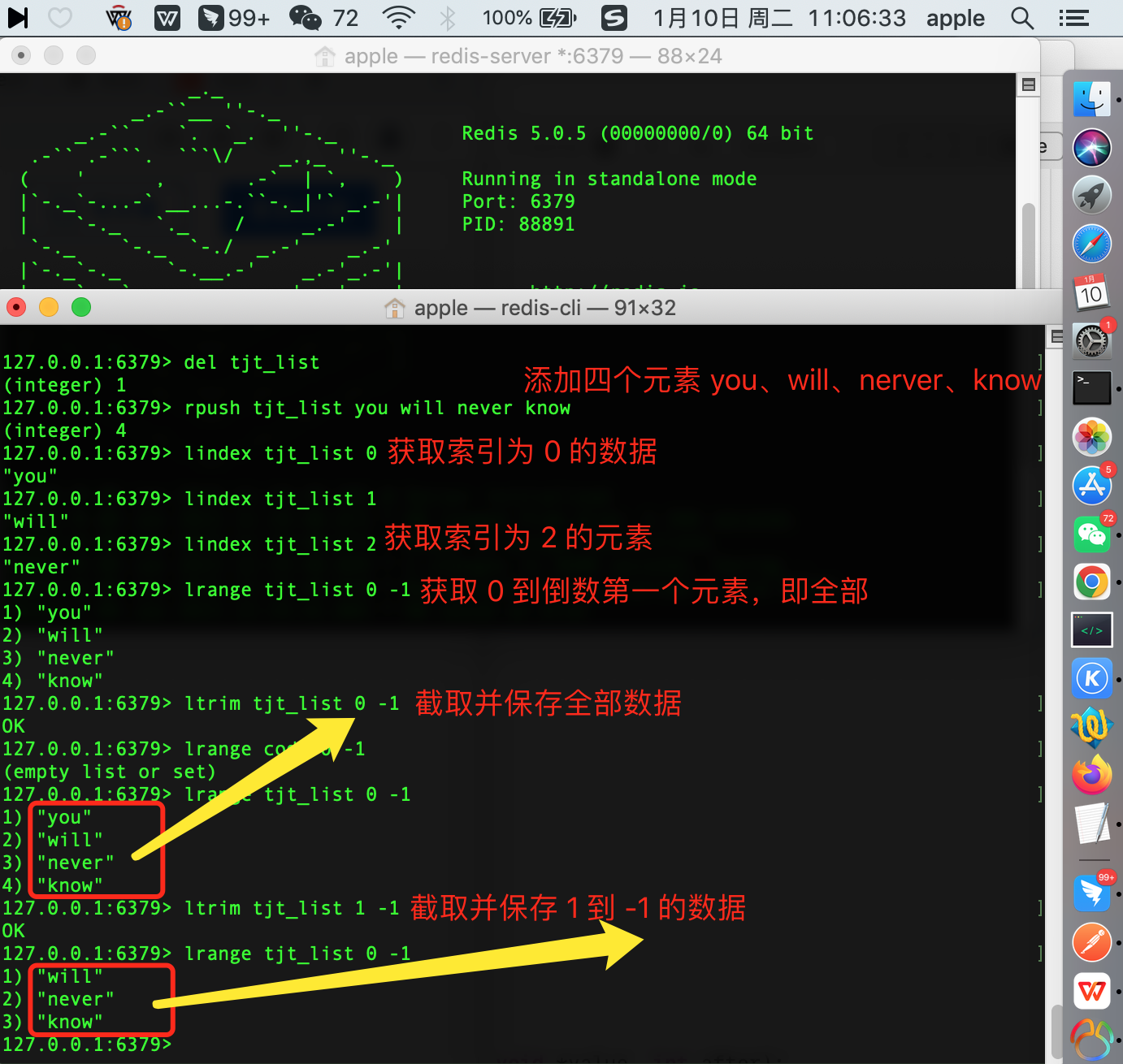
lrange -> 獲取從索引start 到stop 處的全部值
127.0.0.1:6379> lrange tjt_list 0 -1 1) "you" 2) "will" 3) "never" 4) "know"
ltrim -> 截取並保存索引start 到stop 處的全部值,其它將會被刪除
127.0.0.1:6379> ltrim tjt_list 1 -1 OK 127.0.0.1:6379> lrange tjt_list 0 -1 1) "will" 2) "never" 3) "know"
非普通LinkedList
前面提到了Redis 數據類型List 對應的的底層數據結構有 雙向鏈表 和 壓縮列表,因為 Redis底層存儲list(列表)不是一個簡單的LinkedList,而是quicklist 快速列表。
為什麼用quicklist 替代LinkedList
普通的LinkedList node節點元素,都會持有一個prev-> 執行前一個node 節點和next-> 指向後一個node 節點的指針(引用),這種結構雖然支持前後順序遍歷,但是也帶來了不小的記憶體開銷,如果node 節點僅僅是一個int 類型的值,那麼引用的記憶體比例將會更大。所以Redis 底層對於list(列表)的存儲,當元素個數少的時候,它會使用一塊連續的記憶體空間來存儲,這樣可以減少每個元素增加prev 和next 指針帶來的記憶體消耗,減少記憶體碎片化問題。
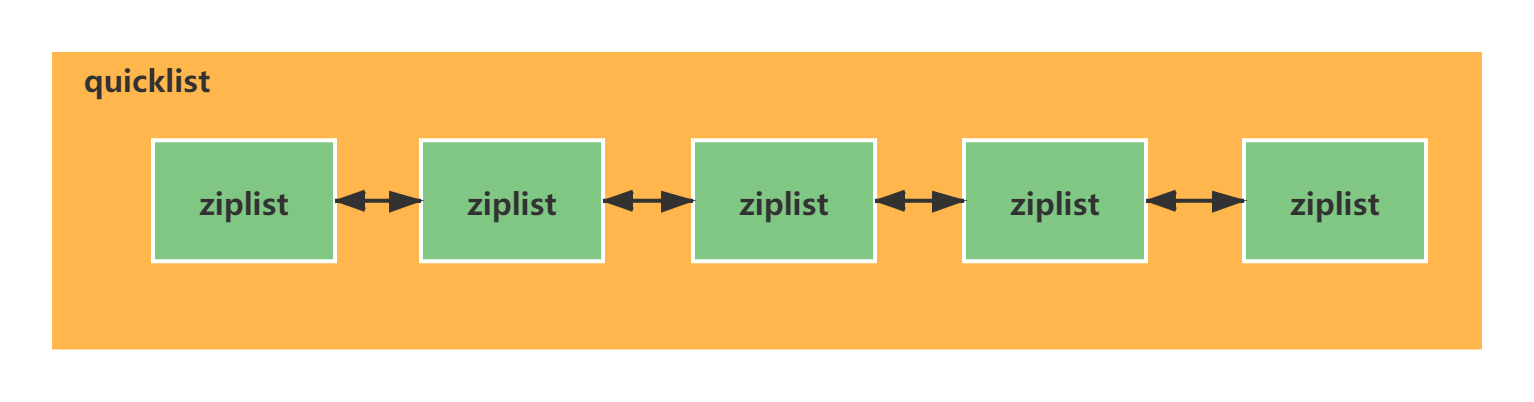
quicklist
quicklist 是多個ziplist (壓縮列表)組成的雙向列表。
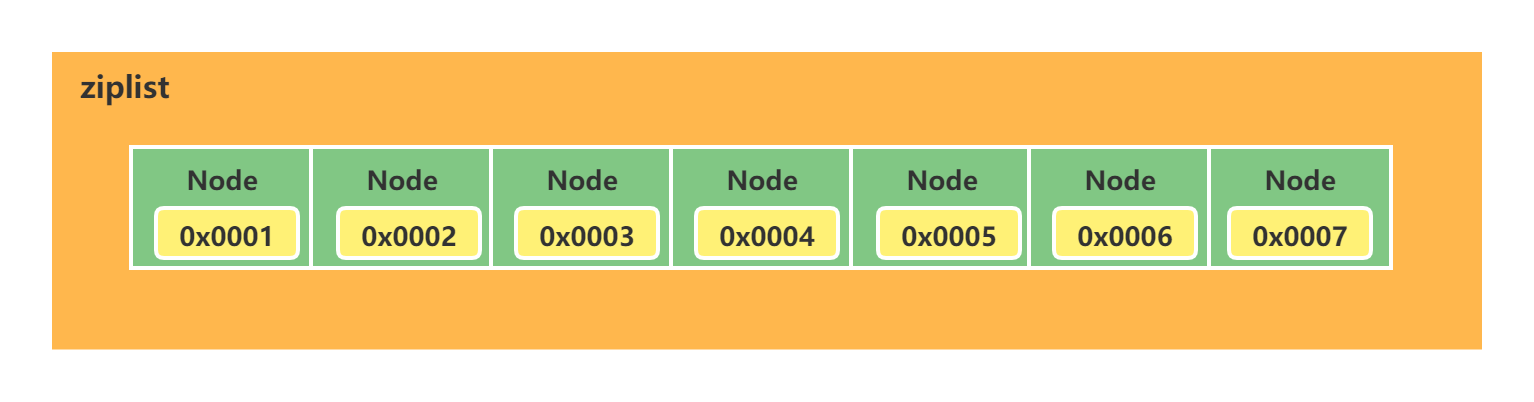
ziplist
ziplist是一塊連續的記憶體地址,他們之間無需持有prev和next指針,能通過地址順序定址訪問。
3、鏈表小結
鏈表優勢
- listNode 鏈表節點的結構裡帶有 prev 和 next 指針,獲取某個節點的前置節點或後置節點的時間複雜度只需O(1),而且這兩個指針都可以指向 NULL,所以鏈表是無環鏈表,對雙向鏈表的訪問以 NULL 結束;
- list 結構因為提供了表頭指針 head 和表尾節點 tail,所以獲取鏈表的表頭、表尾節點的時間複雜度都是 O(1);
- list 結構因為提供了鏈表節點數量 len,通過 len 屬性直接獲取節點的數量,時間複雜度為 O(1) , 效率高;
- listNode 鏈表節使用 void* 指針保存節點值,並且可以通過 list 結構的 dup、free、match 函數指針為節點設置該節點類型特定的函數,因此鏈表節點可以保存各種不同類型的值。
鏈表缺陷
- 鏈表每個節點之間的記憶體都是不連續的,無法很好利用 CPU 緩存。數組數據結構就能很好利用 CPU 緩存,因為數組的記憶體是連續的,可以充分利用 CPU 緩存來加速訪問。
- 保存一個鏈表節點的值每次都需要為一個鏈表節點結構頭分配空間,記憶體開銷較大。Redis 3.0 的 List 對象在數據量比較少的情況下,會採用 壓縮列表 作為底層數據結構的實現,節省記憶體空間,降低保存鏈表節點的記憶體開銷。
最是人間留不住 朱顏辭鏡花辭樹


