分片是指跨機器拆分數據的過程,通過在每台機器上放置數據的子集,無須功能強大的機器,只使用大量功能稍弱的機器,就可以存儲更多的數據並處理更多的負載。 ...
簡介
什麼是分片
高數據量和高吞吐量的資料庫應用會對單機的性能造成較大壓力,大的查詢會將單機的 CPU 耗盡,大的數據量對單機的存儲壓力較大,最終會耗盡系統的記憶體壓力轉移到磁碟 IO 上。
為瞭解決這些問題,有兩個基本的方法:
- 垂直擴展:增加更多的 CPU 和存儲資源來擴展容量
- 水平擴展:將數據集分佈在多個伺服器上
MongoDB 的分片就是水平擴展的體現,使用分片減少了每個分片需要處理的請求數。通過水平擴展,集群可以提高自己的存儲容量和吞吐量。
何時分片
通常來說,不宜過早對數據進行分片,這會增加部署的複雜性;也不應該過晚進行分片,因為很難在不停止運行的情況下對超載的系統進行分片。
通常情況下,分片用於以下情況:
- 增加可用 RAM
- 增加可用磁碟空間
- 減少伺服器的負載
- 處理單個 mongod 無法承受的吞吐量
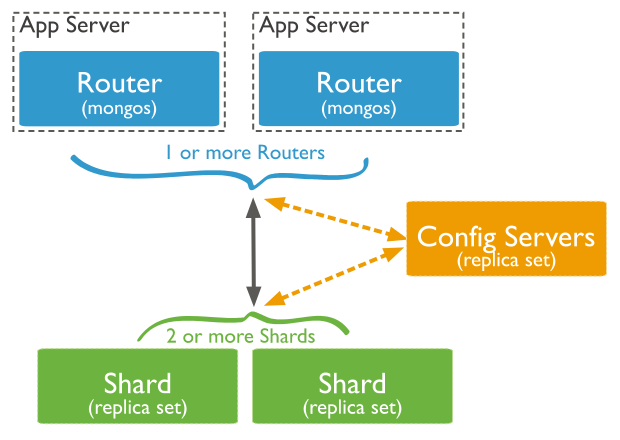
集群結構
一個 MongoDB 的分片集群包含以下組件:
- Shard: 即分片,數據的真正存儲位置,以 chunk 為單位存數據;分片也可以部署為一個副本集
- Router: 查詢的路由,提供客戶端和分片之間的介面;MongoDB 提供了 mongos 進程實現
- Config Servers: 存儲元數據和配置數據
數據存儲
分片的塊
在一個分片服務內部,MongoDB 會把數據分為塊,每個 chunk 代表這個分片內部的一部分數據。其作用有兩個:
- splitting: 當一個 chunk 的大小超過配置的 chunk size 時,MongoDB 的後臺進程會將這個 chunk 繼續切分
- balancing: 在 MongoDB 中,會有一個 balancer 線程負責 chunk 的遷移,從而均衡各個分片的負載
塊的大小
在 MongoDB 中,chunk 的分裂和遷移是非常耗費 IO 資源的,並且 chunk 的分裂只會發生在插入和更新時。
對於大塊和小塊的選擇,其實各有優缺點:
- 小塊:遷移速度快,數據分佈更均勻;數據分裂頻繁,路由節點消耗更多資源
- 大塊:數據分裂少,數據塊移動集中消耗 IO 資源
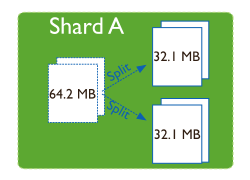
分裂和遷移
隨著數據的增長,其中的數據大小超過了配置的 chunk size(預設 64M),則這個 chunk 就會分裂成兩個。
數據增長的速度快慢會影響 chunk 分裂的速度,數據增長越快則 chunk 分裂的速度越快。
需要註意的是,如果分片試圖分裂的時候,其中一個配置伺服器停止運行了,那麼將無法更新元數據,則會出現分片一直嘗試拆分塊並一直失敗,這種一直無法成功的過程最終會導致 拆分風暴。
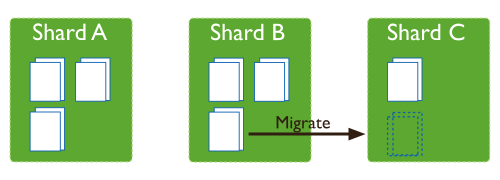
一旦發生了分裂,比如說 Shard A 分裂成 3 個塊,Shard B 分裂成 3 個塊,而 Shard C 仍然只有 1 個塊,則各個分片上的 chunk 數量會不平衡,。
這時候,mongos 中的 balancer 線程就會執行自動平衡,把 chunk 從 chunk 數量最多的分片挪動到 chunk 數量最少的節點。
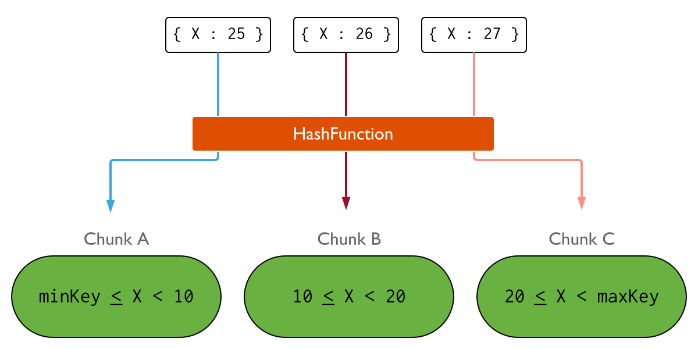
如何分片
分片鍵
在對集合進行分片的時,需要選擇一個或多個組合欄位來對數據進行拆分,這個鍵(這些鍵)被稱為分片鍵。
選擇分片鍵非常重要,分片鍵的有以下註意事項:
- 分片鍵是不可變的
- 分片鍵必須是索引
- 分片鍵不能是數組
- 分片鍵大小限制 512bytes
- 分片鍵用於路由查詢
- 分片鍵的組合最好具有很高的基數
哈希分片
分片過程中可以使用哈希索引作為分片鍵,其最大的好處是能保證數據在各個節點分佈基本均勻。
對於基於哈希的分片,MongoDB 計算一個欄位的哈希值,並用這個哈希值來創建數據塊。
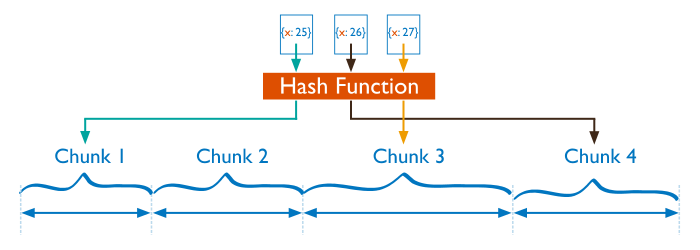
在使用基於哈希分片的系統中,擁有相近分片鍵的文檔很可能不會存儲在同一個數據塊中,數據的分離性更好一些。
基於哈希分片可以很好地在集群中分配負載,但是,如果隨機訪問超出了 RAM 大小的數據時,效率會比較低。
範圍分片
對於基於範圍的分片,MongoDB 按照分片鍵的範圍把數據分成不同部分。
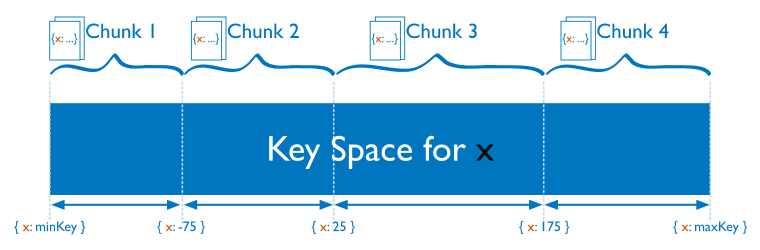
在使用分片鍵做範圍劃分的系統中,擁有相近分片鍵的文檔很可能存儲在同一個數據塊中,因此也會存儲在同一個分片中。
如果這個分片鍵是一個自增的值時,將會使 MongoDB 難以保持塊的均衡,因為 MongoDB 需要不斷將最後一個分片的數據塊移動到其他分片上。
哈希和範圍的結合
哈希分片更適合隨機訪問,不適合範圍查詢;範圍分片則是適合範圍查詢,不適合平衡負載。
一個自定義的方案是,對自增欄位構建哈希索引(儘可能是仍然保持有序的哈希演算法)即可解決。