
如果決策引擎是風控的大腦,那麼規則引擎則是大腦內的重要構成,其編排了各種對抗黑產的規則,是多年對抗黑產的專家經驗的累計,本文將向你介紹規則引擎的構成及實現。 ...
引言
如果決策引擎是風控的大腦,那麼規則引擎則是大腦內的重要構成,其編排了各種對抗黑產的規則,是多年對抗黑產的專家經驗的累計,本文將向你介紹規則引擎的構成及實現。
背景
什麼是規則引擎?
規則引擎可以幫助企業將業務決策從應用程式代碼中分離出來,並使用預定義的語義模塊編寫業務規則。這使得企業可以更靈活地管理和修改業務規則,而無需修改應用程式代碼。
規則引擎可以接受數據輸入,並根據業務規則解釋數據,做出業務決策。這些業務決策可以是自動的,也可以是人工干預的。
規則引擎通常包含如下幾個部分:
- 規則庫:規則庫包含了所有可用的規則。這些規則可以是預先定義好的,也可以是動態生成的。
- 策略:用於管理規則,是對規則的條件組裝,如評分卡策略、最壞匹配策略等。
- 規則執行引擎:負責規則的執行。讀取規則庫中所有可用規則,根據規則的條件執行規則。
為什麼需要規則引擎?
規則引擎可以幫助企業更有效的管理和執行業務規則,提高決策的質量、效率和可靠性。
特點如下:
- 將業務決策從代碼中剝離出來:運營人員可以更靈活有效的管理和修改業務規則,而無需修改業務代碼,節省對抗時間
- 提高決策質量:規則引擎按照業務規則自動做出決策,無需依賴人為干預
- 提效:規則配置好後,可永久自動執行,減少人力消耗
- 穩定性:減少發版,減少測試,減少人為錯誤
設計實現
技術選型
在選擇規則引擎時,需要考慮如下幾點:
- 業務需求:應該根據企業的業務需求來選擇規則引擎。如果企業需要快速執行大量規則,則應選擇性能較高的規則引擎。
- 技術平臺:選擇與企業現有技術平臺相相容的規則引擎。如果企業使用的是 Java 技術平臺,則應選擇支持 Java 的規則引擎。
- 成本:考慮規則引擎的購買成本、實施成本和運行成本。是否開源也是很多技術團隊的選擇因素。
- 可維護性:選擇易於維護的規則引擎,在需要時能夠快速修改和更新規則。
- 市場占有率:選擇市場占有率較高的規則引擎,在需要時能夠獲得較好的技術支持和培訓。
- 技術支持:選擇提供較好技術支持的規則引擎,以便在使用過程中能夠得到及時的幫助。
當然,如果人力足夠,可以考慮自己實現規則引擎亦可,自實現版本的規則引擎肯定靈活性更高,但是在性能和穩定性上需要較長時間的驗證和考驗。
如下是市場上熱門的開源規則引擎:
| 規則引擎 | 簡介 |
|---|---|
| JBoss Drools | JBoss Drools 是一款開源的規則引擎,支持 Java 和其他語言。 |
| OpenRules | OpenRules 是一款開源的規則引擎,支持 Java 和其他語言。 |
| Hippo Rules Engine | Hippo Rules Engine 是一款開源的規則引擎,支持 Java 和其他語言 |
| Apache Flink | Apache Flink 是一款開源的流處理框架,也可以用作規則引擎 |
| Easy Rules | Easy Rules 是一個基於 Java 的開源規則引擎框架,它提供了簡單易用的 API,使得開發人員可以輕鬆地使用規則引擎。 |
| 基於 Groovy 實現規則引擎 | Groovy 是一種動態語言,可以運行在 Java 平臺上。由於 Groovy 的語法簡單,因此可以通過使用 Groovy 來實現規則引擎。 |
規則引擎術語
- 規則(Rule):規則是描述業務決策的規則或條件的語句。規則通常由兩部分組成:條件和動作。條件是描述規則被觸發的判斷,動作是描述規則執行的操作。
- 事實(Fact):事實是描述業務場景的數據。事實可以是一個單獨的數據項,也可以是一組數據。規則引擎會根據事實來觸發規則。
- 決策表:決策表是一種以表格形式表示規則的數據結構。決策表通常由多個條件列和一個結果列組成。當條件列的值都滿足時,決策表就會觸髮結果列的規則。
- 規則集合:規則集合是一種由規則組成的數據結構。規則集合通常以樹形結構存儲,每個規則都有一個條件和一個動作。當條件滿足時,規則集合就會執行規則的動作。
規則配置解析
規則引擎最終是需要交付給運營人員去配置使用的,所以必須能滿足靈活的配置編排,且易懂,才能最大發揮它的威力。
規則配置
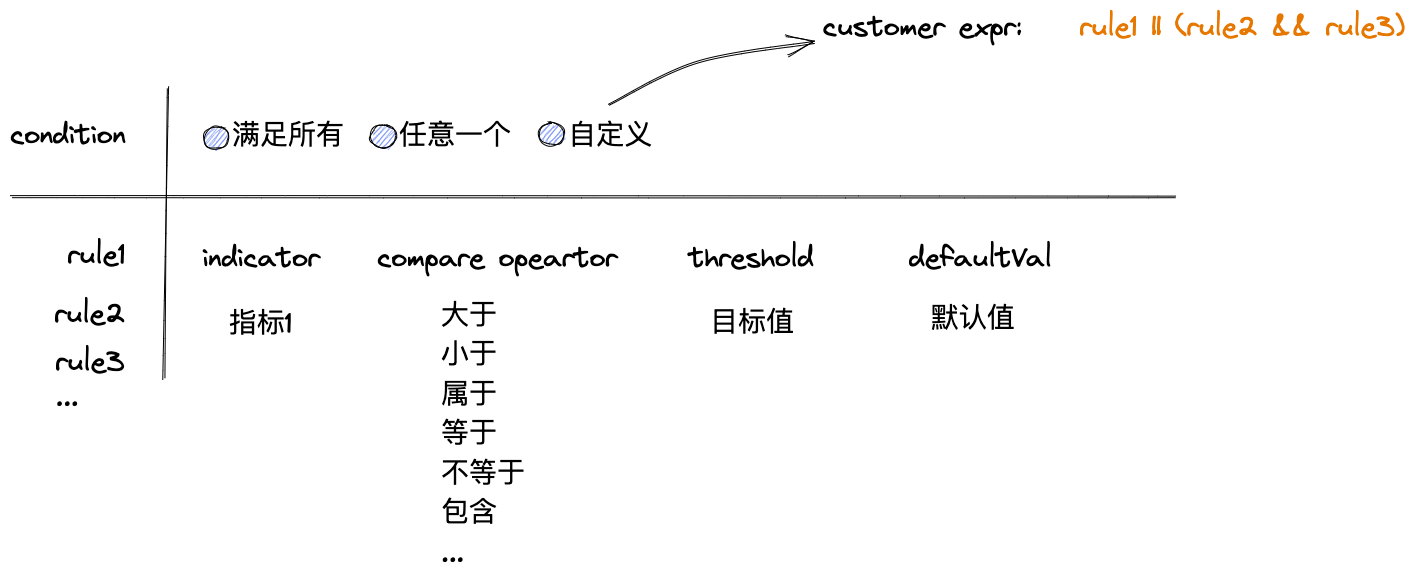
說明:
- 觸發條件:任意一個、滿足所有、自定義。其中自定義最靈活,用戶可以使用條件表達式配置任意想要的觸發與或條件
- 變數(指標):左值,指標是輸入數據衍生、或查詢、或計算所得的值
- 比較符:等於、不等於、包含、屬於、大於、小於、空 等等
- 閾值:右值,與指標計算所得值相比較,如果比較符關係成立,則認為命中當前規則
- 預設值:當指標執行出錯或者超時,預設返回的值
策略配置
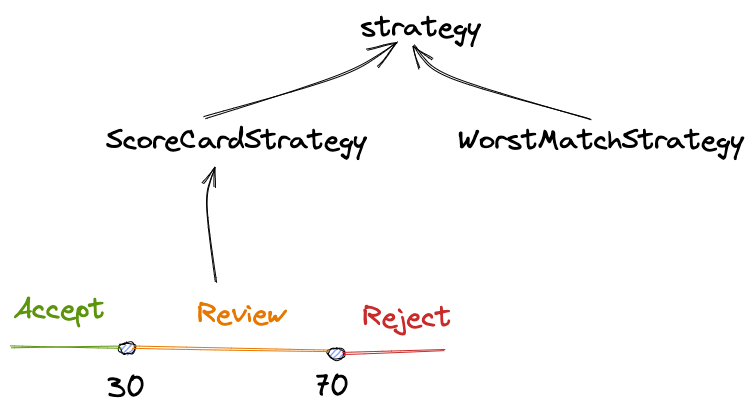
說明:
- 評分卡模式:依據每條規則命中所得分數之和,判定是否命中相應分數段的決策
- 最壞匹配:只要有一條規則命中,則立即拒絕
- 閾值:如果是評分卡模式,需要設置三個段位並且指定閾值
性能調優
決策引擎每天承載企業業務全部的風險決策,峰值 QPS 基本過萬,但是風控的決策耗時需要足夠的短,在不影響業務的情況下,儘可能快的返回決策結果,這是一大挑戰。
從以往的調優經驗來看,可以從以下幾點來優化規則引擎:
- 並行執行規則:一次決策流中可能包含 N 個規則節點,每個規則節點包含 M 個規則,充分利用多核 CPU 優勢,發揮最大威力,但同時需要考慮多線程數據安全問題
- 預載入指標:規則執行都是在記憶體中的,但是所需要的指標值往往都是需要調用外部系統得到的,一是網路開銷,二是指標計算開銷。可以在執行規則集之前,全部預載入一次指標再緩存,這樣執行時直接從記憶體取值就會快很多。但是需要註意成本問題(如付費指標,存儲成本,架構複雜度等),廢調用問題(前置規則已拒絕)等等
- 規則載入預編譯:規則首次載入往往比較耗時,此時最好能
warm up一下,這樣在流量進來後,即可立即執行,但是使用預編譯可能會增加系統的啟動開銷時間,需要做好相應的平衡工作 - 規則執行優化:運營配置規則時可能不會考慮規則執行順序問題,但是程式在執行的時候可以智能編排一下,通過加入
與或及順序關係,儘可能的把大耗時和大成本的指標放在最後面執行,優先執行記憶體指標,萬一命中則直接斷言,後續指標則不會再執行,節省了時間。要做到這一點,需要對指標進行較為詳細的歸類及元數據管理,需要全域的數據配合,對風控這種需要大數據的介面來說是一大挑戰。
總結
規則引擎在風控整體架構內的重要性毋庸置疑,它的穩定性直接關係到風控決策的性能、數據質量。同時,對運營來說,好的決策引擎是足夠靈活,足夠智能,滿足規則數據編排需求,且能立即生效上線,這是保障他們對抗黑產的前提,希望本文對構建高效的規則引擎又較好的啟發。
往期精彩
●性能優化必備——火焰圖
●我是怎麼入行做風控的
●Flink 在風控場景實時特征落地實戰
歡迎關註公眾號:咕咕雞技術專欄
個人技術博客:https://jifuwei.github.io/



