
select/poll/epoll 是 Linux 伺服器提供的三種處理高併發網路請求的 IO 多路復用技術,是個老生常談又不容易弄清楚其底層原理的知識點,本文打算深入學習下其實現機制。 Linux 伺服器處理網路請求有三種機制,select、poll、epoll,本文打算深入學習下其實現原理。 ... ...

select/poll/epoll 是 Linux 伺服器提供的三種處理高併發網路請求的 IO 多路復用技術,是個老生常談又不容易弄清楚其底層原理的知識點,本文打算深入學習下其實現機制。
Linux 伺服器處理網路請求有三種機制,select、poll、epoll,本文打算深入學習下其實現原理。
吃水不忘挖井人,最近兩周花了些時間學習了張彥飛大佬的文章 圖解 | 深入揭秘 epoll 是如何實現 IO 多路復用的 和其他文章 ,及出版的書籍《深入理解 Linux 網路》,對阻塞 IO、多路復用、epoll 等的實現原理有了一定的瞭解;飛哥的文章描述底層源碼邏輯比較清晰,就是有時候歸納總結事情本質的抽象程度不夠,涉及內核源碼細節的講述較多,會讓讀者產生一定的學習成本,本文希望在這方面改進一下。
0. 結論
本文其他的內容主要是得出了下麵幾個結論:
-
伺服器要接收客戶端的數據,要建立 socket 內核結構,主要包含兩個重要的數據結構,(進程)等待隊列,和(數據)接收隊列,socket 在進程中作為一個文件,可以用文件描述符 fd 來表示,為了方便理解,本文中, socket 內核對象 ≈ fd 文件描述符 ≈ TCP 連接;
-
阻塞 IO 的主要邏輯是:服務端和客戶端建立了連接 socket 後,服務端的用戶進程通過 recv 函數接收數據時,如果數據沒有到達,則當前的用戶進程的進程描述符和回調函數會封裝到一個進程等待項中,加入到 socket 的進程等待隊列中;如果連接上有數據到達網卡,由網卡將數據通過 DMA 控制器拷貝到內核記憶體的 RingBuffer 中,並向 CPU 發出硬中斷,然後,CPU 向內核中斷進程 ksoftirqd 發出軟中斷信號,內核中斷進程 ksoftirqd 將內核記憶體的 RingBuffer 中的數據根據數據報文的 IP 和埠號,將其拷貝到對應 socket 的數據接收隊列中,然後通過 socket 的進程等待隊列中的回調函數,喚醒要處理該數據的用戶進程;
-
阻塞 IO 的問題是:一次數據到達會進行兩次進程切換,一次數據讀取有兩處阻塞,單進程對單連接;
-
非阻塞 IO 模型解決了“兩次進程切換,兩處阻塞,單進程對單連接”中的“兩處阻塞”問題,將“兩處阻塞”變成了“一處阻塞”,但依然存在“兩次進程切換,一處阻塞,單進程對單連接”的問題;
-
用一個進程監聽多個連接的 IO 多路復用技術解決了“兩次進程切換,一處阻塞,單進程對單連接” 中的“兩次進程切換,單進程對單連接”,剩下了“一處阻塞”,這是 Linux 中同步 IO 都會有的問題,因為 Linux 沒有提供非同步 IO 實現;
-
Linux 的 IO 多路復用用三種實現:select、poll、epoll。select 的問題是:
a)調用 select 時會陷入內核,這時需要將參數中的 fd_set 從用戶空間拷貝到內核空間,高併發場景下這樣的拷貝會消耗極大資源;(epoll 優化為不拷貝)
b)進程被喚醒後,不知道哪些連接已就緒即收到了數據,需要遍歷傳遞進來的所有 fd_set 的每一位,不管它們是否就緒;(epoll 優化為非同步事件通知)
c)select 只返回就緒文件的個數,具體哪個文件可讀還需要遍歷;(epoll 優化為只返回就緒的文件描述符,無需做無效的遍歷)
d)同時能夠監聽的文件描述符數量太少,是 1024 或 2048;(poll 基於鏈表結構解決了長度限制)
-
poll 只是基於鏈表的結構解決了最大文件描述符限制的問題,其他 select 性能差的問題依然沒有解決;終極的解決方案是 epoll,解決了 select 的前三個缺點;
-
epoll 的實現原理看起來很複雜,其實很簡單,註意兩個回調函數的使用:數據到達 socket 的等待隊列時,通過回調函數 ep_poll_callback 找到 eventpoll 對象中紅黑樹的 epitem 節點,並將其加入就緒列隊 rdllist,然後通過回調函數 default_wake_function 喚醒用戶進程 ,並將 rdllist 傳遞給用戶進程,讓用戶進程準確讀取就緒的 socket 的數據。這種回調機制能夠定向準確的通知程式要處理的事件,而不需要每次都迴圈遍歷檢查數據是否到達以及數據該由哪個進程處理,日常開發中可以學習借鑒下這種思想。
1. Linux 怎樣處理網路請求
1.1 阻塞 IO
要講 IO 多路復用,最好先把傳統的同步阻塞的網路 IO 的交互方式剖析清楚。
如果客戶端想向 Linux 伺服器發送一段數據 ,C 語言的實現方式是:
int main()
{
int fd = socket(); // 創建一個網路通信的socket結構體
connect(fd, ...); // 通過三次握手跟伺服器建立TCP連接
send(fd, ...); // 寫入數據到TCP連接
close(fd); // 關閉TCP連接
}服務端通過如下 C 代碼接收客戶端的連接和發送的數據:
int main()
{
fd = socket(...); // 創建一個網路通信的socket結構體
bind(fd, ...); // 綁定通信埠
listen(fd, 128); // 監聽通信埠,判斷TCP連接是否可以建立
while(1) {
connfd = accept(fd, ...); // 阻塞建立連接
int n = recv(connfd, buf, ...); // 阻塞讀數據
doSomeThing(buf); // 利用讀到的數據做些什麼
close(connfd); // 關閉連接,迴圈等待下一個連接
}
}把服務端處理請求的細節展開,得到如下圖所示的同步阻塞網路 IO 的數據接收流程:
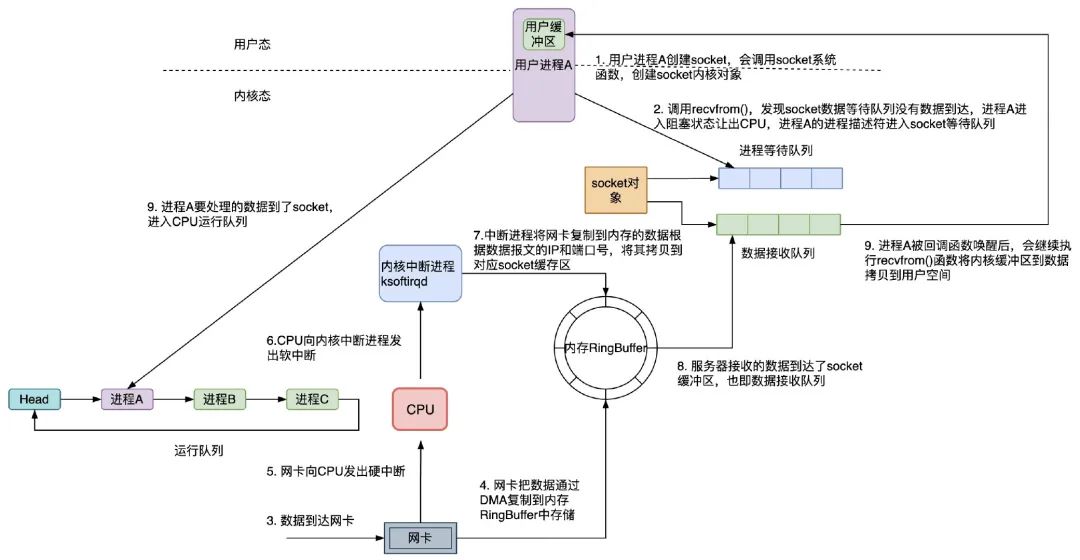
主要步驟是:
1)服務端通過 socket() 函數陷入內核態進行 socket 系統調用,該內核函數會創建 socket 內核對象,主要有兩個重要的結構體,(進程)等待隊列,和(數據)接收隊列,為了方便理解,等待隊列前可以加上進程二字,其實不加更準確,接收隊列同樣;進程等待隊列,存放了服務端的用戶進程 A 的進程描述符和回調函數;socket 的數據接收隊列,存放網卡接收到的該 socket 要處理的數據;
2)進程 A 調用 recv() 函數接收數據,會進入到 recvfrom() 系統調用函數,發現 socket 的數據等待隊列沒有它要接收的數據到達時,進程 A 會讓出 CPU,進入阻塞狀態,進程 A 的進程描述符和它被喚醒用到的回調函數 callback func 會組成一個結構體叫等待隊列項,放入 socket 的進程等待隊列;
3)客戶端的發送數據到達服務端的網卡;
4)網卡首先會將網路傳輸過來的數據通過 DMA 控製程序複製到記憶體環形緩衝區 RingBuffer 中;
5)網卡向 CPU 發出硬中斷;
6)CPU 收到了硬中斷後,為了避免過度占用 CPU 處理網路設備請求導致其他設備如滑鼠和鍵盤的消息無法被處理,會調用網路驅動註冊的中斷處理函數,進行簡單快速處理後向內核中斷進程 ksoftirqd 發出軟中斷,就釋放 CPU,由軟中斷進程處理複雜耗時的網路設備請求邏輯;
7)內核中斷進程 ksoftirqd 收到軟中斷信號後,會將網卡複製到記憶體的數據,根據數據報文的 IP 和埠號,將其拷貝到對應 socket 的接收隊列;
8)內核中斷進程 ksoftirqd 根據 socket 的數據接收隊列的數據,通過進程等待隊列中的回調函數,喚醒要處理該數據的進程 A,進程 A 會進入 CPU 的運行隊列,等待獲取 CPU 執行數據處理邏輯;
9)進程 A 獲取 CPU 後,會回到之前調用 recvfrom() 函數時阻塞的位置繼續執行,這時發現 socket 內核空間的等待隊列上有數據,會在內核態將內核空間的 socket 等待隊列的數據拷貝到用戶空間,然後才會回到用戶態執行進程的用戶程式,從而真的解除阻塞;
用戶進程 A 在調用 recvfrom() 系統函數時,有兩個階段都是等待的:在數據沒有準備好的時候,進程 A 等待內核 socket 準備好數據;內核准備好數據後,進程 A 繼續等待內核將 socket 等待隊列的數據拷貝到自己的用戶緩衝區;在內核完成數據拷貝到用戶緩衝區後,進程 A 才會從 recvfrom() 系統調用中返回,並解除阻塞狀態。整體流程如下:
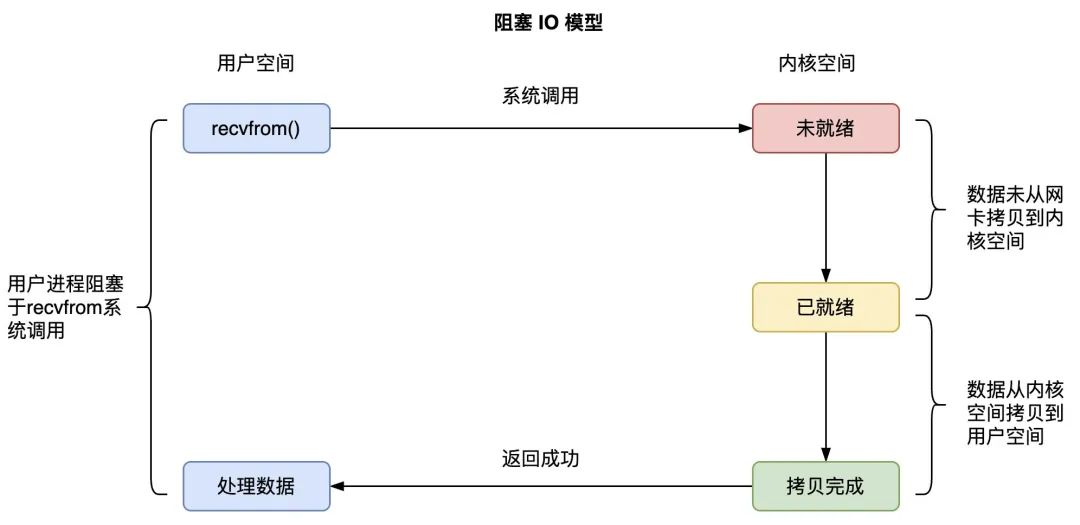
在 IO 阻塞邏輯中,存在下麵三個問題:
-
進程在 recv 的時候大概率會被阻塞掉,導致一次進程切換;
-
當 TCP 連接上的數據到達服務端的網卡、並從網卡複製到內核空間 socket 的數據等待隊列時,進程會被喚醒,又是一次進程切換;並且,在用戶進程繼續執行完 recvfrom() 函數系統調用,將內核空間的數據拷貝到了用戶緩衝區後,用戶進程才會真正拿到所需的數據進行處理;
-
一個進程同時只能等待一條連接,如果有很多併發,則需要很多進程;
總結:一次數據到達會進行兩次進程切換,一次數據讀取有兩處阻塞,單進程對單連接。
1.2 非阻塞 IO
為瞭解決同步阻塞 IO 的問題,操作系統提供了非阻塞的 recv() 函數,這個函數的效果是:如果沒有數據從網卡到達內核 socket 的等待隊列時,系統調用會直接返回,而不是阻塞的等待。
如果我們要產生一個非阻塞的 socket,在 C 語言中如下代碼所示:
// 創建socket
int sock_fd = socket(AF_INET, SOCK_STREAM, 0);
...
// 更改socket為nonblock
fcntl(sock_fd, F_SETFL, fdflags | O_NONBLOCK);
// connect
....
while(1) {
int recvlen = recv(sock_fd, recvbuf, RECV_BUF_SIZE) ;
......
}
...非阻塞 IO 模型如下圖所示:
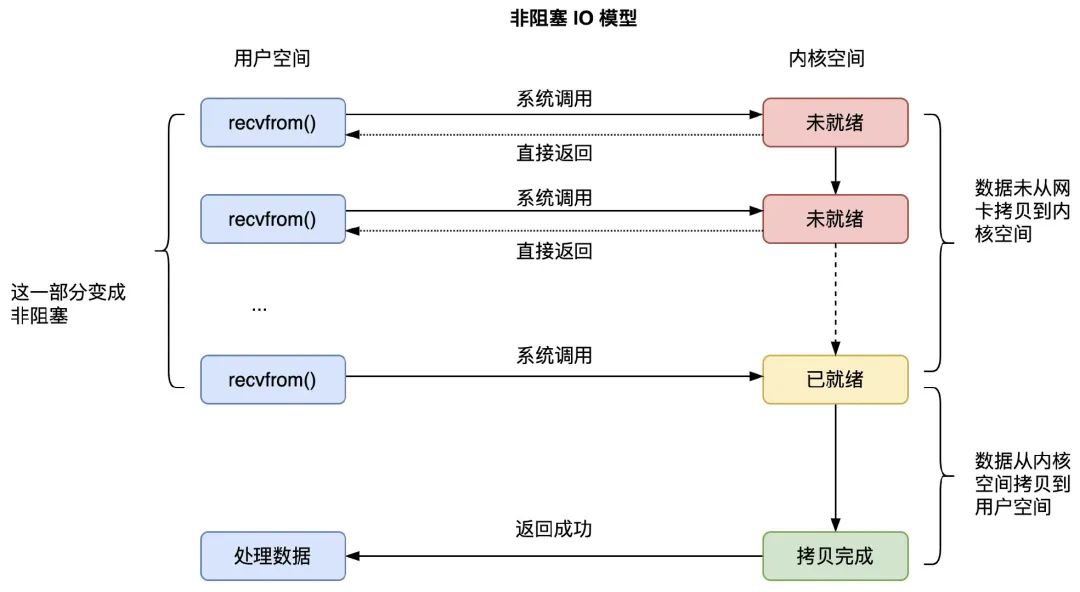
從上圖中,我們知道,非阻塞 IO,是將等待數據從網卡到達 socket 內核空間這一部分變成了非阻塞的,用戶進程調用 recvfrom() 會重覆發送請求檢查數據是否到達內核空間,如果沒有到,則立即返回,不會阻塞。不過,當數據已經到達內核空間的 socket 的等待隊列後,用戶進程依然要等待 recvfrom() 函數將數據從內核空間拷貝到用戶空間,才會從 recvfrom() 系統調用函數中返回。
非阻塞 IO 模型解決了“兩次進程切換,兩處阻塞,單進程對單連接”中的“兩處阻塞”問題,將“兩處阻塞”變成了“一處阻塞”,但依然存在“兩次進程切換,一處阻塞,單進程對單連接”的問題。
1.3 IO 多路復用
要解決“兩次進程切換,單進程對單連接”的問題,伺服器引入了 IO 多路復用技術,通過一個進程處理多個 TCP 連接,不僅降低了伺服器處理網路請求的進程數,而且不用在每個連接的數據到達時就進行進程切換,進程可以一直運行並只處理有數據到達的連接,當然,如果要監聽的所有連接都沒有數據到達,進程還是會進入阻塞狀態,直到某個連接有數據到達時被回調函數喚醒。
IO 多路復用模型如下圖所示:
從上圖可知,系統調用 select 函數阻塞執行並返回數據就緒的連接個數,然後調用 recvfrom() 函數將到達內核空間的數據拷貝到用戶空間,儘管這兩個階段都是阻塞的,但是由於只會處理有數據到達的連接,整體效率會有極大的提升。
到這裡,阻塞 IO 模型的“兩次進程切換,兩處阻塞,單進程對單連接”問題,通過非阻塞 IO 和多路復用技術,就只剩下了“一處阻塞”這個問題,即 Linux 伺服器上用戶進程一定要等待數據從內核空間拷貝到用戶空間,如果這個步驟也變成非阻塞的,也就是進程調用 recvfrom 後立刻返回,內核自行去準備好數據並將數據從內核空間拷貝到用戶空間、再 notify 通知用戶進程去讀取數據,那就是 IO 非同步調用,不過,Linux 沒有提供非同步 IO 的實現,真正意義上的網路非同步 IO 是 Windows 下的 IOCP(IO 完成埠)模型,這裡就不探討了。
2. 詳解 select、poll、epoll 實現原理
2.1 select 實現原理
select 函數定義
Linux 提供的 select 函數的定義如下:
int select(
int nfds, // 監控的文件描述符集里最大文件描述符加1
fd_set *readfds, // 監控有讀數據到達文件描述符集合,引用類型的參數
fd_set *writefds, // 監控寫數據到達文件描述符集合,引用類型的參數
fd_set *exceptfds, // 監控異常發生達文件描述符集合,引用類型的參數
struct timeval *timeout); // 定時阻塞監控時間readfds、writefds、errorfds 是三個文件描述符集合。select 會遍歷每個集合的前 nfds 個描述符,分別找到可以讀取、可以寫入、發生錯誤的描述符,統稱為“就緒”的描述符。然後用找到的子集替換這三個引用參數中的對應集合,返回所有就緒描述符的數量。
timeout 參數表示調用 select 時的阻塞時長。如果所有 fd 文件描述符都未就緒,就阻塞調用進程,直到某個描述符就緒,或者阻塞超過設置的 timeout 後,返回。如果 timeout 參數設為 NULL,會無限阻塞直到某個描述符就緒;如果 timeout 參數設為 0,會立即返回,不阻塞。
文件描述符 fd
文件描述符(file descriptor)是一個非負整數,從 0 開始。進程使用文件描述符來標識一個打開的文件。Linux 中一切皆文件。
系統為每一個進程維護了一個文件描述符表,表示該進程打開文件的記錄表,而文件描述符實際上就是這張表的索引。每個進程預設都有 3 個文件描述符:0 (stdin)、1 (stdout)、2 (stderr)。
socket
socket 可以用於同一臺主機的不同進程間的通信,也可以用於不同主機間的通信。操作系統將 socket 映射到進程的一個文件描述符上,進程就可以通過讀寫這個文件描述符來和遠程主機通信。
socket 是進程間通信規則的高層抽象,而 fd 提供的是底層的具體實現。socket 與 fd 是一一對應的。通過 socket 通信,實際上就是通過文件描述符 fd 讀寫文件。
本文中,為了方便理解,可以認為 socket 內核對象 ≈ fd 文件描述符 ≈ TCP 連接。
fd_set 文件描述符集合
select 函數參數中的 fd_set 類型表示文件描述符的集合。
由於文件描述符 fd 是一個從 0 開始的無符號整數,所以可以使用 fd_set 的二進位每一位來表示一個文件描述符。某一位為 1,表示對應的文件描述符已就緒。比如比如設 fd_set 長度為 1 位元組,則一個 fd_set 變數最大可以表示 8 個文件描述符。當 select 返回 fd_set = 00010011 時,表示文件描述符 1、2、5 已經就緒。
fd_set 的 API
fd_set 的使用涉及以下幾個 API:
#include <sys/select.h>
int FD_ZERO(int fd, fd_set *fdset); // 將 fd_set 所有位置 0
int FD_CLR(int fd, fd_set *fdset); // 將 fd_set 某一位置 0
int FD_SET(int fd, fd_set *fd_set); // 將 fd_set 某一位置 1
int FD_ISSET(int fd, fd_set *fdset); // 檢測 fd_set 某一位是否為 1select 監聽多個連接的用法
服務端使用 select 監控多個連接的 C 代碼是:
#define MAXCLINE 5 // 連接隊列中的個數
int fd[MAXCLINE]; // 連接的文件描述符隊列
int main(void)
{
sock_fd = socket(AF_INET,SOCK_STREAM,0) // 建立主機間通信的 socket 結構體
.....
bind(sock_fd, (struct sockaddr *)&server_addr, sizeof(server_addr); // 綁定socket到當前伺服器
listen(sock_fd, 5); // 監聽 5 個TCP連接
fd_set fdsr; // bitmap類型的文件描述符集合,01100 表示第1、2位有數據到達
int max;
for(i = 0; i < 5; i++)
{
.....
fd[i] = accept(sock_fd, (struct sockaddr *)&client_addr, &sin_size); // 跟 5 個客戶端依次建立 TCP 連接,並將連接放入 fd 文件描述符隊列
}
while(1) // 迴圈監聽連接上的數據是否到達
{
FD_ZERO(&fdsr); // 對 fd_set 即 bitmap 類型進行複位,即全部重置為0
for(i = 0; i < 5; i++)
{
FD_SET(fd[i], &fdsr); // 將要監聽的TCP連接對應的文件描述符所在的bitmap的位置置1,比如 0110010110 表示需要監聽第 1、2、5、7、8個文件描述符對應的 TCP 連接
}
ret = select(max + 1, &fdsr, NULL, NULL, NULL); // 調用select系統函數進入內核檢查哪個連接的數據到達
for(i=0;i<5;i++)
{
if(FD_ISSET(fd[i], &fdsr)) // fd_set中為1的位置表示的連接,意味著有數據到達,可以讓用戶進程讀取
{
ret = recv(fd[i], buf,sizeof(buf), 0);
......
}
}
}從註釋中,我們可以看到,在一個進程中使用 select 監控多個連接的主要步驟是:
1)調用 socket() 函數建立主機間通信的 socket 結構體,bind() 綁定 socket 到當前伺服器,listen() 監聽五個 TCP 連接;
2)調用 accept() 函數建立和 5 個客戶端的 TCP 連接,並把連接的文件描述符放入 fd 文件描述符隊列;
3) 定義一個 fd_set 類型的變數 fdsr;
4)調用 FD_ZERO,將 fdsr 所有位置 0;
5)調用 FD_SET,將 fdsr 要監聽的幾個文件描述符的位置 1,表示要監聽這幾個文件描述符指向的連接;
6)調用 select() 函數,並將 fdsr 參數傳遞給 select;
7)select 會將 fdsr 中就緒的位置 1,未就緒的位置 0,返回就緒的文件描述符的數量;
8)當 select 返回後,調用 FD_ISSET 檢測哪些位為 1,表示對應文件描述符對應的連接的數據已經就緒,可以調用 recv 函數讀取該連接的數據了。
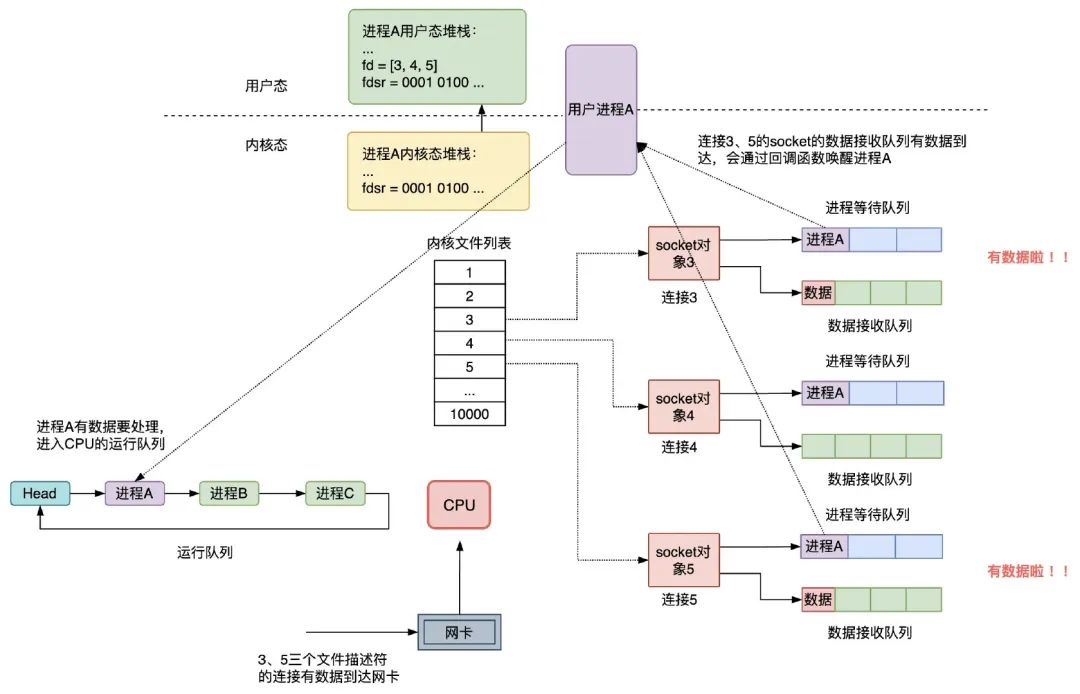
select 的執行過程
在伺服器進程 A 啟動的時候,要監聽的連接的 socket 文件描述符是 3、4、5,如果這三個連接均沒有數據到達網卡,則進程 A 會讓出 CPU,進入阻塞狀態,同時會將進程 A 的進程描述符和被喚醒時用到的回調函數組成等待隊列項加入到 socket 對象 3、4、5 的進程等待隊列中,註意,這時 select 調用時,fdsr 文件描述符集會從用戶空間拷貝到內核空間,如下圖所示:
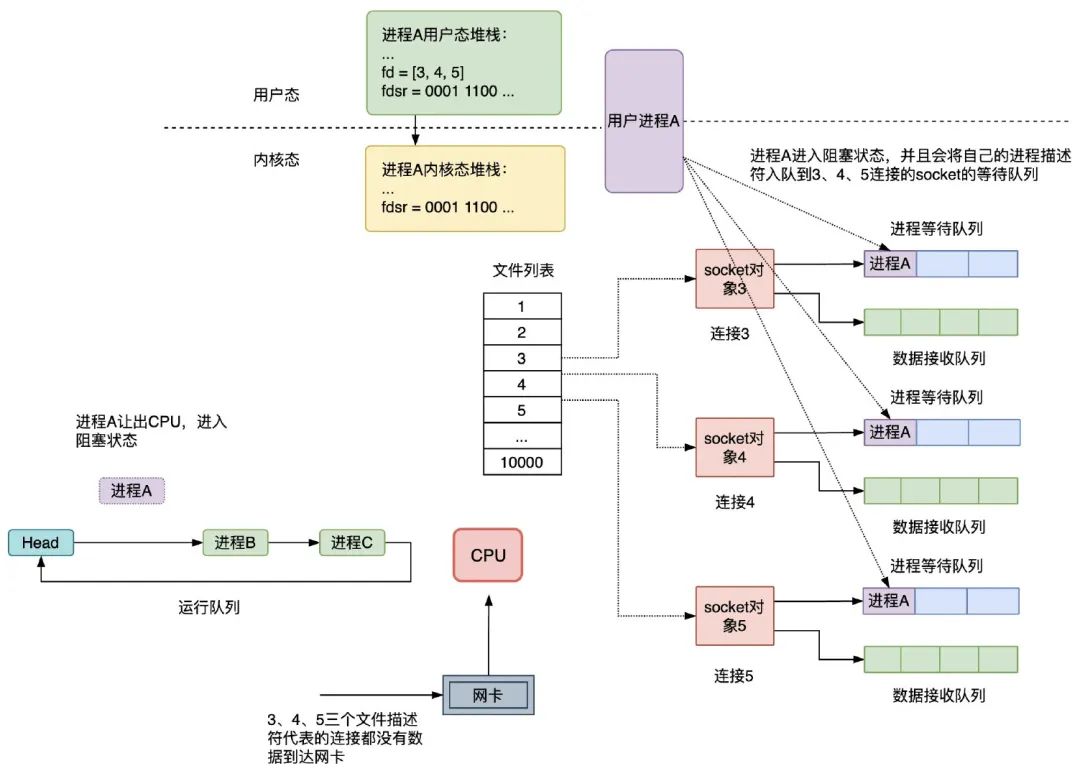
當網卡接收到數據,然後網卡通過中斷信號通知 CPU 有數據到達,執行中斷程式,中斷程式主要做了兩件事:
1)將網路數據寫入到對應 socket 的數據接收隊列裡面;
2)喚醒隊列中的等待進程 A,重新將進程 A 放入 CPU 的運行隊列中;
假設連接 3、5 有數據到達網卡,註意,這時 select 調用結束時,fdsr 文件描述符集會從內核空間拷貝到用戶空間:
select 的缺點
從上面兩圖描述的執行過程,可以發現 select 實現多路復用有以下缺點:
1.性能開銷大
1)調用 select 時會陷入內核,這時需要將參數中的 fd_set 從用戶空間拷貝到內核空間,select 執行完後,還需要將 fd_set 從內核空間拷貝回用戶空間,高併發場景下這樣的拷貝會消耗極大資源;(epoll 優化為不拷貝)
2)進程被喚醒後,不知道哪些連接已就緒即收到了數據,需要遍歷傳遞進來的所有 fd_set 的每一位,不管它們是否就緒;(epoll 優化為非同步事件通知)
3)select 只返回就緒文件的個數,具體哪個文件可讀還需要遍歷;(epoll 優化為只返回就緒的文件描述符,無需做無效的遍歷)
2.同時能夠監聽的文件描述符數量太少。受限於 sizeof(fd_set) 的大小,在編譯內核時就確定了且無法更改。一般是 32 位操作系統是 1024,64 位是 2048。(poll、epoll 優化為適應鏈表方式)
第 2 個缺點被 poll 解決,第 1 個性能差的缺點被 epoll 解決。
2.2 poll 實現原理
和 select 類似,只是描述 fd 集合的方式不同,poll 使用 pollfd 結構而非 select 的 fd_set 結構。
struct pollfd {
int fd; // 要監聽的文件描述符
short events; // 要監聽的事件
short revents; // 文件描述符fd上實際發生的事件
};管理多個描述符也是進行輪詢,根據描述符的狀態進行處理,但 poll 無最大文件描述符數量的限制,因其基於鏈表存儲。
select 和 poll 在內部機制方面並沒有太大的差異。相比於 select 機制,poll 只是取消了最大監控文件描述符數限制,並沒有從根本上解決 select 存在的問題。
2.3 epoll 實現原理
epoll 是對 select 和 poll 的改進,解決了“性能開銷大”和“文件描述符數量少”這兩個缺點,是性能最高的多路復用實現方式,能支持的併發量也是最大。
epoll 的特點是:
1)使用紅黑樹存儲一份文件描述符集合,每個文件描述符只需在添加時傳入一次,無需用戶每次都重新傳入;—— 解決了 select 中 fd_set 重覆拷貝到內核的問題
2)通過非同步 IO 事件找到就緒的文件描述符,而不是通過輪詢的方式;
3)使用隊列存儲就緒的文件描述符,且會按需返回就緒的文件描述符,無須再次遍歷;
epoll 的基本用法是:
int main(void)
{
struct epoll_event events[5];
int epfd = epoll_create(10); // 創建一個 epoll 對象
......
for(i = 0; i < 5; i++)
{
static struct epoll_event ev;
.....
ev.data.fd = accept(sock_fd, (struct sockaddr *)&client_addr, &sin_size);
ev.events = EPOLLIN;
epoll_ctl(epfd, EPOLL_CTL_ADD, ev.data.fd, &ev); // 向 epoll 對象中添加要管理的連接
}
while(1)
{
nfds = epoll_wait(epfd, events, 5, 10000); // 等待其管理的連接上的 IO 事件
for(i=0; i<nfds; i++)
{
......
read(events[i].data.fd, buff, MAXBUF)
}
}主要涉及到三個函數:
int epoll_create(int size); // 創建一個 eventpoll 內核對象
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event); // 將連接到socket對象添加到 eventpoll 對象上,epoll_event是要監聽的事件
int epoll_wait(int epfd, struct epoll_event *events,
int maxevents, int timeout); // 等待連接 socket 的數據是否到達epoll_create
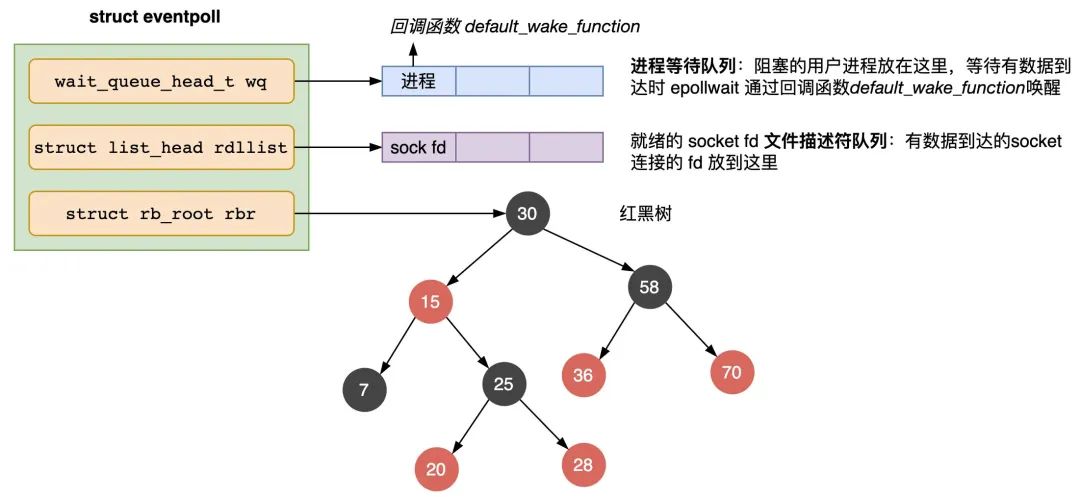
epoll_create 函數會創建一個 struct eventpoll 的內核對象,類似 socket,把它關聯到當前進程的已打開文件列表中。
eventpoll 主要包含三個欄位:
struct eventpoll {
wait_queue_head_t wq; // 等待隊列鏈表,存放阻塞的進程
struct list_head rdllist; // 數據就緒的文件描述符都會放到這裡
struct rb_root rbr; // 紅黑樹,管理用戶進程下添加進來的所有 socket 連接
......
}wq:等待隊列,如果當前進程沒有數據需要處理,會把當前進程描述符和回調函數 default_wake_functon 構造一個等待隊列項,放入當前 wq 對待隊列,軟中斷數據就緒的時候會通過 wq 來找到阻塞在 epoll 對象上的用戶進程。
rbr:一棵紅黑樹,管理用戶進程下添加進來的所有 socket 連接。
rdllist:就緒的描述符的鏈表。當有的連接數據就緒的時候,內核會把就緒的連接放到 rdllist 鏈表裡。這樣應用進程只需要判斷鏈表就能找出就緒進程,而不用去遍歷整棵樹。
eventpoll 的結構如圖 2.3 所示:
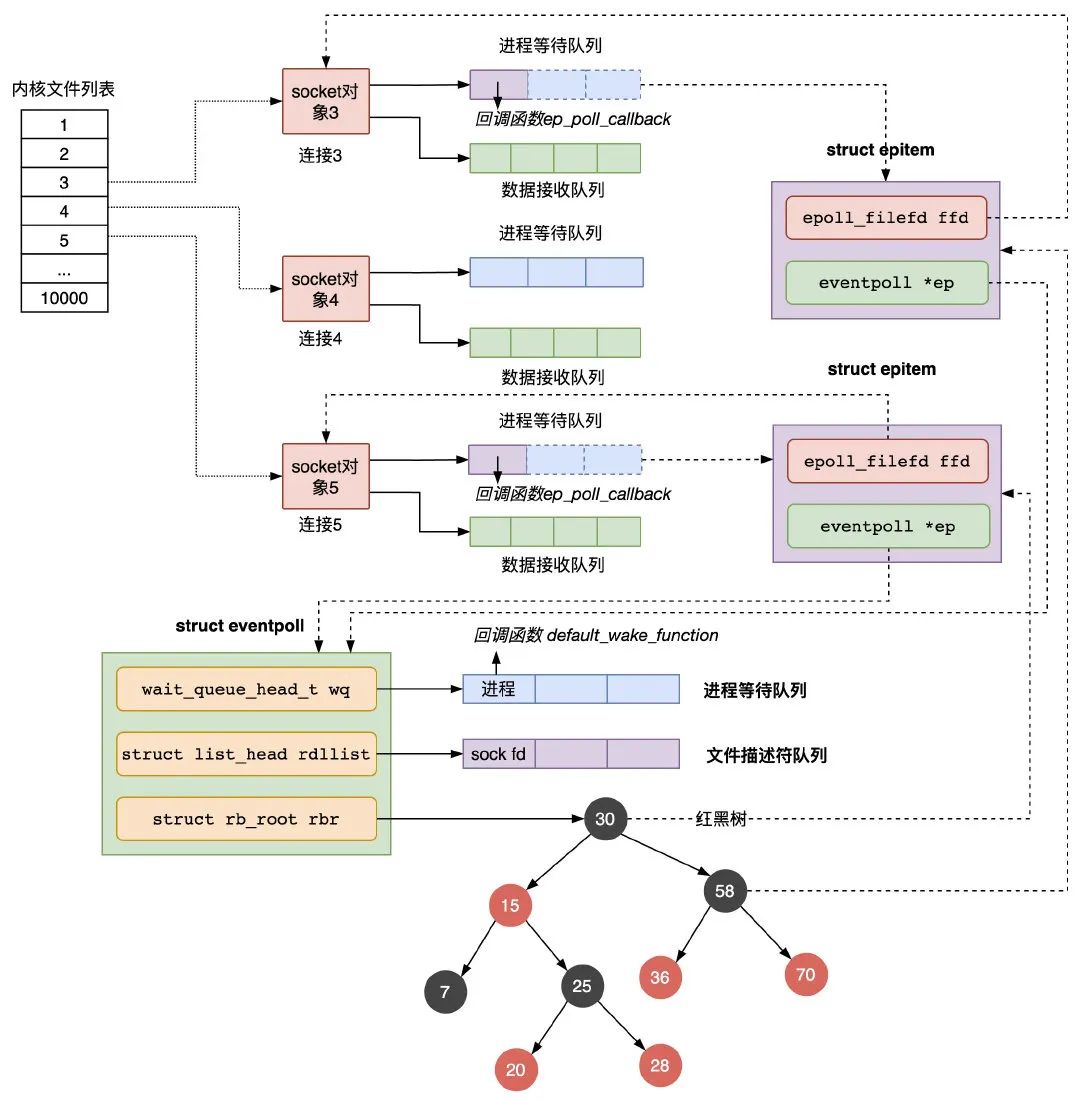
epoll_ctl
epoll_ctl 函數主要負責把服務端和客戶端建立的 socket 連接註冊到 eventpoll 對象里,會做三件事:
1)創建一個 epitem 對象,主要包含兩個欄位,分別存放 socket fd 即連接的文件描述符,和所屬的 eventpoll 對象的指針;
2)將一個數據到達時用到的回調函數添加到 socket 的進程等待隊列中,註意,跟第 1.1 節的阻塞 IO 模式不同的是,這裡添加的 socket 的進程等待隊列結構中,只有回調函數,沒有設置進程描述符,因為在 epoll 中,進程是放在 eventpoll 的等待隊列中,等待被 epoll_wait 函數喚醒,而不是放在 socket 的進程等待隊列中;
3)將第 1)步創建的 epitem 對象插入紅黑樹;
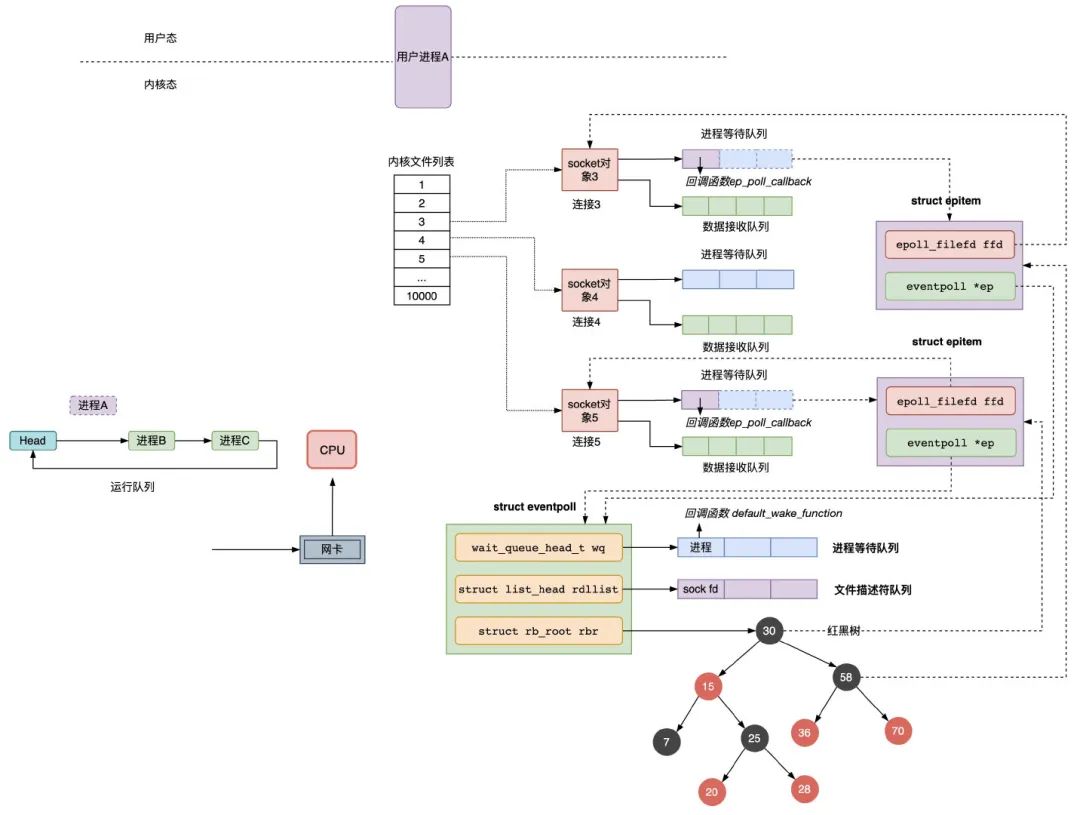
epoll_wait
epoll_wait 函數的動作比較簡單,檢查 eventpoll 對象的就緒的連接 rdllist 上是否有數據到達,如果沒有就把當前的進程描述符添加到一個等待隊列項里,加入到 eventpoll 的進程等待隊列里,然後阻塞當前進程,等待數據到達時通過回調函數被喚醒。
當 eventpoll 監控的連接上有數據到達時,通過下麵幾個步驟喚醒對應的進程處理數據:
1)socket 的數據接收隊列有數據到達,會通過進程等待隊列的回調函數 ep_poll_callback 喚醒紅黑樹中的節點 epitem;
2)ep_poll_callback 函數將有數據到達的 epitem 添加到 eventpoll 對象的就緒隊列 rdllist 中;
3)ep_poll_callback 函數檢查 eventpoll 對象的進程等待隊列上是否有等待項,通過回調函數 default_wake_func 喚醒這個進程,進行數據的處理;
4)當進程醒來後,繼續從 epoll_wait 時暫停的代碼繼續執行,把 rdlist 中就緒的事件返回給用戶進程,讓用戶進程調用 recv 把已經到達內核 socket 等待隊列的數據拷貝到用戶空間使用。
3. 總結
從阻塞 IO 到 epoll 的實現中,我們可以看到 wake up 回調函數機制被頻繁的使用,至少有三處地方:一是阻塞 IO 中數據到達 socket 的等待隊列時,通過回調函數喚醒進程,二是 epoll 中數據到達 socket 的等待隊列時,通過回調函數 ep_poll_callback 找到 eventpoll 中紅黑樹的 epitem 節點,並將其加入就緒列隊 rdllist,三是通過回調函數 default_wake_func 喚醒用戶進程 ,並將 rdllist 傳遞給用戶進程,讓用戶進程準確讀取數據 。從中可知,這種回調機制能夠定向準確的通知程式要處理的事件,而不需要每次都迴圈遍歷檢查數據是否到達以及數據該由哪個進程處理,提高了程式效率,在日常的業務開發中,我們也可以借鑒下這一機制。
References
圖解 | 深入揭秘 epoll 是如何實現 IO 多路復用的!
圖解 | 深入理解高性能網路開發路上的絆腳石 - 同步阻塞網路 IO
I/O 多路復用,select / poll / epoll 詳解
IO 多路復用底層原理全解,select,poll,epoll,socket,系統中斷,進程調度,系統調用
作者:mingguangtu
本文來自博客園,作者:古道輕風,轉載請註明原文鏈接:https://www.cnblogs.com/88223100/p/Deeply-learn-the-implementation-principle-of-IO-multiplexing-select_poll_epoll.html

